L3 和 L2 之間的交易實際上是可以原子組合的
作者:polynya
編譯: Evelyn,W3.Hitchhiker
原用標題(譯後):一文了解新應用:分形擴容
封面: Photo by Siora Photography on Unsplash
StarkWare 已經很好地介紹了這個話題,最近 Vitalik 也出了一篇關於 layer 3 的詳細文章。那麼,在這裡,我有什麼要補充的嗎?我一直認為我沒有,這就是為什麼我從來沒有寫過這個話題的原因—— 自從我第一次與 StarkWare 的人討論這個話題以來,已經過去了 10 個月。但是今天,我想我也許可以從不同的角度來漫談這個問題了。
首先要了解的是,"web2 "現在在全世界的 100,000,000 台服務器上運行。而"Web3 "是一個相當愚蠢的 meme,因為它被明確是"web2 "的一個小眾子集。但是,讓我們假設這種區塊鍊網絡可以創造其小而可持續的(但有利可圖的)利基市場(niche),吸引那些嚴格要求分佈式信任模型和相對最小的計算的場景(即沒有什麼比擁有定制硬件的超級計算機更能實時編碼數百萬個視頻了)。假設我們只需要"web2 "的 0.1% 的計算能力。那就是需要 100,000 台服務器來建立一個小的利基市場。
現在,讓我們考慮一個高 TPS 的單片鏈,如 BNB Chain 或 Solana。雖然按比特幣這樣的安全和去中心化優先的鏈來說,它似乎令人印象深刻,但它必然是一個中端服務器,因為你必須讓成百上千的實體保持同步。今天,一個更高端的服務器將是 128 核,而不是 12 核;有 1TB 內存,而不是 128GB,等等。隨即,1 台普通的服務器就能滿足需求,這似乎是很荒謬的。事實上,一款真正的鏈上游戲要想獲得成功,可能需要多個高端服務器,而這些服務器的計算能力則需要是 Solana 的 10 倍。
下一步是 rollups。雖然專門的執行層的設計空間很廣,而且在不斷發展,但我說的是具有 1-of-N 信任假設的 rollups。由於 1-of-N 的假設(相對於 51% 的大 M 而言),不再需要運行成千上萬的節點。因此,在其他情況下,rollup 可以升級到更高性能的服務器。ZK rollups 有一個特別的優勢,因為許多節點可以簡單地驗證有效性證明(所以你可以只需要一個擁有少量全節點的高性能服務器)。是的,你需要驗證者(prover),但這些證明只需要生成一次,而且隨著軟件和硬件的進步,證明時間也在不斷減少。
不過,在某些時候,rollup 節點會成為一個瓶頸。目前,最強大的瓶頸是狀態增長。讓我們假設狀態增長的問題得到了解決,那接下來的事情就有點模糊了,根據場景的不同,會有一些帶寬/延遲或計算的組合。根據 Dragonfly 的基準,即使是像 AMM swaps 這樣非常溫和的計算密集度低的用例,BNB Chain 在 195 TPS 和 Solana 在 273 TPS 時就達到了這個極限。如前所述,由於需要同步的節點少得多,rollup 可以把這個問題推得進一步,以緩解帶寬瓶頸,但很快你就會遇到計算瓶頸。這實際上是由 Solana 的 devnet 所證明的,它的運行配置更類似於 rollup,它的 TPS 是 425 而不是 273。
