ZK coprocessor 使区块链可以在不伤害去中心化的情况下以较低成本的方式让智能合约抓取更多数据,获取链下的计算资源,同时解藕了智能合约的工作流,增加了可拓展性和效率。
作者:Mike@Foresight Ventures
封面:Photo by Shubham Dhage on Unsplash

一、概念介绍
关于协处理器这个概念,一个很浅显易懂的例子就是电脑和显卡的关系,CPU 可以完成大部分任务,但是一旦遇到特定任务,就需要显卡的帮助,因为 CPU 算力不够,比如说机器学习,图形渲染,或者是大型游戏的运行,我们玩大型游戏的时候如果不想掉帧或者卡顿,那肯定就需要一块性能很好的显卡。那在这个场景中,CPU 就是处理器,显卡就是协处理器。映射到区块链上,智能合约就是 CPU,ZK 协处理器就是 GPU。
关键点就是把特定任务交给特定的协处理器做,就像一个工厂里,老板知道每个环节的步骤,也可以自己做,也可以教员工整个生产过程,但是这样效率就很低,只能一个一个生产,一个生产完了才能生产下一个,于是他雇了很多特定的员工,他们各司其职,在自己的车间做着生产链条上自己擅长的工作,链条的环节之间可以互相进行通信协同但互不干涉对方的工作,只做自己最擅长的事,手速快体力好的就打螺丝,懂操作机器的就去操作机器,懂财会的就去计算生产量和成本,异步协同工作从而最大化工作效率。
在工业革命的时候,资本家们就已经发现这种模式能给自己的工厂带来最大的产能,但可能因为技术或者别的原因,生产环节中的一步遇到壁垒的时候,可能要外包别的专门的生产商去做,比如说一个生产手机的公司,芯片可能由别的专门的芯片公司生产,手机公司就是中央处理器,芯片公司就是协处理器。协处理器能够轻松异步处理中央处理器自身难以处理的壁垒较大和繁琐的特定任务。

ZK 协处理器广义上比较宽泛,有的项目叫自己协处理器,有的叫 ZKVM,但是都是同一个思路:允许智能合约开发者在现有的数据上无状态地证明链下计算。简单来说就是把一些链上计算的工作丢到链下,降本增效,同时用 ZK 保证计算的可靠性,并保护特定数据的隐私。在数据驱动的区块链世界里,这显得尤为重要。
二、为什么我们需要 ZK 协处理器
智能合约开发者面临的最大瓶颈之一仍然是与链上计算相关的高昂成本。由于每次操作都要计量 Gas,因此复杂应用逻辑的成本很快就会变得高到没法执行,因为区块链的 DA 层中的存档节点虽然确实能够存储历史数据,这也是为什么像 Dune Analytics,Nansen,0xscope,Etherscan 这些链外分析应用能有那么多来自区块链上的数据,并且可以追溯到很久以前,但对于智能合约来说要访问所有的这些数据并不简单,它只能够轻松访问虚拟机状态中储存的数据,最新的区块数据,以及其他公开的智能合约的数据。对于更多的数据,智能合约可能要耗费很大的功夫去访问:
智能合约在以太坊虚拟机(EVM)中能够访问最近的 256 个区块的区块头哈希值。这些区块头包含了区块链中直到当前区块为止的所有活动信息,并通过默克尔树和 Keccak 哈希算法被压缩成了 32 字节的哈希值。
虽然这些数据被哈希打包过了,但其实它们是可以解压的——只是这并不容易实现。例如,如果你想利用最近的区块头来无需信任地访问上一个区块中的特定数据,这涉及一系列复杂的步骤。首先,你需要从存档节点获取链外数据,然后构建一个默克尔树和区块的有效性证明,以验证该数据在区块链上的真实性。随后,EVM 会处理这些有效性证明,进行验证和解释,这种操作不仅繁琐而且时间长,Gas 还特别贵。
这个挑战的根本原因在于,区块链虚拟机(如 EVM)本身并不适合处理大量数据和密集型计算任务,比如上述的解压缩工作。EVM 的设计重点是在保证安全和去中心化的同时,执行智能合约代码,而非处理大规模数据或进行复杂的计算任务。因此,当涉及到需要大量计算资源的任务时,通常需要寻找其他解决方案,比如利用链下计算或其他扩展技术,这时候,ZK 协处理器应运而生。

