狀態同步被忽略,目前 L1 區塊鏈 Aptos 正朝著 100k+ TPS 邁進。
— Web3Caff 編輯部注
作者: Joshua Lind
編譯: Xiang
這篇內容篇幅較長,如果不想深入探討或時間有限,可以只看總結:
Aptos 區塊鏈利用廣泛的新技術來確保去中心化網絡中的高吞吐量、低延遲證的狀態同步。今天,在今天的 Aptos 中,對等節點可以驗證和同步超過 10k 的 TPS,延遲為低於 1 秒,而我們已經朝著 100k+ TPS 邁進。
概述
狀態同步是區塊鏈設計中一個重要但經常被忽視的方面。在這篇博文中,我們討論了 Aptos 狀態同步的演變,並展示了最新狀態同步協議設計背後的幾個關鍵見解。我們進一步探索了我們最近如何將狀態同步吞吐量提高了 10 倍,將延遲降低了 3 倍,並繼續為更快、更高效的區塊鏈同步鋪平道路。
什麼是狀態同步?
今天的大多數區塊鏈都是分層結構的,在網絡的核心有一組活躍的驗證者。驗證者通過執行交易、產生區塊和達成共識來發展區塊鏈。網絡中的其他對等節點(例如,全節點和客戶端)複製由驗證者生成的區塊鏈數據(例如,區塊和交易)。狀態同步是允許非驗證節點分發、驗證和持久化區塊鏈數據並確保生態系統中所有節點同步的協議。有關 Aptos 的外觀,請參見下圖。
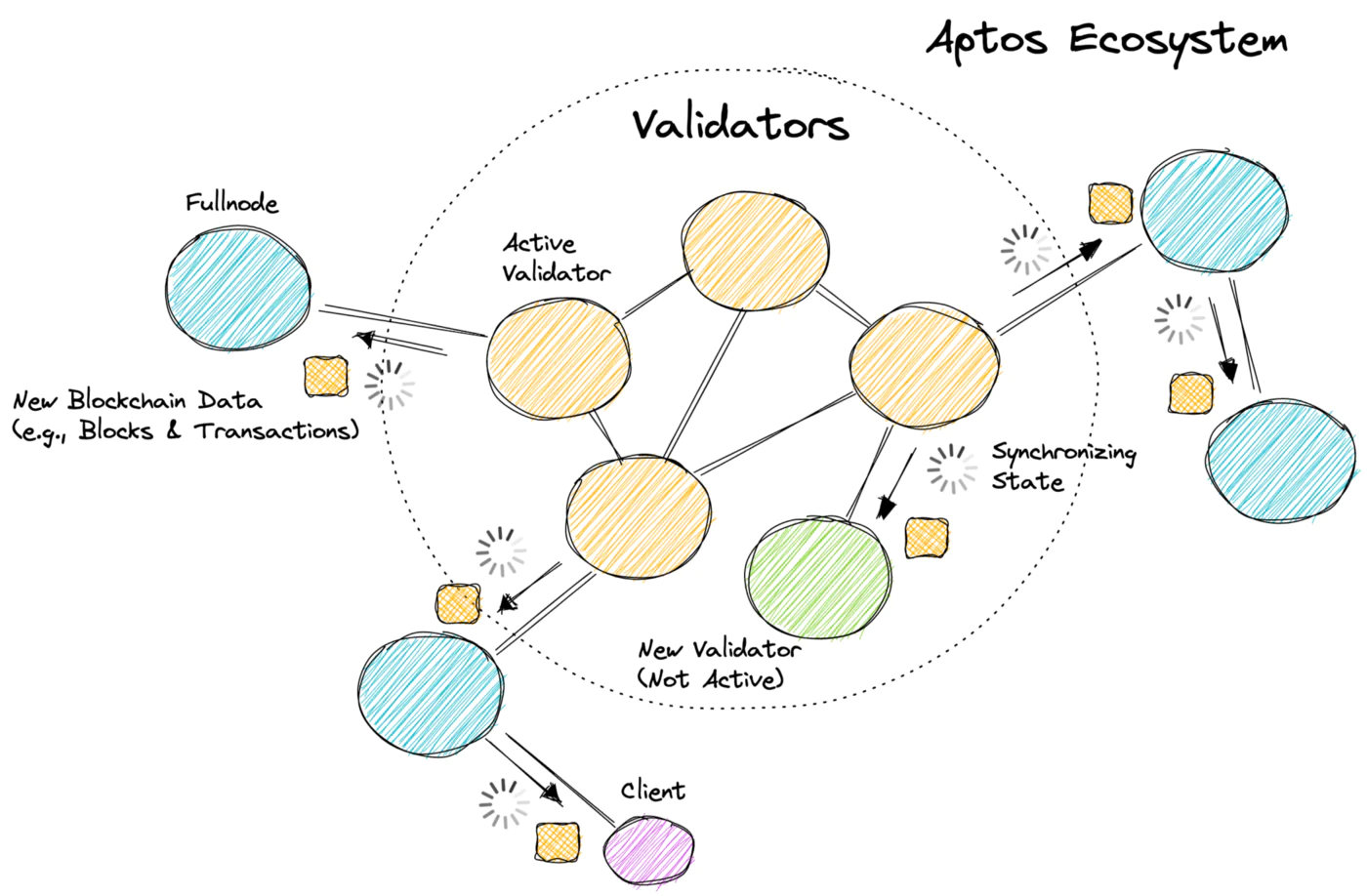
為什麼狀態同步很重要?
