

從原理到用例
作者:Grace & Hill
本文為 SevenX 研究團隊原創,僅供交流學習,不構成任何投資參考。 如需引用,請註明來源。
原版英文報告於 2023 年 4 月發表於 SevenX 的 Mirror 平台。
感謝 Brian Retford, Sun Yi, Jason Morton, Shumo, Feng Boyuan, Daniel, Aaron Greenblatt, Nick Matthew, Baz, Marcin, and Brent 對本文提供的寶貴見解、反饋和審閱。 作者:Grace & Hill

對於我們這些加密愛好者來說,人工智慧已經火了好一陣子。 有趣的是,沒人願意看到人工智慧失控的情況。 區塊鏈發明的初衷是防止美元失控,所以我們可能會嘗試一下防止人工智慧的失控。 此外,我們現在有了一種叫做零知識證明的新技術,用於確保事情不會出錯。 然而,要駕馭人工智慧這個野獸,我們必須瞭解它的工作原理。
機器學習的簡單介紹
人工智慧已經經歷了幾個名字的變化,從「專家系統」到「神經網路」,然後是「圖形模型」,最後演變為「機器學習」。 所有這些都是「人工智慧」的子集,人們給它起了不同的名字,我們對人工智慧的瞭解也在不斷加深。 讓我們稍微深入瞭解一下機器學習,揭開機器學習的神秘面紗。

注:如今,大多數機器學習模型都是神經網路,因為它們在許多任務中具有優異的性能。 我們主要將機器學習稱為神經網路機器學習。
機器學習是如何工作的?
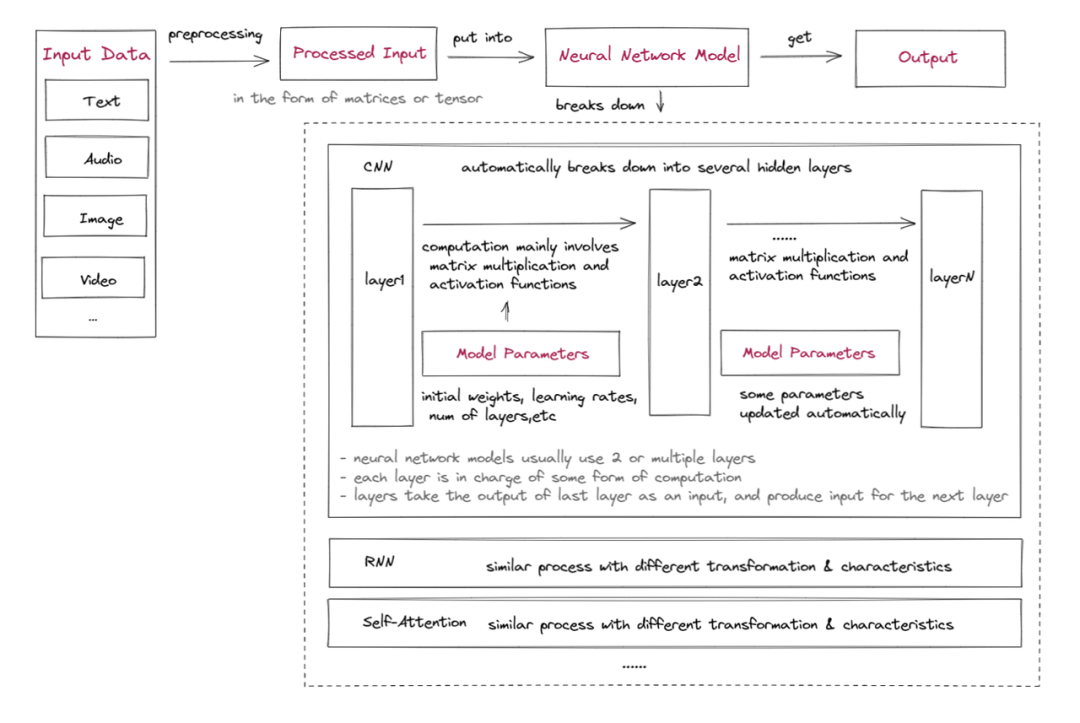
首先,讓我們快速瞭解一下機器學習的內部運作:
- 輸入資料預處理:
輸入數據需要處理成可以作為模型輸入的格式。 這通常涉及預處理和特徵工程,以提取有用的資訊並將數據轉換成合適的形式,如輸入矩陣或張量(高維矩陣)。 這是專家系統方法。 隨著深度學習的出現,處理層自動處理預處理。
- 設定初始模型參數:
初始模型參數包括多個層、啟動函數、初始權重、偏置、學習率等。 有些參數可以在訓練過程中通過優化演算法進行調整以提高模型的準確性。
- 訓練資料:
- 輸入數據輸入到神經網路中,通常從一個或多個特徵提取和關係建模層開始,如卷積層(CNN),迴圈層(RNN)或自注意力層。 這些層學會從輸入數據中提取相關特徵並建模這些特徵之間的關係。
- 這些層的輸出然後傳遞給一個或多個額外的層,這些層對輸入數據執行不同的計算和轉換。 這些層通常主要涉及可學習權重矩陣的矩陣乘法和非線性啟動函數的應用,但也可能包括其他操作,如卷積神經網路中的捲積和池化,或者迴圈神經網路中的反覆運算。 這些層的輸出作為模型中下一層的輸入,或者作為最終的預測輸出。
- 取得模型的輸出:
神經網路計算的輸出通常是一個向量或矩陣,表示圖像分類的概率、情感分析分數或其他結果,具體取決於網路的應用。 通常還有一個錯誤評估和參數更新模組,根據模型的目的自動更新參數。 如果上述解釋看起來太晦澀,可以參考以下使用 CNN 模型識別蘋果圖片的例子。

1. 將影像以像素值矩陣的形式載入到模型中。 該矩陣可以表示為具有尺寸(高度、寬度、通道)的 3D 張量。
2. 設定 CNN 模型的初始參數。
3. 輸入圖像通過 CNN 中的多個隱藏層,每個層應用卷積濾波器從圖像中提取越來越複雜的特徵。 每層的輸出通過非線性啟動函數,然後進行池化以減小特徵圖的維數。 最後一層通常是一個全連接層,根據提取的特徵生成輸出預測。
4. CNN 的最終輸出是概率最高的類別。 這是輸入圖像的預測標籤。
機器學習信任框架
我們可以將上述內容總結為一個機器學習信任框架,包括四個機器學習的基本層,整個機器學習過程需要這些層是可信的才能可靠:
