

看 Crypto 如何開戰人工智慧資料的爭奪
原文:The Data Must Flow(Decentralised.co)
編譯:LlamaC
封面: Photo by Martin Martz on Unsplash
「推薦寄語:本文為渴望真正理解 Ai 並探索 Crypto 與 Ai 有機結合將如何塑造新世界的人準備,給所有對未來充滿好奇、渴望在技術大潮中找到自己位置的讀者。無論你是技術開發者、產業分析師、機制制定者,還是只是一個對科技如何塑造我們生活感興趣的思考者,這篇文章都將為你提供了全面的知識和啟發。新時代,共同見證並參與這場前所未有的科技革新。
正文
1,500 萬張圖片<> 22,000 個類別
這是 ImageNet 的資料集大小,當時普林斯頓大學的助理教授李飛飛想要創建它。她希望這樣做能夠幫助推動電腦視覺這一停滯不前的領域的發展。這是一個大膽的嘗試。 22,000 個類別至少比以前創建的任何圖像資料集都多兩個數量級。
她的同行認為,建構更好的人工智慧系統的答案在於演算法創新,他們質疑她的智慧。 “我越和同事們討論 ImageNet 的想法,我感到越孤獨。 ”
儘管遭到懷疑,飛飛和她的小團隊——包括博士候選人 Jia Deng 和幾名時薪 10 美元的本科生——開始標記來自搜尋引擎的圖像。進展緩慢而痛苦。 Jia Deng 估計,以他們的速度,完成 ImageNet 將需要 18 年——沒有人有這個時間。就在這時,一位碩士生向飛飛介紹了亞馬遜的 Mechanical Turk,這是一個透過眾包來自世界各地的貢獻者完成「人類智慧任務」的市場。飛飛立刻意識到這正是他們所需要的。
在 2009 年,也就是飛飛開始她生命中最重要的計畫三年後,在一支分散的全球勞動力的幫助下,ImageNet 終於準備好了。在推動電腦視覺的共同使命中,她已經盡了自己的一份心力。
現在,輪到研究人員開發演算法,利用這個龐大的資料集幫助電腦像人類一樣觀察世界。然而,在最初的兩年裡,並沒有發生這種情況。這些演算法幾乎沒有比 ImageNet 之前的狀態表現得更好。
飛飛開始懷疑她的同事們是否一直對 ImageNet 是徒勞的努力的看法是正確的。
然後,在 2012 年 8 月,就在飛飛放棄希望她的專案能激發她設想的變化時, Jia Deng 急切地打電話告訴她關於 AlexNet 的消息。這個新演算法在 ImageNet 上訓練,超過了歷史上所有的電腦視覺演算法。由多倫多大學的三位研究人員創建,AlexNet 使用了一種幾乎被拋棄的 AI 架構,稱為 “神經網路”,並且超出了飛飛最狂野的預期。
在那一刻,她知道自己的努力已經結出果實。「歷史剛剛被創造,世界上只有少數人知道。」李飛飛在她的回憶錄《我看到的世界》中分享了 ImageNet 背後的故事。
ImageNet 結合 AlexNet 之所以具有歷史意義,有幾個原因。
- 首先,神經網路的重新引用,長期以來被認為是一條死胡同的技術,成為了推動 AI 發展超過十年指數增長的,演算法背後的實際架構。
- 其次,三位來自多倫多的研究人員(其中一位是你可能聽說過的 Ilya Sutskever)是最早使用圖形處理單元(GPU)來訓練 AI 模型的人之一。現在這也是業界標準。
- 第三,AI 產業終於意識到飛飛多年前首次提出的觀點:高階人工智慧的關鍵要素是大量的數據。
我們都讀過也聽過諸如「數據是新石油」和「垃圾進,垃圾出」這樣的諺語無數次。如果這些話不是關於我們世界的基本真理,我們可能會對它們感到厭倦。多年來,人工智慧在幕後逐漸成為我們生活中越來越重要的一部分——影響著我們閱讀的推文、觀看的電影、我們支付的價格以及我們被認為值得的信用。所有這些都是透過精心追蹤我們在數位世界中的每一個舉動來收集數據所驅動的。
但在過去兩年裡,自從一個相對不知名的新創公司 OpenAI 發布了一個名為 ChatGPT 的聊天機器人應用以來,人工智慧的重要性已經從幕後走到了台前。我們正處於機器智慧滲透到我們生活每一個面向的風口浪尖。隨著關於誰將控制這種智慧的競爭升溫,對驅動它的數據的需求也不斷升溫。