在評估區塊鏈時很少提及狀態同步:然而,狀態同步對區塊鏈性能、安全性和用戶體驗有重大影響。考慮以下:
- 完成時間和用戶體驗:當驗證者執行新事務時,狀態同步負責將數據傳播給對等方和客戶端。如果狀態同步緩慢或不可靠,對等方將感知到較長的事務處理延遲,人為地誇大了最終確定的時間。這對用戶體驗產生了巨大影響,例如去中心化應用程序(dApps)、去中心化交易所(DEXs)和支付處理都會慢得多。
- 與共識的關係:崩潰或落後於其他驗證者集的驗證者依靠狀態同步來使它們恢復速度(即同步最新的區塊鏈狀態)。如果狀態同步無法像共識執行的那樣快速處理事務,則崩潰的驗證者將永遠無法恢復。此外,新的驗證者將永遠無法開始參與共識(因為他們永遠趕不上!),全節點將永遠無法同步到最新狀態(他們將繼續落後!)。
- 對去中心化的影響:擁有快速、高效和可擴展的狀態同步協議允許:(i) 活躍驗證者集的更快輪換,因為驗證者可以更自由地進出共識;(ii) 網絡中有更多潛在的驗證者可供選擇;(iii) 更多全節點快速上線,無需等待很長時間;(iv) 降低資源需求,增加異質性。所有這些因素都增加了網絡的去中心化,並有助於在規模和地理上擴展區塊鏈。