ZK rollups 其实就是最早的 ZK 协处理器,以更大的规模和数量支持在 L1 上使用的同类型计算。这个处理器是协议层面上的,现在我们说的 ZK 协处理器是 dapp 层面上的。ZK 协处理器通过允许智能合约使用 ZK 证明无信任地委托历史性链上数据访问和计算来增强智能合约的可拓展性。开发者可以将昂贵的操作转移到 ZK 协处理器上,并简单地使用链上的结果,而不是在 EVM 中执行所有操作。通过将数据访问和计算与区块链共识解耦,这为智能合约提供了一种新的扩展方式。

ZK 协处理器为链上应用引入了一种新的设计模式,消除了计算必须在区块链虚拟机中完成的限制。这使得应用程序在控制 gas 成本的情况下可以访问更多数据,并以比以前更大的规模运行,在不损害去中心化和安全性的情况下增加了智能合约的可扩展性和效率。
三、技术实现
这个部分将以 Axiom 的架构诠释技术上 zk coprocessor 是怎么解决问题的。其实就是两个核心:数据抓取和计算。在这两个过程中,ZK 同时保障了效率和隐私。
3.1 数据抓取
在 ZK 协处理器上执行计算最重要的一个方面是确保从区块链历史中正确访问所有输入数据。 前文有提到过其实这挺难的,因为智能合约只能在其代码中访问当前的区块链状态,而即使是这种访问也是链上计算中最昂贵的部分。这意味着交易记录或以前的余额等历史性链上数据(计算中有趣的链上输入)无法被智能合约本地使用,以验证协处理器的结果。
ZK 协处理器通过三种不同的方式来解决这个问题,在成本、安全性和开发难度之间进行权衡:
- 在区块链状态中存储额外数据,并使用 EVM 存储读取验证协处理器在链上使用的所有数据。 这种方法相当昂贵,对于海量数据来说成本过高。
- 信任 Oracle 或签名者网络来验证协处理器的输入数据。 这要求协处理器用户信任 Oracle 或多重签名提供者,但这样降低了安全性。
- 使用 ZK 证明来检查协处理器中使用的任何链上数据是否在区块链历史中得到了承诺。区块链中的任何区块都会提交所有过去的区块,因此会提交任何历史数据,从而为数据有效性提供加密保证,并且不需要用户提供额外的信任假设。
3.2 计算
在 ZK 协处理器中执行链下计算需要将传统计算机程序转化为 ZK 电路。目前,所有实现这一目的的方法都会对性能产生巨大影响,与本地程序执行相比,ZK 证明的开销从 10,000 到 1,000,000 不等。另一方面,ZK 电路的计算模型与标准计算机体系结构不同(比如,目前所有变量都必须以一个大的加密质数为模数来编码,而且执行可能是非确定性的),这意味着开发人员很难直接编写它们。
因此,在 ZK 协处理器中指定计算的三种主要方法主要是在性能、灵活性和开发难度之间进行权衡,:
- 自定义电路: 开发人员为每个应用编写自己的电路。 这种方法具有最大的性能潜力,但需要开发人员投入大量精力。
- 电路的 eDSL / DSL: 开发人员为每个应用编写电路,但要在一个有主见的框架中抽象出 ZK 特有的问题(类似于使用 PyTorch 处理神经网络)。但这样性能就稍微低一些。
- zkVM 开发人员在现有虚拟机中编写电路,并在 ZK 中验证其执行。在使用现有虚拟机时,这为开发人员提供了最简单的体验,但由于虚拟机和 ZK 之间的计算模型不同,这样性能和灵活性都比较低。
四、应用
ZK 协处理器的应用非常广泛,Dapp 能覆盖到的所有应用场景 ZK 协处理器理论上来说都能覆盖到。只要是跟数据和计算相关的任务,ZK 协处理器都能起到降本增效、保护隐私的作用,以下将从不同的赛道出发,探讨 ZK 处理器能在应用层具体做些什么。
4.1 Defi
4.1.1 DEX
以 Uniswap V4 里的 hook 来举例:
Hook 允许开发者在流动性池的整个生命周期中的任意关键点执行指定的操作——例如在交易代币之前或之后,或者在 LP 头寸更改之前或之后,自定义流动性池、兑换、费用和 LP 头寸之间的交互方式,比如说:
- 时间加权平均做市商(TWAMM);
