

透過歷史脈絡了解自主權身份
— 導讀/ 原用標題
原文:Seeing Self-Sovereign Identity in Historical Context(IDENTITY WOMAN)
編譯: zCloak Network
摘要
當前,出現了一套名為"自我主權身份"(SSI)的新技術標準,它重新構造了數字身份系統的工作方式。我的論題是,這種新組態的出現,與西方社會系統進化出的身份系統——用以開展大規模工作、基於早期紙質技術的興起方式非常一致。
為了說明這一點,我追溯了兩段不同的歷史。
第一段歷史有關在計算機系統中設計和管理身份的方式。新興的 SSI 的創新是計算機身份系統設計中的一個重大突破。
第二段歷史考察了出現在歐洲的紙質身份系統的演變。在有關第二段歷史的行文中,整合了一項最近的學術研究,有關於伴隨第一批紙質身份文件的出現而出現的特殊社會心理學。這項學術研究解釋了紙質身份意味著什麼,以及為什麼它被接受並對人們有意義。
本文的最後一節將這兩段歷史結合起來,解釋了為什麼 SSI 的基本技術設計是與西方自由民主價值觀相一致的,而早期的數字身份系統設計卻沒有做到這一點。
引言
開發者和政策制定者都認為當下的社會系統和技術系統是一個既定事實。現有的系統是給定的這一假設,適用於紙質身份系統、數字身份系統,也適用於與我們緊密相關並用來形成我們身份的社會系統。本文采取唯物主義的方式,將所有事物視為過程的結果。
本文的第一部分,為不熟悉自我主權身份(SSI:Self-Sovereign Identity)技術的讀者回顧了該技術的一些基本知識,但並不是講訴 SSI 的發展歷史。
第二部分解釋了自計算機出現以來,數字身份系統是如何演變的。這一節為非專業人士明確了這些早期系統之間的關鍵區別。例如,新的 SSI 系統減少了內在的跟踪機會,因此也就降低了早期數字身份系統以及當前企業身份和訪問管理主流技術架構的隱私風險。
第三部分探討瞭如今廣泛使用的紙質身份系統的歷史,解釋了它們是如何運作的,以及為什麼要在可問責性和可見性之間對它們做出有效的跨系統權衡。相比大多數其它的記述,本節對這段歷史追溯到了更早的時期—— 從公元 500 年左右天主教會的行動開始。這一節整合了最近的一項學術研究,即當第一批紙質身份文件誕生的時候,出現了一種特定的社會心理學,它闡述了這些文件是被人們接受,且對他們是有一定意義的。該項學術研究還回顧了紙質身份文件從最初出現到現在的材料演進過程。
第四部分解釋了 SSI 技術與其它數字身份管理模式的不同之處—— 特別是企業身份、訪問管理,和消費者身份提供者模型。它們的主要區別在於,SSI 提供了一種以數字格式表達具有高置信度數字證書的方法,而無需將身份信息錨定到一些諸如由國家或企業實體控制的網絡端點等類型的標識符上。紙質文件擁有一種品質,即一旦將它發放給個人,文件就完全由個人控制,個人可以僅向他們選擇的任何人展示這份文件。而 SSI 提供了在數字世界中恢復這種品質的方法。此外,SSI 通過限制個人為驗證其身份各方面情況而必須透露的信息,提高了早期身份系統的效率和安全性。