- 數據正確性:狀態同步負責在同步過程中驗證所有區塊鏈數據的正確性。這可以防止網絡中的惡意對等方和對手修改、審查或偽造交易數據並將其顯示為有效。如果狀態同步未能做到這一點(或做得不正確),全節點和客戶端可能會被欺騙接受無效數據,這將對網絡造成毀滅性後果。
關於狀態同步的推理
為了更好地解釋狀態同步,我們首先介紹了區塊鏈執行的通用模型。雖然該模型專門針對 Aptos 區塊鏈,但它可以推廣到其他模型。
我們將 Aptos 區塊鏈建模為一個簡單的版本化數據庫,其中每個版本 V 都有一個獨特的區塊鏈狀態 Sⱽ,其中包含所有鏈上帳戶和資源。事務 T 可以由 Aptos 虛擬機 (VM) 在狀態 Sⱽ上執行,以生成狀態增量 Dᵀᵥ,表示 Sⱽ上應提交的所有狀態修改。當 Dᵀᵥ 應用於 Sⱽ(即我們認為 T 已提交)時,它會產生新版本 V+1 和新的區塊鏈狀態 Sⱽ⁺¹, 我們將第一個區塊鏈狀態稱為創世狀態 S⁰。下圖顯示了事務執行和狀態增量應用程序。
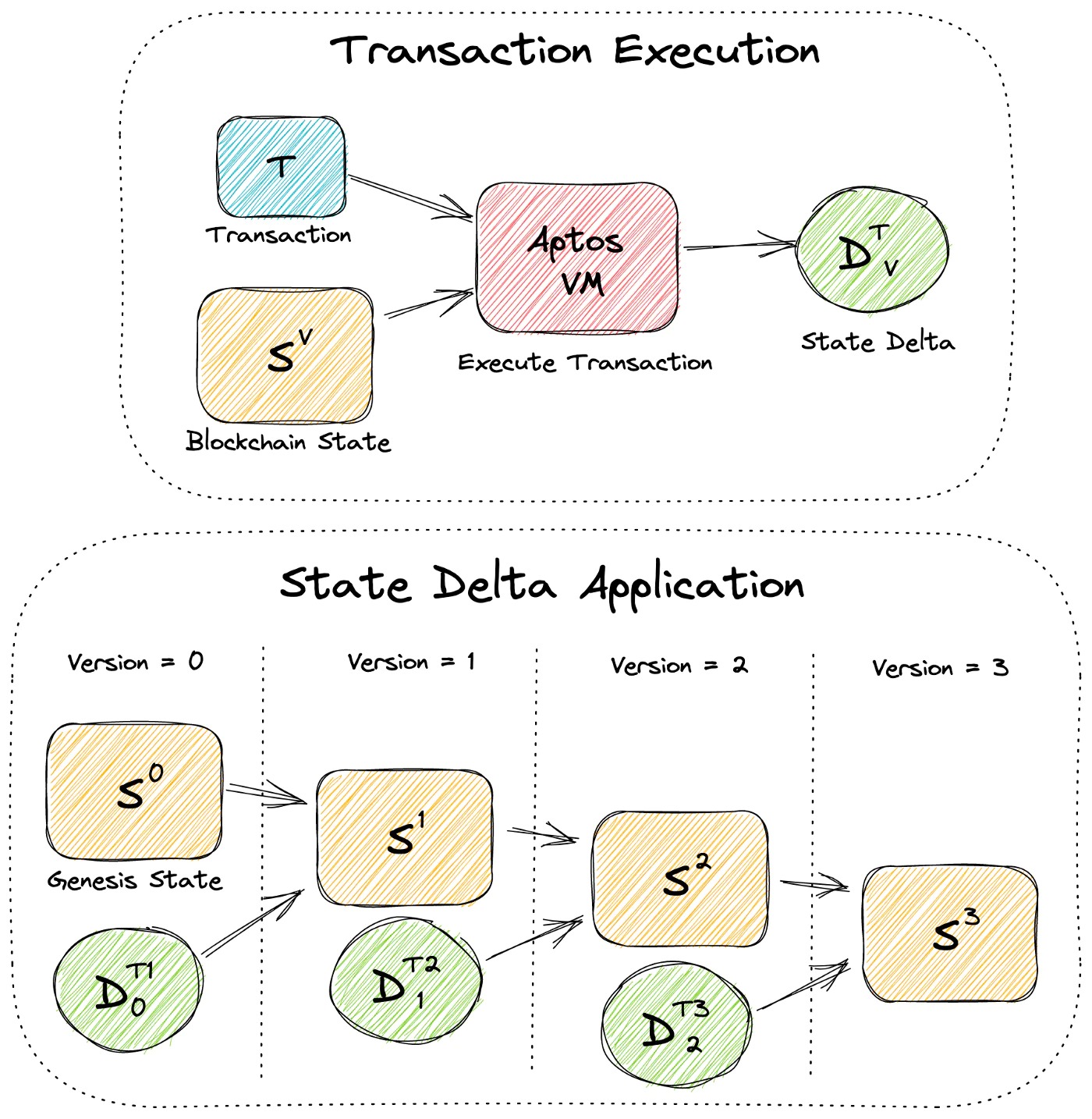
目標是什麼?
