本文將主要討論 ZKP 作為擴容方案的發展現狀,從理論層面描述產生證明過程中主要需要優化的幾個維度,並引深到不同擴容方案對於加速的需求。然後再圍繞硬件方案著重展開,展望 zk 硬件加速領域的摩爾定律。
作者: Bryan, IOSG Ventures
封面: Photo by Milad Fakurian on Unsplash
本文為 IOSG 原創內容,僅做行業學習交流之用,不構成任何投資參考。如需引用,請註明來源,轉載請聯繫 IOSG 團隊獲取授權及轉載須知。
本文將主要討論 ZKP 作為擴容方案的發展現狀,從理論層面描述產生證明過程中主要需要優化的幾個維度,並引深到不同擴容方案對於加速的需求。然後再圍繞硬件方案著重展開,展望 zk 硬件加速領域的摩爾定律。最後,關於硬件 zk 加速領域的一些機會和現狀,會在文末闡述。首先,影響證明速度的主要有三個維度:證明系統,待證明電路規模,和算法軟硬件優化。
對於證明系統來說,凡是使用橢圓曲線(EC)的算法,也就是市面上主流的 Groth 16(Zcash), Galo2(Scroll), Plonk(Aztec, Zksync) 這些 zk-snark 算法,產生多項式承諾的過程中涉及的大數點乘(MSM),目前都有時間長(算力要求高)的瓶頸。對於 FRI-based 算法,如 ZK-Stark,其多項式承諾產生方式是 Hash Function,不牽扯 EC,所以並不涉及 MSM 運算。
證明系統是基礎,待證明電路的規模也是核心的硬件優化的需求之一。近期討論很火的 ZKEVM 據對以太坊的兼容程度不同,導致了電路的複雜程度的不同,比如 Zksync/Starkware 構建了與原生以太坊不同的虛擬機,從而繞開了一些以太坊原生的不適合利用 zk 處理的底層代碼,縮小了電路的複雜長度,而 Scroll/Hermez 這樣目標從最底端兼容的 zkevm 的電路自然也會更複雜。(一個方便理解的比方是,電路的複雜性可以理解為一輛巴士上的座位,比如普通日子下需要搭載的乘客數在 30 人以下,有些巴士選擇了 30 人的座位,這些巴士就是 Zksync/StarkWare,而一年中也有一些日子有特別多的乘客,一般的巴士坐不下,所以有一些巴士設計的座位更多(Scroll)。但是這些日子可能比較少,會導致平時會有很多空餘的座位。)硬件加速對於這些電路設計更複雜的電路更迫切,不過這更多是一個 Specturm 的事情,對於 ZKEVM 也同樣有利無弊。