- 輸入:原始數據需要進行預處理,有時還需要保密。
- 完整性:輸入數據未被篡改,未被惡意輸入污染,並且正確地進行了預處理。
- 隱私:如有需要,輸入數據不會洩露。
- 輸出:需要準確生成和傳輸
- 完整性:輸出正確生成。
- 隱私:如有需要,輸出不會洩露。
- 模型類型/演算法:模型應正確計算
- 完整性:模型執行正確。
- 隱私:如有需要,模型本身或計算不會洩露。
- 不同的神經網路模型具有不同的演算法和層,適用於不同的用例和輸入。
- 卷積神經網路(CNN)通常用於涉及網格狀數據的任務,如圖像,其中局部模式和特徵可以通過對小輸入區域應用卷積操作來捕獲。
- 另一方面,迴圈神經網路(RNN)非常適用於順序數據,如時間序列或自然語言,其中隱藏狀態可以捕獲來自先前時間步的資訊並建模時間依賴關係。
- 自注意力層對於捕獲輸入序列中元素之間的關係非常有用,使其對於諸如機器翻譯或摘要之類的任務非常有效,這些任務中長程依賴關係至關重要。
- 還存在其他類型的模型,包括多層感知機(MLP)等。
- 模型參數:在某些情況下,參數應該透明或民主生成,但在所有情況下都不易被篡改。
- 完整性:參數以正確的方式生成、維護和管理。
- 隱私:模型擁有者通常會對機器學習模型參數保密,以保護開發該模型的組織的智慧財產權和競爭優勢。 這種現象只在變壓器模型變得瘋狂昂貴的訓練前非常普遍,但對行業來說仍然是一個主要問題。
機器學習的信任問題
隨著機器學習(ML)應用的爆炸式增長(複合年增長率超過 20%)以及它們在日常生活中的日益融入,例如最近備受歡迎的 ChatGPT,機器學習的信任問題變得越來越關鍵,不容忽視。 因此,發現並解決這些信任問題至關重要,以確保負責任地使用 AI 並防止其潛在濫用。 然而,究竟是哪些問題呢? 讓我們深入瞭解。

透明度或可證明性不足
信任問題長期困擾著機器學習,主要原因有兩個:
- 隱私性質:如上所述,模型參數通常是私密的,而在某些情況下,模型輸入也需要保密,這自然會在模型擁有者和模型使用者之間帶來一些信任問題。
- 演算法黑盒:機器學習模型有時被稱為「黑盒」,因為它們在計算過程中涉及許多難以理解或解釋的自動化步驟。 這些步驟涉及複雜的演算法和大量的數據,帶來不確定性和有時隨機的輸出,使得演算法容易受到偏見甚至歧視的指責。
在更深入之前,本文的一個更大的假設是模型已經「準備好使用」,意味著它經過良好的訓練並符合目的。 模型可能不適用於所有情況,而且模型以驚人的速度改進,機器學習模型的正常使用壽命在 2 到 18 個月之間,具體取決於應用場景。
機器學習信任問題的詳細分解
模型訓練過程中存在一些信任問題,Gensyn 目前正在努力生成有效證明以促進這一過程。 然而,本文主要關注模型推理過程。 現在讓我們使用機器學習的四個構建模組來發現潛在的信任問題:
- 輸入:
- 數據來源是防篡改的
- 私有輸入數據不被模型操作者竊取(隱私問題)
- 模型:
- 模型本身如宣傳的那樣準確。
- 計算過程正確完成。
- 參數:
- 模型參數沒有被改變或與宣傳的一致。
- 在過程中,對模型擁有者具有價值的模型參數沒有洩露(隱私問題)
- 輸出:
- 輸出結果可證明是正確的(可能隨著上述所有元素的改進而改進)
如何將 ZK 應用到機器學習信任框架中
上述一些信任問題可以通過上鏈來解決; 將輸入和機器學習參數上傳到鏈上,並在鏈上計算模型,可以確保輸入、參數和模型計算的正確性。 但這種方法可能會犧牲可擴展性和隱私性。 Giza 正在 Starknet 上進行這項工作,但由於成本問題,它僅支援像回歸這樣的簡單機器學習模型,不支援神經網路。 ZK 技術可以更有效地解決上述信任問題。 目前,ZKML 的 ZK 通常指 zkSNARK。 首先,讓我們快速回顧一下 zkSNARK 的一些基本概念:
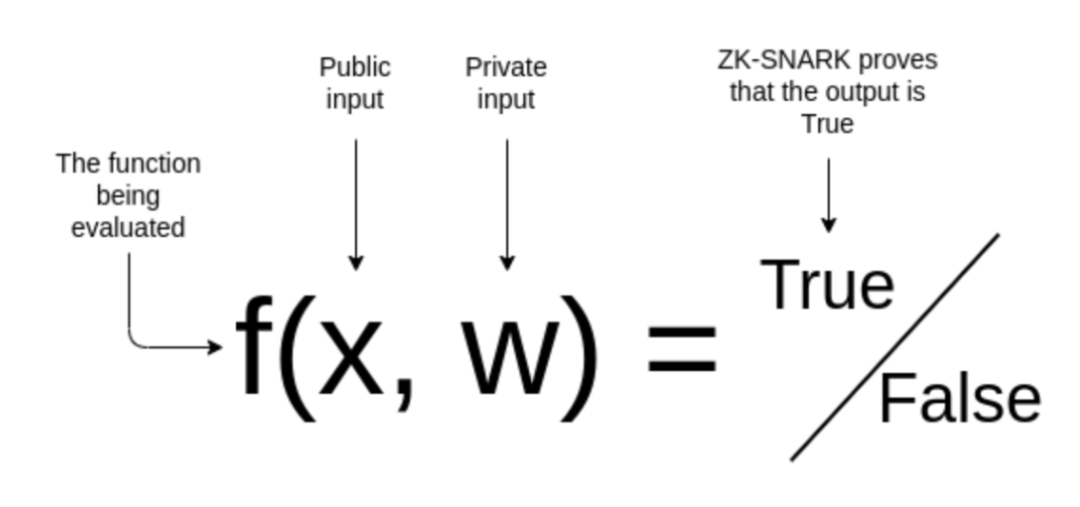
一個 zkSNARK 證明是證明我知道一些秘密輸入 w,使得這個計算 f 的結果為 OUT 是真實的,而不告訴你 w 是什麼。 證明生成過程可以總結為以下幾個步驟:
- 制定需要證明的陳述:f(x,w)=true
- “我使用具有私有參數 w 的機器學習模型 f 正確地對這個圖像 x 進行了分類。”
- 將陳述轉換為電路(算術化):不同的電路構建方法包括 R1CS、QAP、Plonkish 等。
- 與其他用例相比,ZKML 需要一個額外的步驟,稱為量化。 神經網路推斷通常使用浮點算術完成,而在算術電路的主要領域中類比浮點算術非常昂貴。 不同的量化方法在精度和設備要求之間取得折衷。
- 一些像 R1CS 這樣的電路構建方法對神經網路來說效率不高。 這部分可以調整以提高性能。
- 生成一個證明金鑰和一個驗證金鑰
- 創建一個見證:當 w=w*時,f(x,w)=true
- 創建一個哈希承諾:見證人 w*承諾使用加密哈希函數生成一個哈希值。 這個哈希值可以公之於眾。
- 這有助於確保在計算過程中,私有輸入或模型參數沒有被篡改或修改。 這一步至關重要,因為即使是細微的修改也可能對模型的行為和輸出產生重大影響。
- 生成證明:不同的證明系統使用不同的證明生成演算法。
- 需要為機器學習操作設計特殊的零知識規則,如矩陣乘法和捲積層,以便實現這些計算的子線性時間高效協定。
- 像 groth16 這樣的通用 zkSNARK 系統可能無法有效處理神經網路,因為計算負載過大。
- 自 2020 年以來,許多新的 ZK 證明系統應運而生,以優化模型推理過程的 ZK 證明,包括 vCNN、ZEN、ZKCNN 和 pvCNN。 然而,它們中的大多數都針對 CNN 模型進行了優化。 它們只能應用於一些主要的數據集,如 MNIST 或 CIFAR-10。
- 2022 年,Daniel Kang Tatsunori Hashimoto、Ion Stoica 和 Yi Sun(Axiom 創始人)提出了一種基於 Halo2 的新證明方案,首次實現了對 ImageNet 數據集的 ZK 證明生成。 他們的優化主要集中在算術化部分,具有用於非線性的新穎查找參數和跨層重用子電路。
- Modulus Labs 正在為鏈上推理對不同證明系統進行基準測試,發現在證明時間方面,ZKCNN 和 plonky2 表現最佳; 在峰值證明者記憶體使用方面,ZKCNN 和 halo2 表現良好; 而 plonky 雖然表現良好,但犧牲了記憶體消耗,而且 ZKCNN 僅適用於 CNN 模型。 它還正在開發一個專門為 ZKML 設計的新 zkSNARK 系統,以及一個新的虛擬機。
- 驗證證明:驗證者使用驗證密鑰進行驗證,無需知道見證人的知識。

因此,我們可以證明將零知識技術應用於機器學習模型可以解決很多信任問題。 使用互動式驗證的類似技術可以達到類似的效果,但會在驗證者方面需要更多資源,並可能面臨更多的隱私問題。 值得注意的是,根據具體的模型,為它們生成證明可能需要時間和資源,因此在將此技術最終應用於現實世界的用例時,各方面將存在折衷。
當前解決方案的現狀
接下來,現有的解決方案是什麼? 請注意,模型提供者可能有很多不想生成 ZKML 證明的原因。 對於那些勇敢嘗試 ZKML 並且解決方案有意義的人,他們可以根據模型和輸入所在的位置選擇幾種不同的解決方案:
- 如果輸入數據在鏈上,可以考慮使用 Axiom 作為解決方案:
- Axiom 正在為乙太坊構建一個零知識協處理器,以改善使用者對區塊鏈數據的訪問並提供更複雜數位化的鏈上數據視圖。 在鏈上資料上進行可靠的機器學習計算是可行的:
- 首先,Axiom 通過在其智慧合約 AxiomV0 中存儲乙太坊區塊哈希的默克爾根來導入鏈上數據,這些數據通過 ZK-SNARK 驗證過程進行無信任驗證。 然後,AxiomV0StoragePf 合約允許對 AxiomV0 中緩存的區塊哈希給出的信任根進行任意歷史乙太坊存儲證明的批量驗證。
- 接下來,可以從導入的歷史數據中提取機器學習輸入數據。
- 然後,Axiom 可以在頂部應用經過驗證的機器學習操作; 使用經過優化的 halo2 作為後端來驗證每個計算部分的有效性。
- 最後,Axiom 會附上每個查詢結果的 zk 證明,並且 Axiom 智慧合約會驗證 zk 證明。 任何想要證明的相關方都可以從智慧合約中訪問它。
- 如果將模型放在鏈上,可以考慮使用 RISC Zero 作為解決方案:
通過在 RISC Zero 的 ZKVM 中運行機器學習模型,可以證明模型涉及的確切計算是正確執行的。 計算和驗證過程可以在用戶喜歡的環境中離線完成,或者在 Bonsai Network 中完成,Bonsai Network 是一個通用的 roll-up。
- 首先,需要將模型的原始程式碼編譯成 RISC-V 二進位檔。 當這個二進位檔在 ZKVM 中執行時,輸出會與一個包含加密密封的計算收據配對。 這個密封作為計算完整性的零知識論據,將加密的 imageID(識別執行的 RISC-V 二進位檔)與聲明的代碼輸出關聯起來,以便第三方快速驗證。
- 當模型在 ZKVM 中執行時,關於狀態更改的計算完全在 VM 內部完成。 它不會向外部洩露有關模型內部狀態的任何資訊。
- 一旦模型執行完畢,生成的密封就成為計算完整性的零知識證明。 RISC Zero ZKVM 是一個 RISC-V 虛擬機,它可以生成對其執行的代碼的零知識證明。 使用 ZKVM,可以生成一個加密收據,任何人都可以驗證這個收據是由 ZKVM 的客戶代碼生成的。 發佈收據時,不會洩露有關代碼執行的其他資訊(例如,所提供的輸入)。
生成 ZK 證明的具體過程涉及到一個與隨機 oracle 作為驗證者的交互協定。 RISC Zero 收據上的密封本質上就是這個交互協議的記錄。
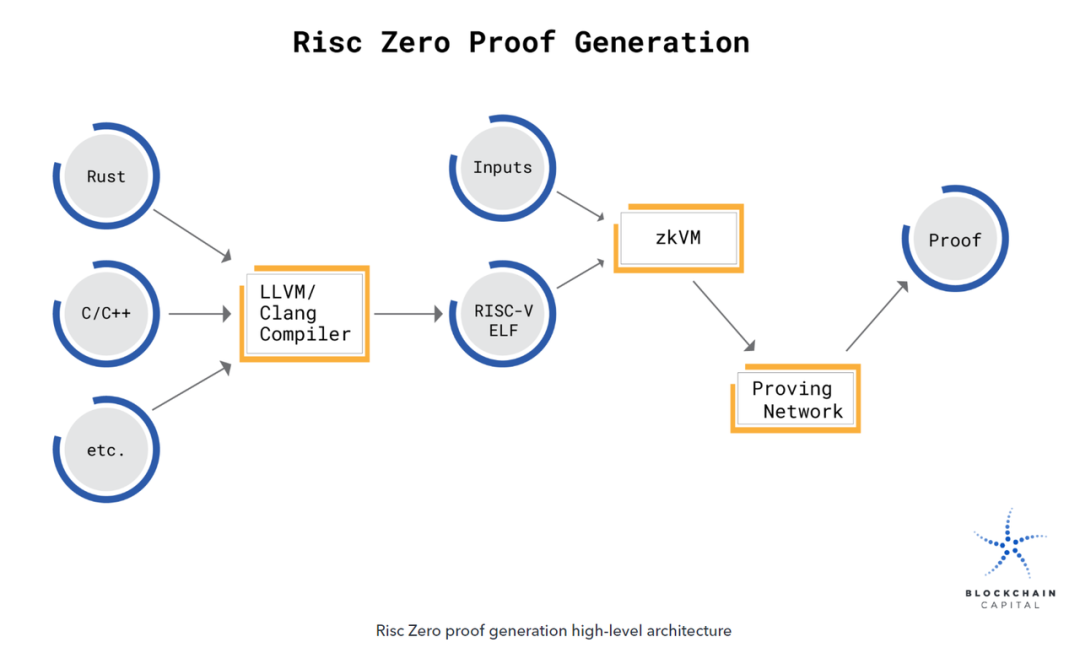
- 如果您想直接從常用的機器學習軟體(如 Tensorflow 或 Pytorch)導入模型,可以考慮使用 ezkl 作為解決方案:
Ezkl 是一個庫和命令行工具,用於在 zkSNARK 中進行深度學習模型和其他計算圖的推斷。
- 首先,將最終模型導出為 .onnx 檔,將一些樣本輸入匯出為 .json 檔。
- 然後,將 ezkl 指向 .onnx 和 .json 檔,以生成可以證明 ZKML 語句的 ZK-SNARK 電路。
看起來簡單,對吧? Ezkl 的目標是提供一個抽象層,允許在 Halo 2 電路中調用和佈局高級操作。 Ezkl 抽象了許多複雜性,同時保持了令人難以置信的靈活性。 他們的量化模型具有自動量化的縮放因數。 他們支持靈活地更改為新解決方案所涉及的其他證明系統。 他們還支援多種類型的虛擬機,包括 EVM 和 WASM。
關於證明系統,ezkl 通過聚合證明(通過仲介將難以驗證的證明轉換為易於驗證的證明)和遞歸(可以解決記憶體問題,但難以適應 halo2)來定製 halo2 電路。 Ezkl 還通過融合和抽象(可以通過高級證明減少開銷)來優化整個過程。
- 值得注意的是,與其他通用 zkml 專案相比,Accessor Labs 專注於為完全上鏈遊戲提供專門設計的 zkml 工具,可能涉及 AI NPC、遊戲玩法的自動更新、涉及自然語言的遊戲介面等。