有了通用模型,我們現在可以為狀態同步定義幾個基本目標:
- 高吞吐量:狀態同步應該使每個對等方每秒可以同步的事務量最大化。也就是說,對於驗證者提交的每個 T(事務),最大化從 Sⱽ 到 Sⱽ⁺¹ 的狀態轉換率。如果吞吐量低,它會增加同步時間並成為網絡的瓶頸。
- 低延遲:狀態同步應該最大限度地減少更新節點同步驗證者提交的新事務所需的時間。也就是說,對於驗證者新提交的每個 T ,最小化 Sⱽ 的對等方同步到 Sⱽ⁺¹的時間。這會影響客戶感知到的總時間。
- 快速引導時間:狀態同步應該盡量減少新的(或崩潰的)節點同步到區塊鏈最新狀態的時間。也就是說,無論對等方的當前版本 P 和狀態 Sᴾ 如何,最小化同步到 Sⱽ(其中 V 是驗證者同意的最高數據庫版本)所需的時間。這允許對等方更快地執行有用的工作(例如,響應餘額查詢或驗證交易)。
- 抵抗故障和惡意行為者:狀態同步應該抵抗故障(例如,機器和網絡故障)並容忍網絡中的惡意行為者,包括其他對等方。這意味著要克服各種各樣的攻擊,例如偽造交易數據、修改或重放網絡消息以及日蝕攻擊。
- 容忍資源約束和異構性:狀態同步應該容忍資源約束(例如,CPU、內存和存儲)並包含異構性。鑑於去中心化網絡的性質,對等點將可以訪問不同類型的硬件並針對不同的目標進行優化。狀態同步應該考慮到這一點。
所需的構建塊
我們接下來介紹一組構建狀態同步協議所需的基本構建塊。為簡潔起見,我們在下面提供每個構建塊的摘要,並將技術細節推遲到未來的工作中(每個都可以是一篇博文,本身!):
- 持久存儲:為了在機器崩潰和故障中持久保存數據(並使數據能夠分發到其他對等點!),我們要求每個對等點都可以訪問受信任的持久存儲。在 Aptos,我們目前正在使用 RocksDB,但正在積極探索其他選項。
- 可驗證的區塊鏈數據:為防止惡意行為者修改區塊鏈數據,我們要求數據經過身份驗證和可驗證。具體來說,我們需要能夠證明: (i) 驗證者已執行並提交的每一筆交易 T ;(ii) 驗證者執行和提交的每筆交易 T 的順序; (iii) 提交每筆交易 T 後得到的區塊鏈狀態 Sⱽ。在 Aptos,我們通過以下方式實現這一目標: (i) 在已提交的交易和由此產生的區塊鏈狀態上構建默克爾樹; (ii) 讓驗證者對這些樹的 merkle 根進行簽名以驗證它們。
- 信任根:鑑於 Aptos 支持動態驗證者集(即在每個時期更改驗證者),對等方需要能夠從 Aptos 區塊鏈的已驗證歷史中識別當前驗證者集。我們通過以下方式實現這一點:(i)由 Aptos 認證的 genesis blob,它識別第一個驗證者集和初始區塊鏈狀態 S⁰;(ii) 最近的 可信航路點(例如,當前驗證者集和區塊鏈狀態 Sⱽ的散列)。起源 blob 和航路點一起形成信任根,允許對等方同步真正的 Aptos 區塊鏈並防止攻擊(例如,遠程攻擊)。
實現 1k TPS:一種簡單的方法
使用上面介紹的模型和構建塊,我們現在可以說明一個簡單的狀態同步協議。該協議是 Aptos 使用的原始協議的簡化版(即 state sync v1)。
該協議的工作原理如下:(i)Alice(同步對等方)識別最高的本地持久區塊鏈版本 V 和狀態 Sⱽ。如果不存在,則 Alice 使用 genesis,即 S⁰;(ii) Alice 然後隨機選擇一個節點,Bob,並請求驗證者已提交的任何新的順序事務;(iii) 如果 Alice 收到來自 Bob 的響應,Alice 將驗證新事務(T⁰到 Tᴺ)並執行它們以產生狀態增量(D⁰ᵥ到 Dᵀᵥ ₊ₙ);(iv) Alice 然後將新狀態增量與新交易一起應用到存儲中,將區塊鏈的本地狀態從 Sⱽ 更新為 Sⱽ⁺¹⁺ᴺ。Alice 無限期地重複該循環。該協議的偽代碼如下所示:

我們在 Aptos 實現了這個協議,在 devnet 上對其進行了基準測試,並對其進行了分析。我們所做的一些關鍵觀察是:
- 吞吐量受網絡延遲限制:此協議最大可達到