這就是這篇文章的主題。我們討論了人工智慧公司所需的數據規模和緊迫性,以及它們在獲取數據時所面臨的問題。我們探討了這種永不滿足的需求如何威脅到我們對網路和數十億貢獻者的熱愛。最後,我們介紹了一些新興的新創公司,它們正在使用加密貨幣來解決這些問題和擔憂。
在我們深入討論之前,快速說明一下:這篇文章是從訓練大型語言模型 (LLMs) 的角度撰寫的,而不是所有 AI 系統。因此,我經常交替使用 “AI” 和 “LLMs”。雖然這種用法在技術上不準確,但適用於 LLMs 的概念和問題,特別是關於數據的問題,也適用於其他形式的 AI 模型。
數據
大型語言模型的訓練受三個主要資源的限制:運算、能源和資料。公司、政府和新創公司同時在爭取這些資源,背後有大量資本支持。在這三者中,對運算的競爭是最激烈的,部分歸功於 NVIDIA 股價的急速上漲。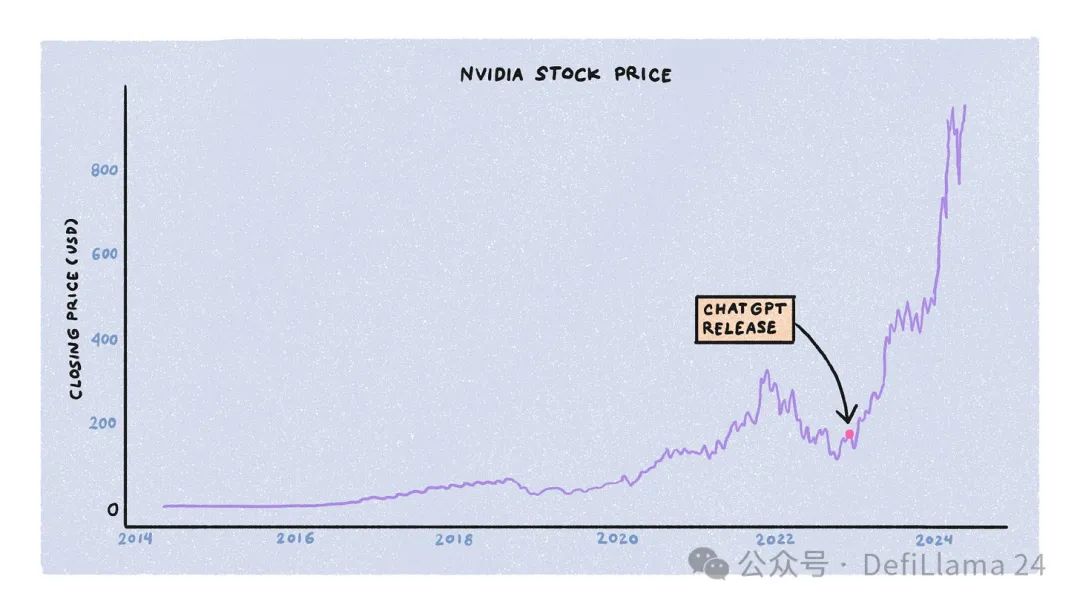
訓練 LLMs 需要大量的專業圖形處理單元 (GPU) 集群,特別是 NVIDIA 的 A100、H100 和即將推出的 B100 型號。這些不是你可以從亞馬遜或當地電腦商店現成購買的計算機。相反,它們成本高達數萬美元。 NVIDIA 決定如何將其供應分配給 AI 實驗室、新創公司、資料中心和超大規模的客戶。
在 ChatGPT 發布後的 18 個月裡,GPU 需求遠遠超過了供應,等待時間高達 11 個月。然而,隨著最初的狂熱塵埃落定,供需動態正在正常化。新創公司倒閉、訓練演算法和模型架構的改進、其他公司的專用晶片的出現,以及 NVIDIA 增加生產,所有這些都有助於增加 GPU 的可用性和價格的遞減。
第二,能源。在資料中心運作 GPU 需要大量的能源。根據某些估計,到 2030 年,資料中心將消耗全球能源的 4.5%。由於這種激增的需求給現有的電網帶來壓力,科技公司正在探索替代能源解決方案。亞馬遜最近以 6.5 億美元購買了一座由核電廠供電的資料中心。微軟已經聘請了一個核子技術負責人。 OpenAI 的 Sam Altman 支持了像 Helion、Exowatt 和 Oklo 這樣的能源新創公司。
從訓練 AI 模型的角度來看—能源和計算只是商品。使用 B100 而不是 H100,或使用核能而不是傳統能源可能會使訓練過程更便宜、更快、更有效率——但這不會影響模型的品質。換句話說,在創造最聰明、最像人類的 AI 模型的競賽中,能源和計算是基本要素,而不是區分因素。
關鍵資源是數據。
James Betke r 是 OpenAI 的研究工程師。用他自己的話來說,他已經訓練了「比任何人都有權訓練的更多生成模型」。在一篇部落格文章中,他指出,「在相同的資料集上訓練足夠長的時間,幾乎所有具有足夠權重和訓練時間的模型都會收斂在同一點上。」這意味著區分一個 AI 模型與另一個 AI 模型的是資料集。沒有別的。
當我們提到一個模型為「ChatGPT」、「Claude」、「Mistral」或「Lambda」時,我們談論的不是架構、使用的 GPU 或消耗的能源,而是它所訓練的資料集。
如果資料是 AI 訓練的食物,那麼模型就是吃他們的東西。
訓練一個最先進的生成模型需要多少資料?
答案:很多。
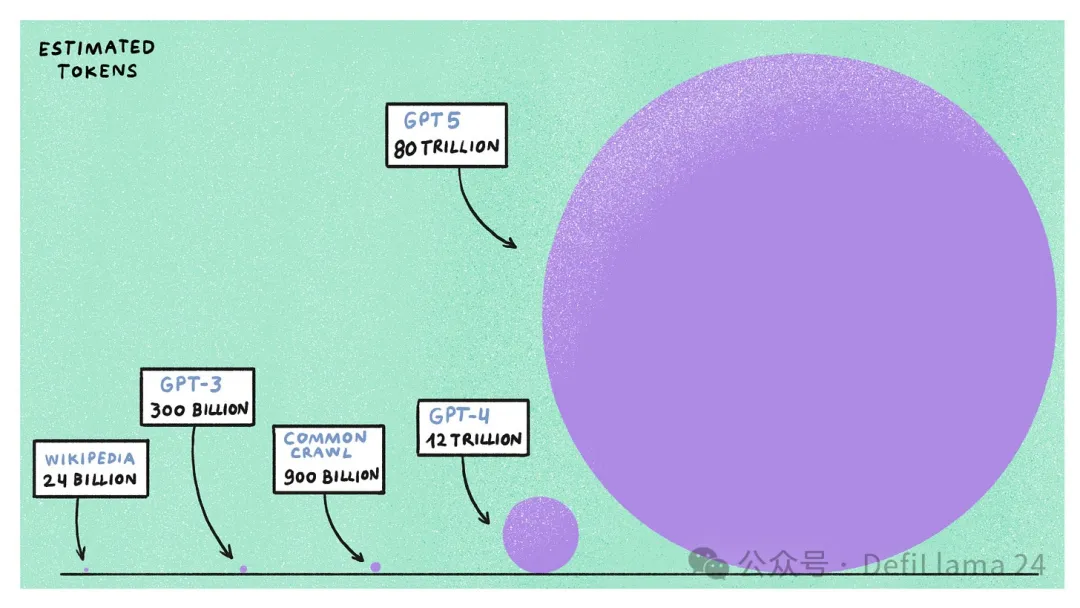
GPT-4,在發布一年多後仍被認為是最好的大型語言模型,它在估計 1.2 兆個 token(或約 9000 億個單字)上進行了訓練。這些資料來自公開可用的互聯網,包括維基百科、Reddit、Common Crawl(一個免費開放的網路爬取資料儲存庫)、超過一百萬個轉錄 YouTube 資料小時,以及像 GitHub 和 Stack Overflow 這樣的程式碼平台。