用例在哪裡
通過 ZK 技術解決機器學習的信任問題意味著它現在可以應用於更多「高風險」和「高度確定性」的用例,而不僅僅是與人們的對話保持同步或將貓的圖片與狗的圖片區分開來。 Web3 已經在探索許多這樣的用例。 這並非巧合,因為大多數 Web3 應用程式都在區塊鏈上運行或打算在區塊鏈上運行,這是因為區塊鏈具有特定的特性,可以安全運行,難以篡改,並具有確定性計算。 一個可驗證的行為良好的 AI 應該是能夠在無信任和去中心化的環境中進行活動的 AI,對吧?

Web3 中可應用 ZK+ML 的用例
許多 Web3 應用為了安全性和去中心化而犧牲了用戶體驗,因為這顯然是它們的優先事項,而基礎設施的局限性也存在。 AI/ML 有潛力豐富用戶體驗,這無疑是有説明的,但以前在不妥協的情況下似乎是不可能的。 現在,多虧了 ZK,我們可以舒適地看到 AI/ML 與 Web3 應用的結合,而不會在安全性和去中心化方面做太多犧牲。
從本質上講,這將是一個 Web3 應用程式(在撰寫本文時可能存在或不存在),以無需信任的方式實現 ML/AI。 在無需信任的方式下,我們指的是它是否在無需信任的環境/平台上運行,或者其操作是否可以被證明是可驗證的。 請注意,並非所有 ML/AI 用例(即使在 Web3 中)都需要或更喜歡以無需信任的方式運行。 我們將分析在各種 Web3 領域中使用的 ML 功能的每個部分。 然後,我們將確定需要 ZKML 的部分,通常是人們願意為證明支付額外費用的高價值部分。 下面提到的大多數用例/應用仍處於實驗研究階段。 因此,它們距離實際採用還很遙遠。 我們稍後會討論原因。
Defi
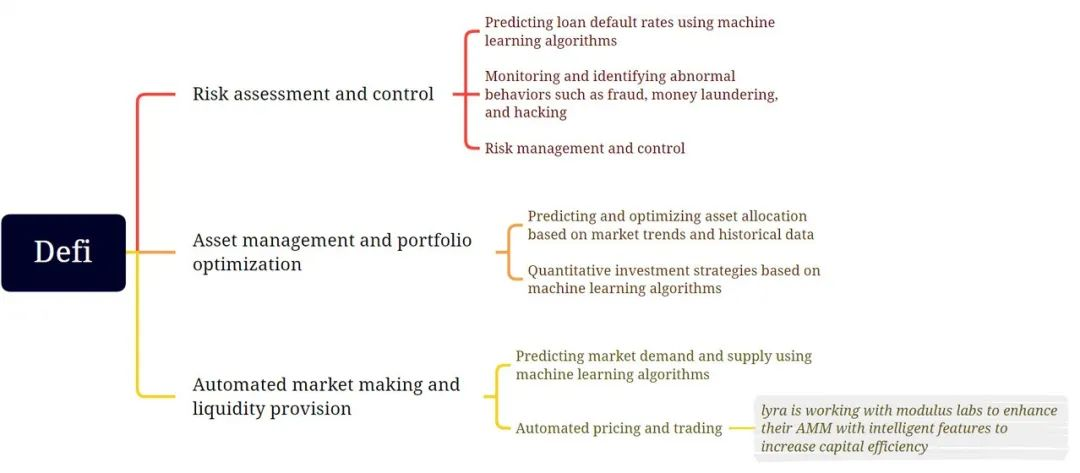
Defi 是區塊鏈協定和 Web3 應用中為數不多的產品市場契合度證明之一。 以無需許可的方式創建、存儲和管理財富和資本在人類歷史上是前所未有的。 我們已經確定了許多需要 AI/ML 模型無需許可地運行以確保安全性和去中心化的用例。
- 風險評估:現代金融需要 AI/ML 模型進行各種風險評估,從防止欺詐和洗錢到發放無擔保貸款。 確保這種 AI/ML 模型以可驗證的方式運行意味著我們可以防止它們被操縱以實現審查制度,從而阻礙使用 Defi 產品的無需許可的性質。
- 資產管理:自動交易策略對於傳統金融和 Defi 來說並不新鮮。 已經有人嘗試應用 AI/ML 生成的交易策略,但只有少數去中心化的策略取得了成功。 目前 Defi 領域的典型應用包括 Modulus Labs 實驗的 Rocky Bot。
- Rocky Bot:Modulus Labs 在 StarkNet 上使用 AI 進行決策創建了一個交易機器人。
一個在 L1 上持有資金並在 Uniswap 上交換 WEth / USDC 的合約。
這適用於 ML 信任框架的「輸出」部分。 輸出是在 L2 上生成的,傳輸到 L1,並用於執行。 在此過程中,不會被篡改。
- 一個 L2 合約實現了一個簡單(但靈活)的三層神經網路,用於預測未來的 WEth 價格。 合約使用歷史 WETH 價格資訊作為輸入。
- 這適用於「輸入」和「模型」部分。 歷史價格信息輸入來自區塊鏈。 模型的執行是在 CairoVM(一種 ZKVM)中計算的,其執行跟蹤將生成一個用於驗證的 ZK 證明。
- 一個簡單的前端用於可視化以及用於訓練回歸器和分類器的 PyTorch 代碼。
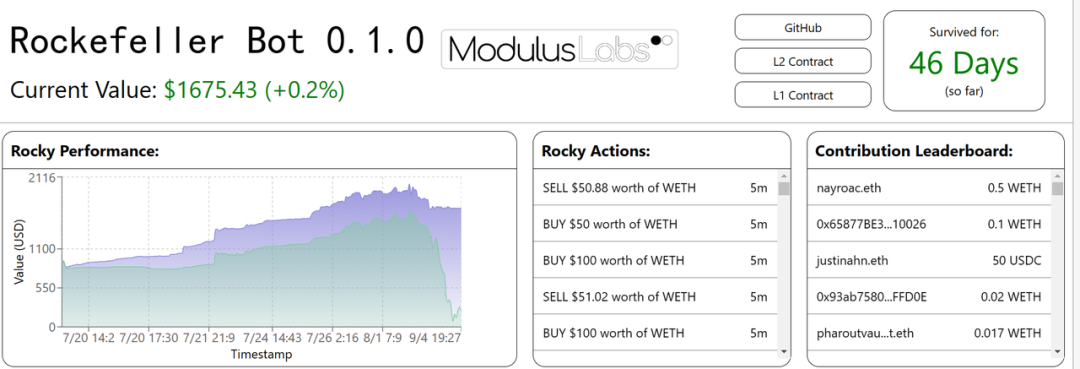