- 基于波动性或其他投入的动态费用;
- 链上限价订单;
- 将超出范围的流动性存入借贷协议;
- 定制化的链上预言机,例如几何平均数预言机;
- 自动复利 LP 手续费到 LP 头寸;
- Uniswap 的 MEV 利润分配给 LP;
- LP 或者交易员的忠诚度折扣计划;
简单来说就是可以让开发者根据自己的想法,抓取任意链上历史数据并用来自定义 Uniswap 里的池子的机制,Hook 的出现给链上的交易带来更多的可组合性,和更高的资本效率。然而,定义这些的代码逻辑一旦复杂起来,就会给用户和开发者带来极大的 gas 负担,那么这个时候 zkcoprocessor 就派上用场了,它可以帮助省去这些 gas 费用,又提高了效率。
从更长远的视角来看,ZK 协处理器将加速 DEX 和 CEX 的融合,自 2022 年以来,我们看到 DEX 和 CEX 在功能上趋于一致,各大 CEX 都在接受这一现实,并采用 Web3 钱包、构建 EVM L2 并采用闪电网络等现有基础设施或开源来拥抱链上的流动性份额。这种现象的背后离不开 ZK 协处理器的助推,CEX 能实现的所有功能,无论是网格交易,跟单,快速借贷,还是用户数据的使用,DEX 也能通过 ZK 协处理器实现,而 Defi 的可组合性和自由度,以及链上小币种的交易,传统的 CEX 都难以实现,同时 ZK 技术还能在执行的同时保障用户的隐私。
4.1.2 空投
如果一些项目方想进行空投,那就需要智能合约查询地址的历史活动,但又不想暴露用户的地址信息,并在不引入额外信任证明的情况下执行,比如说一个做 Defi lending 的项目方想通过地址和 Aave,Compound,Fraxlend,Spark 一系列的借贷协议的交互量作为空投的标准,ZK 协处理器的抓取历史数据和隐私特性可以轻松的解决这个需求。
4.2 ZKML
ZK 协处理器另一个令人兴奋的点是在机器学习这块,既然可以赋予智能合约链下计算的能力,那么链上的高效率机器学习将成为可能,而事实上,ZK 协处理器确实也是目前 ZKML 数据的输入和计算不可或缺的板块,它可以智能合约中导入的链上/链下历史数据中提取机器学习需要的 input,然后把计算编写成 ZK 电路丢到链上。
4.3 KYC
KYC 是一个很大的生意,现在 web3 世界正在逐渐拥抱合规,有了 ZK 协处理器,就可以通过抓取用户提供的任何链下数据,做出一个智能合约可验证的证明,而不需要暴露用户的任何多余信息,事实上一些项目正在落地,比如说 Uniswap 的 KYC hook,就是采用了 ZK 协处理器 Pado 无信任地抓取链下数据。资产证明,学历证明,出行证明,驾驶证明,执法证明,玩家证明,交易证明……. 一切链上链下的历史行为,甚至可以打包成一个完整的身份,都可以写成可信度极强的 ZK 证明上链,同时保护用户隐私。
4.4 Social
Friend.tech 的投机属性其实要比社交属性更强,核心在于它的 bonding curve,那有没有可能也给 friend.tech 的 bonding curve 上一个 hook,让用户可以自定义 bonding curve 的走向,比如说实现在交易 key 的热潮结束,投机者离开之后,让 bonding curve 变得平滑,使真正的粉丝进入门槛变低,实现真正的私域流量的增长。又或是让智能合约获得用户的链上/链下的社交图谱,在不同的社交 Dapp 上都能够一键关注自己的好友。又或者在链上建立 private club,比如说 Degen club,达到历史 Gas 消耗条件的地址才能进入等等。
4.5 Gaming
在传统的 Web2 游戏中,用户数据是一个很重要的参数,购买行为,游戏风格以及贡献都可以让游戏更好的去运营,提供更好的用户体验,比如说 MOBA 游戏中的 ELO 匹配机制,对皮肤的购买频率等等,但在区块链上这些数据难以被智能合约抓取,所以只能用中心化的方案取代或者干脆直接放弃。但 ZK 协处理器的出现使得去中心化的方案成为可能。