~1.2k TPS. 但是,吞吐量受到網絡延遲的嚴重影響,因為Alice請求數據是按順序請求的,並且必須等待對等方響應。鑑於我們在 devnet 中看到平均網絡往返時間 (RTT) 為150ms,這是次優的。 - CPU 執行為主:當
Alice接收到一組新的要同步的事務時,我們看到55%CPU 的時間花在執行事務和40%驗證數據、將狀態增量應用於存儲和持久化新事務上。另一個5%歸屬於消息處理、序列化和其他任務。 - 延遲很高:在最大負載下運行網絡時,
Alice接收新事務的平均延遲是~900 ms在它們被提交之後。這主要是由於Alice在請求數據時隨機選擇對等節點而不考慮網絡拓撲:離驗證者較近的對等節點將更快地收到新交易。 - 引導很慢:上面的協議需要
Alice重放和同步自創世以來的所有交易。如果Alice遠遠落後於最新狀態,她必須等待很長一段時間才能做任何有用的事情(這可能需要幾個小時甚至幾天!)。 - 性能很容易被操縱:該協議的性能受到惡意對等方的嚴重影響。如上面 1 中所述,故意緩慢(或無響應)的對等方將迫使
Alice花費很長時間等待數據而不做任何事情。因此,顯著增加了同步時間。 - 資源使用率高:該協議對所有資源類型都很昂貴:(i)CPU 使用率高,因為
Alice必須重新執行所有事務;(ii) 存儲量很大,因為Alice必須存儲自創世以來的所有交易和區塊鏈狀態;(iii) 網絡使用率很高,因為Alice必須通過網絡接收自創世以來的所有交易。這會自動帶來高成本和資源需求,從而減少異質性。 - 資源被浪費:在
Alice同步新數據的同時,網絡中的對等點也在從她那裡同步。隨著請求數據的對等方數量的Alice增加,處理這些請求所需的存儲和 CPU 上會增加額外的讀取負載。但是,為處理這些請求而執行的大部分計算Alice都是浪費的,因為對等方通常請求相同的數據。
實現 10k TPS:一種優化的方法
參考上面的簡單協議,我們可以做一些修改來幫助解決這些限制。首先,我們擴展協議以支持 2 種額外的同步模式:
- 狀態增量同步:鑑於驗證者已經執行交易並通過 merkle 證明證明生成的區塊鏈狀態,節點可以依賴驗證者產生的狀態增量來跳過交易執行。這避免了: (i) 高昂的執行成本,將 CPU 時間減少了大約
55%; (ii) 對 Aptos VM 的需求,極大地簡化了增量同步實現。因此,對等點現在可以通過下載每個事務 T 和狀態增量 Dᵀᵥ並將它們應用到存儲以生成新狀態 Sⱽ⁺¹來進行同步。我們注意到,這是以增加網絡使用量為代價的(大約2.5x)。 - 區塊鏈快照同步:鑑於驗證者證明了每個區塊鏈狀態 Sⱽ,我們可以通過允許對等方直接下載最新的區塊鏈狀態(而不必使用交易或狀態增量生成它)來進一步減少引導時間。這顯著減少了引導時間,並且與以太坊中的 snap-sync 方法類似。權衡是節點不會存儲任何交易或 Sⱽ之前的區塊鏈狀態。
接下來,我們實施了一些常規優化和附加功能,以幫助提高性能和可擴展性:
- 數據預取:為了防止網絡延遲影響吞吐量,我們可以執行數據預取。對等點可以在處理其他對等點之前從其他對等點預取交易數據(例如,交易和狀態增量),從而分攤網絡延遲。
- 流水線執行和存儲:為了進一步提高同步吞吐量,我們可以將事務執行與存儲持久性分開並使用流水線:處理器設計中常用的優化。這允許在事務 T¹ 和狀態增量 Dᵀ¹ᵥ同時持久化到存儲時執行事務 T² 。
- 對等點監控和聲譽:為了提高可觀察性並更好地容忍惡意對等點,我們可以實施對等點監控服務: (i) 監控對等點的惡意行為(例如,傳輸無效數據);(ii) 識別關於每個對等點的元數據,例如對等點擁有的所有交易數據的摘要以及它們與驗證者集的感知距離;(iii) 為每個對等方維護一個本地分數。然後,此信息可用於在請求新的區塊鏈數據時優化對等點選擇。
- 數據緩存:為了減少存儲的讀取負載並防止狀態同步在越來越多的對等點同步時執行冗餘計算,我們可以實現一個數據緩存,將通常請求的數據項和響應存儲在內存中。