- Automated MM and liquidity provision: 本質上,這是風險評估和資產管理中進行的類似努力的結合,只是在交易量、時間線和資產類型方面採用了不同的方式。 關於如何在股票市場中使用 ML 進行做市的研究論文有很多。 在一些研究成果適用於 Defi 產品可能只是時間問題。
- 例如,Lyra Finance 正與 Modulus Labs 合作,通過智慧功能提升其 AMM,使其資本利用效率更高。
- 榮譽提名:
- Warp.cc 團隊開發了一個教程專案,介紹如何部署一個運行訓練好的神經網路以預測比特幣價格的智能合約。 這符合我們框架的「輸入」和「模型」部分,因為輸入使用 RedStone Oracles 提供的數據,模型作為一個 Warp 智慧合約在 Arweave 上執行。
- 這是第一次反覆運算並涉及 ZK,所以它屬於我們的榮譽提名,但是在未來,Warp 團隊考慮實現一個 ZK 部分。
遊戲

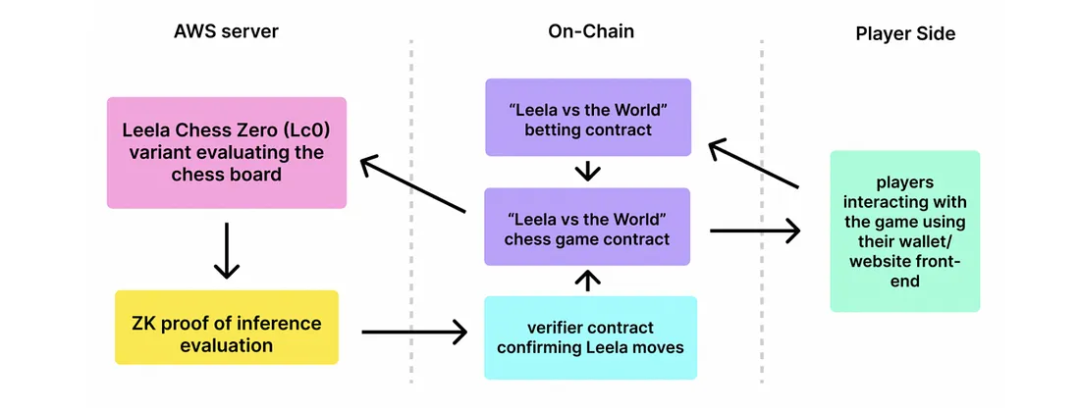
遊戲與機器學習有很多交集:圖中的灰色區域代表了我們對遊戲部分中的機器學習功能是否需要與相應的 ZKML 證明配對的初步評估。 Leela Chess Zero 是將 ZKML 應用於遊戲的一個非常有趣的例子:
- AI 代理
Leela Chess Zero(LC0):由 Modulus Labs 構建的一款完全基於鏈上的 AI 棋手,與來自社區的一群人類玩家對戰。
- LC0 和人類集體輪流進行遊戲(正如象棋中應有的那樣)。
- LC0 的行動是透過簡化的、適合電路的 LC0 模型計算出來的。
LC0 的移動有一個 Halo2 snark 證明,以確保沒有人類智囊團的干預。 只有簡化的 LC0 模型在那裡做決策。
這符合「模型」部分。 模型的執行有一個 ZK 證明,以驗證計算沒有被篡改。
- 數據分析與預測:這一直是 Web2 遊戲世界中 AI/ML 的常見用途。 然而,我們發現在這個 ML 過程中實現 ZK 的理由非常少。 為了不讓過多的價值直接涉及到這個過程,這可能不值得付出努力。 然而,如果某些分析和預測被用來為用戶確定獎勵,那麼 ZK 可能會被實施以確保結果是正確的。
- 榮譽提名:
- AI Arena 是一款乙太坊原生遊戲,來自世界各地的玩家可以在其中設計、訓練和戰鬥由人工神經網路驅動的 NFT 角色。 來自世界各地的才華橫溢的研究人員競相創建最佳機器學習(ML)模型來參與遊戲戰鬥。 AI Arena 主要關注前饋神經網路。 總體而言,它們的計算開銷比卷積神經網路(CNNs)或迴圈神經網路(RNNs)低。 儘管如此,目前模型只在訓練完成後上傳到平臺,因此值得一提。
- GiroGiro.AI 正在構建一個 AI 工具包,使大眾能夠為個人或商業用途創建人工智慧。 用戶可以根據直觀且自動化的 AI 工作流平臺創建各種類型的 AI 系統。 只需輸入少量數據和選擇演算法(或用於改進的模型),使用者就可以生成並利用心中的 AI 模型。 儘管該項目處於非常早期階段,但我們非常期待看到 GiroGiro 可以為遊戲金融和元宇宙為重點的產品帶來什麼,因此將其列為榮譽提名。
DID 和社交
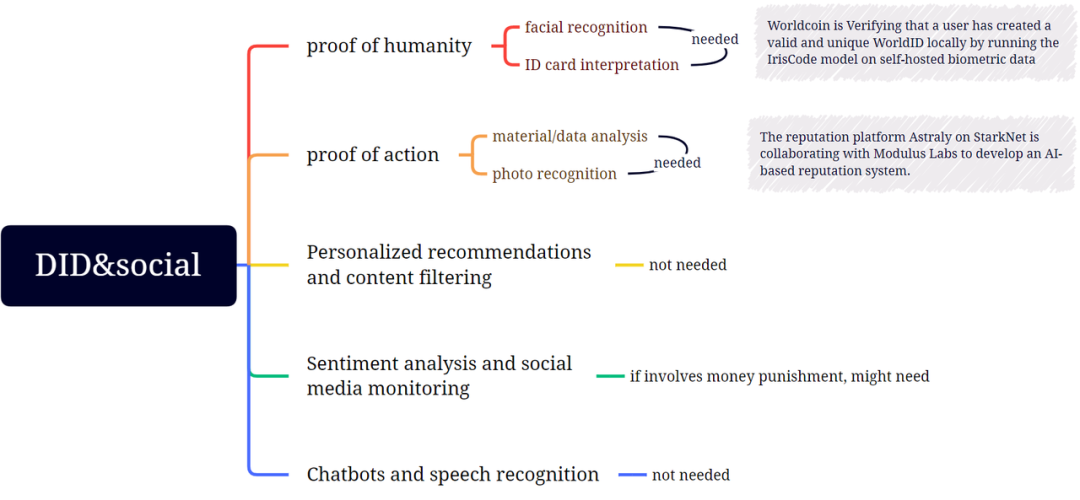
在 DID 和社交領域,Web3 和 ML 的交叉點目前主要體現在人類證明和憑據證明領域; 其他部分可能會發展,但需要更長的時間。
- 人類證明
Worldcoin 使用一種名為 Orb 的設備來判斷某人是否是一個真實存在的人,而不是試圖欺詐驗證。 它通過各種攝像頭感測器和機器學習模型分析面部和虹膜特徵來實現這一目標。 一旦做出這個判斷,Orb 就會拍攝一組人的虹膜照片,並使用多個機器學習模型和其他計算機視覺技術創建虹膜編碼,這是一個表示個體虹膜圖案最重要特徵的數位表示。 具體的註冊步驟如下:
- 用戶在手機上生成一個 Semaphore 金鑰對,並通過二維碼向 Orb 提供哈希後的公鑰。
- Orb 掃描使用者的虹膜並在本地計算使用者的 IrisHash。 然後,它將包含哈希公鑰和 IrisHash 的簽名訊息發送到註冊順序節點。
- 順序節點驗證 Orb 的簽名,然後檢查 IrisHash 是否與資料庫中已有的匹配。 如果唯一性檢查通過,IrisHash 和公鑰將被保存。
Worldcoin 使用開源的 Semaphore 零知識證明系統將 IrisHash 的唯一性轉換為用戶帳戶的唯一性,而不會將它們關聯起來。 這確保新註冊的使用者可以成功領取他/她的 WorldCoins。 步驟如下:
- 使用者的應用程式在本地生成一個錢包位址。
- 應用程式使用 Semaphore 證明它擁有之前註冊的一個公鑰的私鑰。 因為這是零知識證明,所以它不會透露是哪個公鑰。
- 证明再次发送到顺序器,顺序器验证证明并启动将代币存入提供的钱包地址的过程。所谓的零件随证明一起发送,确保用户不能领取两次奖励。
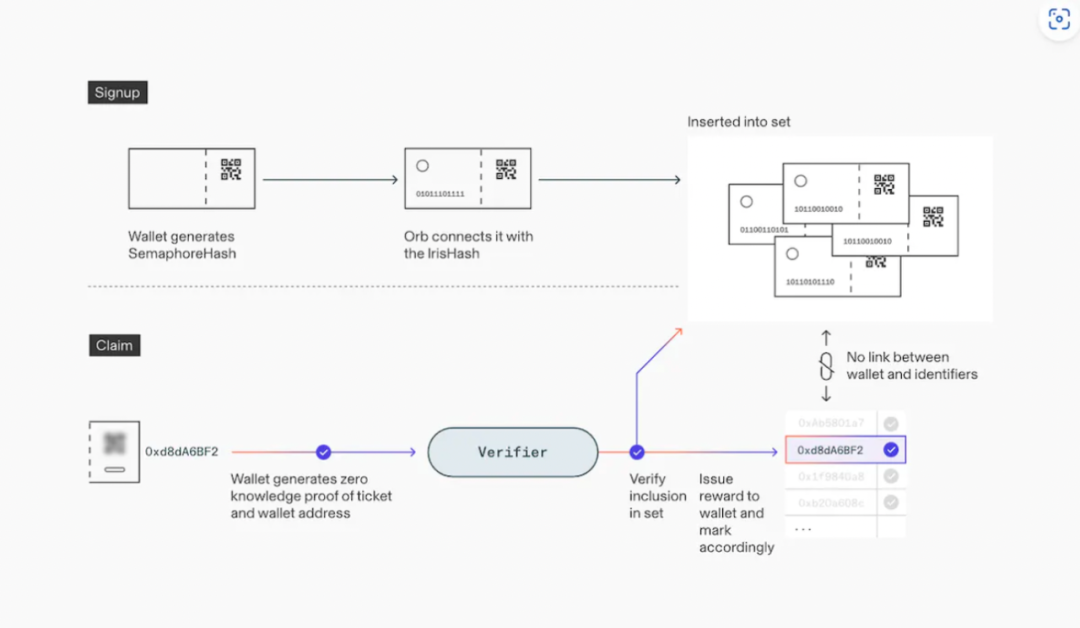
WorldCoin 使用 ZK 技術確保其 ML 模型的輸出不會洩露使用者的個人數據,因為它們之間沒有關聯。 在這種情況下,它屬於我們信任框架的「輸出」部分,因為它確保了輸出以期望的方式傳輸和使用,在這種情況下是私密的。
- 行動證明
Astraly 是 StarkNet 上一個基於信譽的代幣發行平臺,用於尋找和支援最新、最棒的 StarkNet 專案。 衡量聲譽是一項具有挑戰性的任務,因為它是一個抽象的概念,無法用簡單的指標輕易量化。 在處理複雜的指標時,更全面、更多樣化的輸入往往能產生更好的結果。 這就是 Astraly 尋求 Modulus Labs 説明,使用 ML 模型提供更準確聲譽評級的原因。
- 個性化推薦和內容過濾
Twitter 最近開源了「為你」(For You)時間軸的演算法,但使用者無法驗證演算法是否正確運行,因為用於推文排名的 ML 模型的權重是保密的。 這引起了人們對偏見和審查的擔憂。
然而,Daniel Kang、Edward Gan、Ion Stoica 和 Yi Sun 使用 ezkl 提供了一種解決方案,通過在不透露模型權重的情況下證明 Twitter 演演算法的真實運行,説明平衡隱私和透明度。 通過使用 ZKML 框架,Twitter 可以對其排名模型的特定版本做出承諾,併發佈證明,證明它為給定使用者和推文生成了特定的最終輸出排名。 這一解決方案使用戶能夠驗證計算是否正確,而無需信任系統。 雖然要使 ZKML 更為實用還有很多工作要做,但這是向提高社交媒體透明度邁出的積極一步。 因此,這屬於我們的 ML 信任框架的「模型」部分。
從用例角度重新審視 ML 信任框架
可以看到,Web3 中 ZKML 的潛在用例尚處於起步階段,但不能被忽視; 未來,隨著 ZKML 使用的不斷擴大,可能會出現對 ZKML 供應商的需求,形成下圖中的閉環:
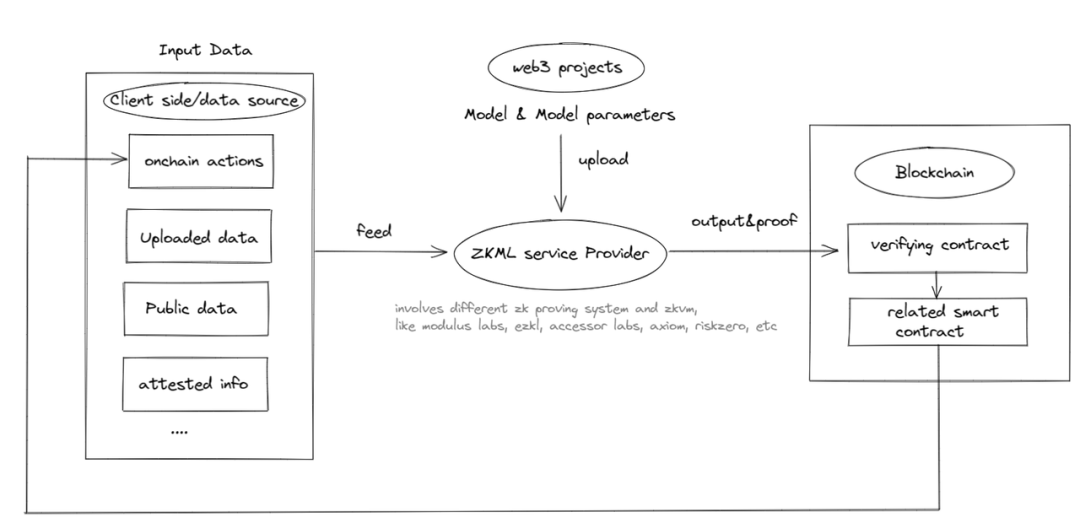
ZKML 服務提供者主要關注 ML 信任框架的「模型」和「參數」部分。 儘管我們現在看到的大部分與「參數」相關的更多是「模型」相關。 需要注意的是,「輸入」和「輸出」部分更多地由基於區塊鏈的解決方案解決,無論是作為數據來源還是數據目的地。 單獨使用 ZK 或區塊鏈可能無法實現完全的可信度,但它們聯合起來可能會實現。
大規模應用還有多遠?