如果你認為那是很多數據,請稍等。在生成 AI 中有一個概念叫做 “Chinchilla Scaling Laws”,它指出,對於給定的計算預算,在較大資料集上訓練較小模型比在較小資料集上訓練較大模型更有效。如果我們推斷 AI 公司為訓練下一代 AI 模型(如 GPT-5 和 Llama-4)所分配的運算資源——我們發現這些模型預計需要五到六倍的運算能力,使用高達 100 兆個 token 進行訓練。
由於大多數公共網路資料已經被爬取、索引並用於訓練現有模型,那麼額外的資料從哪裡來?這已經成為 AI 公司的前沿研究問題。有兩種方法可以解決這個問題。一種是你決定使用由 LLMs 直接產生的合成數據,而不是由人類產生。然而,這種數據在使模型變得更聰明方面的有效性尚未經過測試。
另一種選擇是簡單地尋找高品質數據而不是合成創建。然而,取得額外數據具有挑戰性,特別是當 AI 公司面臨的問題不僅威脅到未來模型的訓練,也威脅到現有模型的有效性時。
第一個數據問題涉及法律問題。儘管 AI 公司聲稱他們在「公開可用資料」上訓練模型,但其中許多是受版權保護的。例如,Common Crawl 資料集包含了來自《紐約時報》和美聯社等出版物的數百萬篇文章,以及其他受版權保護的資料,如出版的書籍和歌詞。
一些出版物和創作者正在對 AI 公司採取法律行動,聲稱他們侵犯了他們的版權和智慧財產權。《泰晤士報》起訴 OpenAI 和微軟「非法複製和使用《泰晤士報》獨特且有價值的作品」。一群程式設計師提起集體訴訟,質疑使用開源程式碼訓練 GitHub Copilot(一種流行的 AI 程式設計助手)的合法性。
喜劇演員薩拉·西爾弗曼和作家保羅·特雷姆布萊也因未經許可使用他們的作品而起訴 AI 公司。
其他人則透過與 AI 公司合作來擁抱變革的時代。《美聯社》、《金融時報》和 Axel Springer 都與 OpenAI 簽署了內容授權協議。蘋果正在與 Condé Nast 和 NBC 等新聞機構探索類似的合作。谷歌同意每年支付 6000 萬美元以獲得 Reddit API 的使用權來訓練模型,Stack Overflow 也與 OpenAI 達成了類似的協議。 Meta 據考慮直接購買出版商西蒙與舒斯特。
這些合作與 AI 公司面臨的第二個問題一致:開放網路的關閉。
網路論壇和社群媒體網站已經意識到 AI 公司透過利用他們平台上的資料訓練模型所創造的價值。在與 Google(以及未來可能的其他 AI 公司)達成交易之前, Reddit 開始對其先前免費的 API 收費,關閉了其流行的第三方客戶端。類似地,Twitter 限制了對其 API 的存取並提高了價格,馬斯克使用 Twitter 資料為他自己的 AI 公司 xAI 訓練模型。
即使是較小的出版物、同人小說論壇和網路的其他小眾角落,它們生產了供大家自由消費的內容,並透過廣告(如果有的話)獲利,現在也開始關閉。網路原本被設想為一個神奇的網路空間,每個人都可以在這裡找到一個分享他們獨特興趣和怪癖的部落。這種魔力似乎正在慢慢消散。
訴訟威脅、數百萬內容交易的日益增長趨勢,以及開放網路的關閉,這三個因素的結合產生了二個影響:
- 首先,數據戰高度偏向科技巨頭。新創公司和小公司既無法存取以前可用的 API,也無法在不承擔法律風險的情況下支付購買使用權所需的現金。這具有明顯的集中效應,即能夠購買最好的數據並創建最好的模型的富人將變得更加富有。
- 其次,使用者生成內容平台的商業模式對使用者越來越不利。像 Reddit 和 Stack Overflow 這樣的平台依賴數百萬未付薪酬的人類創作者和版主的貢獻。然而,當這些平台與 AI 公司達成數百萬美金的交易時,他們既不補償用戶,也不徵求用戶的許可,沒有用戶就沒有數據可賣。
Reddit 和 Stack Overflow 都經歷了顯著的用戶罷工,抗議這些決定。聯邦貿易委員會(FTC)就其而言,已經對 Reddit 的銷售、授權和與外部組織共享使用者貼文以訓練 AI 模型的行為展開了調查。
這些問題所引起的問題與訓練下一代 AI 模型和網路內容的未來息息相關。就目前而言,那個未來看起來很沒有希望。加密解決方案能否為小型公司和網路使用者創造公平競爭的環境,解決這些問題?
