

盡可能通俗的解釋 BitVM 原理,闡明未來比特幣 Layer2 的技術解決方案。
作者:霧月 & Faust,極客 Web3
顧問:Kevin He, BitVM 中文社區贊助者,ex Web3 Tech Head@Huobi
封面:Photo by Shubham’s Web3 on Unsplash
導語:目前,比特幣 Layer2 已經成為一股熱潮,市面上自我定位為「比特幣 Layer2」的項目,據說已有數十家。 其中,不少自封為 “Rollup” 的比特幣 Layer2,聲稱採用了 BitVM 白皮書提出的方案,使得 BitVM 成為比特幣生態的顯學。
但無奈的是,目前大多數關於 BitVM 的文字資料,都未能通俗的解釋其原理。
本文是我們讀過了 BitVM 只有 8 頁的白皮書後,查閱了與 Taproot、MAST 樹、Bitcoin Script 相關的資料後,得出的簡單總結。 為了便於讀者理解,其中一些表達方式與 BitVM 白皮書中闡述的內容不同,我們假定讀者對 Layer2 有一些瞭解,並能夠理解 “欺詐證明” 的簡單思想。

先幾句話概括 BitVM 的思路:無需 on chain 的數據,先在鏈下發佈並存儲,鏈上只存放 Commitment(承諾)。
發生挑戰/欺詐證明時,我們只把需要上鏈的數據 on chian,證明其與鏈上的 Commitment 存在關聯。 之後,BTC 主網再校驗這些 on chian 的數據是否有問題,數據生產者(處理交易的節點)是否有作惡行為。 這一切都遵循奧卡姆剃刀原則——若非必要,勿增實體 “(能少 on chain,就少 on chain)。

正文:所謂的基於 BitVM 的 BTC 鏈上欺詐證明驗證方案,通俗總結:
1. 首先,計算機/處理器,是一個由大量邏輯門電路組合成的輸入-輸出系統。 BitVM 的核心思路之一,是用 Bitcoin Script(比特幣腳本),類比出邏輯門電路的輸入-輸出效果。
只要能類比出邏輯門電路,理論上就可以實現圖靈機,完成所有可計算任務。 也就是說,只要你人多錢多,就可以召集一幫工程師,幫你用功能簡陋的 Bitcoin Script 代碼,先類比出邏輯門電路,再用巨量的邏輯門電路實現 EVM 或是 WASM 的功能。
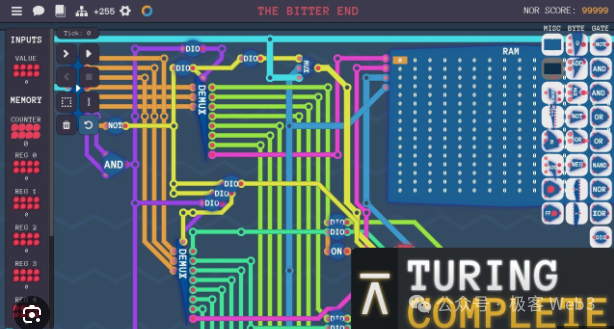
有人曾將 BitVM 的思路比作:在《我的世界》里,用紅石電路做一個 M1 處理器。 或者說,相當於用積木撘出來紐約帝國大廈。

2. 那麼,為什麼非要用 Bitcoin Script 類比 EVM 或 WASM? 這樣不是很麻煩嗎? 這是因為大多數比特幣 Layer2 往往選擇支援 Solidity 或 Move 等高級語言,而目前可以直接在比特幣鏈上運行的,是 Bitcoin Script 這種簡陋的、由一堆獨特操作碼組成的、非圖靈完備的程式設計語言。

