Web3 的數據應當如何定義與理解?
作者:Lewis Liao,Zonff Partners 投資經理
封面:Photo by Pawel Czerwinski on Unsplash
當我們在談 Web3 數據的時候,在談些什麼?想要弄清楚這個問題,首先我們要弄清楚,在 Web2 中數據是什麼樣的。本文將從數據的產生、收集、存儲、管理和使用的全生命週期來展開討論。在此之前,我們首先明晰數據是如何被定義的。
中國全國信息安全標準化技術委員會出台的《網絡安全標準實踐指南- 數據分類分級指引》(徵求意見稿- v1.0 - 202109)中,將數據分類為個人信息、公共數據和法人數據。
其具體定義與實例如下表,
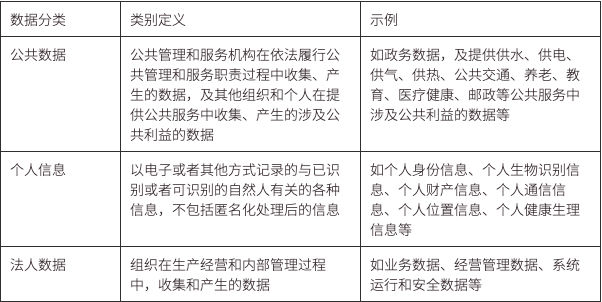
在每個類別之上,又根據數據洩露的危害對象和程度分為 5 個級別:公開級(1 級)、內部級(2 級)、敏感級(3 級)、重要級(4 級)和核心級(5 級)。對於公開級的數據,它更像是一個公共產品,是非競爭性和非排他性的。這種類型的數據一般由政府/公共組織提供,收益歸其所有,如天氣預報、宏觀經濟數據等等。
1.1 數據的產生、收集和存儲
公共數據、個人數據和法人數據大部分是在我們日常使用計算機應用程序時產生的,其中與普通用戶切身相關的是個人數據和法人數據。
那麼個人數據和法人數據是如何產生和被收集的呢?一個高度抽象的互聯網產品系統架構圖如下所示,
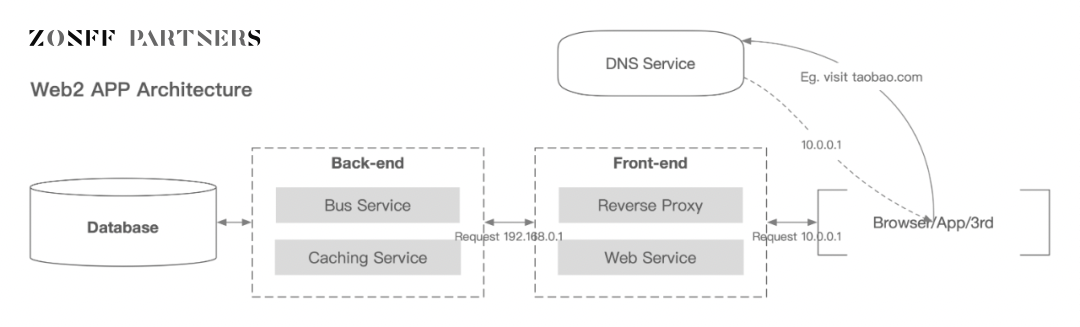
圖片來源:Zonff Partners
最底層的數據庫存儲著來自於後端傳遞過來的,用戶與前端互動產生的數據。廣義上說,這些都是用戶數據。
就移動端應用來說,數據大概可以分為以下幾類:
- 用戶信息,用戶使用應用服務記錄下來的與用戶相關的信息,包括用戶的身份信息、設備、網絡、地理位置甚至移動設備上安裝的應用列表等,由服務端數據表和埋點進行收集;
- 內容數據,用戶使用應用服務生產的數據,這些包括用戶任何主動在應用上交互寫入的非個人信息內容數據,屬於應用服務的一部分,一般由服務端數據表直接收集;
- 行為數據,用戶使用應用期間交互產生的數據,這些包括用戶在使用應用期間的行為習慣,如觀看時長、點擊率、滲透率、滑動情況等等,一般由埋點進行收集;
- 日誌數據,用戶使用應用期間應用本身產生的數據,這些包括應用的崩潰日誌等;
- 代碼數據,非用戶交互的數據包括前端與後端代碼,這些數據與用戶數據一樣,都是存儲在某個地方的中心化服務器上;
在這個分類當中,用戶信息屬於個人信息數據,日誌和代碼數據屬於法人數據。其中值得討論的是內容數據和行為數據,它們在 Web2 時代更多被中心化實體劃分為自身的業務數據,即法人數據。
在 Web3 的應用中有什麼不一樣嗎?Preethi Kasireddy 這張 Web3 產品架構可以幫助我們理解。