五、项目方
这个赛道里已经有了一些佼佼者,思路其实都差不多,通过 storage proof 或者共识生成 ZK 证明然后丢到链上,但技术特点和实现的功能各有所长。
5.1 Axiom
Axiom 作为 ZK(零知识)协处理器的领导者,专注于智能合约能够无需信任地访问整个以太坊历史和任何 ZK 验证计算。开发者可以向 Axiom 提交链上查询,Axiom 随后通过 ZK 验证处理这些查询,并以无信任的方式将结果回传给开发者的智能合约。这使得开发者能够构建更丰富的链上应用程序,而无需依赖额外的信任假设。
为了实现这些查询,Axiom 执行以下三个步骤:
- 读取:Axiom 利用 ZK 证明,无需信任地从以太坊历史区块的区块头、状态、交易和收据中读取数据。由于所有以太坊链上数据都以这些格式编码,Axiom 因此能够访问存档节点能够访问的所有内容。Axiom 通过 Merkle-Patricia 三元组和区块头哈希链的 ZK 证明来验证 ZK 协处理器的所有输入数据。 虽然这种方法开发起来比较困难,但它能为最终用户提供最佳的安全性和成本,因为它能确保 Axiom 返回的所有结果在密码学上等同于 EVM 中进行的链上计算。
- 计算:数据摄取后,Axiom 在其上应用经过验证的计算。开发者可以在 JavaScript 前端指定他们的计算逻辑,每次计算的有效性都在 ZK 证明中得到验证。开发者可以访问 AxiomREPL 或查看文档,了解可用的计算原语。Axiom 通过 eDSL 允许用户访问链上数据并指定自己的计算。还允许用户使用 ZK 电路库编写自己的电路。
- 验证:Axiom 为每个查询结果提供 ZK 有效性证明,这些证明确保(1)输入数据是从链中正确提取的,(2)计算是正确应用的。这些 ZK 证明在 Axiom 智能合约中进行链上验证,确保最终结果在用户的智能合约中可靠使用。
由于结果是通过 ZK 证明验证的,Axiom 的结果在密码学上与以太坊的结果具有相同的安全性。这种方法不对加密经济学、激励机制或博弈论做任何假设。Axiom 相信这种方式将为智能合约应用提供尽可能高的保证水平。Axiom 团队和 Uniswap Foundation 密切合作,拿到了 Uniswap 的 Grants,将在 Uniswap 上打造无信任的预言机。
5.2 Risc Zero
Bonsai: 在 2023 年,RISC Zero 发布了 Bonsai,这是一个证明服务,允许链上和链下应用请求并接收 zkVM 证明。Bonsai 是一个通用的零知识证明服务,允许任何链、任何协议和任何应用利用 ZK 证明。它具有高度并行性,可编程性和高性能。
Bonsai 使你能够直接将零知识证明集成到任何智能合约中,无需定制电路。这使得 ZK 可以直接集成到任何 EVM 链上的去中心化应用程序中,有潜力支持任何其他生态系统。
zkVM 是 Bonsai 的基础,支持广泛的语言兼容性,支持可证明的 Rust 代码,以及潜在的任何编译到 RISC-V 的语言(如 C++、Rust、Go 等)的零知识可证明代码。通过递归证明、定制电路编译器、状态延续以及对证明算法的持续改进,Bonsai 使任何人都能为各种应用生成高性能的 ZK 证明。

RISC Zero zkVM: RISC Zero zkVM 首次发布于 2022 年 4 月,可以证明任意代码的正确执行,使开发者能够用成熟的语言如 Rust 和 C++构建 ZK 应用。这个发布是 ZK 软件开发的一个重大突破:zkVM 使得无需构建电路和使用定制语言就能构建 ZK 应用成为可能。
通过允许开发者使用 Rust 并利用 Rust 生态系统的成熟度,zkVM 使开发者能够快速构建有意义的 ZK 应用,无需有高级数学或密码学方面的背景。
这些应用包括:
- JSON:证明 JSON 文件中某个条目的内容,同时保持其他数据的私密性。
