

Solana 以系統可用性為代價,將 Layer1 擴容的敘事推向了極端,基本觸及無分片公鏈的 TPS 瓶頸。但多次宕機似乎預示了犧牲可用性換取效率的結局。
作者: eternal1997,CatcherVC
技術顧問:劉洋,《嵌入式系統安全》作者
封面: Solana
摘要
- Solana 擴容主要基於:高效利用網絡帶寬、減少節點間通訊次數、加快節點運算速度 三大方面,這些措施直接縮短了出塊和共識通訊的時間,但也降低了系統可用性(安全)。
- Solana 提前公開出塊者 Leader 名單,揭示了單一可信的數據來源,縮減了共識通訊開銷。但又會帶來賄賂、針對性攻擊等安全隱患。
- Solana 將共識通訊(投票信息)作為交易事件來處理,TPS 成分中超過 70% 都是共識訊息,與用戶交易相關的 TPS 約為 500—1000;
- Solana 的 Gulf Stream 機制取締了全局性交易池,這提高了交易處理速度,但降低了過濾垃圾交易的效率,Leader 容易宕機。
- Solana 的 Leader 節點發布的是交易序列,而非真實的區塊。結合 Turbine 傳輸協議,交易序列可以切碎後分發給不同節點,數據同步速度極快。
- POH(Proof Of History)實質為一種計時和計數方式,它給不同的交易事件蓋上序號,生成交易序列。Leader 實質上在交易序列中發布了全網一致的計時器(時鐘)。在很短的窗口期內,不同節點的賬本推進、時間推移都是一致的;
- Solana 有 132 個節點佔據 67% 的質押份額,其中的 25 個節點佔據 33% 的質押份額,基本構成了 “寡頭政治” 或 “元老院”。如果這 25 個節點串謀,足以導致網絡陷入混亂;
- Solana 對節點硬件水準要求很高,它以設備成本為代價,實現了縱向擴容。運行 Solana 節點的個體多為鯨魚或機構、企業,不利於真正意義的去中心化。
- 綜上,Solana 以高級節點設備、顛覆性的共識機制與數據傳輸協議,將 Layer1 擴容推向了極端,基本觸及無分片公鏈可維持的 TPS 瓶頸。但多次宕機已經預示了犧牲可用性/安全性來換取效率的結局。
導語
2021 年是區塊鍊和 Crypto 的轉折之年。隨著 Web3 等概念成為顯學,公鏈界迎來了有史以來最強勁的流量增長。在這樣的外部環境下,以太坊憑藉充分的去中心化和安全性,成為 Web3 世界的泰山北斗,但效率問題卻成了它的 “阿喀琉斯之踵”。相比於 TPS 輕鬆破千的 VISA,每秒 10 幾筆交易的以太坊宛若懷中襁褓,與其 “世界級去中心化應用平台” 的宏大願景相差甚遠。