不同證明系統優化的需求/側重點:
基本:
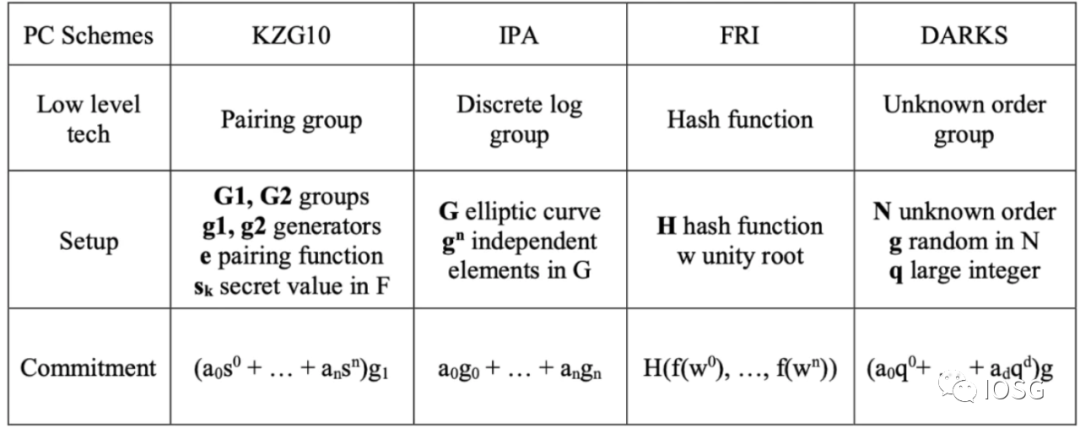
當一個待證明事物經過電路(如 R1CS/QAP)處理之後,會得到一組標量和向量,之後被用來產生多項式或者其他形式的代數形式如 inner product argument (groth16)。這個多項式依然很冗長,如果直接生成證明那麼無論是證明大小或是驗證時常都很大。所以我們需要將這個多項式進一步簡化。這裡的優化方式叫做多項式承諾,可以理解為多項式的一種特殊的哈希值。以代數為基礎的多項式承諾有 KZG, IPA,DARK,這些都是利用橢圓曲線產生承諾。
FRI 是以 Hash Function 為產生承諾的主要途徑。多項式承諾的選擇主要是圍繞幾點– 安全性,Performance。安全性在這裡主要是考慮到在 set up 階段。如果產生 secret 所使用的 randomness 是公開的,比如 FRI,那麼我們就說這個 set up 是透明的。如果產生 secret 所利用的 randomness 是私密的,需要 Prover 在使用之後就銷毀,那麼這個 set up 是需要被信任的。MPC 是一種解決這裡需要信任的手段,但是實際應用中發現這個是需要用戶來承擔一定的成本。
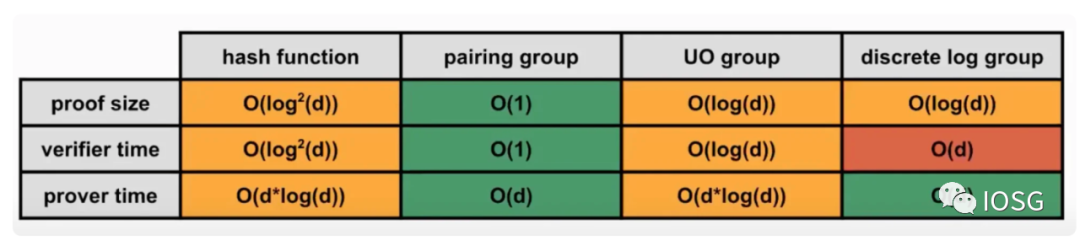
而上述提到的在安全性方面相對卓越的 FRI 在 Performance 並不理想,同時,雖然 Pairing-friendly 橢圓曲線的 Performance 比較卓越,但是當考慮將 recursion 加入時,因適合的曲線並不多,所以也是相當大的存在相當大的 overhead。
行業現狀:
當前不管是的基於 Plonk(matterlabs) 或者基於 Ultra-Plonk(Scroll, PSE),他們最後的多項式 commitment 都是基於 KZG,故而 Prover 的大部分工作都會涉及到大量的 FFT 計算 (產生多項式)和 ECC 點乘 MSM 運算(產生多項式承諾)。在純 plonk 模式下,由於需要 commit 的 point 數量不大,MSM 運算所佔的 Prove 時間比重不高,所以優化 FFT 性能能夠短期帶來更大的性能提升。但是在 UltraPlonk(halo2)框架下,由於引入了 customer gate,prover 階段設計的 commit 的 point 數量變多,使得 MSM 運算的性能優化也變得非常重要。(目前 MSM 運算進行 pippenger 優化之後,依然需要 log(P(logB)) (B 是 exp 的上界,p 是參與 MSM 的 point 的數量)。