流程拆解
訓練 AI 模型和創建有用的應用程式是複雜且昂貴的努力,需要數月的規劃、資源分配和執行。這些過程包括多個階段,每個階段都有不同的目的和不同的數據需求。
讓我們拆解這些階段,以了解加密如何適應更大的 AI 難題。
預訓練
預訓練,是 LLM 訓練過程中的第一步驟,也是最資源密集的步驟,它構成了模型的基礎。在這個階段,AI 模型在大量未標記的文本上進行訓練,以捕捉關於世界的一般知識和語言使用資訊。當我們說 GPT-4 在 1.2 兆個 token 上進行訓練時,這指的是用於預訓練的資料。
我們需要一個高層次的概述,了解 LLMs 的工作原理,以理解為什麼預訓練是 LLMs 的基礎。注意,這是一個簡化的概述。你可以在 Jon Stokeshttps://www.jonstokes.com/p/chatgpt-explained-a-guide-for-normies
的這篇優秀文章中找到更全面的解釋,或在這個精彩影片中,Andrej Karpathyhttps://www.youtube.com/watch?v=zjkBMFhNj_g
甚至在這本傑出書籍中找到更深入的分解。 Stephen Wolframhttps://writings.stephenwolfram.com/2023/02/what-is-chatgpt-doing-and-why-does-it-work/
LLMs 使用一種稱為下一個 token 預測的統計技術。簡單來說,給定一系列 token(即單字),模型嘗試預測下一個最有可能的 token。這個過程重複進行,形成完整的反應。因此,你可以將大型語言模型視為一個「完併機器」。
讓我們透過一個例子來理解這一點。
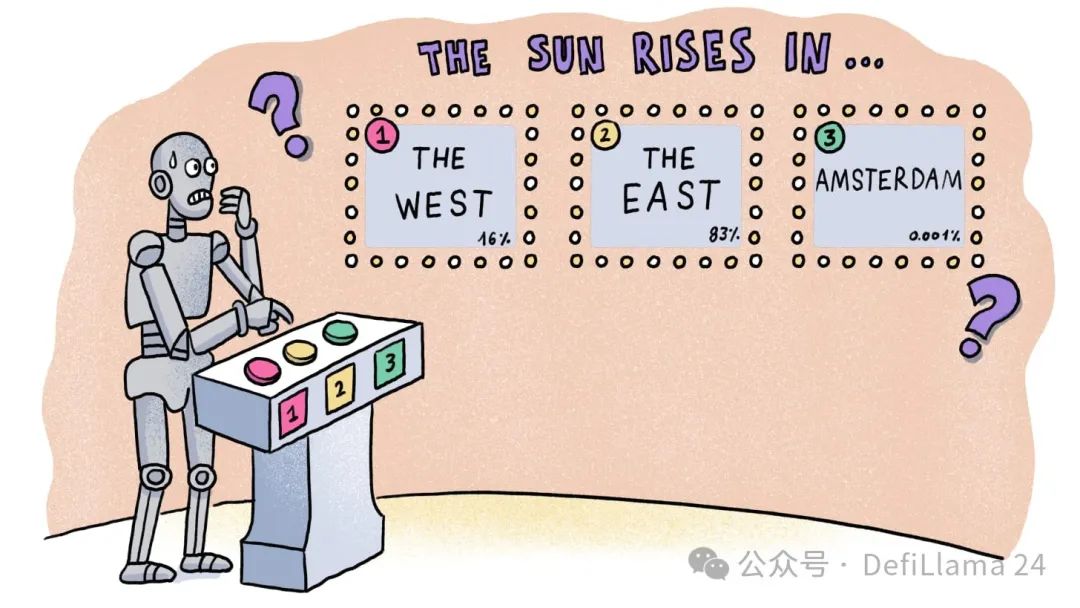
當我向 ChatGPT 提出一個問題,例如 “太陽從哪個方向升起?” 時,它首先預測單字 “the”,然後是短語 “太陽從東方升起” 中的每個後續單字。但這些預測來自哪裡? ChatGPT 如何確定在「太陽從」之後應該是「東方」而不是「西方」、「北方」或「阿姆斯特丹」?換句話說,它如何知道「東方」比其他選項在統計學上更有可能?

-理解這一點的另一種方法是比較包含這些短語的維基百科頁面的數量。「太陽從東方升起」共 55 頁,而「太陽從西方升起」則有 27 頁。 “阿姆斯特丹的太陽升起” 沒有顯示任何結果!這些是 ChatGPT 選取的模式。
答案在於從大量高品質訓練資料中學習統計模式。如果你考慮互聯網上的所有文本,什麼更有可能出現- “太陽在東方升起” 還是 “太陽在西方升起”?後者可能在特定脈絡中找到,如文學隱喻(「這就像相信太陽從西方升起一樣荒謬」)或關於其他行星(如金星,太陽確實從西方升起)的討論。但總體而言,前者常見得多。
透過反覆預測下一個單詞,LLM 形成了對世界的整體看法(我們稱之為常識)以及對語言規則和模式的理解。另一種看待 LLM 的方式是將其視為互聯網的壓縮版本。這也有助於理解為什麼數據需要大量(更多類別可供選擇)且高品質(提高模式學習準確性)。
但如同前面所討論的,AI 公司正在用盡訓練更大模型的資料。訓練資料需求的成長速度遠超過開放網路上新資料的產生速度。隨著迫在眉睫的訴訟和主要論壇的封閉,AI 公司面臨嚴重的問題。
對於無法負擔與像 Reddit 這樣的專有數據提供商達成數百萬美元交易的小公司來說,這個問題更加嚴重。
這就我們想到了 Grass,這是一個去中心化的住宅代理服務提供商,旨在解決其中一些數據問題。他們自稱為「AI 的資料層」。讓我們先了解住宅代理服務提供者的作用。
網路是訓練資料的最佳來源,爬取網路是公司取得這些資料的首選方法。在實踐中,為了規模、便利性和效率,爬取軟體通常託管在資料中心。但是,擁有有價值數據的公司不希望他們的數據被用來訓練 AI 模型(除非他們得到了報酬)。為了實施這些限制,他們經常阻止已知資料中心的 IP 位址,阻止大規模爬取。
這時住宅代理服務提供者就發揮作用了。網站只阻止已知資料中心的 IP 位址,而不是像你我這樣的普通網路使用者的 IP 位址,這使得我們的網路連接,或者說住宅網路連接,變得有價值。住宅代理服務提供者匯集了數百萬這樣的連接,以便為 AI 公司大規模爬取網站。
然而,中心化的住宅代理服務提供者秘密運作。他們通常不會明確說明他們的意圖。如果使用者知道某個產品正在使用他們的頻寬,而該產品沒有給予補償,他們可能不願意提供他們的頻寬。更糟糕的是,他們可能要求對他們的頻寬使用進行補償,這反過來又會減少他們的利潤。
為了保護他們的利潤底線,住宅代理服務提供者將消耗頻寬的程式碼附加在免費應用程式上,這些應用程式廣泛分發,如行動工具應用程式(例如計算器和錄音機)、VPN 供應商,甚至消費者電視螢幕保護程式。認為自己可以免費獲得產品的用戶通常並不知道第三方住宅提供者正在消耗他們的頻寬(這些細節通常被埋在很少有人閱讀的服務條款中)。