然後是並行化。像 StarkNet 和 Fuel V2 這樣的 rollups 項目都專注於並行執行;而像 Optimism 這樣的其他團隊的路線圖上也計劃有這一點。理論上,你可以在多個核心上的不同收費市場上與不同的用戶運行多個不同的 dapp,但在實踐中,這裡所獲得的收益預計是相當有限的。MEV 機器人將在任何時候訪問所有的狀態,而費用將根據鏈上的金融活動來設定。所以,在現實中,你會有一個核心的瓶頸。這是智能合約鏈的一個基本限制。這並不是說並行化沒有幫助(它會有幫助的)。例如,StarkNet 的 optimistic 並行方法,肯定是一個淨正的方法(這是因為,如果交易不能被並行化,它就會返回到主核心)。
64 核 CPU → 64 倍潛在吞吐量的想法是非常錯誤的。首先,如上所述,並行執行只在某些情況下有幫助。但更大的問題是,64 核 CPU 運行時的單線程性能大大降低。例如,64 核 EPYC 以 2.20 GHz 或 3.35 GHz(boost)的時鐘頻率運行;而基於相同架構的 16 核 Ryzen 9 的時鐘頻率為 3.4 GHz,boost 最高至 4.9 GHz。因此,對於許多交易來說,64 核的 CPU 實際上會明顯慢一些。順便提一下,最新的第七代 Ryzen 9 將在幾週後發布,在每個核心的基礎上提升到 5.7 GHz ,速度提高了 15% —— 所以,是的,隨著時間的推移,每個個體的計算能力確實都有提高。但遠沒有許多人認為的那麼快(如今若想翻一倍,需要 4-5 年的時間)。
因此,由於快速主核心的重要性,你可以擴展到最大的 16 核,如上圖所示。(順便說一下,這也是為什麼你的廉價的 Ryzen 5 在遊戲中提供的 FPS 是 64 核 EPYC 的 2 倍)。但是這些核心不太可能被利用到,所以我們最多只能看到 2-5 倍的提升。對於任何計算密集型的東西,我們最多考慮幾百個 TPS,以實現最快的執行層。
一個充滿吸引力的解決方案可能是 ASIC VM,所以基本上你有一個巨大的單核,比普通的 CPU 核快 100 倍。一位硬件工程師告訴我,把 EVM 變成一個快如閃電的 ASIC 是非常簡單的,但是會花費數億美元。也許這對於解決像 EVM 一樣多的金融活動來說是非常值得的?缺點是我們需要先解決狀態管理和有效性證明(即 zkEVM)的僵化規範—— 但也許是 2030 年代要考慮的問題。