- 存儲修剪:為了防止存儲隨著時間的推移而持續增長(例如,隨著更多事務的提交),我們還可以實施動態修剪器以從存儲中刪除不必要的事務和區塊鏈數據,例如超過幾天、幾週或幾個月的任何數據,取決於對等配置。
我們實現了這些修改並產生了一個新的狀態同步協議(即 state sync v2)。我們在 devnet 上對其進行了基準測試並觀察到:
- 吞吐量增加了 5 到 10 倍:在執行事務時 (沒有並行執行),協議現在達到了最大值
~4.5kTPS,這主要是由於流水線和數據預取(即,協議現在能夠使 CPU 完全飽和)。當同步狀態增量時,協議可以很好地10K TPS完成,避免事務執行的進一步結果。在這兩種情況下,吞吐量都不再受網絡延遲的影響。 - 延遲降低了 3 倍:在以最大負載運行網絡時,我們現在看到
Alice接收新事務的平均延遲是~300 ms在它們被提交之後。這是由於數據預取和更有效的對等點選擇:響應速度更快且離驗證者更近的對等點會被更頻繁地聯繫。 - 引導速度明顯更快:使用區塊鏈快照同步的節點能夠更快地引導。此外,引導時間不再受區塊鍊長度(即交易數量)的影響,而是要同步的鏈上資源數量。目前在 devnet 中,對等點可以在幾分鐘內啟動。
- 減少資源需求:通過多種同步模式和存儲修剪,減少了資源需求。此外,現在支持異質性,因為對等方可以靈活地選擇同步策略。例如: (i) CPU 受限的節點可以跳過事務執行;(ii) 存儲有限的對等點可以將修剪器配置為激進;(iii) 希望快速更新的節點可以執行區塊鏈快照同步。
- 資源使用效率更高:在處理來自對等點的同步請求時,我們發現存儲上的讀取負載顯著降低,CPU 浪費更少。這是由於新的數據緩存將通常請求的數據項和響應存儲在內存中。我們還看到,隨著 devnet 中同步對等點數量的增加,數據緩存變得更加高效,例如,對於
20個同步對等點,我們看到每個請求的緩存命中率為70%-80%。但是,對於 60 個對等點,我們看到緩存命中率為93%-98%. 這是以額外的 RAM 為代價~150 MB來維護緩存的。
100k TPS 及以上?
雖然我們已經將吞吐量提高了 10 倍,延遲提高了 3 倍,但我們意識到還有更多工作要做。特別是如果我們想匹配 Block-STM 並使 Aptos 成為每個人的 Layer 1!
那麼,我們將如何到達那裡?好吧,我們已經開始了我們的下一個狀態同步目標:100k+ TPS!雖然,我們計劃為未來的博文保存詳細信息,但我們確實想為熱心的讀者提供一些提示:
- 交易 批處理:目前,Aptos 將每筆交易視為可驗證的,即用於驗證和驗證數據的默克爾證明在交易粒度上運行。這使得驗證和存儲變得異常昂貴。避免這種情況的一種方法是執行交易批處理,即對交易的批次(或塊!)進行證明。
- 網絡壓縮:網絡帶寬經常成為點對點網絡的瓶頸,Aptos 也不例外。目前,狀態同步預取器可以在帶寬飽和之前
~45K TPS在 devnet 中取回。如果我們想擴大規模,這是一個問題。值得慶幸的是,我們已經認知到,對等點正在使用低效的序列化格式分發數據,並且通過使用現成的壓縮技術,我們可以將傳輸的數據量減少超過10x. - 更快的存儲寫入:目前,將區塊鏈數據保存到存儲所需的時間成為狀態同步吞吐量的瓶頸。我們正在積極尋找不同的優化和改進來消除這個瓶頸,包括:(i) 更高效的數據結構;(ii) 更優化的存儲配置;(iii) 備用存儲引擎。
- 並行數據處理:到目前為止,我們要求狀態同步處理數據順序(例如,處理順序增加版本的事務)。然而,有許多現有的方法可以讓我們避免這種要求並利用並行數據處理來顯著提高吞吐量,例如區塊鏈分片!
免責聲明:作為區塊鏈信息平台,本站所發布文章僅代表作者及嘉賓個人觀點,與 Web3Caff 立場無關。本文內容僅用於信息分享,均不構成任何投資建議及要約,並請您遵守所在國家或地區的相關法律法規。