最終,其中一些數據會流向 AI 公司,他們使用這些數據來訓練模型,為自己創造價值。
Andrej Radonjic 在經營自己的住宅代理服務提供者時,意識到這些做法的不道德性質以及對使用者的不公平。他看到加密貨幣的發展,並確定了一個創造更公平解決方案的方法。這就是 Grass 在 2022 年底成立的原因。幾週後,ChatGPT 發布,改變了世界,使 Grass 在正確的時間出現在了正確的地點。

與其它住宅代理服務提供者採用偷偷摸摸的策略不同,Grass 向用戶明確了使用頻寬來訓練 AI 模型的情況。作為回報,他們直接獲得獎勵。這種模式徹底顛覆了住宅代理服務提供者的運作方式。透過自願提供頻寬存取並成為網路的部分所有者,使用者從不知情的被動參與者轉變為積極的傳播者,提高了網路的可靠性,並從 AI 創造的價值中獲益。
Grass 的成長率非常顯著。自 2023 年 6 月推出以來,他們已經聚集了超過 200 萬活躍用戶運行節點(透過安裝瀏覽器擴充功能或行動應用程式),並為網路貢獻頻寬。這種成長發生在沒有任何外部行銷成本的情況下,並由一個非常成功的推薦計劃推動。
使用 Grass 的服務允許各種規模的公司,從大型 AI 實驗室到開源新創公司,無需支付數百萬美元,就能獲得抓取的訓練資料。同時,日常用戶透過分享他們的網路連線獲得獎勵,成為不斷增長的 AI 經濟的一部分。
除了原始抓取的數據,Grass 還為其客戶提供了一些額外的服務。
首先,他們將非結構化的網頁轉換為結構化數據,這些數據可以更容易被 AI 模型處理。這一步驟被稱為資料清洗,通常是由 AI 實驗室執行的一項資源密集型任務。透過提供結構化、清潔的資料集,Grass 提升了對客戶的價值。此外,Grass 也正在訓練一個開源的 LLM 來自動化抓取、清洗和標記資料的過程。
其次,Grass 正在將資料集與不可否認的來源證明捆綁在一起。鑑於高品質資料對 AI 模型的重要性,確保不良行為者- 無論是網站還是住宅代理提供者- 沒有篡改資料集的權利,這對 AI 公司至關重要。
這個問題的嚴重性反映在諸如《數據與信任聯盟》之類的機構的形成上,這是一個由 Meta、IBM 和 Walmart 等二十餘家公司組成的非營利組織,它們共同合作創建來源標準,幫助組織確定一組資料是否適合且受信任地使用。
Grass 也正在採取類似的措施。每次 Grass 節點抓取網頁時,它也會記錄元數據,以驗證抓取的網頁。這些來源證明儲存在區塊鏈上,並與客戶共享(客戶可以進一步與他們的用戶分享)。
儘管 Grass 是建立在 Solana 之上的,Solana 是吞吐量最高的區塊鏈之一,但在 L1 上儲存每個抓取工作的來源是不切實際的。因此,Grass 正在建立一個 rollup(在 Solana 上的第一批之一),它使用 ZK 處理器批次處理來源證明,然後將其發佈在 Solana 上。這個 rollup,Grass 稱之為 “AI 的資料層”,成為他們所有抓取資料的資料帳本。
Grass 的 Web 3 優先方法賦予了它與中心化住宅代理商提供者相比的幾個優勢。首先,透過使用激勵措施讓用戶直接共享頻寬,他們更公平地分配了 AI 創造的價值(同時也節省了支付應用程式開發者捆綁他們程式碼的成本)。其次,他們可以為提供「合法流量」收取溢價,這在行業中非常有價值。
另一個建立在「合法流量」角度上的協定是 Masa。這個網路允許用戶傳遞他們的 Reddit、Twitter 或 TikTok 等平台的登入資訊。網路上的節點然後抓取上下文、更新的資料。這種模型的優點在於收集的資料是一個正常 Twitter 使用者在他們的 Feed 中會看到的內容。你可以即時擁有豐富的資料集來預判即將病毒式傳播的情緒或內容
他們的數據集用於什麼?就目前而言,這些上下文資料有兩個主要用例。
- 金融- 如果你有機制看到成千上萬的人在他們的 Feed 上看到的內容,你可以根據它們開發交易策略。以情感資料為基礎的智慧代理可以在 Masa 的資料集上進行訓練。
- 社交- 基於 AI 的伴侶(或像 Replika 這樣的工具)的出現意味著我們需要模仿人類對話的數據集。這些對話還需要用最新資訊進行更新。 Masa 的資料流可以用於訓練能夠有意義地談論 Twitter 上最新趨勢的代理。
Masa 的方法是從封閉花園(如 Twitter)中獲取信息,並在獲得用戶同意後,使它們可供開發人員建立應用程式。這種以社交為先的方法收集數據,也允許圍繞不同國家語言建立數據集。
例如,一個使用印地語的機器人可以使用在印地語操作的社交網路中收集資料。這些網路開啟的應用程式類型還有待探索。
模型對齊
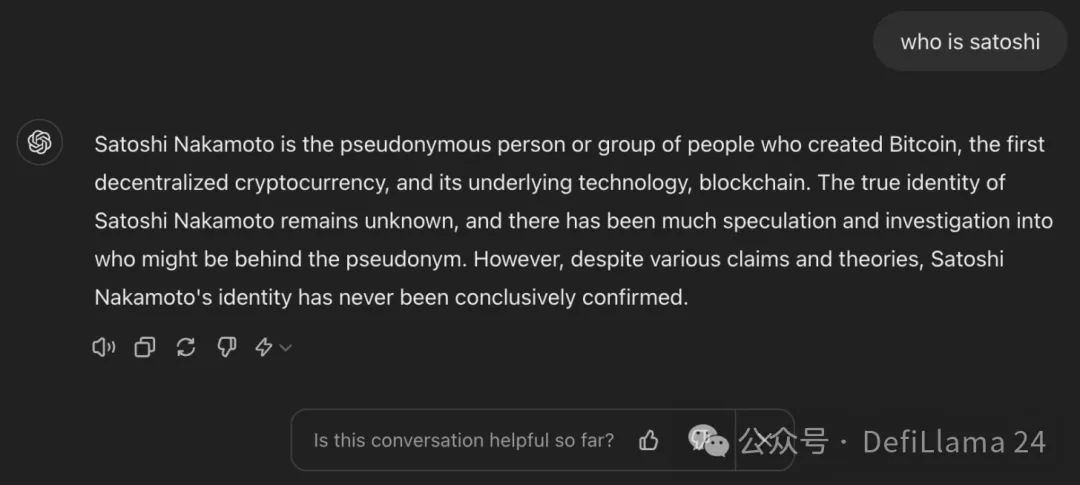
預訓練的 LLM 遠未準備好用於生產。想想看。到目前為止,模型所知道的只是如何在序列中預測下一個單詞,沒有別的。如果你給一個預訓練模型一些文本,例如 “誰是中本聰”,那麼以下任何一個回答都將是有效的回應:
- 完成問題:中本聰?