- Where's Waldo:证明 Waldo 出现在 JPG 文件中,同时保持图像的其他部分私密。
- ZK Checkmate:证明你看到一步将军,而不透露获胜的举动。
- ZK Proof of Exploit:证明你可以利用一个以太坊账户,而不透露漏洞。
- ECDSA 签名验证:证明 ECDSA 签名的有效性。
这些示例都是通过利用成熟的软件生态系统实现的:大部分 Rust 工具包在 Risc Zero zkVM 中开箱即用。能够兼容 Rust 对 ZK 软件世界来说是一个游戏规则改变者:在其他平台上可能需要几个月或几年才能构建的项目,在 RISC Zero 的平台上可以轻松解决。
除了更容易构建之外,RISC Zero 还在性能上交付成果。zkVM 具有 CUDA 和 Metal 的 GPU 加速,且通过延续实现了大型程序的并行证明。
此前,Risc Zero 获得了 Galaxy Digital, IOSG, RockawayX, Maven 11, Fenbushi Capital, Delphi Digital, Algaé Ventures, IOBC 等机构的 4 千万美元 A 轮融资。
5.3 Brevis
Celer Network 旗下的 Brevis 则专注于多链历史数据的抓取,它赋予智能合约能力,从任何链上读取其完整的历史数据,并执行全面无信任的定制计算,目前主要支持以太坊 POS,Comos Tendermint 和 BSC。

应用界面:Brevis 的当前系统支持高效且简洁的 ZK 证明,为连接至区块链的去中心化应用(dApp)合约提供以下经过 ZK 证明的源链信息:
- 源链上任何区块的区块哈希值及相关状态、交易、收据根。
- 源链上任何特定区块、合约、槽的槽值和相关元数据。
- 源链上任何交易的交易收据和相关元数据。
- 源链上任何交易的交易输入和相关元数据。
- 源链上任何实体发送至目标链上任何实体的任意信息。
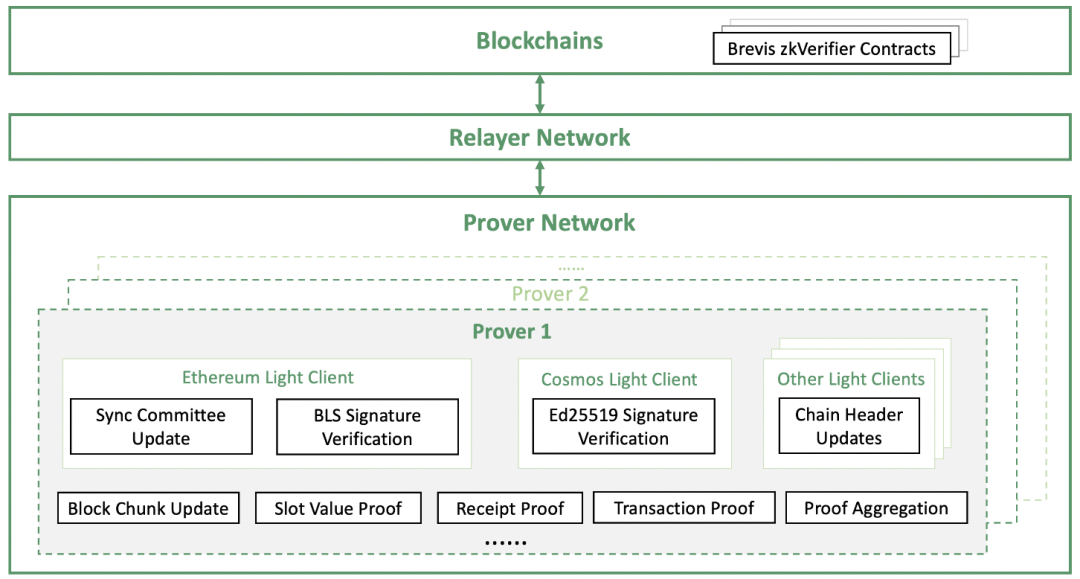
架构概述:Brevis 的架构由三个主要部分构成:
- 中继器网络:它同步来自不同区块链的区块头和链上信息,并将其转发给验证器网络以生成有效性证明。之后,它会将验证过的信息及其相关证明提交至连接的区块链。
- 证明者网络:为每个区块链的轻客户端协议、区块更新实现电路,并生成所请求的槽值、交易、收据以及集成应用逻辑的证明。为了最小化证明时间、成本和链上验证成本,证明者网络可以汇总同时生成的分布式证明。此外,它还可以利用 GPU、FPGA 和 ASIC 等加速器来提高效率。
- 连接区块链上的验证器合约:接收由验证器网络生成的经过 zk 验证的数据和相关证明,然后将经过验证的信息反馈给 dApp 合约。
这一整合的架构使得 Brevis 在提供跨链数据和计算时,能够保证高效率和安全性,从而使 dApp 开发者能够充分利用区块链的潜力。有了这种模块化架构,Brevis 可以在所有支持的链上为链上智能合约提供完全免信任、灵活、高效的数据访问和计算能力。这为 dApp 开发提供了全新的范式。Brevis 具有广泛的用例,如数据驱动的 DeFi、zkBridges、链上用户获取、zkDID、社交账户抽象等,增加了数据的互操性。
5.4 Langrange
Langrange 和 Brevis 的愿景类似,旨在通过 ZK Big Data Stack 增强多链之间的互通,它能够在所有主流区块链上创建通用的状态证明。通过与 Langrange 协议集成,应用程序能够提交多链状态的聚合证明,这些证明随后可以被其他链上的合约以非交互的方式验证。
与传统的桥接和消息传递协议不同,Langrange 协议不依赖于特定的节点组来传递信息。相反,它利用加密技术来实时协调跨链状态的证明,这包括那些由不受信任的用户提交的证明。在这种机制下,即使信息来源不可信,加密技术的应用也保证了证明的有效性和安全性。