我的工作使我每天都在和技術專家、商業領袖和政策制定者打交道。我所在的社區充滿了真摯的人,他們努力為新興的數字身份系統開發良好的設計。我天生熱愛研究知識,廣泛地閱讀了一系列學科知識,包括那些專注於設計和理解系統的學科,我在本文中運用了自己在這些領域的知識素養。
全文通篇解釋了紙質身份和數字身份的基礎系統設計,並探討了每一種身份在各自歷史背景下的品質。這包括探討這些身份本身,以及它們與現實世界的相交點—— 西方自由民主國家(新西蘭、加拿大、美國、歐盟)設計的基於 SSI 的系統。
這些有關身份的哲學問題,可能自從人類首次獲得意識以來就已經存在了。如果不承認這些問題的存在,就無法合理地書寫身份。我們在各種文化的神話、故事、宗教和哲學中都能找到它們。所問的主要問題是"我是誰?"、"我是否不僅僅是我的身體" 等等。我把這些正統的探索路徑擱置一旁,選擇用歷史唯物主義的方法來解讀人類身份的建立。這種方法認為"所有圍繞在我們周圍的,並形成現實結構(山脈、動物和植物、人類語言、社會機構)的東西,都是特定歷史過程的產物"。
在繼續之前,我必須強調,在這種歷史唯物主義傳統中,一切都源於過程。每一個你可以指出的、你可以識別的"東西",都是隨著時間推移而出現的過程的結果;我們作為人類生活在身體裡是過程的結果;在我們生活的複雜社會中,我們為指出或識別出人們身份而創造的物品,如"身份文件",也是這些過程的結果。鑑別本身就是一個過程。
當討論"身份" 時,似乎被識別的實物對像一直都是我們關注的重點,然而,塑造身份文件的歷史過程或是用來表達身份的技術往往被忽略。含有"身份信息" 的文件是那些歷史決定、歷史事件和幫助組織運作的創新所共同形成的結果。一個人本身以及他的身份文件都具有物質性體現,但它們是如何形成的,或者說創造它們的過程是怎樣的,是與它們的"物性" 同樣重要的。
我引入這個錨定框架來理解歷史進程,是因為我將在本文中使用它來解釋各種身份系統的進程。通過觀察這些進程,可以發現和理解這些系統之間的關鍵差異。如果著眼於"東西" 或產生的人工製品,差異就不那麼明顯了。不同身份架構的形成,是通過對人們有著不同含義的進程,以及通過人們和組織交互權力關係的過程來達到的。
第一部分:SSI 技術
以下是對 SSI 的簡要概述,並非是講訴其歷史。關於其歷史發展,推薦閱讀《自我主權身份》一書中的第 16 章。
本節涵蓋了 SSI 的基本架構和核心標準,以便:a)可以在技術部分討論 SSI 和其它系統的差異;b)可以在最後一節探討 SSI 是否適合取代紙質的身份文件。
可驗證憑證
可驗證憑證(VC:Verifiable Credentials)是一種萬維網聯盟(W3C:World Wide Web Consortium)規範,它定義了數字憑證的通用數據格式以及如何分享其真實性證明。一個憑證可以證明一個實體想要證實的關於另一個實體的任何東西,並且適用於多種目的。舉例來說,政府頒發的出生證明憑證,民間社會頒發的專業協會會員資格證書;又比如,商店的會員卡屬於商業憑證;員工徽章屬於就業憑證。

由於巧妙地使用了公私鑰加密技術,憑證發行者(Issuer)和憑證驗證者(Verifier)無需直接通信。Issuer 在將證書作為結構化數據發放給憑證持有者(Holder)之前,會使用他們的私鑰對憑證進行密封。Holder 將這些憑證存儲在他們的數字錢包中,並可以選擇向任何人展示存儲在他們數字錢包中的可驗證憑證,就像你可以有選擇地展示你的物理錢包一樣。
