

乍一看,AI 和 Web3 似乎是相互獨立的技術,各自基於根本不同的原理,並服務於不同的功能。然而,深入探討會發現,這兩種技巧有機會平衡彼此的權衡取捨,彼此獨特的優勢可以相輔相成,互相提升。
作者: IOSG Ventures
封面: Photo by Faded_Gallery on Unsplash

本文僅供學習交流使用,不構成任何投資建議。轉載請註明出處,並與 IOSG 團隊聯繫以取得授權及轉載須知。文章中提及的所有項目並非推薦或投資建議。
乍一看,AI x Web3 似乎是一種相互獨立的技術,各自基於根本不同的原理,並服務於不同的功能。然而,深入探討會發現,這兩種技巧有機會平衡彼此的權衡取捨,彼此獨特的優勢可以相輔相成,互相提升。 Balaji Srinivasan 在 SuperAI 大會上精闢地闡述了這項互補能力的概念,激發了對這些技術如何相互作用的詳細比較。
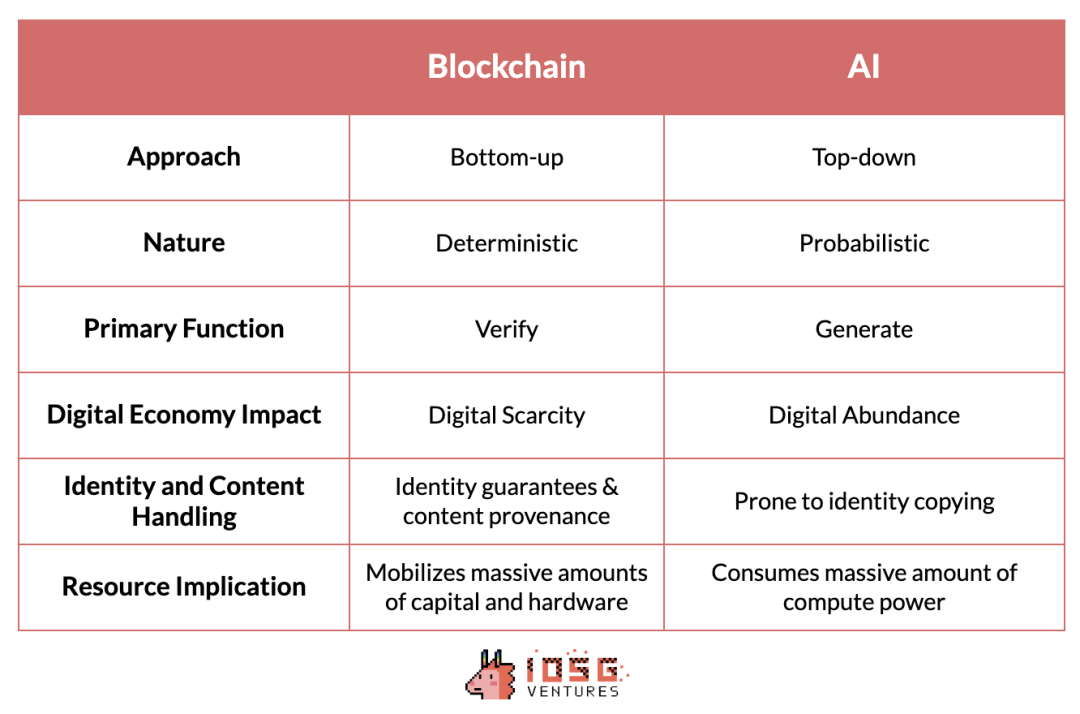
Token 採用由下而上的方法,從匿名網路龐克的去中心化努力中興起,十多年的時間透過全球眾多獨立實體的協同努力不斷演變。相反,人工智慧是透過自上而下的方法開發的,由少數科技巨頭主導。這些公司決定了產業的步伐和動態,進入門檻更多是由資源密集度而非技術複雜性決定的。
這兩種技術也有著截然不同的本質。本質上,Token 是確定性系統,產生不可改變的結果,例如雜湊函數或零知識證明的可預測性。這與人工智慧的機率性和通常不可預測性形成了鮮明對比。
同樣,加密技術在驗證方面表現出色,確保交易的真實性和安全性,並建立無信任的流程和系統,而人工智慧則專注於生成,創造豐富的數位內容。然而,在創造數位豐富的過程中,確保內容來源和防止身分盜用成為一個挑戰。
幸運的是,Token 提供了數位豐富的對立概念——數位稀缺性。它提供了相對成熟的工具,可以推廣到人工智慧技術,以確保內容來源的可靠性並避免身分盜用問題。
Token 的一個顯著優勢是其吸引大量硬體和資本進入協調網絡,以服務特定目標的能力。這項能力對消耗大量運算能力的人工智慧尤為有利。動員未充分利用的資源以提供更廉價的運算能力,能夠顯著提升人工智慧的效率。
透過將這兩大技術進行對比,我們不僅可以欣賞它們各自的貢獻,還可以看到它們如何共同開創技術和經濟的新道路。每一種技術都能彌補另一種技術的不足,創造一個更整合、更創新的未來。在這篇部落格文章中,我們旨在探索新興的 AI x Web3 產業圖譜,並重點介紹這些技術交叉點上一些新興的垂直領域。
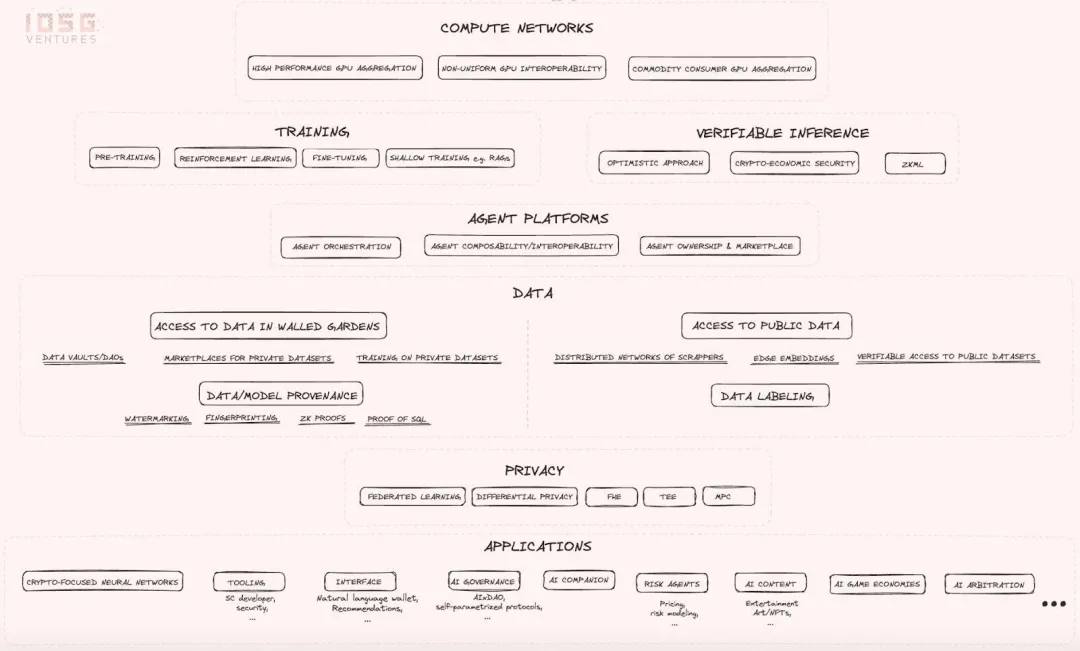
2.1 計算網絡
產業圖譜首先介紹了運算網絡,它們試圖解決受限的 GPU 供應問題,並嘗試以不同的方式降低運算成本。值得重點關注的是以下幾項:
- 非統一 GPU 互通性:這是一個非常雄心勃勃的嘗試,技術風險和不確定性都很高,但如果成功,將有可能創造出規模和影響巨大的成果,使所有運算資源變得可互換。本質上,這個想法是建立編譯器和其他前提條件,使得在供應端可以插入任何硬體資源,而在需求端,所有硬體的非統一性將完全被抽象化,這樣你的計算請求可以路由到網絡中的任何資源。如果這個願景成功,將降低目前對 AI 開發者完全主導的 CUDA 軟體的依賴。儘管技術風險很高,許多專家對這種方法的可行性持高度懷疑態度。
- 高效能 GPU 聚合:將全球最受歡迎的 GPU 整合到分散式且無權限的網路中,而無需擔心非統一 GPU 資源之間的互通性問題。
- 商品消費級 GPU 聚合:指向聚合一些效能較低但可能在消費性設備中可用的 GPU,這些 GPU 是供應端最未充分利用的資源。它迎合了那些願意犧牲性能和速度以獲得更便宜、更長訓練過程的人群。
2.2 訓練與推理
計算網路主要用於兩個主要功能:訓練和推理。這些網路的需求來自於 Web 2.0 和 Web 3.0 專案。在 Web 3.0 領域,像 Bittensor 這樣的專案利用運算資源進行模型微調。在推理方面,Web 3.0 專案強調過程的可驗證性。這項重點催生了可驗證推理作為一個市場垂直領域,計畫們正在探索如何將 AI 推理整合到智能合約中,同時保持去中心化的原則。
2.3 智能代理平台
接下來是智慧代理平台,圖譜概述了這一類別中的新創公司需要解決的核心問題:
- 代理互通性與發現及通訊能力:代理之間能夠互相發現與溝通。
- 代理集群建構和管理能力:代理能夠組成集群並管理其他代理。
- AI 代理商的所有權和市場:為 AI 代理商提供所有權和市場。
這些特性強調了靈活和模組化系統的重要性,這些系統可以無縫整合到各種區塊鏈和人工智慧應用中。 AI 代理有可能徹底改變我們與網路的互動方式,我們相信代理商將利用基礎設施來支援其營運。我們設想 AI 代理在以下幾方面依賴基礎設施:
- 利用分散式抓取網路存取即時網路數據
- 使用 DeFi 管道進行代理間支付
- 需要經濟押金不僅是為了在不當行為發生時進行懲罰,還可以提高代理的可發現性(即在發現過程中利用押金作為經濟訊號)
- 利用共識決定哪些事件應導致削減
- 開放的互通性標準和代理框架以支援建立可組合的集體
- 根據不可變的數據歷史來評估過去的表現,並即時選擇合適的代理集體

2.4 資料層
在 AI x Web3 的融合中,資料是一個核心組成部分。數據是 AI 競爭中的策略資產,與運算資源一道構成關鍵資源。然而,這個類別往往被忽視,因為業界的大部分注意力都集中在計算層面。實際上,原語在資料取得過程中提供了許多有趣的價值方向,主要包括以下兩個高層次方向:
- 存取公共互聯網數據
- 存取被保護的數據