Langrange 协议一开始将与所有 EVM 兼容的 L1、L2 rollups 兼容。此外,Langrange 还计划在不久的将来支持非 EVM 兼容链,包括但不限于 Solana、Sui、Aptos 以及基于 Cosmos SDK 的流行公链。
Langrange 协议与传统桥接和消息协议的区别:
传统的桥接和消息传递协议主要用于在特定的一对链之间转移资产或消息。这些协议通常依赖于一组中间节点来确认源链在目标链上的最新区块头。这种模式主要针对单一对单的链关系进行优化,基于两个链的当前状态。相比之下,Langrange 协议提供了一种更通用、更灵活的跨链交互方法,使应用程序能够在更广泛的区块链生态系统中进行交互,而不仅限于单一的链对链关系。
Langrange 协议专门优化了用于证明链间合约状态的机制,而非仅限于信息或资产的传输。这一特点允许 Langrange 协议有效地处理涉及当前和历史合约状态的复杂分析,这些状态可能跨越多条链。这种能力使得 Langrange 能够支持一系列复杂的跨链应用场景,例如计算多链去中心化交易所(DEX)上资产价格的移动平均值,或者分析多条不同链上货币市场利率的波动性。

因此,Langrange 状态证明可被视为对多对一(n 对 1)链关系的优化。在这种跨链关系中,一条链上的去中心化应用(DApp)依赖于来自多条其他链(n 条)的实时和历史状态数据的聚合。这一特性极大地拓展了 DApp 的功能和效率,使其能够汇总和分析来自多个不同区块链的数据,进而提供更深入、全面的洞察。这种方式显著区别于传统的单一链或一对一链关系,为区块链应用提供了更加广阔的潜力和应用范围。
Langrange 此前获得了 1kx,Maven11, Lattice,CMT Digital 和 gumi crypto 等机构的投资。
5.5 Herodotus
Herodotus 旨在为智能合约提供来自其他以太坊层的同步链上数据访问。他们认为存储证明可以统一多个 Rollups 的状态,甚至允许以太坊层之间的同步读取。简单来说就是跨 EVM 主链和 rollup 之间的数据抓取。目前支持 ETH 主网,Starknet,Zksync,OP,Arbitrum 和 Polygon。
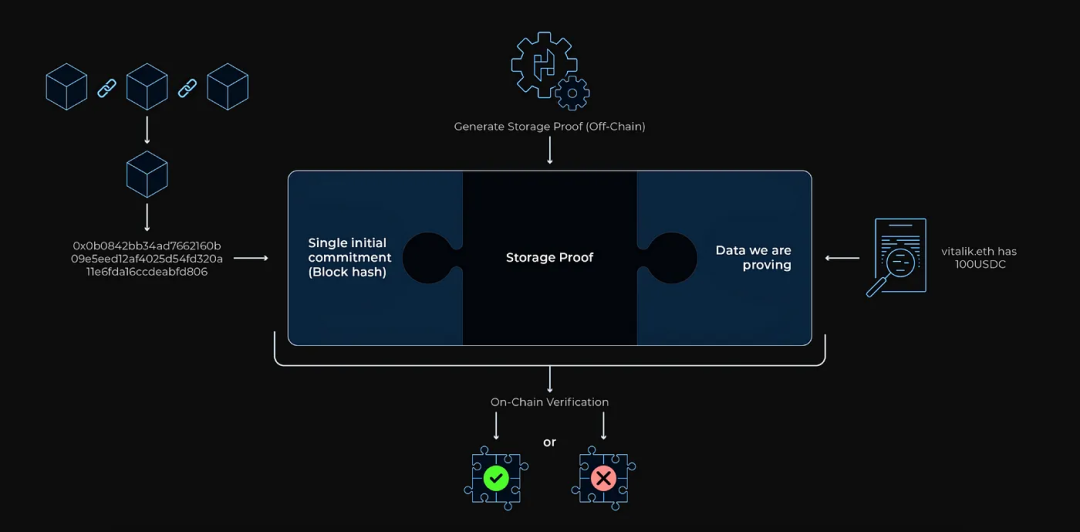
Herodotus 定义的 Storage Proof 是一种复合证明,可用于验证大型数据集中的一个或多个元素的有效性,比如整个以太坊区块链中的数据。
Storage Proof 的生成流程大致分为三个步骤:
第一步:获取可验证承诺的区块头储存累加器
- 这一步是为了获取一个我们可以验证证明的 “承诺”。如果累加器还没有包含我们需要证明的最新区块头,我们首先需要证明链的连续性,以确保覆盖到包含我们目标数据的区块范围。例如,如果我们要证明的数据在区块 1,000,001 中,而区块头储存的智能合约只覆盖到区块 1,000,000,那么我们就需要对头存储进行更新。
- 如果目标区块已在累加器中,则可以直接进行下一步。
第二步:证明特定账户的存在
- 这一步需要从以太坊网络中所有账户构成的状态树(State Trie)中生成包含证明。状态根是推导区块承诺哈希的重要部分,也是头存储的一部分。需要注意的是,累加器中的区块头哈希值可能与区块的实际哈希值不同,因为为了提高效率,可能采用了不同的哈希处理方法。
第三步:证明账户树中的特定数据
- 在这一步,可以为诸如 nonce、余额、存储根或 codeHash 等数据生成包含证明。每个以太坊账户都有一个存储三元组(Merkle Patricia Tree),用于保存账户的存储数据。如果我们要证明的数据在账户存储中,那么就需要为该存储中的特定数据点生成额外的包含证明。
生成所有必要的包含证明和计算证明之后,就形成了一个完整的存储证明。这个证明随后会被发送到链上,在链上进行验证,验证依据是单一的初始承诺(如 blockhash)或头存储的 MMR 根。这个过程确保了数据的真实性和完整性,同时也保持了系统的高效性。