如果比特幣 Layer2 打算像 Arbitrum 等乙太坊 Layer2 一樣,在 Layer1 上驗證欺詐證明,極大程度繼承 BTC 安全性,需要在 BTC 鏈上直接驗證「某筆有爭議的交易」或「某個有爭議的操作碼」。。 如此一來,就要把 Layer2 採用的 Solidity 語言 / EVM 對應的操作碼,放在比特幣鏈上重新跑一遍。 問題歸結為:
用 Bitcoin Script 這種比特幣 native 的簡陋程式設計語言,實現出 EVM 或其他虛擬機的效果。
所以,從編譯原理的角度去理解 BitVM 方案,它是把 EVM / WASM / Javascript 操作碼,轉譯為 Bitcoin Script 的操作碼,邏輯門電路作為 “ EVM 操作碼 ——> Bitcoin Script 操作碼” 兩者之間的一種中間形態(IR)。
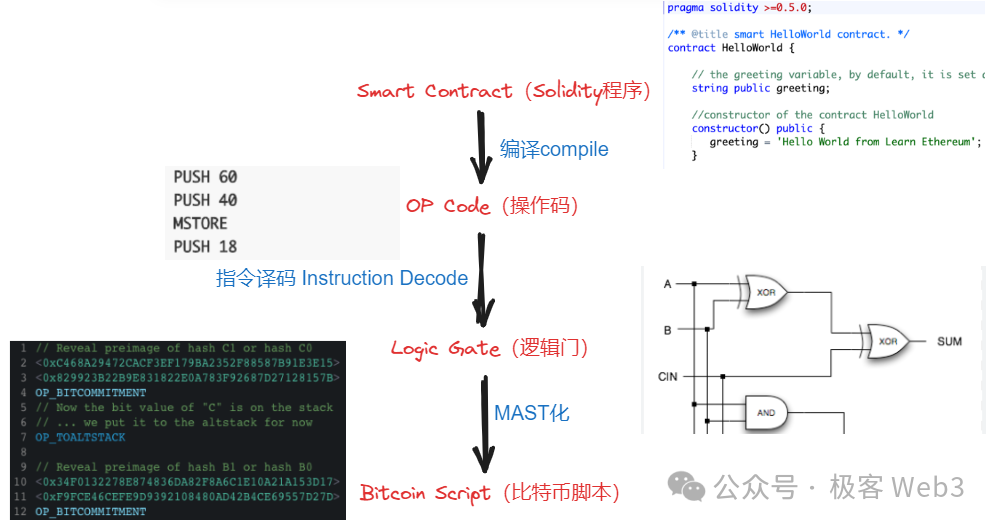
Anyway,最終類比出的效果是,把原本在 EVM / WASM 上才能處理的指令,放到比特幣鏈上直接處理 。 這個方案雖然可行,但難點在於,如何用大量的邏輯門電路作為中間形態,表達出所有的 EVM / WASM 操作碼 op code。 而且,用邏輯門電路的組合,直接表達某些極為複雜的交易處理流程,可能產生巨大的工作量。
3. 下面說下 BitVM 白皮書中提到的另一個核心,也就是與 Arbitrum 高度相似的 “互動式欺詐證明”。
互動式欺詐證明會涉及到一個稱為 assert(斷言)的詞,一般而言,Layer2 的提議者 Proposer(往往由排序器充當),會在 Layer1 上發佈 assert 斷言,聲明某些交易數據、狀態轉換結果,是有效無誤的。
如果有人認為 Proposer 提交的 assert 斷言有問題(關聯的數據有誤),就會發生爭議。 此時,Proposer 和 Challenger 會回合式的交換資訊,並對有爭議的數據進行二分法查找,快速定位到某個粒度極細的操作指令,及其關聯的數據片段。 對這個有爭議的操作指令(OP Code),需要連帶其輸入參數在 Layer1 上直接執行,並對輸出結果作出驗證(Layer1 節點會把自己計算得到的輸出結果,與 Proposer 之前發佈的輸出結果進行對比)。 在 Arbitrum 裡,這被稱為「單步欺詐證明」。