當 Holder 想要向任何 Verifier 出示憑證時,Holder 會發送一個可驗證的憑證呈現。然後,通過使用 Issuer 的公鑰,Verifier 進行數學計算以驗證數據結構是否來源於 Issuer 且沒有被更改。具體一點說,由於 Issuer 的公鑰是被廣泛共享的(有時通過區塊鏈),所以 Verifier 可以使用數學計算來驗證 Holder 的可驗證憑證的真實性。
自可驗證憑證規範第 1 版(2018 年)編制以來,開發人員已顯著擴大了其有效性,可以更好地保護隱私。也就是說,Holder 現在可以只是提供特定的信息,而無需提供整個憑證。舉例來說,Holder 可以因此只顯示他們的年齡,而非具體的出生日期;或者,Holder 可以證明他們曾在軍隊服役,但不必共享他們曾在哪個部門服役或其具體服役日期;又或者,Holder 可以證明他們是某所學校的學生,但不透露他們的學生號。這種類型的共享被稱為選擇性披露。
去中心化標識符
為了更好的支持可驗證憑證和(與 Issuer 相關的)加密密鑰資料之間的交換,我們需要一個用於管理的應用程序以及與其相關的存儲,該應用程序還必須使用由 Holder 生成和管理的加密密鑰資料,但這些資料從未存儲在任何其他人那裡。
管理這類資料是很困難的。早期的系統使用特殊的密鑰註冊服務,來發布與特定電子郵件地址相關聯的公鑰。也就是說,如果某人欲向某特定地址發送加密安全的電子郵件,那麼他可以使用與收件人電子郵件地址相關聯的公鑰來達到該目的。為了解密來自特定發件人的消息,收件方將查詢發件人的公鑰並確定它來自該發件人。
可驗證憑證系統的密鑰管理規模非常巨大,要知道,一個數據庫,如 MIT 的密鑰服務器,或一個網站,如 keys.openpgp.org,並不具有規模。依靠這樣的中心化的服務會使系統變得脆弱和易損。
除此之外,更重要的是,與電子郵件地址相關聯的密鑰被錨定在一個全球性的中心化系統上。SSI 技術的革新者決定以一種既可擴展又可訪問但不受中心化機構控制的方式來存儲和管理密鑰。
開發人員需要向用戶提供持久的標識符和指向加密密鑰的指標。儘管如此,在更新這些密鑰可以解鎖的內容時,密鑰管理員仍需重新為一個標識符分配不同的密鑰。和上面描述的 MIT 密鑰數據庫一樣,開發人員不能將加密密鑰存儲在那些分配給某電子郵件地址的固定數據庫中。開發人員需要找到另一個抽象級別,以便隨著時間的推移,與持久的去中心化標識符相關聯的加密密鑰仍可以進行輪換。區塊鏈集體管理著數據庫(無論是需要權限的還是無需權限的),數據一旦寫入就不可擦除。儘管可驗證憑證可以在沒有去中心化標識符或沒有區塊鏈的情況下發行,但當這兩項創新碰撞一起時,則為以可解析的方式共享密鑰提供了一個有益的通用標準。以下是來自 W3C 標準的描述。