Herodotus 已经得到了 Geometry,Fabric Ventures,Lambda Class 以及 Starkware 的支持。
5.6 HyperOracle
Hyper Oracle 专门为可编程零知识预言机设计,旨在保持区块链的安全性和去中心化。Hyper Oracle 通过其 zkGraph 标准,让链上数据和链上等价计算变得既实用又可验证,并且具有快速终结性。它为开发人员提供了一种全新的方式来与区块链互动。
Hyper Oracle 的 zkOracle 节点主要由两个组件构成:zkPoS 和 zkWASM。
- zkPoS:这个组件负责通过零知识(zk)证明获取以太坊区块链的区块头和数据根,以确保以太坊共识的正确性。zkPoS 还充当 zkWASM 的外部电路。
- zkWASM:它使用从 zkPoS 获取的数据作为运行 zkGraphs 的关键输入。zkWASM 负责运行由 zkGraphs 定义的定制数据映射,并为这些操作生成零知识证明。zkOracle 节点的操作员可以选择他们想要运行的 zkGraph 数量,这可以是从一个到所有已部署的 zkGraph。生成 zk 证明的过程可以委托给分布式的证明者网络。
zkOracle 的输出是链外数据,开发者可以通过 Hyper Oracle 的 zkGraph 标准来使用这些数据。这些数据还附带 zk 证明,以验证数据的有效性和计算。
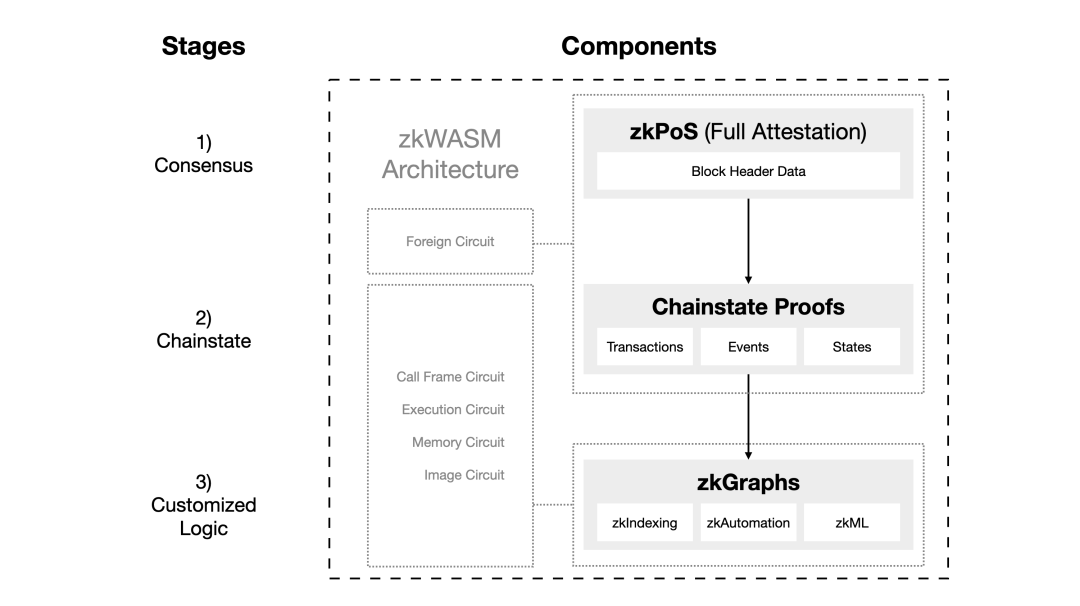
为了维护网络安全,Hyper Oracle 网络只需要一个 zkOracle 节点。然而,网络中可以存在多个 zkOracle 节点,针对 zkPoS 和每个 zkGraph 进行操作。这样可以并行生成 zk 证明,从而显著提高性能。总的来说,Hyper Oracle 通过结合先进的 zk 技术和灵活的节点架构,为开发者提供了一个高效且安全的区块链互动平台。
2023 年 1 月,Hyper Oracle 宣布获得由 Dao5,红杉中国,Foresight Ventures,FutureMoney Group 共同参与的 300 万美元种子轮前融资。
5.7 Pado
Pado 在 ZK 协处理器中是一个比较特殊的存在,其他协处理器专注于抓取链上数据,而 Pado 提供了抓取链下数据的路径,旨在把所有互联网数据带入智能合约当中,在保证隐私和无需信任外部数据源的情况下一定程度上替代了预言机的功能。
5.8 ZK coprocessor 和预言机的对比
- 延迟: 预言机是异步的,因此与 ZK coprocessor 相比,访问平面数据时的延迟更长。
- 成本: 虽然许多预言机不需要计算证明,因此成本较低,但安全性较低。存储证明成本更高,但安全性更高。
- 安全性: 数据传输的最大安全性以预言机自身的安全级别为上限。相比之下,ZK coprocessor 与链的安全性相匹配。此外,由于使用链外证明,预言机容易受到操纵攻击。
下图展示了 Pado 的工作流:
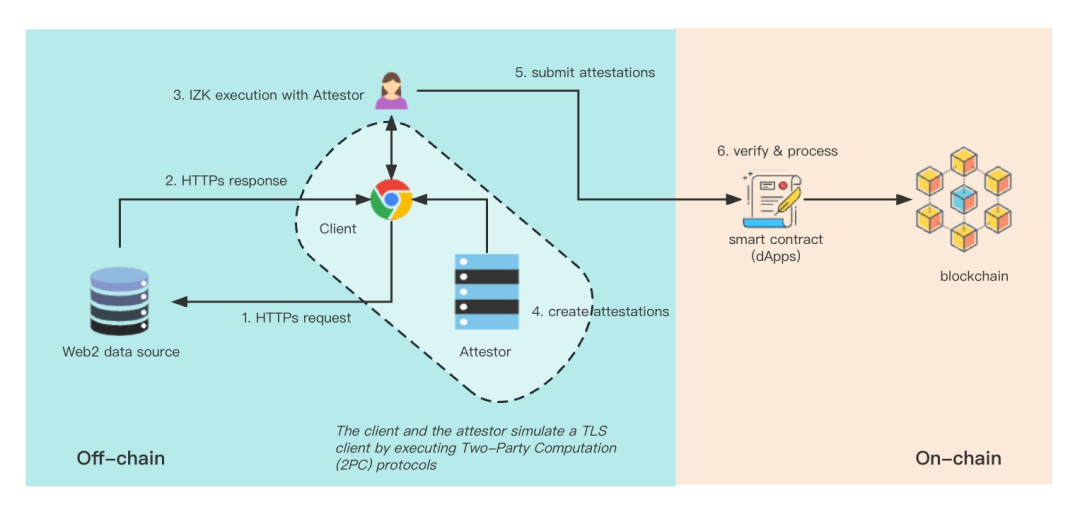
Pado 采用加密节点作为后端证明者。为了降低信任假设,Pado 团队将采取演进策略,逐步完善证明者服务的去中心化。证明者积极参与用户数据检索和共享过程,同时证明从网络数据源获取的用户数据的真实性。其独特之处在于,Pado 利用了 MPC-TLS(传输层安全多方计算)和 IZK(交互式零知识证明),使证明者能够 "盲目 "地证明数据。这意味着验证者看不到任何原始数据,包括公共和私人用户信息。不过,验证者仍可通过加密方法确保任何传输的 TLS 数据的数据来源。