對此,Solana、Avalanche、Fantom、Near 等以擴容為核心的新公鏈一度成為 Web3 敘事的主要角色,獲得了巨量資本的垂青。僅以 Solana 為例,這個號稱 “以太坊殺手” 的頭部公鏈在 2021 年市值飆漲 170 倍,如日中天,甚至一度超越老牌公鏈 Polkadot 和 Cardano,大有和以太坊爭雄的勢頭。
但在 2021 年 9 月 14 日,Solana 因為性能上的問題,首次迎來宕機事故,時間長達 17 小時,SOL 代幣價格隨之快速下跌 15%;2022 年 1 月,Solana 再次出現宕機,時長足有 30 小時,引發了極為廣泛的討論;之後的 5 月,Solana 先後宕機 2 次,6 月初又宕機 1 次。根據 Solana 官方的說法,其主網至少經歷了 8 次性能下降或是宕機事故。
(鏈聞聯創劉鋒對 Solana 的評論)
伴隨著諸多問題的出現,以太坊支持者為首的批評者輪番對 Solana 提出質疑,有人甚至給 Solana 冠以 “SQLana” 的稱號(SQL 是管理中心化數據庫的系統),並先後產生了大量的評論與分析。時至今日,關於 Solana 真實可用性的討論似乎從未停止,吸引著無數好奇心濃重的觀察者。出於對主流公鏈的興趣與關注,CatcherVC 將從自身視角出發,在本文對 Solana 擴容機制及其宕機的部分原因展開簡單解讀。
Solana 系統架構、共識機制、區塊傳輸流程
公鏈的效率主要指其處理交易的能力,也就是吞吐量 TPS(每秒處理的交易筆數),這個指標受到出塊速度和區塊容量的影響,同時也影響著交易手續費和用戶活躍度。從 2018 年甚囂塵上的 EOS,到近期發幣的 Optimism,所有擴容方案幾乎都繞不開 “加速出塊” 這個最關鍵的要素。
要提升出塊速度,往往要在出塊流程上 “做手腳”,Solana 也不出其右。其擴容方式主要立足於 高效利用網絡帶寬、減少節點間通訊的次數、提高節點處理事務的速度 三大方面,這些措施直接縮短了出塊和共識通訊的時間。Solana 的創始人 Anatoly Yakovenko 及其隊友對每一個細節都進行了精心雕琢,以系統的可用性(安全)為代價,盡可能在效率上作出提升,基本達到了無分片公鏈的實際 TPS 極限,最終作出了 “有代價” 的創新。