參考資料:前 Arbitrum 技術大使解讀 Arbitrum 的元件結構(上)
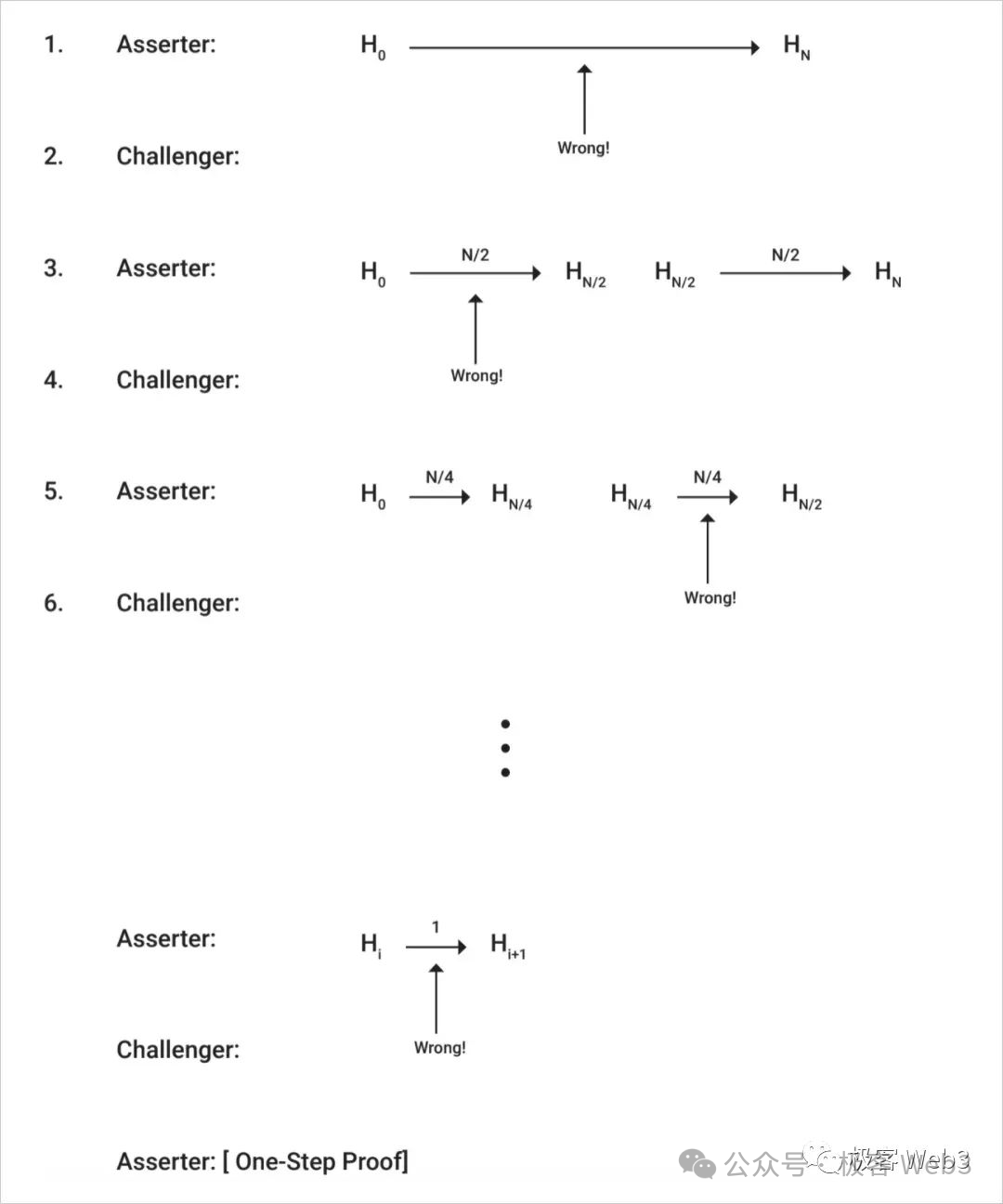
到了這裡,單步欺詐證明的思路很好理解了:絕大多數發生在 Layer2 的交易指令,不需要在 BTC 鏈上重新驗證。 但其中某個有爭議的數據片段/操作碼,在被人挑戰時要在 Layer1 重放一遍。
如果檢測結論為:Proposer 之前發佈的數據有問題,則 Slash 掉 Proposer 質押的資產; 如果是 Challenger 有問題,則 Slash 掉 Challenger 質押的資產。 如果 Prover 長時間不回應挑戰,也可以被 Slash。
Arbitrum 通過乙太坊上的合約來實現上述效果,BitVM 則要藉助 Bitcoin Script 實現時間鎖、多簽等功能。