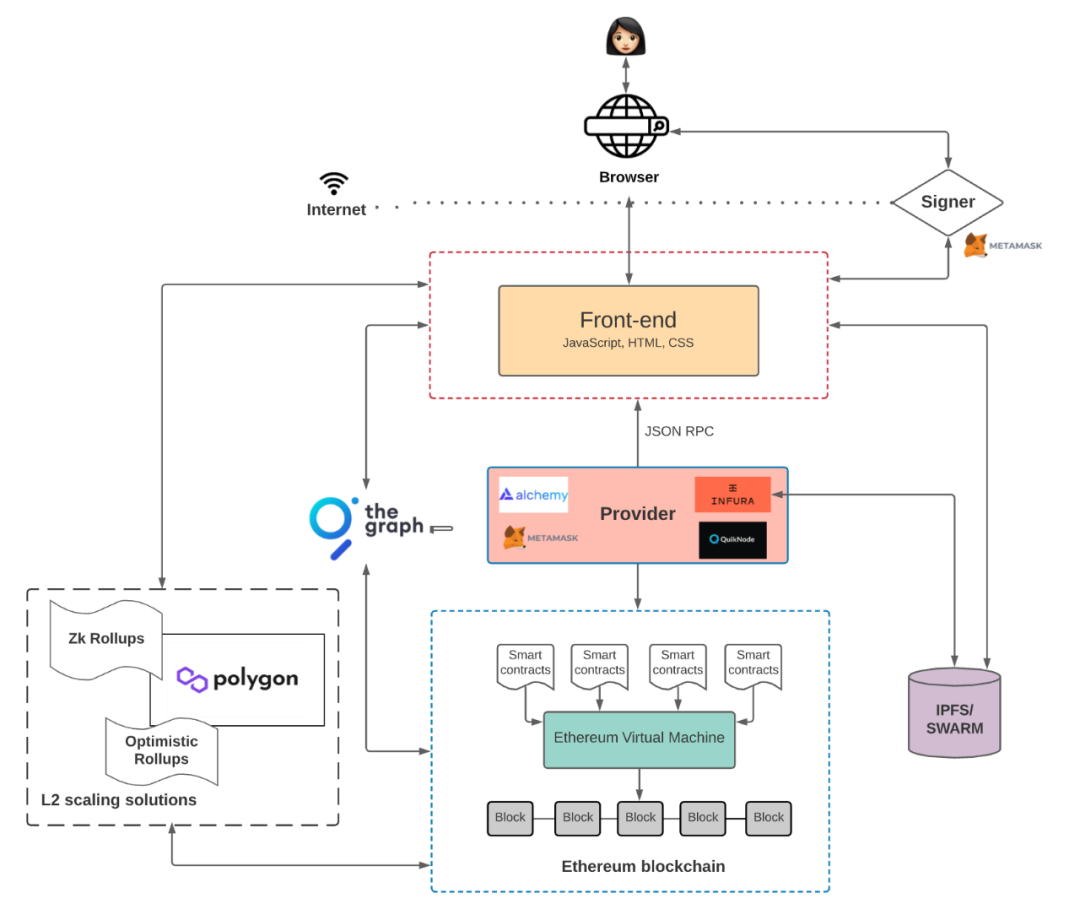
與 Web2 應用相比,用戶終端與前端是幾乎沒有什麼變化的,不一樣在於後端與數據庫。用戶通過前端與節點提供商互動(而不是某台中心化服務器),訪問佈置在以太坊等區塊鏈上的合約代碼(而不是服務器上的後端環境),並進行交互。在這個過程同樣會產生上述幾種類型的數據,由於技術架構的區別,Web3 產生的數據並不是由一台中心化服務器存儲,對於不同方式產生的數據其存儲的方式或有異同之處。
其中凡是智能合約交互產生的數據,都發佈在區塊鏈上,任何人可以都訪問,它因此成為一種公共產品,這些包括資產信息、交易數據和合約代碼。理論上,只要區塊鏈塊空間夠大,任何數據都可以存儲在區塊鏈上,甚至也有的項目在嘗試將區塊鏈作為數據庫來存儲數據。
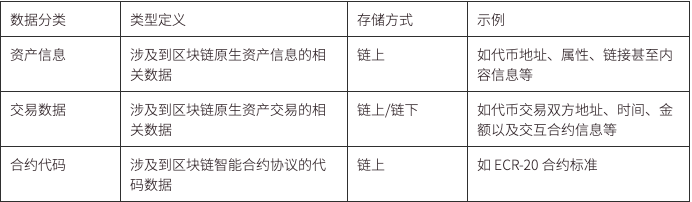
目前階段,一個 Web3 應用產生的數據,除以上三類數據以外,大多數仍然採用中心化服務器的存儲方式,這些包括前端代碼、用戶信息、內容數據、行為數據和日誌數據。這是由於目前相關存儲基礎設施並不完善,項目方或受限於技術問題,或為了保證訪問速度等原因採取了中心化方案。隨著基礎設施的不斷發展,有很多功能越來越強大的存儲基建的出現,如 IFPS、Stroj、Filecoin 和 Ceramic 等,也有越來越多應用已經開始將自身部署在去中心化存儲上面,如將前端網站佈置在 IPFS 上然後通過 ENS 訪問,從而搭建一個去中心化網站前端以及將 NFT 項目對應的圖片等文件數據用 Arweave 進行永存等等。
總的來說,在搭建一個 Web3 應用的時候,對於應用數據的存儲,開發人員通常可以有 3 種選擇:
- 將其存在區塊鏈上,這種選擇非常昂貴,會導致應用盡可能的簡單,並且數據完全公開,好處是最為直接保護了應用主權;
- 將智能合約邏輯存在區塊鏈上,其他存在傳統後端上。這種方法會犧牲用戶的主權性,同時有中心化的風險。這是目前大多數 Web3 應用採用的方式;
- 將智能合約邏輯存在區塊鏈上,其他存在 IPFS、Arweave 和 Ceramic 等存儲上,通過智能合約管理和更新數據,這種方法較為昂貴(Ceramic 目前免費)且暫時較為緩慢,但這種方法可以保護應用的主權性;
目前,絕大多數 Web3 應用是通過第 2 種方式進行搭建的,也有一些特定應用,目前已經可以使用第 3 種方式進行搭建,極少數應用是通過第 1 種方式進行搭建的。那麼,我們應該選擇哪種方式存儲呢?什麼樣的存儲方式是趨勢呢?
1.2 趨勢:去中心化存儲- 數據和應用主權