回到此時此刻—— 如果我們將並行的概念提升到一個新的水平會怎樣?與其把所有東西都塞進一台服務器,為什麼不把事情擴展到多台服務器上呢?這就是我們得到 Layer 3 的地方。對於任何計算密集型應用來說,特定於應用的 rollup 是相當必要的。而這樣也有幾個好處:
- 為一個應用程序進行微調,虛擬機成本為零
- 沒有 MEV,或有限的 MEV,通過簡單的解決方案來減輕有害的 MEV
- 專門的收費市場,也是 2)有很大的幫助。此外,你可以有新的收費模式,以獲得最佳的用戶體驗
- 為特定目的選擇微調硬件(而智能合約鏈總是有一些不適合你的應用的瓶頸)
- 解決交易質量的三難問題—— 你可以不收取,或是收取忽略不計的費用,但仍然可以通過有針對性的 DDoS 緩解措施來規避垃圾信息。這樣做的原因是,用戶總是可以退出到結算層(2 或 1),保持抗審查。
那麼,為什麼不是特定於應用的 L1,如 Cosmos zones、Avalanche subnets 或 Polygon supernets?答案很簡單:社會經濟和安全碎片化。讓我們重新審視一下問題陳述:如果我們有 100,000 台服務器,每台都有自己的驗證者集(這顯然是永遠不會成功的)。如果你有重疊的驗證者,每個驗證者將需要運行多個超級計算機;或者如果每個驗證者都有自己的驗證者集,那將會變得非常不安全。目前來說,欺詐證明或有效性證明是唯一的方法。為什麼不採用類似於 Polkadot 的或 NEAR 的分片?這裡存在嚴格的限制,例如,每個 Polkadot 分片只能做幾十 TPS,而且它的分片只會有 100 個。當然,他們有條件轉向分形擴容方法,我也希望他們能這樣做。
值得注意的是,欺詐和有效性證明執行層的設計範圍非常廣泛(所以不是所有的東西都需要 rollup)。對於大多數由一個應用程序或公司運行的低價值交易或商業交易等用例,validium 就是一個很好的解決方案。只有那些需要以太坊完整安全性的高價值去中心化金融產品才需要使用到 rollup,真的。隨著像 adamantium 和 eigenDA 這樣的誠實少數數據層想法的成熟,從長遠來看,它們幾乎可以和 rollups 一樣安全。
我將跳過關於它如何工作的部分,因為 StarkWare 的 Gidi 以及 Vitalik 的說明比我更好。但要點是:你可以在一個 L2 上擁有 1000 個 L3、L4 或其他任何東西,而且所有的這些東西都可以用一個簡潔的遞歸有效性證明來解決;只有這個需要在 L1 解決。因此,通過一個簡潔的有效性證明進行驗證,你就可以實現幾百萬的 TPS(如上所述,具有不同的屬性)。因此,整個"layer "的術語是相當有局限性的,如果我們達到 100,000 個服務器的目標,就會出現各種瘋狂的結構。讓我們只把它們看作是 rollups、validiums、volition 或其他什麼,並討論他們各自的安全屬性。