最後,我們可以關注一下 ZKML 的當前可行性狀態,以及我們離 ZKML 大規模應用還有多遠。
Modulus Labs 的論文通過測試 Worldcoin(具有嚴格的精度和記憶體要求)和 AI Arena(具有成本效益和時間要求)為我們提供了一些關於 ZKML 應用可行性的數據和見解:
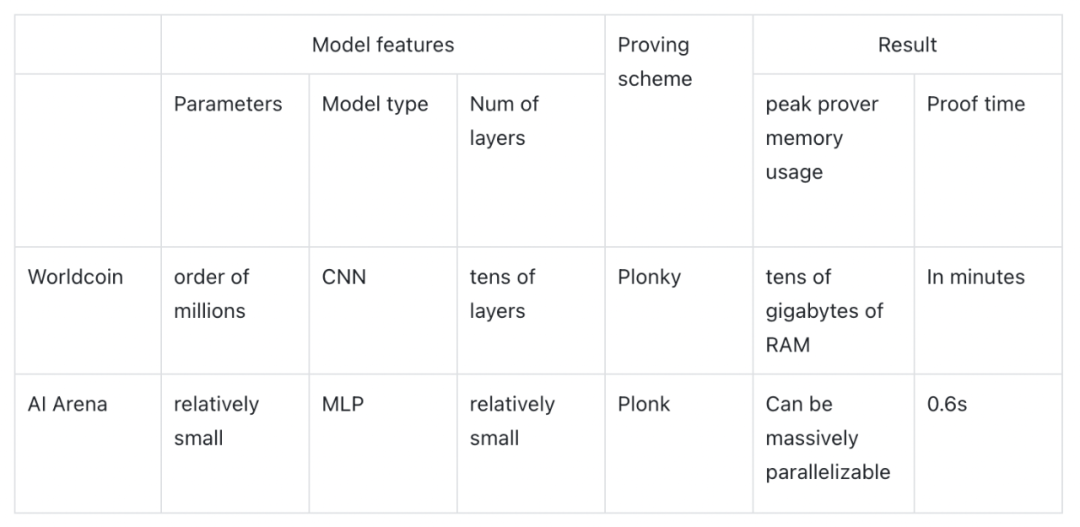
如果 Worldcon 使用 ZKML,證明者的記憶體消耗將超過任何商用行動硬體的承受能力。 如果 AI Arena 的比賽使用 ZKML,使用 ZKCNNs 將使時間和成本增加 100 倍(0.6s 對比原來的 0.008s)。 所以遺憾的是,這兩者都不適合直接應用 ZKML 技術來證明時間和證明者記憶體使用。
那麼證明大小和驗證時間呢? 我們可以參考 Daniel Kang、Tatsunori Hashimoto、Ion Stoica 和 Yi Sun 的論文。 如下所示,他們的 DNN 推理解決方案在 ImageNet(模型類型:DCNN,16 層,3.4 百萬參數)上的準確率可以達到 79%,同時驗證時間僅需 10 秒,證明大小為 5952 位元組。 此外,zkSNARKs 可以縮小到 59% 準確率時驗證時間僅需 0.7 秒。 這些結果表明,在證明大小和驗證時間方面,對 ImageNet 規模的模型進行 zkSNARKing 是可行的。

目前主要的技術瓶頸在於證明時間和記憶體消耗。 在 web3 案例中應用 ZKML 在技術上尚不可行。 ZKML 是否有潛力趕上 AI 的發展呢? 我們可以比較幾個經驗數據:
- 機器學習模型的發展速度:2019 年發佈的 GPT-1 模型具有 1.5 億個參數,而 2020 年發佈的最新 GPT-3 模型具有 1,750 億個參數,僅兩年間參數數量增加了 1,166 倍。
- 零知識系統的優化速度:零知識系統的性能增長基本上遵循「摩爾定律」式的步伐。 幾乎每年都會出現新的零知識系統,我們預計證明者性能的快速增長在一段時間內還將繼續。
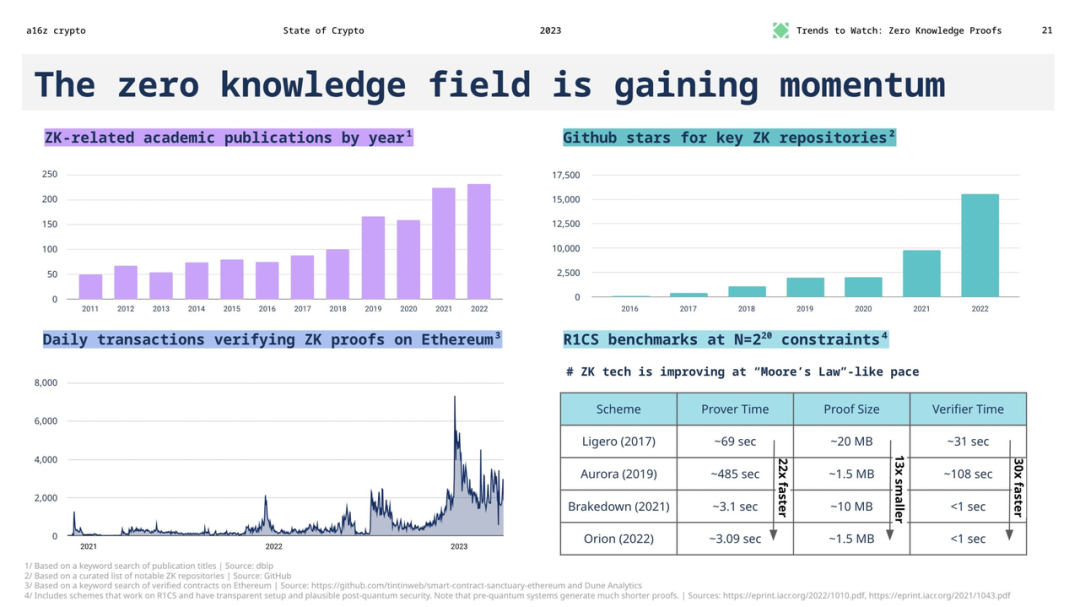
從這些數據來看,儘管機器學習模型的發展速度非常快,但零知識證明系統的優化速度也在穩步提升。 在未來一段時間內,ZKML 可能仍有機會逐步趕上 AI 的發展,但它需要不斷地進行技術創新和優化以縮小差距。 這意味著,儘管目前 ZKML 在 web3 應用中存在技術瓶頸,但隨著零知識證明技術的不斷發展,我們仍有理由期待 ZKML 在未來能夠在 web3 場景中發揮更大的作用。
對比前沿的 ML 與 ZK 的改進率,前景並不十分樂觀。 不過,隨著捲積性能、ZK 硬體的不斷完善,以及基於高度結構化的神經網路操作而量身定做的 ZK 證明系統,希望 ZKML 的發展能夠滿足 web3 的需求,先從提供一些老式的機器學習功能開始。
雖然我們可能很難用區塊鏈+ZK 來驗證 ChatGPT 反饋給我的資訊是否可信,但我們也許可以在 ZK 電路中安裝一些較小和較老的 ML 模型。
結論
“ 權力趨於腐敗,而絕對的權力會使人絕對腐敗” 隨著人工智慧和 ML 的令人難以置信的力量,目前還沒有萬無一失的方法將其置於治理之下。 事實一再證明,政府要麼提供後期干預的後遺症,要麼提前徹底禁止。 區塊鏈+ZK 提供了為數不多的解決方案,能夠以一種可證明和可核實的方式馴服野獸。 我們期待在 ZKML 領域看到更多的產品創新,ZK 和區塊鏈為 AI/ML 的運行提供了一個安全和值得信賴的環境。 我們也期待這些產品創新產生全新的商業模式,因為在無許可的加密貨幣世界里,我們不受這裡的去 SaaS 商業化模式的限制。 我們期待著支援更多的建設者,在這個「西部荒野無政府狀態」和「象牙塔精英」的迷人重疊中,來建立他們令人興奮的想法。
我們仍處於早期階段,但我們可能已經在拯救世界的路上。
END
免責聲明:作為區塊鏈資訊平臺,本站所發佈文章僅代表作者及嘉賓個人觀點,與 Web3Caff 立場無關。 文章內的資訊僅供參考,均不構成任何投資建議及要約,並請您遵守所在國家或地區的相關法律法規。