當談到搭建 Web3 應用的 3 種方式時,這有一個關鍵詞:主權(sovereign)。這個詞是當我們聊到 Web3 的特點時一個繞不開的話題,一般來說會包括數據主權和應用主權。那麼主權重要嗎?這是另一個話題,本文不作探討,感興趣可以閱讀相關文章,如「Web3 數據市場展望」和「Web3 - Let the "right to data" awaken」。這裡想從數據的角度,切入 Web3 主權確立的必經之路,並推演基礎設施發展的方向和重點。
關於數據主權,包括數字資產主權和用戶數據主權,「縱向流動性:價值如何互聯互通」一文中有談到關於代幣可以定義用戶的數字資產主權(身份、關係與物權),這是由一個難以篡改的廣泛共識所決定的。最基礎的,這些權利的定義由區塊鏈本身就能完成,如一個代幣歸屬於哪一個地址。可一旦涉及到更複雜的數字產品權利歸屬,就會有很多問題出現,比較典型的就是 NFT 對應的圖片(或文章等)的存儲問題,「NFT:數字所有權的革命」中對這個問題進行過討論。大多數 NFT 的現狀是其對應的數字產品存儲在某個地方的中心化服務器上,一旦服務器崩潰或者被黑,那麼用戶所擁有的就只是一串鏈上哈希,哈希背後真正的 “物品” 則隨時可以被偷竊或者替換,變得毫無價值。
此外,用戶數據主權作為 Web2 與 Web3 最為明顯的分界線之一,是為 Web3 創新與進步所吶喊的旗幟。就此,Ceramic 設想了一個數據宇宙,一個可組合的、網絡級規模的數據生態系統,由每個人擁有,但不被任何人獨有。用戶數據跟隨用戶從一個應用到另一個應用,用戶作為中心控制自己的數字宇宙。目前,幾乎還沒有應用可以實現這一點,Cyberconnect 作出了很好的嘗試,它創造了一個去中心化社交圖譜協議,希望在應用間實現用戶社交關係數據的可互操作性。但目前來講,該應用並沒有保證用戶的數據主權,儘管他們已經開始轉移到 Ceramic 之上進行建設,但一切仍然還在路上。
關於應用主權,有人把主權應用稱為 “超級結構”,它擁有不可停止、免費、有價值、可擴展、無許可、正外部性和可信中立等特徵,這些綜合起來提供了一個數字世界的公共產品,打造了 “元宇宙”(如果你信的話)的基礎設施。目前絕大多數所謂 Web3 的應用其應用主權程度都不高,它們不是真正的公共產品,它們可以很容易被強權制裁與改變,Tornado Cash 事件非常直接地說明了這個問題。主要原因之一是因為雖然這些應用協議層的合約代碼都發佈在區塊鏈上,但如前端、域名等組件仍然由第三方中心化的實體所控制。
為了實現數據主權和應用主權,Web3 應用的構建方式至關重要,其基礎出發點就是存儲,數據存在哪裡,怎麼存才能保證用戶能夠擁有主權?總的來說,根據用戶的數據類型不同,可以有不同的解決方案:
- 用戶的資產信息、交易數據應為公共賬本數據,存在鏈上保證可驗證性是最重要的,但 Aztec 這樣的應用出現用來保障用戶鏈上交易的隱私性是非常有價值的;