目前新一代 Plonky2 證明系統由於所採用的多項式 commitment 不再是 KZG 而是 STARK 系統中常見的 FRI,使得 Plonky2 的 prover 不需要再考慮 MSM,從而理論上該系統的性能提升不再依賴 MSM 相關的算法優化。plonky2 的作者 Mir(目前的 Polygon Zero) 正在大力推廣該系統。不過由於 plonky2 採用的數域 Goldilocks Field 對於編寫 elliptic 相關的 hash 算法相關的電路(例如 ECDSA)不是特別友好,所以儘管 Goldilocks Field 在機器 word 運算方面優勢明顯,但是依然難以判斷 Mir 和 PSE/Scroll 方案誰是更好的方案。
基於對 Plonk,Ultraplonk, Plonky2 的 Prove 算法的綜合考量,需要硬件加速的模塊大概率還是會集中在 FFT,MSM,HASH 三個方向。
Prover 的另一個瓶頸是 witness 的生成,通常普通非 zk 計算會略去大量的中間變量,但是在 ZK prove 的過程中,所有 witness 都需要被記錄,並且會參與之後的 FFT 計算,所以如何高效的並行 witness 計算也會是 prover 礦機需要潛在考慮的方向。
加速 ZKP 方面的嘗試: recursive proof – StarkNet 的 fractal L3 概念基於 recursive proof 的概念,Zksync 的 fractal hyperscaling,Scroll 也有類似的優化。
> Recursive zkSNARK 概念是對一個 Proof A 的驗證過程進行證明,從而產生另一個 Proof B。只要 Verifier 能接受 B,那麼相當於也接受了 A。遞歸 SNARK 可以也可以把多個證明聚合在一起,比如把 A1 A2 A3 A4 的驗證過程聚合為 B;遞歸 SNARK 也可以把一段很長的計算過程拆解為若干步,每一步的計算證明 S1 都要在下一步的計算證明中得到驗證,即計算一步,驗證一步,再計算下一步,這樣會讓 Verifier 只需要驗證最後一步即可,並避免構造一個不定長的大電路的難度。