相比於其他採用 POS 的公鏈,Solana 最大的創新點在於其獨特的共識協議和網絡節點通信方式,該共識協議基於 POS 和 PBFT(實用拜占庭容錯),引入獨創的 POH(Proof of History)作為推進區塊鏈賬本的機制,獨樹一幟的創建了自己的共識體系。
單從表現形式的角度看,Solana 的共識協議與 Cardano 最早的 Ouroboros(銜尾蛇)算法類似,都包含 Epoch(紀元)和 Slot(間隔)兩大時間單位。每個 Slot 約為 0.4~0.8 秒,相當於一個區塊的時間間隔。而每個 Epoch 週期包含 43.2 萬個 Slot(區塊),長達 2~4 天。
在 Solana 的系統架構中,最重要的角色分為兩類:Leader(出塊者)和 Validator(驗證者)。兩者實際上都是質押了 SOL 代幣的全節點,只是在不同的 Slot(出塊週期)內,Leader 會由不同的全節點來充當,而沒有當選 Leader 的全節點會成為 Validator。
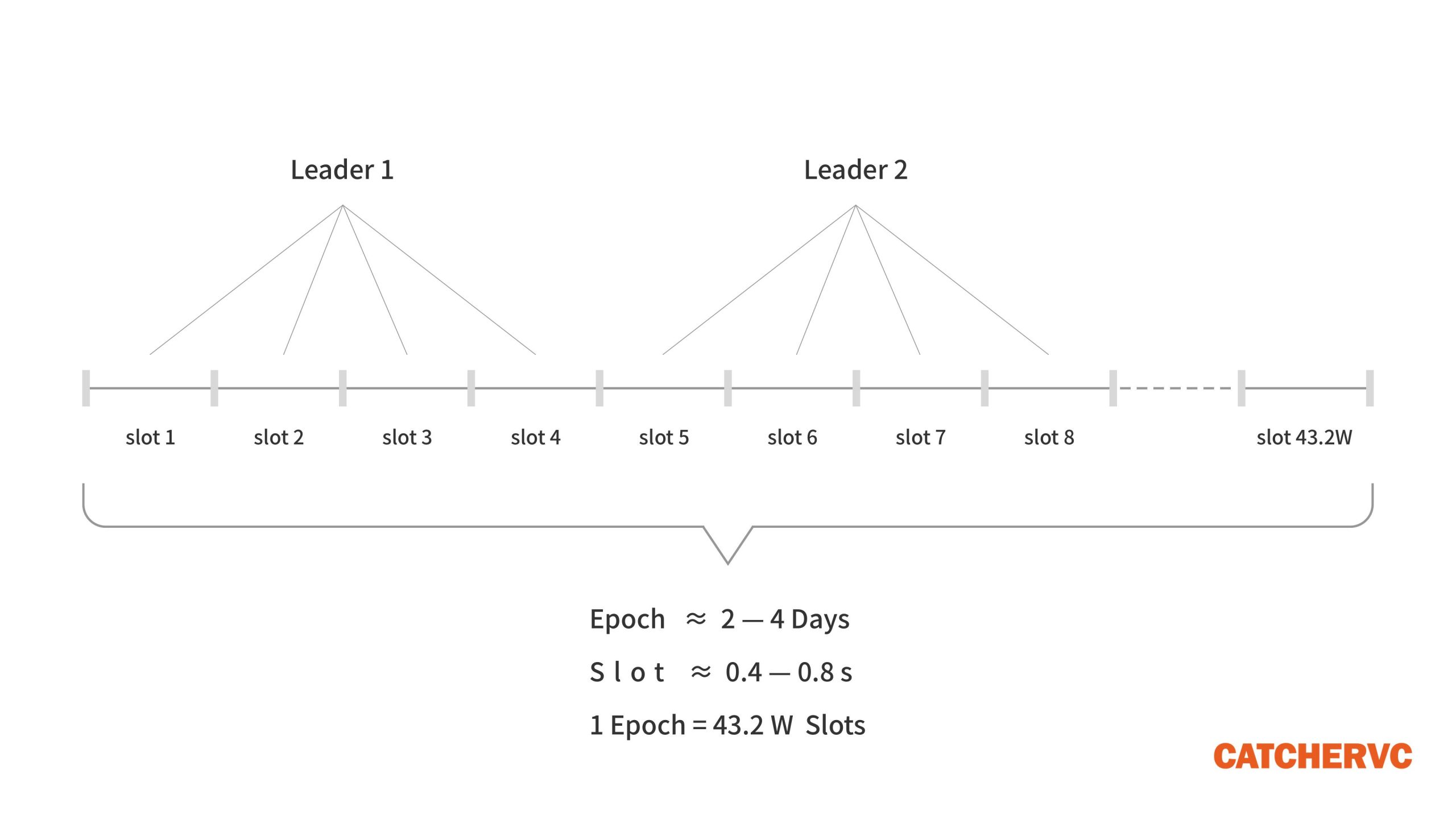
在每個新的 Epoch 週期開始時,Solana 網絡會按照各節點的質押權重進行抽選,組成一個出塊者 Leader 輪換名單,“欽定” 了未來不同時刻的出塊者。在整個 Epoch (2~4 天)內,出塊者會按照名單指定的次序進行輪換,每過 4 個 Slot(出塊週期),Leader 節點就會進行一次變更。
由於提前公開了未來的出塊節點,Solana 網絡實質獲得了確定而可信的新區塊數據源,為共識過程提供了巨大便利。
Solana 出塊流程簡述
為了更清晰的理解 Solana 的擴容機制,我們不妨從出塊邏輯開始,對 Solana 的大致結構進行解析:
1. 用戶發起交易後,會被客戶端直接轉發給 Leader 節點,或者先被普通節點接收,再立刻轉發給 Leader;
2. 出塊者 Leader 接收網絡內全部的待處理交易,一邊執行,一邊給交易指令排序,製成交易序列(類似區塊)。每隔一段時間,Leader 會把排好的交易序列發送給 Validator 驗證節點;
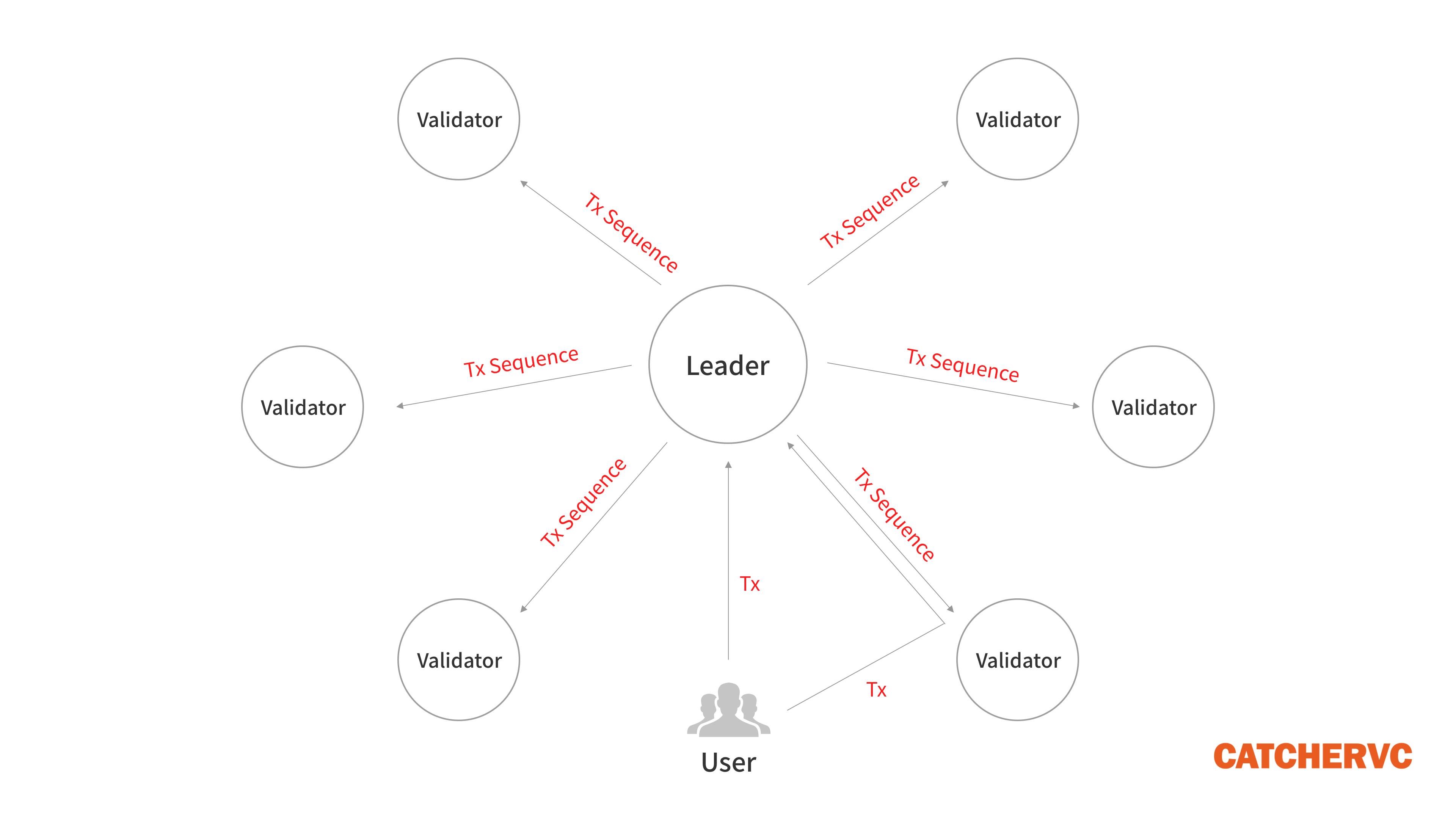
3.Validator 按照交易序列(區塊)給定的順序執行交易,產生相應的狀態信息 State(執行交易會改變節點的狀態,比如改變某些賬戶的餘額);