- 將短語變成一個句子:這是一個多年來一直困擾比特幣信徒的問題。
- 真正回答問題:中本聰是創建比特幣(第一個去中心化加密貨幣)及其底層區塊鏈技術的匿名人士或團體。
旨在提供有用答案的 LLM 將提供第三個回應。然而,預訓練模型的反應並不連貫或正確。事實上,它們經常隨機輸出對最終用戶毫無意義的文字。最糟的情況是,模型秘密地以事實上錯誤、有毒或有害的訊息回應。當這種情況發生時,模型被稱為 “幻覺”。

模型對齊的目標是使預訓練模型對使用者最終有用。換句話說,將其從單純的統計文字工具完成轉換為理解用戶需求並與用戶需求一致的聊天機器人,並進行連貫、有用的對話。
對話微調
這個過程的第一步是對話微調。微調是採用預先訓練的機器學習模型,並在較小的、針對性的資料集上進一步訓練它,幫助它適應特定的任務或用例。對於訓練 LLM,這個特定的用例是進行類似人類的對話。自然,此類微調的資料集是一組人類生成的提示-回應對,這些對話展示了模型應該如何表現。
這些資料集涵蓋了不同類型的對話(問題-回答、摘要、翻譯、代碼生成),通常由具有出色語言技能和專業知識的受過高等教育的人類(有時稱為 AI 導師)設計。
像 GPT-4 這樣的最先進模型估計在大約 100,000 個這樣的提示-響應對上進行了訓練。

根據人類回饋進行強化學習 (RLHF)
將這個階段想像成類似人類訓練寵物小狗:獎勵好的行為,懲罰不良行為。模型給出一個提示,它的回應與人類標籤員共享,標籤員根據輸出的準確性和品質在數字尺度上對其進行評分(例如,1-5)。另一種 RLHF 版本是獲得一個提示以產生多個回應,然後由人類標籤員從最好到最差進行排名。
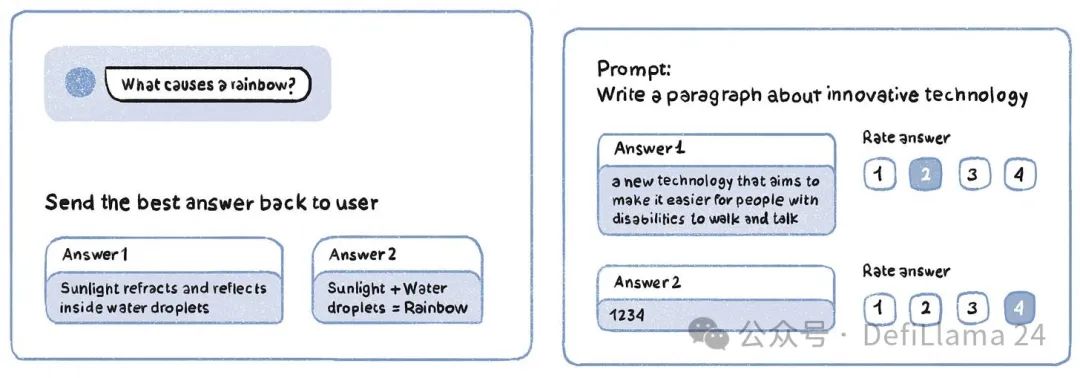 RLHF 任務範例
RLHF 任務範例
RLHF 有助於將模型推向人類偏好和期望的行為。事實上,如果你使用 ChatGPT,OpenAI 也使用你作為 RLHF 資料標籤員!當模型有時產生兩個回應,並要求你選擇更好的一個時,就會發生這種情況。
即使是簡單的讚或不喜歡圖標,提示你對答案的有用性進行評分,也是模型 RLHF 訓練的一種形式。
當我們使用 AI 模型時,我們很少考慮投入其中的數百萬小時的人力。這並不是 LLM 獨有的。從歷史上看,即使是像內容審核、自動駕駛和腫瘤檢測這樣的傳統機器學習用例,也需要大量的人力參與資料標註。(這篇來自 2019 年紐約時報的《精彩報導 https://www.nytimes.com/2019/08/16/technology/ai-humans.html
《展示了在 iAgent 印度辦公室幕後發生的情況,iAgent 是一家專注於人工標註的公司)。
Mechanical Turk,是李飛飛用來創建 ImageNet 資料庫的服務,被 Jeff Bezos 稱為 “人工的人工智慧”,因為它的工人在 AI 訓練幕後扮演資料標註的角色。
今年稍早的一個《奇異故事》https://www.bloomberg.com/opinion/articles/2024-04-03/the-humans-behind-amazon-s-just-walk-out-technology-are -all-over-ai
中,透露了亞馬遜的 Just Walk Out 商店,顧客可以從貨架上挑選商品然後走出去(稍後自動收費),並不是由一些先進的 AI 驅動。相反,是有 1000 名印度承包商在手動篩選商店錄影。
關鍵是,每個大規模 AI 系統都在某種程度上依賴人類,LLM 只是增加了對這些服務的需求。像 Scale AI 這樣的公司,客戶包括 OpenAI,已經憑藉這一需求達到了 11 位數的估值。即使是 Uber 也正在將其在印度的一些工人重新用於在不駕駛車輛時標註 AI 輸出。
在他們成為全端 AI 資料解決方案的探索中,Grass 也進入了這個市場。他們很快就會發布一個 AI 標註解決方案(作為他們主要產品的擴展),在他們的平台上的用戶將能夠透過完成 RLHF 任務賺取激勵。問題是:Grass 透過去中心化過程相對於同一領域的數百家中心化公司獲得了什麼優勢?