理論上 zkSNARK 都支持遞歸,有些 zkSNARK 方案可以直接將 Verifier 用電路實現,另一些 zkSNARK 需要把 Verifier 算法拆分成易於電路化的部分和不易電路化的部分,後者採用滯後聚合驗證的策略,把驗證過程放到最後一步的驗證過程中。
在 L2 的未來應用上,遞歸的優勢可以通過對於帶證明事物的歸納而進一步將成本與性能等要求進一步降低。
第一種情況 (application-agnostic) 是針對不同的待證明的事物,比如一個是 state update 另一個是 Merkle Tree,這兩個待證明事物的 proof 可以合併成一個 proof 但是依舊存在兩個輸出結果(用來分別驗證的 public key)
第二種情況 (applicative recursion) 是針對同類的待證明的事物,比如兩個都是 state update, 那麼這兩個事物可以在生成 proof 前進行聚合,且僅有一個輸出結果,該結果就是經歷了兩次 update 的 state difference。(Zksync 的方法也類似,user cost 僅對 state difference 負責)
除了 recursive proof 以及下文主要討論的硬件加速之外,還有其他的加速 ZKP 的方式,比如 custom gates, 移除 FFT(OlaVM 的理論基礎)等,但本文因篇幅原因不予討論。
硬件加速
硬件加速在密碼學中一直是一種普遍的加速密碼學證明的方式,無論是對於 RSA(RSA 的底層數學邏輯與橢圓曲線有類似之處,同樣涉及了很多複雜的大數運算),還是早期對於 zcash/filecoin 的 zk-snark 的 GPU-based 的優化方式。
硬件選擇
在以太坊 The Merge 發生之後,不可避免將會有大量的 GPU 算力冗餘(部分受到以太坊共識改變的影響,GPU 巨頭英偉達股價距年初已經跌去 50%,同時庫存冗餘也在不斷增加),下圖是英偉達 GPU 旗艦產品 RTX 3090 的成交價格,也顯示買方勢力較為薄弱。
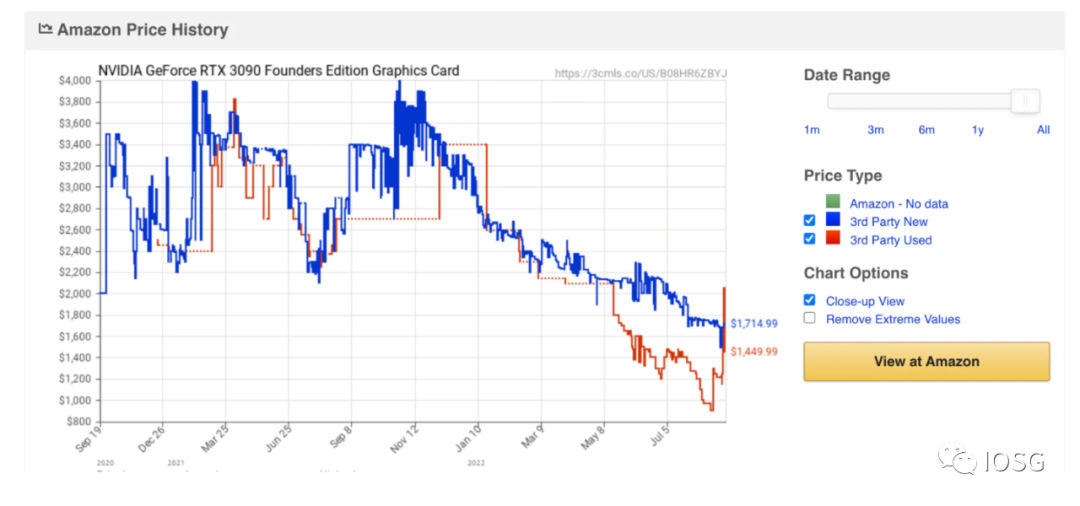
在 GPU 價格處於低點,同時大量 GPU 算力閒置,一個自然的問題就是,是否 GPU 是合適的加速 zk 的硬件呢?硬件端主要有三個選擇,GPU/FPGA/ASIC.
FPGA vs GPU:
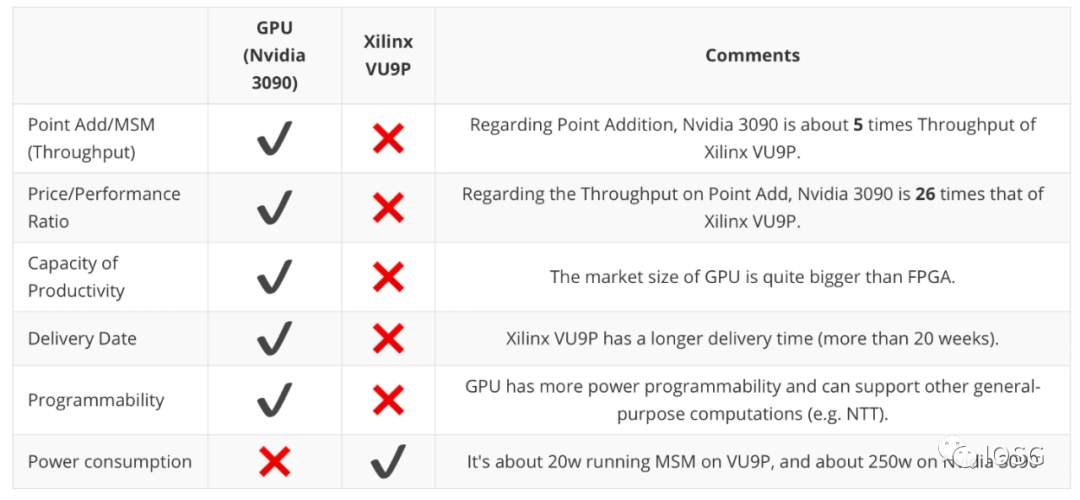