4. 簡單講完「互動式欺詐證明」與「單步欺詐證明」後,我們將談及 MAST 樹和 Merkle Proof。
前面談到,BitVM 方案中,不會將 Layer2 在鏈下處理的大量交易數據/涉及的巨量邏輯門電路 直接 on chain,只在必要時刻將極少數據/邏輯門電路 on chian。
但是,我們需要某種方式,證明這些「原本在鏈下,現在要 on chain」的數據,不是隨手捏造的,這就是密碼學中常提到的 Commitment。 Merkle Proof 就是 Commitment 的一種。
首先,我們說下 MAST 樹。 MAST 樹全名為 Merkelized Abstract Syntax Trees,是把編譯原理里涉及的 AST 樹,轉化為 Merkle Tree 之後的形態。
那麼,AST 樹又是什麼? 它的中文名是「抽象語法樹」,簡單的講,就是把一段複雜的指令,通過詞法分析,細分為一堆基礎的操作單元,然後組織為一棵樹狀的數據結構。

而 MAST 樹,就是把 AST 樹 Merkle 化,以支援 Merkle Proof。 Merkle 樹有一個好處,就是它可以實現高效率的「數據壓縮」。。 比如,你想在必要時,將 Merkle 樹上的某段數據發佈到 BTC 鏈上,但又要讓外界確信,這個數據片段確實存在於 Merkle 樹上,而不是你「隨手拈來」的,怎麼辦?
你只要事先將 Merkle 樹的 Root 記錄在鏈上,在未來出示 Merkle Proof,證明某段數據,存在於 Root 對應的 Merkle 樹上,就行。

所以,無需將完整的 MAST 樹存放在 BTC 鏈上,只需要提前披露其 Root 充當 Commitment,在必要時出示 數據片段 + Merkle Proof /Branch 即可。 這種可以極大程度壓縮 on chain 的數據量,且能保證 on chain 數據真的存在於 MAST 樹上。 而且,僅在 BTC 鏈上公開小部分數據片段+Merkle Proof,而不是公開所有數據,能起到很好的隱私保護效果。 參考資料:數據扣留與欺詐證明:Plasma 不支援智能合約的原因