存取公共互聯網資料:這個方向旨在建立分散式爬蟲網絡,可以在幾天內爬取整個互聯網,獲取大量資料集,或即時存取非常具體的互聯網資料。然而,要爬取網路上的大量資料集,網路需求非常高,至少需要幾百個節點才能開始一些有意義的工作。幸運的是,Grass,一個分散式爬蟲節點網絡,已經有超過 200 萬個節點積極向網路共享互聯網頻寬,目標是爬取整個互聯網。這顯示了經濟誘因在吸引寶貴資源方面的巨大潛力。
儘管 Grass 在公共數據方面提供了公平的競爭環境,但仍有利用潛在數據的難題——即專有數據集的存取問題。具體來說,仍有大量資料因其敏感性質而以隱私保護的方式保存。許多新創公司正在利用一些密碼學工具,使 AI 開發者能夠在保持敏感資訊私密的同時,利用專有資料集的基礎資料結構來建立和微調大型語言模型。
聯邦學習、差分隱私、可信任執行環境、全同態和多方運算等技術提供了不同程度的隱私保護和權衡。 Bagel 的研究文章(https://blog.bagel.net/p/with-great-data-comes-great-responsibility-d67)總結了這些技術的優秀概述。這些技術不僅在機器學習過程中保護資料隱私,還可以在運算層面實現全面的隱私保護 AI 解決方案。
2.5 資料與模型來源
資料和模型來源技術旨在建立可以向使用者保證他們正在與預期模型和資料互動的過程。此外,這些技術還提供真實性和來源的保證。以水印技術為例,水印是模型來源技術之一,它將簽名直接嵌入到機器學習演算法中,更具體地說是直接嵌入到模型權重中,這樣在檢索時可以驗證推理是否來自預期的模型。
2.6 應用
在應用方面,設計的可能性是無限的。在上面的產業版圖中,我們列出了一些隨著 AI 技術在 Web 3.0 領域的應用而特別令人期待的發展案例。由於這些用例大多是自我描述的,我們在此不作額外評論。然而,值得注意的是,AI 與 Web 3.0 的交匯有可能重塑領域的許多垂直領域,因為這些新原語為開發者創造創新用例和優化現有用例提供了更多的自由度。
總結
AI x Web3 融合帶來了充滿創新和潛力的前景。透過利用每種技術的獨特優勢,我們可以解決各種挑戰,並開闢新的技術路徑。在探索這個新興產業時, AI x Web3 之間的協同作用可以推動進步,重塑我們的未來數位體驗和我們在網路上的互動方式。
數位稀缺與數位豐富的整合、未充分利用資源的動員以實現運算效率,以及安全、隱私保護的資料實踐的建立,將定義下一代技術演進的時代。
然而,我們必須認識到,這個行業仍處於起步階段,目前的行業版圖可能在短時間內變得過時。快速的創新節奏意味著今天的前沿解決方案可能很快就會被新的突破所取代。儘管如此,所探討的基礎概念——如運算網路、代理平台和資料協定——突顯了人工智慧與 Web 3.0 融匯的巨大可能性。
免責聲明:作為區塊鏈資訊平台,本站所發布文章僅代表作者及來賓個人觀點,與 Web3Caff 立場無關。文章內的資訊僅供參考,均不構成任何投資建議及要約,並請您遵守所在國家或地區的相關法律法規。