先看總結:以下是 trapdoor-tech 關於 GPU(以 Nvidia 3090 為例)以及 FPGA(Xilinx VU9P 為例)在幾個維度的總結,非常重要的一點是:GPU 在性能(生成證明的速度)方面要高於 FPGA, 而 FPGA 在能源消耗則更具有優勢。
一個更直觀的來自於 Ingoyama 的具體的運行結果:
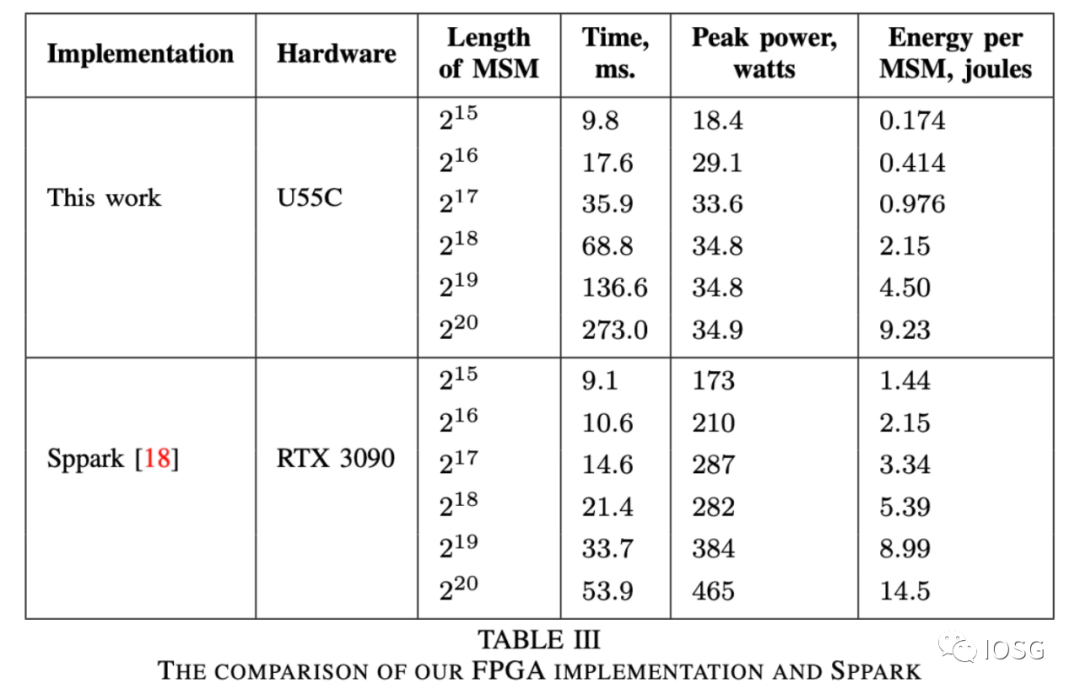
尤其是對於比特寬度更高(2^20)的運算,GPU 是 FPGA 運算速度的五倍,而消耗的電量同時也高很多。
對於普通礦工來說,性價比也是一個衡量到底使用哪一個硬件的重要的因素。無論是 U55C ($4795) 還是 VU9P ($8394) 來說,相比於 GPU (RTX 3090:$1860),價格都要高出很多。
理論層面,GPU 適合併行運算,FPGA 追求可編程性,而在零知識證明生成的環境下,這些優勢並不能完美適用。比如,GPU 適用的並行計算是針對大規模圖形處理,雖然邏輯上和 MSM 的處理方式類似,但是適用的範圍(floating number)與 zkp 針對的特定的有限域並不一致。對於 FPGA 來說,可編程性在多個 L2 的存在的應用場景並不明朗,因為考慮到 L2 的礦工獎勵與單個 L2 承接的需求掛鉤(與 pow 不一樣),有可能在細分賽道出現 winner takes all 的局面,導致礦工需要頻繁更換算法的情景出現的可能性不高。
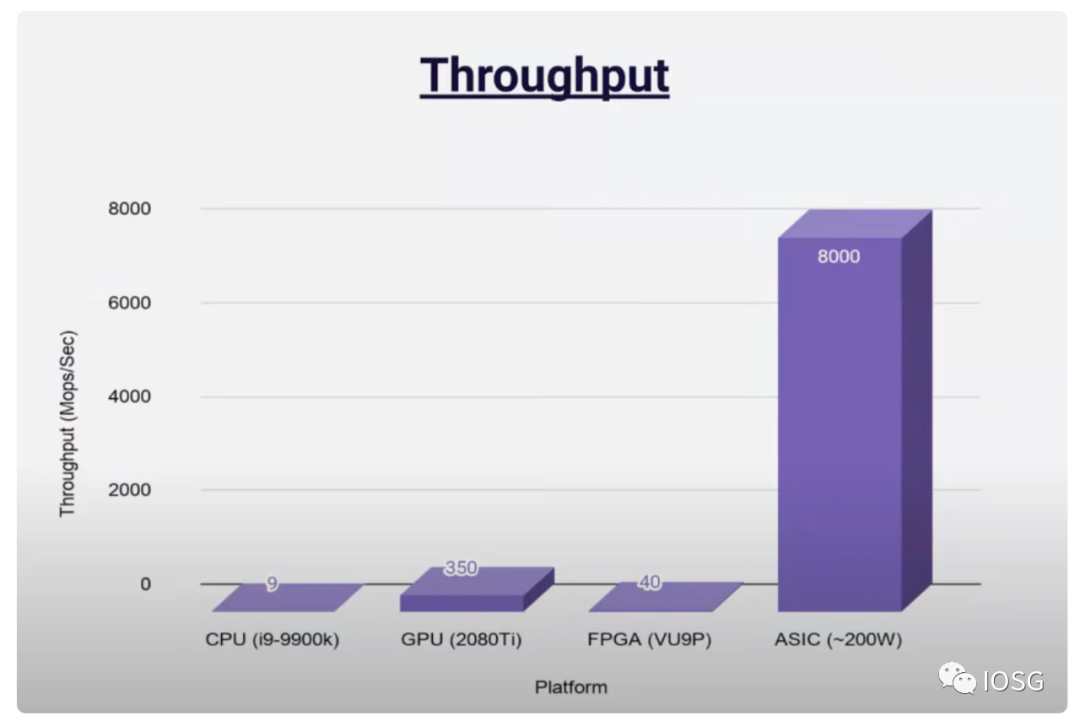
ASIC 是在性能與成本方面上權衡表現較優的方案(包括吞吐量、延遲等),但是否是最好的方案仍然沒有定論,其存在的問題是:
開發時間長- 需經歷完整的芯片設計到芯片生產的過程,即使目前已經設計好了芯片,芯片生產也是一個冗長、燒錢並且良片率不一的過程。代工資源方面,台積電和三星是最好的芯片代工工廠,目前台積電的訂單已經排到了兩年後,與 ZK 芯片競爭代工資源的是 AI 芯片、電動車芯片這類 web2 早早做好芯片設計的已經被需求證明的產品,相比之下 ZK 芯片的需求並不明朗。
其次,整顆芯片的性能和單個芯片的大小,也就是人們常說的 20nm,18nm 是成負相關的,也就是說單個芯片越小,晶片可以容納的芯片的數量越多,即整顆的性能越高,而目前的製造高端芯片的的技術是被壟斷的(比如芯片製造中最複雜的一環,光刻技術,是被荷蘭的 ASML 公司壟斷),對於一些中小型的代工廠(如國內的中芯國際)這類技術方面落後頂尖一到兩代,也就意味著從良品率以及芯片大小方面是落後於最好的代工廠的。這會導致對於 ZK 芯片來說,只能尋求一些次優的解決方案,當然也是在需求端不那麼明朗的情況下基於成本的考慮,選擇 28nm 左右的非高端芯片。