BitVM 的方案,嘗試把所有的邏輯門電路用比特幣腳本表達出來,再組織成一個巨大的 MAST 樹,這棵樹最底下的葉子 leaf(圖中的 Content),就對應著用比特幣腳本實現的邏輯門電路。
Layer2 的 Proposer,會頻繁的在 BTC 鏈上發佈 MAST 樹的 root,每棵 MAST 樹,都關聯著一筆交易,涉及其所有的 輸入參數 / 操作碼 / 邏輯門電路。 某種程度上,這類似於 Arbitrum 的 Proposer 在乙太坊鏈上發布 Rollup Block。
當爭議發生時,挑戰者在 BTC 鏈上聲明,自己要挑戰 Proposer 發佈的哪個 Root,然後要求 Proposer 揭示 Root 對應的某段數據。 之後,Proposer 出示默克爾證明,反覆在鏈上披露 MAST 樹的小部分數據片段,直到和挑戰者共同定位到有爭議的邏輯門電路。 之後就可以執行 Slash。
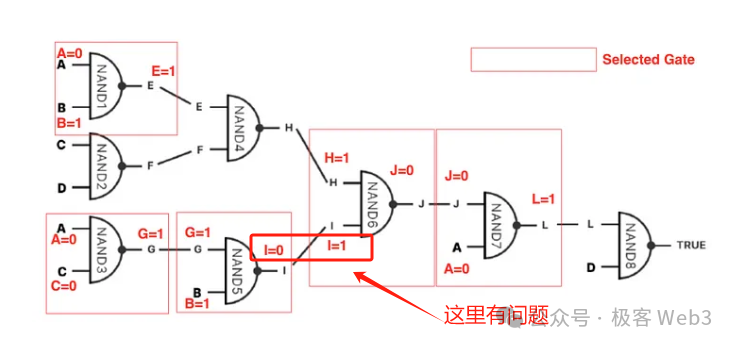
5. 到這裡,BitVM 整個方案最重要的部分基本講完,雖然其中某些細節還是有點晦澀,但相信讀者已經可以 get 到 BitVM 的精華與要旨。 至於其白皮書裡提到的 bit value commitment,是為了防止 Proposer 在被挑戰並被迫在鏈上驗證邏輯門電路時,給該邏輯門的輸入值「既賦值 0,又賦值 1」,產生二義性混亂。
總結:BitVM 的方案,先用比特幣腳本表達邏輯門電路,再用邏輯門電路表達 EVM/其他 VM 的操作碼,再用操作碼表達任意一條交易指令的處理流程,最後組織成 merkle tree/MAST 樹。
這樣的一棵樹,如果表達的交易處理流程很複雜,很容易破 1 億個 leaf,所以要盡量縮減 Commitment 佔用的區塊空間,以及欺詐證明波及的範圍。
雖然單步欺詐證明,只需要 onchain 極小的一段數據和邏輯門腳本,但完整的 Merkle Tree 要長期存儲在鏈下,以備有人挑戰時,可以隨時 onchain 樹上的數據。
Layer2 每筆發生的交易,都會產生一個大號 Merkle Tree,節點的計算和存儲壓力可想而知,大多數人可能不願意去運行節點(但這些歷史數據可以被過期淘汰,而 B^2 network 專門引入類似 Filecoin 的 zk 存儲證明,激勵存儲節點長期保存歷史數據)
不過,基於欺詐證明的樂觀 Rollup,本身也不需要有太多節點,因為其信任模型是 1/N,只要 N 個節點中有 1 個是誠實的,能夠在關鍵時刻發起欺詐證明,Layer2 網路就是安全的。
但是,基於 BitVM 的 Layer2 方案設計中,還存在許多挑戰,比如:
1)理論上說,為了進一步壓縮數據,不必直接在 Layer1 驗證操作碼,可以將操作碼的處理流程再度壓縮為 zk proof,讓挑戰者對 zk proof 的驗證步驟進行挑戰。 這樣可以大幅度壓縮 on chain 的數據量。 但具體的開發細節會很複雜。
2)Proposer 和 Challenger 要在鏈下反覆產生交互,協定該如何設計,Commitment 和挑戰過程,該如何在處理流程上進一步優化,需要消耗很多腦細胞。
參考文獻:
1.BitVM 白皮書
2.Deep dive into BitVM -Computing paradigm to express Turing-complete Bitcoin contracts-
3.Merkelized Abstract Syntax Trees
https://hashingit.com/elements/research-resources/2014-12-11-merkelized-abstract-syntax-trees.pdf
4. 數據扣留與欺詐證明:Plasma 不支援智能合約的原因
https://mp.weixin.qq.com/s/oOPZqIoi2p6sCxBdfUP4eA
5. 前 Arbitrum 技術大使解讀 Arbitrum 的元件結構(上)
https://mp.weixin.qq.com/s/BgpHI4oXQYYVpB5v6x8cAg
免責聲明:作為區塊鏈資訊平臺,本站所發佈文章僅代表作者及嘉賓個人觀點,與 Web3Caff 立場無關。 文章內的資訊僅供參考,均不構成任何投資建議及要約,並請您遵守所在國家或地區的相關法律法規。