- 用戶的用戶信息、內容數據和行為數據作為個人信息,保證用戶的控制權非常重要,在用戶的同意之下,可以選擇性對這些數據進行公開,作為公共產品以發掘正外部性;
- 日誌數據和代碼數據作為法人數據,私有化是可以接受的,也有一定的必要性,但涉及到 “超級建築” 類的 Web3 基礎設施類應用,它應當具有公共基礎設施的特性,應用代碼的存儲應當公開且具備超過平台級的抗審查能力;
目前,大多數 Web3 應用採用「將智能合約邏輯存在區塊鏈上,其他存在傳統後端上」的原因是目前沒有足夠好用的去中心化基礎設施可以替代原本的中心化基礎設施方案。
首先,IPFS、Filecoin 與 Arweave 等去中心化存儲都是靜態存儲,這使得其缺乏計算和狀態管理能力,無法實現更高級的類似數據庫的功能(如可變性、版本控制、訪問控制和可編程邏輯),而雖然 Ceramic 是動態存儲,一定程度解決了這些問題,但 Ceramic 目前的訪問速度仍然較為緩慢,且開發套件不夠完善,並且其去中心化程度也一直為人詬病。
IPFS、Filecoin 與 Arweave 等去中心化存儲的主要作用是靜態存儲瞭如圖片、文檔和靜態代碼等文件非結構化數據,因為其難以被篡改的特性一定程度上的保障瞭如 NFT 之類的數字主權,鏈上哈希代碼與鏈下去中心化存儲地址之間的聯繫一旦建立,就很難被外力以非常的手段影響。而前端代碼搭建在上面也促進了應用主權的完整性,但由於目前階段的存儲技術僅僅是存儲而已,計算能力的缺乏導致其功能支持遠遠落後於中心化的服務器方案。
目前市面上的主流去中心化存儲情況如下表所示,本表格參考「Web3 去中心化存儲進化史」總結更新,
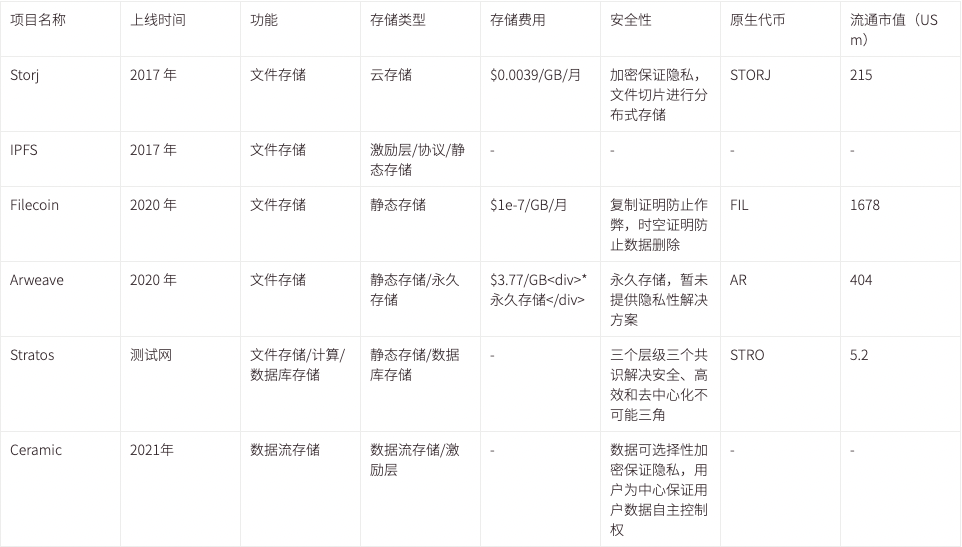
目前來說,大多數的存儲方案只是實現了一個「去中心化硬盤」,這滿足了最基本的需求,更高級一些的如基於存儲的計算需求並未完全滿足,這些計算包括本地開發環境渲染、數據流的插入與提取等等,這些都是目前 Web2 應用最常用和最必要的功能模塊。Ceramic 基於數據流存儲的創新使得數據的權限管理、版本控制、動態存儲和可組合性得以實現, Stratos 則正在嘗試提供一個更完善的、全套的解決方案,包括數據庫存儲、靜態存儲、計算和共識等多個模塊。此外,Arweave 和 Filecoin 也意識到了計算的重要性,正在自己或者鼓勵生態建設相關模塊,如 Filecoin 已經推出了 FVM 以支持在 Filecoin 上的計算 。
2.1 數據的管理