目前的 ASIC 解決方案主要處理的是 FFT 以及 MSM 兩個常見的 ZK 電路中算力需求比較高的算子,並不是針對具體的一個項目設計的,所以具體運行的效率並不是理論上最高的。比如,目前 Scroll 的 prover 的邏輯電路還沒百分百實現,自然也不存在與之一一匹配的硬件電路。並且,ASIC 是 application-specific,並不支持後續的調整,當邏輯電路發生了變化,比如節點的客戶端需要升級,是否存在一個方案也可以兼容,也是目前不確定的。
同時,人才缺失也是 ZK 芯片的一個行業現狀,理解密碼學和硬件的人才並不好找,合適的人選是有同時具備較深的數學造詣以及多年的硬件產品設計以及維護經驗。
Closing thoughts – prover 發展趨勢 EigenDA
以上都是行業對於加速 ZKP 的思考與嘗試,最終意義就是運行 prover 的門檻會越來越低。週期性來講 prover 需要經歷大致的如下三個階段:
Phase I: Cloud-based prover
基於雲的 prover 可以大大提高第三方 prover(非用戶/項目方)的准入門門檻,類似於 web2 的 aws/google cloud。商業模式上來講,項目方會流失一部分獎勵,但是從去中心化的敘事講這是一種經濟以及執行層面吸引更多參與者的方式。而云計算/雲服務是 web2 現有的技術棧,已有成熟的開發環境可供開發者使用,並且可以發揮雲所特有的低門檻/高集群效應,對於短期內的 proof outsource 是一種選擇。目前,Ingoyama 也有在這一方面的實現(最新的 F1 版甚至達到了 pipeMSM 的基準速度的兩倍)。但是,這依然是一個單個 prover 運行整個 proof 的方式,而在 phase II 中 proof 可以是一種可拆分的形式存在,參與者數量會更多。
Phase II: Prover marketplace
proof 生成的過程中包含不同的運算,有的運算對於效率有偏好,有的運算則對成本/能源消耗有要求。比如 MSM 計算涉及 pre-computation,這需要一定的 memory 支持不同的 pre-computation 上的標量顆粒,而如果所有的標量都存在一個計算機上的話對於該計算機的 memory 要求較高,而如果將不同的標量存儲在多個服務器上,那麼不僅該類的計算的速度會提高,並且參與者的數量也會增加。