去中心化標識符(DID)是一種新型標識符,能夠實現可驗證的、去中心化的數字身份。DID 可以識別任何主體(如個人、組織、事物、數據模型、抽象實體等),DID 的管理者(Controller)決定它可以識別這些主體。與典型的聯合標識符相比,DID 的設計使它們可以與中心化的註冊機構、身份提供者和證書頒發機構解耦。具體來講,雖然其它各方可能被用來幫助發現與 DID 相關的信息,但這種設計使 DID 管理者在無需任何其他各方許可的情況下,就可證明其對 DID 的控制權。DID 是將 DID 主體與 DID 文檔關聯起來的統一資源標識符(URI:Uniform Resource Identifiers),可以與其主體進行可信交互。
每個 DID 文檔都可表達加密材料、驗證方法或服務端點。它提供了一套機制,使 DID 管理者能夠證明其對 DID 的控制。服務端點支持與 DID 主體關聯的可信交互。另外,一個 DID 文檔可能包含其 DID 主體本身,也就是說,如果一個 DID 主體是一種信息資源,如數據模型,那麼該 DID 文檔中也將包含這些信息資源本身。
該規範包括一個通用數據模型、一種 URL 格式和一組用於 DID、DID 文檔和 DID 方法的操作指導。
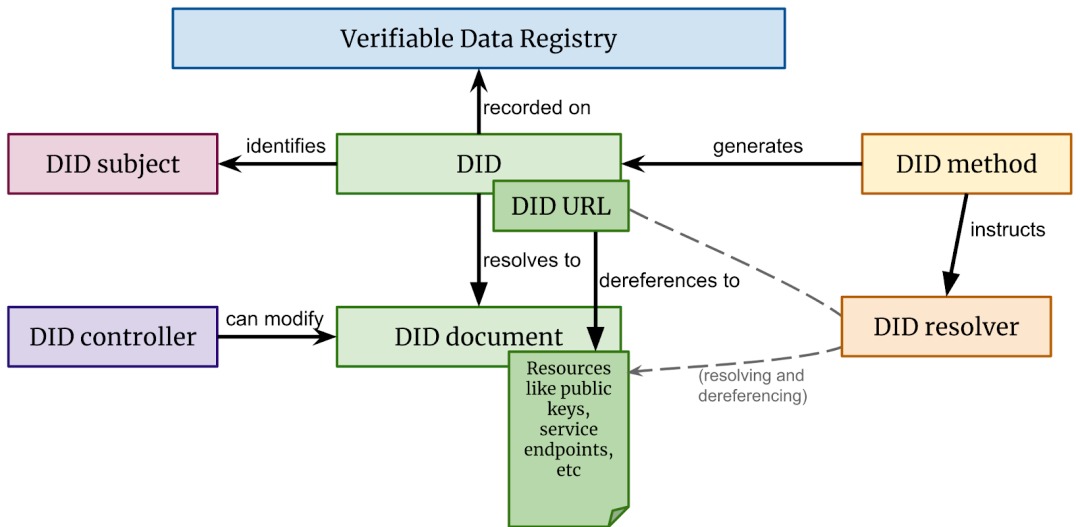
 圖 2. W3C DID 規範中, DID 文檔和 DID 關鍵組件之間的關係圖
圖 2. W3C DID 規範中, DID 文檔和 DID 關鍵組件之間的關係圖去中心化標識符與早期的標識符系統形成了鮮明的對比,早期的標識符系統要么是永久固定在全球化性的註冊中心(例如,基於 ICANN 創建在 DNS 上的域名,或基於 ITU-T 的電話號碼),要么是固定在私有命名空間中,如網站(在域名系統內)的用戶名、Twitter 賬號或 Instagram 賬號。
去中心化標識符是技術架構上的一個突破,它將標識符的控制權,通過實體所控制的軟件,集中在了其實體本身。另外,標識符不再需要由一些外部發行機構來分配,實體本身就可以生成標識符。這些標識符的所有權可以被證明是獨立於任何"發行機構" 的,這種證明是通過使用公私鑰密碼學的特性實現的。
去中心化標識符並非一定要存儲在區塊鏈上才有效。任何實體(個人或組織)都可創建和擁有一個 DID,與該 DID 相關聯的公鑰可以連接到任何其他各方,而這些連接對雙方來說可以是具有唯一性的。一個正在開發的名為 DIDComm 的規範,將標準化這種類型的通信。
DIDComm 與之前的一些技術形成了對比,比如通過 PGP 的加密安全電子郵件。電子郵件通過 PGP,以可公開訪問的形式,在密鑰服務器上公佈相關的公鑰。所有發送到這個郵件地址的信息都會使用該公鑰,這使得每個連接都喪失了唯一性。另外,和像 WhatsApp、Signal 和 Telegram 這樣被廣泛使用的消息傳遞應用程序相比, DIDComm 也有所不同。前者在每個連接中都使用唯一的密鑰對,雖然它們避免了用戶名/標識符,但利用電話號碼來作為一個可識別網絡中用戶的持久標識符,這是一種"作弊" 行為。每次與其它方連接時,它們也不會交換這些不同的密鑰,而是選擇在它們參與的所有連接中都共享使用一個單一的公鑰。
(因本文篇幅過長,後續詳見中、下篇)
免責聲明:作為區塊鏈信息平台,本站所發布文章僅代表作者及嘉賓個人觀點,與 Web3Caff 立場無關。本文內容僅用於信息分享,均不構成任何投資建議及要約,並請您遵守所在國家或地區的相關法律法規。