將 Web3 應用建立在去中心化存儲之上,使得他們更加不容易被外力干擾,打破了壟斷與強權。但僅僅是存儲還不夠,還需要存儲環境的渲染計算、數據處理、權限配置和隱私保護等等技術的支持,才能夠保證應用的主權、用戶的數據主權,從而實現數字世界個人主權的崛起。尤其是權限控制和隱私保護問題,它們應該用一個高級別的主權技術方案實現。Web2 應用中這些級別數據都是按照不同的安全防護級別,保存在某些具體的中心化服務器上,其安全性由網絡安全保障,其主權性由平台保障(如企業平台、政府平台等等)。這種數據管理模式下,用戶服從於超級管理員,對於數據本身,用戶沒有任何權利。此外,數據安全也受制於超級管理員這一中心化實體,如前段時間某地區的公安數據洩露事件,一個超級管理員將其私鑰洩露,使得上億人的個人私密信息洩露。
Web3 的數據管理應當具有以下兩大特性:
- 數據主權保障。這應該是超越平台級的甚至是世界級的,通過世界級的共識保障數字世界用戶共同的權力。傳統世界這方面的保障是平台級的,而且規則來自於非共識,一家平台級公司就可以掌控所有的規則制度,並隨時可以更改,從而隨時可以侵犯用戶個人主權;
- 數據隱私保障。通過密碼學從數學上對用戶數據隱私安全進行保障,而不是通過數據庫網絡安全的方式進行保護,用戶控制的選擇性加密是用戶數據主權的基本權利之一;
如何對 Web3 數據進行管理,取決於該數據是如何存儲的。
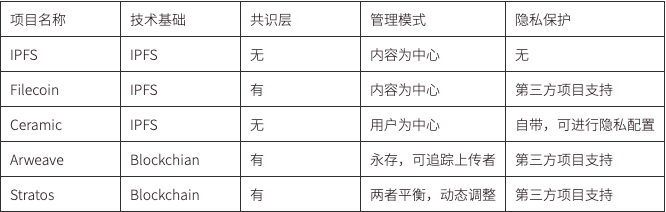
IPFS 和 Filecoin 以內容為中心,通過 Content ID(CID)來訪問存儲的內容,在此基礎之上通過搭建第三方應用進行數據管理,如通過 ChainSafe Files,可以本地化方式解決單點登錄問題後,可以方便地通過非對稱加密對數據進行加密存儲。以內容為中心的管理模式,使得用戶管理變得困難,如何給數據定所有權變得較為複雜。Filecoin 除了提供存儲之外,它的生態的拓展性會比其他的底層來說要高得多。特別是接下來 FVM 推出之後,可能會有一些針對數據存儲數據檢索方面的一些垂直領域推出特色的工具,能幫助用戶幫助企業更好地去管理它的一些數據,保證數據的安全,然後開發很多的一些新的應用。
Ceramic 也是基於 IPFS,但以用戶為中心,基於 IDX Protocol,3ID DID 方法(CIP - 79)構建了 Ceramic-native 的賬戶體系,可用於對 Ceramic 進行身份驗證,用戶可以使用區塊鏈錢包控制 3ID DID 在數據流上執行交易並管理自己的數據。這是通過將 DID 與數據關聯後存儲進數據模型實現的,數據模型定義了用戶數據的格式(schema),只要使用同一個數據模型的應用都共享該數據格式。
Arweave 是一個一次付費、永久存儲的鏈上數據去中心化存儲項目,數據公開透明地存儲在鏈上,任何人都可以訪問,通過 Arweave 區塊鏈瀏覽器可以瀏覽存在鏈上的數據。這種模式下的數據管理與管理鏈上數據一模一樣,沒有訪問權限控制,以及對原來數據的 “熱更新”,每次更新數據,其索引地址都會發生變化,這一點 IPFS 和 Filecoin 不存在問題,但其好處是數據歸屬於哪一位用戶非常明確,有利於對於數據權益進行回溯。