現在則是來到了房間裡的大象:可組合性。有趣的是,經過有效性證明的執行層可以與它的結算層單向地進行原子組合。要求是每個區塊都生成一個證明(我們顯然還沒有達到這個要求,但這是可能的),證明生成是簡單可並行的。因此,你可以讓 L3 與 L2 進行原子組合。但問題是,你需要等待下一個區塊的組合回來。對於許多應用程序來說,這根本不是問題,而且這些應用程序對於能夠留在智能合約鏈上而感到愉悅。如果第 L2 提供某種形式的預先確認,這也有可能得到解決,所以 L3 和 L2 之間的交易實際上是可以原子組合的。
當你可以讓多個排序器/節點組成一個統一的狀態時,聖杯就成為戰場爭奪的中心了。我知道至少有 StarkWare、Optimism 和 Polygon Zero 的團隊正在研究相關的解決方案。雖然我對實現這一目標所需的技術工程一無所知,但這似乎是在可能範圍內的事情。事實上,Geometry 已經通過與 Slush 的合作在這方面取得了進展。
這就是真正的並行。一旦想通了這一點—— 你實際上可以在對安全性和可組合性的做出最小妥協的情況下進行大規模的分形擴容。讓我們回顧一下:你有 1000 個排序器組成一個統一的狀態,一個簡潔的有效性證明,這就是你需要驗證所有這 1000 個排序器的全部東西。所以,你繼承了以太坊的信任根,你保留了完全的可組合性,有些繼承了完全的安全性,有些繼承了部分安全性,但在每一種情況下,在可擴展性、安全性、可組合性和去中心化方面,都比運行 1000 個高度分散的單片 L1 有絕對巨大的淨收益。
我預計今年晚些時候,第一批特定於應用的 L3 將通過 L2 StarkNet 上線。當然,我們將首先看到現有的 L2 會採取些行動。但是,真正的潛力將通過我們以前沒有見過的新應用來釋放,這些應用只有在分形擴容的情況下才真正可能實現。鏈上游戲或類似的項目,如 Topology 的 Isaac 或 Briq,可能會成為第一批部署自己的 L3 的項目。
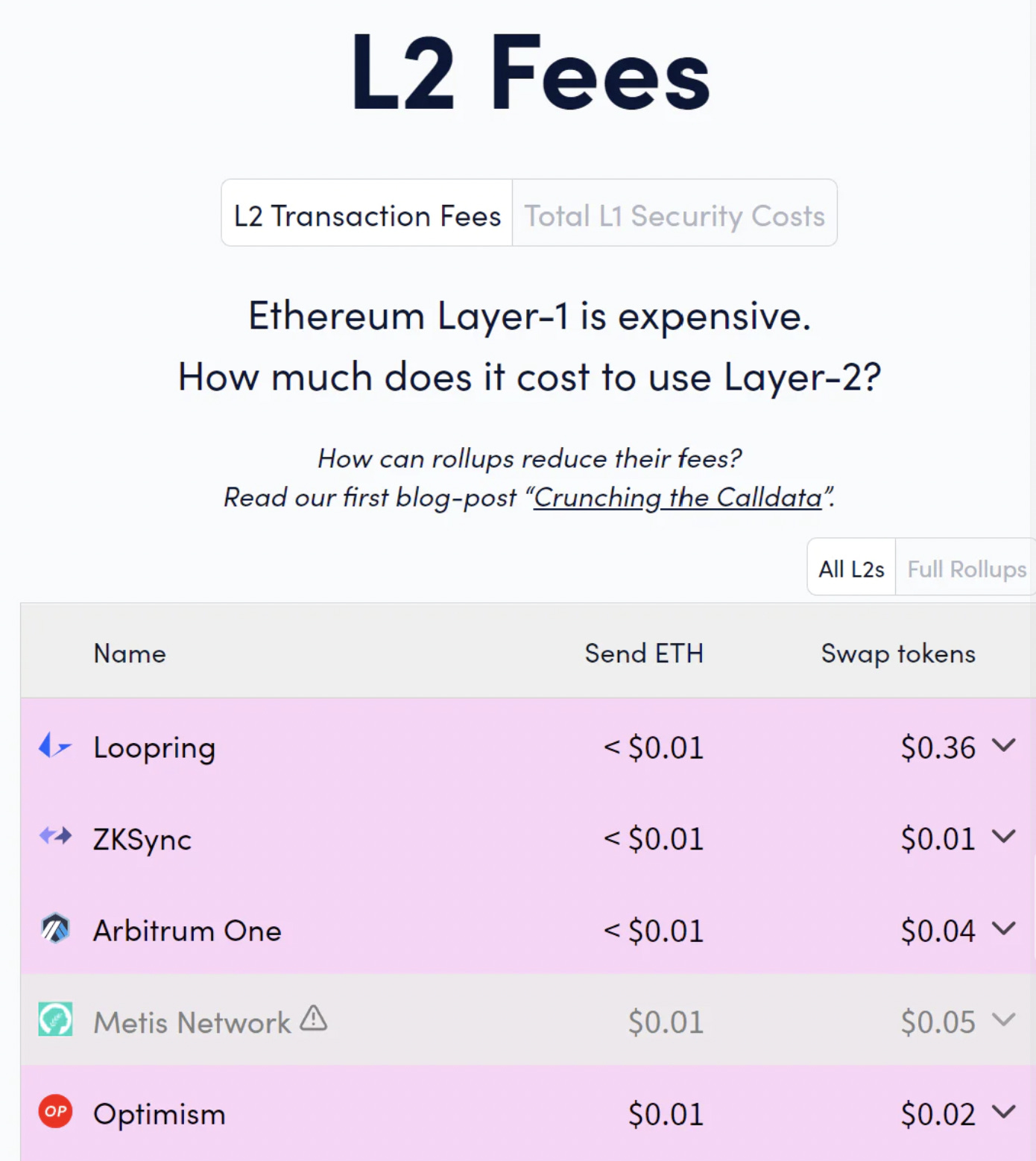
我們在這裡談論的是分形容,目前 rollup 費用是亞美分級別(實際上,Immutable X、Sorare 的費用更是低至 0.00 美元),但直到現在,它們也鮮少被利用。這也讓我重回到了開始,重新來認識區塊鏈領域的真正瓶頸—— 新型應用。這不再是先有雞還是先有蛋的問題了—— 不管是昨天還是今天,我們都有大量的空區塊空間,但是卻沒有需求。現在是我們應該專注於建立新穎的應用,獨特地利用區塊鏈的優勢,並建立一些真正的消費者和企業需求的時候了。我還沒有看到來自行業或投資者的足夠承諾—— 自 2020 年以來,應用層的創新幾乎不存在。(將現有的 web2 概念克隆過來也毫無意義)不用說,沒有這些應用,任何類型的擴容(分形或其他)都是資源浪費。
免責聲明:作為區塊鏈信息平台,本站所發布文章僅代表作者及嘉賓個人觀點,與 Web3Caff 立場無關。文章內的信息僅供參考,均不構成任何投資建議及要約,並請您遵守所在國家或地區的相關法律法規。