Grass 可以使用代幣誘因來引導工人網絡。就像他們用代幣獎勵用戶分享他們的網路頻寬一樣,他們也可以用來獎勵人類標註 AI 訓練資料。在 Web2 世界中,對於零工經濟工人的薪酬支付,尤其是對於全球分佈的工作,與在像 Solana 這樣的快速區塊鏈上提供的即時流動性相比,是一個較差的用戶體驗。
總的來說,加密社區,特別是 Grass 現有的社區,已經有高度集中的受過教育的、互聯網原生的和技術熟練的用戶。這減少了 Grass 需要花在招募和培訓工人的資源。
你可能會想知道,用激勵來交換標註 AI 模型響應的任務是否會引起農民和機器人的注意。我也有同樣的疑問。幸運的是,已經進行了廣泛的研究,使用基於共識的技術來識別高品質的標註者並篩選出機器人。
請注意,至少目前,Grass 只是進入了 RLHF(透過人類回饋進行強化學習)市場,並沒有幫助公司進行對話微調,這需要一個高度專業化的勞動力市場,且難以自動化。
專業微調
一旦完成預訓練和對齊步驟,我們就得到了所謂的基礎模型。基礎模型對世界運作有一般性的理解,並且可以在廣泛的主題上進行流暢、類似人類的對話。它還對語言有紮實的掌握,並且可以幫助用戶輕鬆地撰寫電子郵件、故事、詩歌、文章和歌曲。
當你使用 ChatGPT 時,你正在與基礎模型 GPT-4 互動。
基礎模型是通用模型。雖然它們對數百萬類別的主題已經有了足夠的了解,但它們並不專精於任何一個。當被要求幫助理解比特幣的代幣經濟學時,答案將是有用且基本上準確的。然而,當你要求它闡述如何降低 EigenLayer 這樣的再質押協議風險時,你不應信任它。
回想一下,微調是採用預先訓練的機器學習模型,並在較小的、針對性的資料集上進一步訓練,幫助它適應特定任務或用例的過程。我們之前在將原始文字完成工具轉換為對話模型的背景下討論了微調。同樣,我們也可以對產生的基礎模型進行微調,使其專業化於特定領域或特定任務。
Med-PaLM2,是 Google 基礎模型 PaLM-2 的微調版本,被訓練用來提供高品質的醫療問題答案。 MetaMath 在 Mistral-7B 上進行微調,以便更好地執行數學推理。有些微調模型專業化於特定類別,如故事敘述、文字摘要和客戶服務,而其他模型則專業化於小眾領域,如葡萄牙語詩歌、印地語-英語翻譯和斯里蘭卡法律。
對模型進行特定用例的微調需要與該用例相關的高品質資料集。這些資料集可以來自特定領域的網站(如加密資料的時事快訊)、專有資料集(醫院可能會記錄成千上萬的醫病互動)或專家的經驗(這將需要徹底的訪談來捕捉)。

隨著我們進入擁有數百萬 AI 模型的世界,這些小眾的長尾資料集正變得越來越有價值。從像安永這樣的大型會計師事務所到加薩的自由攝影師,這些數據集的所有者正在被追捧,因為它們很快就會成為 AI 軍備競賽中最炙手可熱的商品。像 Gulp Data 這樣的服務已經出現,幫助企業公平地評估他們資料的價值。
OpenAI 甚至有一份公開請求,尋求與擁有「反映人類社會且今天已經不容易在線上公開獲取的大規模資料集」的實體建立資料合作夥伴關係。
我們知道至少有一種方法可以將尋找特定產品的買家與賣家配對:網路市場! Ebay 為收藏品創造了一個市場,Upwork 為人力勞動創造了一個市場,還有無數平台為無數其他類別創建了市場。毫不意外,我們也看到了市場的出現,有些是去中心化的,用於小眾資料集。
Bagel 正在建立 “通用基礎設施”,這是一套工具,使 “高品質、多樣化資料” 的持有者能夠以一種可信賴的、保護隱私的方式與 AI 公司共享他們的資料。他們使用零知識(ZK)和完全同態加密(FHE)等技術來實現這一點。
公司經常掌握著他們無法貨幣化的但具有極高價值的數據,由於隱私或競爭問題。例如,一個研究實驗室可能擁有大量基因組數據,他們以保護患者隱私不能共享,或者一個消費品製造商可能有供應鏈降低廢品率的數據,它不能在不洩露競爭秘密的情況下公開。 Bagel 使用密碼學的進步使這些資料集有用,同時緩解附帶的擔憂。
Grass 的住宅仲介服務也可以協助建立專業資料集。例如,如果你想微調一個模型以提供專業的烹飪建議,你可以要求 Grass 從像 r/Cooking 和 r/AskCulinary 這樣的 Reddit 子版塊抓取資料。同樣,一個面向旅行的模型創建者可以要求 Grass 從 TripAdvisor 論壇抓取資料。
雖然這些並不完全是專有資料來源,但它們仍然可以成為其他資料集的有價值的補充。 Grass 還計劃使用其網路來建立可以被任何客戶重複使用的歸檔資料集。
上下文數據
試試問你喜歡的 LLM「你的訓練截止日期是什麼時候?」你會得到像 2023 年 11 月這樣的答案。這意味著基礎模型只提供那個日期之前可用的資訊。考慮到訓練這些模型(或微調它們)的計算成本和時間消耗,這是有意義的。
要保持它們即時更新,你必須每天訓練和部署一個新模型,這根本是不可行的(至少到目前為止)。
然而,一個沒有關於世界最新資訊的 AI 對於許多用例來說是相當無用的。例如,如果我使用一個依賴 LLMs 回應的個人數位助手,當被要求總結未讀郵件或提供上一場利物浦比賽的進球者時,它們將會受到限制。
為了繞過這些限制,並為使用者提供基於即時資訊的回應,應用程式開發人員可以查詢並插入資訊到所謂的基礎模型的「上下文視窗」中。上下文視窗是 LLM 可以處理的輸入文本,用於產生回應。它以 token 計量,代表 LLM 在任何給定時刻可以「看到」的文字。
所以,當我讓我的數位助手總結我的未讀郵件時,應用程式首先查詢我的郵件提供者獲取所有未讀郵件的內容,將響應插入發送到 LLM 的提示中,並在提示後附加類似的東西:「我已經提供了 Shlok 收件匣中所有未讀郵件的清單。請總結它們。」有了這個新上下文,LLM 然後可以完成任務並提供回應。將這個過程想像成你將一封郵件複製並貼上到 ChatGPT 中並要求它產生回應,但在後端發生。
要創建具有最新響應的應用程序,開發人員需要存取即時數據。 Grass 節點可以即時抓取任何網站,可以為開發人員提供這些資料。例如,基於 LLM 的新聞應用程式可以要求 Grass 每五分鐘抓取 Google 新聞上的所有熱門文章。當用戶查詢「剛剛襲擊紐約市地震的震級是多少?」時,新聞應用程式會檢索相關文章,將其添加到 LLM 的上下文視窗中,並與用戶分享回應。