Stratos 也是基於區塊鏈共識的存儲,會專門維護一個索引樹,記錄數據存儲的路徑,從而保持對數據更新的追踪。與 Arweave 不同的是,Stratos 每一個存儲節點(Resource Node)被設計成同時擁有計算能力、存儲和內容訪問控制服務,項目方自己會搭建基於區塊鏈本身的數據庫用於數據的動態吞吐,其形態和管理模式接近於去中心化雲計算機。
2.2 趨勢:去中心化數據市場
在用戶擁有數據所有權的情況下,數據市場是一個必然趨勢,數據作為資本要素在其中流通。在 Filecoin 上就曾經有過數據市場的嘗試,Fivehive 由去中心化應用開發工作室 OB1 搭建並維護,是一個開源市場,支持數據集的上傳、維護、購買和(或)轉讓。該項目 Github 已經在兩年前就停止了更新和維護,大概率是失敗了。
Ceramic 的數據模型市場
Ceramic 在其數據宇宙中提到了他們要打造的開放數據模型市場,因為數據需要互操作性,它能夠極大地促進生產力的提升。這樣的數據模式市場是通過對數據模型的緊急共識實現的,就類似於以太坊中的 ETC 合約標準,開發人員可以從中選擇作為功能模板,從而擁有一個符合該數據模型的所有數據的應用程序。目前來說,這樣的市場並不是一個交易市場。
關於數據模型,一個簡單的例子是,在去中心化社交網絡當中,數據模型可以簡化為 4 個參數,分別是:
- PostList:存儲用戶帖子的索引
- Post:存儲單個帖子
- Profile:存儲用戶的資料
- FollowList:存儲用戶的關注列表
那麼數據模型如何在 Ceramic 上進行創建、共享和重用,從而實現跨應用程序數據互操作性呢?
Ceramic 提供了一個數據模型註冊表(DataModels Registry),這是一個開源的、社區共建的、用於 Ceramic 的可重用應用程序數據模型的存儲庫。在這裡,開發人員可以在其中公開註冊、發現和重用現有數據模型- 這是構建在共享數據模型上的客戶操作應用程序的基礎。目前,它基於 Github 存儲,未來它將分散在 Ceramic 上。
添加到註冊表的所有數據模型都會自動發佈到 @datamodels 的 npm 插件包下面。任何開發人員都可以使用 @datamodels/model-name 安裝一個或多個數據模型,使這些模型可用於在運行時使用任何 IDX 客戶端存儲或檢索數據,包括 DID DataStore 或 Self.ID。
此外,Ceramic 還基於 Github 搭建了一個 DataModels 論壇,數據模型註冊表中的每個模型在該論壇上都有自己的討論線程,社區可以通過它來評論和討論。同時,這裡還可以供開發人員發布關於數據模型的想法,從而在將其添加到註冊表之前徵求社區的意見。目前一切都在早期階段,註冊表中的數據模型並不多,收納進入註冊表中的數據模型應當通過社區的評定成為 CIP 標準,就像以太坊的智能合約標準一樣,這為數據提供了可組合性。