Marketplace 是一種針對上述外包計算的一種商業模式上的大膽的思考。但其實在 Crypto 圈子裡也有先例– Chainlink 的預言機服務,不同鏈上的不同交易對的價格餵送也是以一種 marketplace 的形式存在。同時,Aleo 的創始人 Howard Wu 曾經合作撰寫過一篇 DIZK,是一個分佈式賬本的零知識證明生成方法論,理論上是可行的。
話說回來,商業模式上講這是一種非常有意思的思考,但是可能在實際落地時一些執行上的困難也是巨大的,比如這類運算之間如何協調生成完整的 proof,至少需要在時間以及成本上不落後於 Phase I。
Phase III: Everyone runs prover
未來 Prover 會運行在用戶本地(網頁端或者移動端),如 Zprize 有基於 webassembly/andriod 執行環境的 ZKP 加速相關的競賽和獎勵,意味著一定層面上用戶的隱私會得到確保(目前的中心化 prover 只是為了擴容,並不保證用戶隱私),最重要的上– 這裡的隱私不僅局限於鏈上行為,也包括鏈下行為。
一個必須要考慮的問題是關於網頁端的安全性,網頁端的執行環境相比硬件來說對於安全性的先決條件更高(一個 industry witness 是 metmask 這樣的網頁端錢包相比於硬件錢包,安全性更低)。
除了鏈上數據鏈下證明外,以 ZKP 的形式將鏈下數據上傳到鏈上,同時百分百保護用戶隱私,也只有在這個 Phase 可能成立。目前的解決方案都難免面臨兩個問題– 1. 中心化,也就是說用戶的信息依然有被審查的風險 2. 可驗證的數據形式單一。因為鏈下數據形式多樣且不規範化,可驗證的數據形式需要經過大量的清洗/篩查,同時依舊形式單一。這裡的挑戰甚至不只是證明生成的環境,對於算法層面是否有能夠兼容(首先必須使用 transparent 的算法),以及成本/時間/效率都是需要思考的。但是同樣需求也是無與倫比的,想像可以以去中心化的方式抵押現實生活的信用在鏈上進行借貸,並且不會有被審查的風險。
免責聲明:作為區塊鏈信息平台,本站所發布文章僅代表作者及嘉賓個人觀點,與 Web3Caff 立場無關。文章內的信息僅供參考,均不構成任何投資建議及要約,並請您遵守所在國家或地區的相關法律法規。