這也是 Masa 今天適應的地方。就目前而言,Alphabet、Meta 和 X 是唯一擁有不斷更新用戶資料的大型平台,因為它們擁有用戶群。 Masa 為較小的新創公司提供了公平競爭的環境。
這個過程的技術術語是檢索增強生成(RAG)。 RAG 工作流程是所有現代基於 LLM 的應用程式的核心。這個過程涉及向量化文本,或將文本轉換為數字數組,然後可以被電腦輕鬆解釋、操作、儲存和搜尋。
Grass 計劃將來發布實體硬體節點,為客戶提供向量化的、低延遲的即時數據,以簡化他們的 RAG 工作流程。
產業中的大多數建設者預測,上下文層級查詢(也稱為推理)將來將使用大部分資源(能源、計算、數據)。這是有意義的。模型的訓練將始終是一個時間限制的過程,它消耗一定數量的資源分配。另一方面,應用程式層級的使用理論上可以有無限的需求。
Grass 已經看到這種情況的發生,他們的大部分文字資料請求來自於尋找即時資料的客戶。
LLMs 的上下文視窗隨著時間的推移而擴大。當 OpenAI 首次發布 ChatGPT 時,它的上下文視窗是 32,000 個 token。不到兩年後,Google 的 Gemini 模型的上下文視窗超過一百萬 token。一百萬 token 相當於超過十一本 300 頁的書——大量的文本。
這些發展使得上下文視窗可以建立的東西比僅僅訪問即時資訊要大得多。例如,有人可以將所有泰勒·斯威夫特的歌詞,或者這個新聞簡報的全部存檔,傾倒入上下文窗口,並要求 LLM 以類似的風格生成一件新的內容。
除非明確編程不這樣做,否則模型將產生相當不錯的輸出。
如果你能感受到這次討論的走向,請稍等,看看接下來會發生什麼。到目前為止,我們主要討論了文字模型,但生成模型在其他模態,如聲音、圖像和視訊生成方面也變得非常熟練。我最近在 Twitter 上看到了 Orkhan Isayen 創作的這張非常酷的倫敦插圖。

Midjourney,這個流行的(而且非常好)的文本到圖像的工具有一個叫做風格調節器的功能,可以生成與現有圖像風格相同的新圖像(這個功能也依賴於類似 RAG 的工作流程,但並不完全相同)。我上傳了 Orkhan 手工製作的插圖,並使用風格調節器提示 Midjourney 將城市改為紐約。這就是我得到的:

四個圖像,如果你瀏覽這位藝術家的插圖,很容易被誤認為是他們的作品。這些都是基於單一輸入影像,在 30 秒內由 AI 產生的。我請求的是 “紐約”,但主題可以是任何東西,真的。在其他模態,如音樂中,也可以實現類似種類的複製。
回想我們先前的討論,一些起訴 AI 公司的實體,包括創作者,你可以明白為什麼他們這麼做是有道理的。
網路曾是創作者的福音,是他們與全世界分享他們的故事、藝術、音樂和其他形式的創意表達的方式;是他們找到自己的 1000 個真實粉絲的方式。現在,同一個全球平台正成為他們生計的最大威脅。
當你可以以每月 30 美元的 Midjourney 訂閱費獲得一件風格足夠接近 Orkhan 作品的副本時,為什麼還要支付 500 美元的委託費呢?
聽起來很反烏托邦?
科技的偉大之處在於,它幾乎總是能提出解決它本身創造出的問題的新方法。如果你將對創作者看似嚴峻的情況顛倒過來,你會發現這是他們以前所未有的規模貨幣化他們才能的機會。
在 AI 之前,Orkhan 能夠創造的藝術作品數量受到他們一天中擁有的小時數的限制。有了 AI,他們現在理論上可以服務無限的客戶群。
為了理解我的意思,讓我們來看看 elf.tech,這是音樂家 Grimes 的 AI 音樂平台。 Elf Tech 允許你上傳一首歌的錄音,然後它將其轉換成 Grimes 的聲音和風格。從這首歌賺取的任何版稅都由 Grimes 和創作者 50 比 50 平分。這意味著,作為 Grimes 的粉絲,她的聲音,她的音樂會,或她的分發,你可以簡單地想出一首歌的主意,然後平台利用 AI 將其轉換成 Grimes 的聲音。
如果這首歌走紅,你和 Grimes 都會受益。這也使 Grimes 能夠擴大她的才能並被動地利用她的分發。
TRINITI,是支援 elf.tech 的技術,是由 CreateSafe 公司創建的工具。他們的 litepaper 揭示了我們預見的區塊鏈和生成 AI 技術最有趣的交叉點之一。
透過創作者控制的智慧合約擴展數位內容的定義,並透過基於區塊鏈的、點對點的、付費存取的微交易重新構想分發,允許任何串流媒體平台即時驗證並存取數位內容。生成性 AI 隨後根據創作者指定的條款執行即時的微支付,並將體驗串流傳輸給消費者。
Balaji 更簡潔地表述了這一點。
隨著新媒介的出現,我們急於弄清楚人類將如何與之互動。當它們與網路結合時,它們成為了推動變革的強大引擎。書籍為新教革命提供了燃料。廣播和電視是冷戰的重要組成部分。媒體通常是一把雙面刃。它可以被用於好的方面,也可以被用在壞的方面。
我們今天所擁有的是擁有大部分用戶資料的中心化公司。這幾乎就像我們相信自己的公司會為創造力、我們的心理健康和更好的社會發展做出正確的事。這是太多的權力,不能交給少數公司,我們對它們的內部運作幾乎不了解。
我們還在 LLM 革命的早期階段。就像 2016 年的以太坊,我們幾乎不知道可能會使用它們來建立什麼樣的應用程式。一個能和我祖母用印地語交談的 LLM?一個能夠瀏覽資訊流並只呈現高品質資料的智慧代理?一個讓獨立貢獻者分享特定文化細微差別(如俚語)的機制?我們還不清楚太多的可能性。
然而,顯而易見的是,建立這些應用程式將受到一個關鍵要素的限制:數據。
像 Grass、Masa 和 Bagel 這樣的協議是基礎設施,它以公平的方式提供資料來源。當考慮到可以建立在其上的內容時,人類的想像力是極限。對我來說,這似乎令人興奮。
免責聲明:作為區塊鏈資訊平台,本站所發布文章僅代表作者及來賓個人觀點,與 Web3Caff 立場無關。文章內的資訊僅供參考,均不構成任何投資建議及要約,並請您遵守所在國家或地區的相關法律法規。