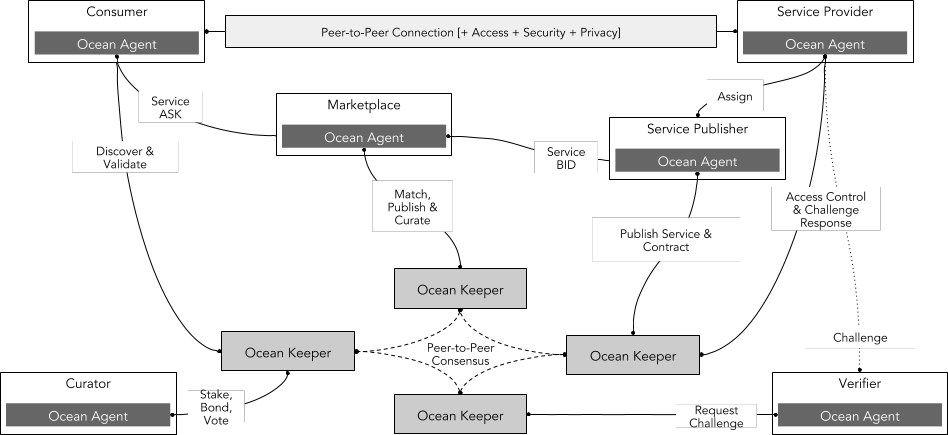
Ocean 的數據交易市場
Ocean Protocol 以數據交易市場為核心,建立了一個去中心化的數據服務供應鍊網絡。下圖顯示了創建數據服務供應鏈所需的主要服務,提供數據、算法、計算、存儲、分析和策劃。這些組件與服務執行協議(如服務等級協議)、安全計算、訪問控制和許可綁定在一起。
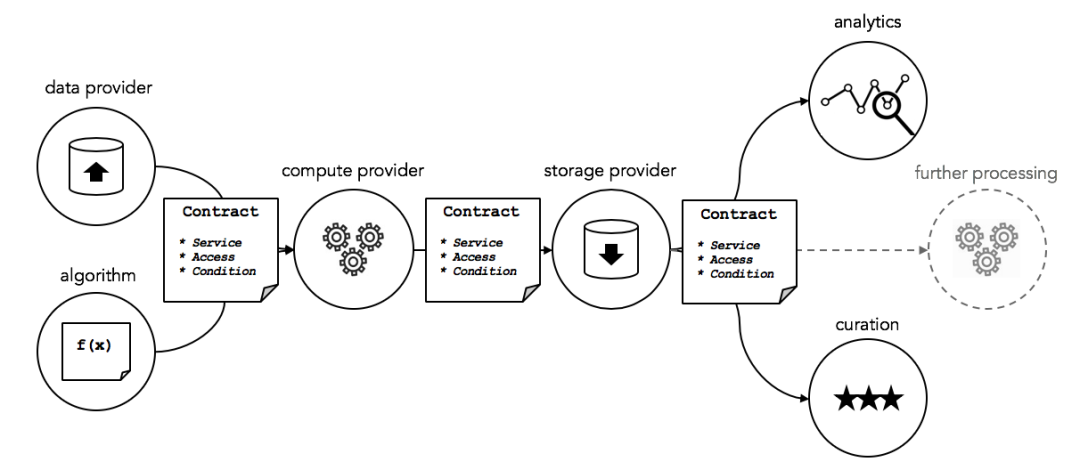
主要的參與角色為數據使用者、服務提供者、市場、服務發布者、驗證者和策展人。Ocean 提供了全套數據科學工具,數據使用者可以在 Ocean 上建立數據服務管道以自動化運行數據算法從而對數據進行加工處理以及價值發現。在這個過程中,數據使用者無法下載全部數據集以及看到全部數據集,因此保護了數據集不被盜取,使用者購買的是數據集的使用權,而非擁有該數據集。
除此之外,Ocean 還和其他機構合作建立數據市場,如它與梅賽德斯-奔馳的去中心化數據市場 [Acentrik] (https://acentrik.io/) 在其最近推出的 Enterprise Release 中聯手。Acentrik Marketplace 由 OceanONDA V4 智能合約和庫驅動,可以發布數據服務、部署和鑄造數據代幣和 Acentrik 資產管理代幣,並通過花費來消費數據服務。
3.1 數據的使用與堆棧
基於以上內容的理解,我們提出了 Web3 數據堆棧,見下圖,
- 最底層是數據源所存儲的地方,包括去中心化存儲、鏈上和鏈下數據等;
- 其次是針對這些數據的管理應用,包括數據庫、數據表、索引中間件以及數據市場等;
- 在一定的數據管理範式下,能夠對數據進行挖掘,包括算法建模、統計分析和數據可視化等;

圖片來源:Zonff Partners
目前行業內關於 Web3 的數據使用,絕大多數是鏈上數據,層出不窮的數據分析工具與索引工具出現,鏈上數據這個巨大的金礦已經被充分地挖掘,上圖的數據表和分析應用分類中絕大多數都是鏈上數據的挖掘,只有少部分涉及到鏈下數據。總的來說,數據的使用鏈路是一個 ETLA(Extract、Transform、Load、Analysis)的過程,每個節點上都具有代表性的項目。提取(Extract)項目的代表是 The Graph,而轉換(Transform)成可用數據表和加載(Load)環節的項目代表是 Dune 和 Luabsae,分析(Analysis)的代表是 Nansen 和 NFTGO。