- MPC-TLS:TLS 是一种安全协议,用于保护互联网通信的隐私和数据完整性。当你访问一个网站,并在 URL 上看到 “锁” 图标和 “https” 时,就意味着你的访问是通过 TLS 进行保护的。MPC-TLS 模仿了 TLS 客户端的功能,使 Pado 的验证器能够与 TLS 客户端协作,执行以下任务:需要注意的是,这些与 TLS 相关的操作都是在客户端和验证者之间通过双方计算(2PC)协议执行的。MPC-TLS 的设计依赖于一些加密技术,如混淆电路(GC)、遗忘传输(OT)、IZK 等。
- 建立 TLS 连接,包括计算主要密钥、会话密钥和验证信息等。
- 在 TLS 通道中执行查询,包括生成加密请求和解密服务器响应。
- IZK:交互式零知识证明是一种证明者和验证者可以进行交互的零知识证明。在 IZK 协议中,验证者的结果是接受或拒绝证明者的声明。与简单的 NIZKs(如 zk-STARKs 或 zk-SNARKs)相比,IZK 协议具有几个优点,如对大型声明的高扩展性、低计算成本、无需可信设置以及最小化内存使用。
Pado 正在积极开发 Uniswap 的 kyc hook,寻求更多的数据上链应用场景,并入选了首批 Consensys Fellowship 计划。
六、未来展望
ZK coprocessor 使区块链可以在不伤害去中心化的情况下以较低成本的方式让智能合约抓取更多数据,获取链下的计算资源,同时解藕了智能合约的工作流,增加了可拓展性和效率。
单从需求端来看,ZK coprocessor 是个刚需,就单从 DEX 这个赛道来看,这个 hook 的潜力非常大,可以做很多事情,如果 sushiswap 不上 hook,就没法和 uniswap 竞争,会被很快淘汰,如果不用 zkcoprocessor 上 hook,那么对开发者和用户来说 gas 就会很贵,因为 hook 引入了新的逻辑,让智能合约变得更复杂,适得其反。那么目前来看,使用 zk coprocessor 就是最好的解决方案。无论从数据抓取还是计算来看,几种方法都有不同的优劣点,适用于特定功能的协处理器就是好的协处理器。链上可验证计算市场前景广阔,会在更多领域体现出新的价值。
在区块链未来的发展中,有潜力打破 web2 传统的数据壁垒,信息之间不再是孤岛,实现更强的互操性,ZK 协处理器们将会成为强劲的中间件,在保障安全、隐私以及无信任的情况下为智能合约的数据抓取、计算、验证降本增效,解放数据网络,打开更多的可能性,成为真正的意图应用落地以及链上 AI Agent 的基础设施,只有你想不到,没有你做不到。
试想在将来的一个场景:利用 ZK 做数据验证的高可信度和隐私性,网约车司机们可以在自己的平台之外另外建立一个聚合网络,这个数据网络可以涵盖 Uber,Lyft,滴滴,bolt 等等,网约车司机可以提供自己平台的数据,你拿一块,我拿一块,在区块链上把他拼起来,慢慢地独立于自己平台的网络就建立起来了,聚合了所有的司机数据,成为了网约车数据的大聚合器,同时可以让司机匿名,不泄漏自己的隐私。

七、索引
https://blog.axiom.xyz/what-is-a-zk-coprocessor/
https://crypto.mirror.xyz/BFqUfBNVZrqYau3Vz9WJ-BACw5FT3W30iUX3mPlKxtA
https://blog.uniswap.org/uniswap-v4
https://blog.celer.network/2023/03/21/brevis-a-zk-omnichain-data-attestation-platform/
https://lagrange-labs.gitbook.io/lagrange-labs/overview/what-is-the-lagrange-protocol
https://docs.herodotus.dev/herodotus-docs/
感谢 Yiping Lu 对本文的建议和指导
免责声明:作为区块链信息平台,本站所发布文章仅代表作者及嘉宾个人观点,与 Web3Caff 立场无关。 文章内的信息仅供参考,均不构成任何投资建议及要约,并请您遵守所在国家或地区的相关法律法规。