而在去中心化存儲上 ETLA 整個流程的支持項目幾乎還是荒漠,只有一些提取類項目,這裡存在巨大的機遇和挑戰。The Graph 和 Ceramic 社區本身正致力於提取 Ceramic 上的數據,Orbis 的創始人也嘗試做了一個 Cerscan 用於瀏覽 Ceramic 上的數據。Arweave 已經可以通過 The Graph 用子圖讀取和管理 Arweave 存儲的數據,Filecoin 上也有相關第三方項目在做這件事情。但 TLA 的過程目前還無人問津,其中最大的原因是存儲在不同去中心化存儲上的數據異質性很高,很難有一個統一的模式去挖掘這些數據的價值,其中最有希望踏出這一步的是 Ceramic,這是因為其數據模型的存在使得 Ceramic 上數據的異質性指數級降低,從而使得數據的可利用性變得更高。
除了鏈上數據以外,還有很多項目在嘗試將鏈上數據與鏈下數據進行打通,這類項目可以看作為 “鏈改” 型項目。
類型分類有:
- Web2 數據主權賦予與交易市場:Itheum、Navigate、Swash 和 Phyllo 等。這類項目主要是將傳統互聯網數據與鏈上數據相結合,希望把 Web2 與 Web3 之間的信息交互打通,常見做法是將 Web2 數據導出再導入指定數據池或者直接綁定傳統互聯網社交賬號等等;
- 企業數據共識:Authtrail,該項目通過與企業內部數據庫進行整合,加入共識層從而做到企業內數據的防篡改與可追踪等;
- 鏈上與鏈下數據組合:Space and Time,該項目和 Authtrail 一樣會做鏈下數據庫的整合,但無共識層,更多是鏈下與鏈上數據的共同計算,此外 Pool 也在做類似的事情;
Web3 數據的使用範式和 Web2 存在明顯的不同,其主要在於數據聚集在一起的方式,即不同類型的數據其存儲、索引、提取、整合和利用的方式都會存在差別。根據前文的分類,這裡做一些簡單的總結:
公開數據:包括《網絡安全標準實踐指南- 數據分類分級指引》分類中的公共數據和部分法人數據。作為公共產品,是可以被公開挖掘價值的數據,接入無需許可,但可以追溯用戶所有權,從而追溯空投分潤,典型的例子是鏈上數據和存儲在去中心化存儲上的非加密應用數據(如用戶帖子、點贊和評論等)。其使用最重要的上游支持是索引應用,如 The Graph,或 Web3 原生數據庫的應用,如 Tableland。
私密數據:包括《網絡安全標準實踐指南- 數據分類分級指引》分類中的個人信息和部分法人數據。作為需要加密存儲,且需要一定隱私權限配置的數據類型,其接入有許可,不可被公開獲取,若存儲在去中心化存儲和區塊鏈上,則需要可權限配置的加密存儲。或通過其他手段,如 ZK、MPC 和 TEE 等隱私技術手段保護。其使用最重要的上游支持是數據庫應用,如 Kwil 和 Ceramic 等。
免責聲明:作為區塊鏈信息平台,本站所發布文章僅代表作者及嘉賓個人觀點,與 Web3Caff 立場無關。文章內的信息僅供參考,均不構成任何投資建議及要約,並請您遵守所在國家或地區的相關法律法規。