4. 每發送 N 個交易序列,Leader 會定期公開本地的狀態 State, Validator 會將其與自己的 State 作對比,給出肯定/否定的投票。這一步就類似於以太坊 2.0 或其他 POS 公鏈裡的 “檢查點”。
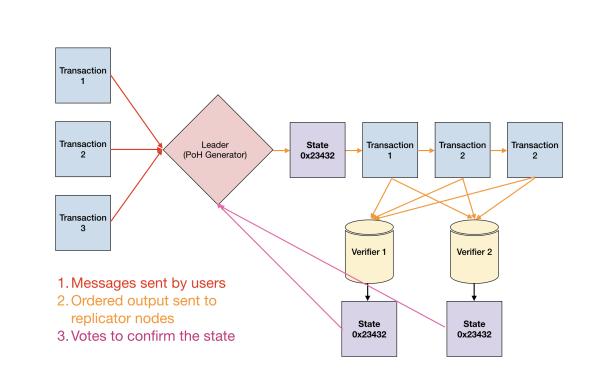
5. 如果在規定時間內,Leader 收集到佔全網 2/3 質押權重 的節點們給出的肯定票,則此前發布的交易序列和狀態 State 就被敲定,“檢查點” 通過,相當於區塊完成最終確認 Finality;
6. 一般而言,給出肯定票的 Validator 節點與出塊者 Leader 所執行的交易、執行後的狀態都是相同的,數據會同步。
7. 每過 4 個 Slot 週期,Leader 會進行一次切換,這意味著 Leader 每次大概有 1.6 秒~3.2 秒時間掌握網絡的 “最高話語權”。
Solana 擴容機制細解
表面看來,Solana 的出塊邏輯與其他採用 POS 機制的公鏈大體一致,都有一個發佈區塊、對區塊投票的過程。但如果我們對每一個步驟都展開觀察,不難發現 Solana 與其他公鏈之間有著天壤之別,而這正是其高 TPS、低可用性的根源所在:
1. 最重要的一點:Solana 提前公開每個週期 Slot 的出塊者 Leader,大幅減少了共識過程的工作量。在其他 POS 公鏈中,由於缺乏單一的、可信的出塊節點,網絡的共識通訊效率極低,產生的時間複雜度往往比 Solana 高出幾個數量級,這成為了多數公鏈在 TPS 上的瓶頸。
以主流的 POS 共識協議或 PBFT 算法為例,這些算法大多采用了和 Solana 相同的時間單位與角色劃分,也有類似於 Epoch 紀元、Slot 區塊週期、Leader 出塊者、Validator 驗證者、Vote 投票 的設定,只是參數設置和叫法不同而已。最大的不同在於,此類算法大多以安全性(可用性)為前提,不會提前公開 Leader 名單。
(比如 Cardano 也會事先生成一個 Leader 輪換列表,但列表不公開。每個選中的 Leader 只知道自己該在何時出塊,不知道其他時刻的出塊者是誰。這使得出塊節點不可被外界預測。)
由於沒有公開的出塊者,節點間會 “互不信任”並 “各自為政”。此時,若某個節點自稱為合法出塊者,大家並不敢信任他,必須要其出示相關的 Proof 證明才行。但此類 Proof 證明的生成、傳播、驗證會浪費帶寬資源,並產生額外的工作量(甚至會和 ZK 零知識證明扯上關係)。Solana 公開每個時段的 Leader,可以避免此類麻煩。
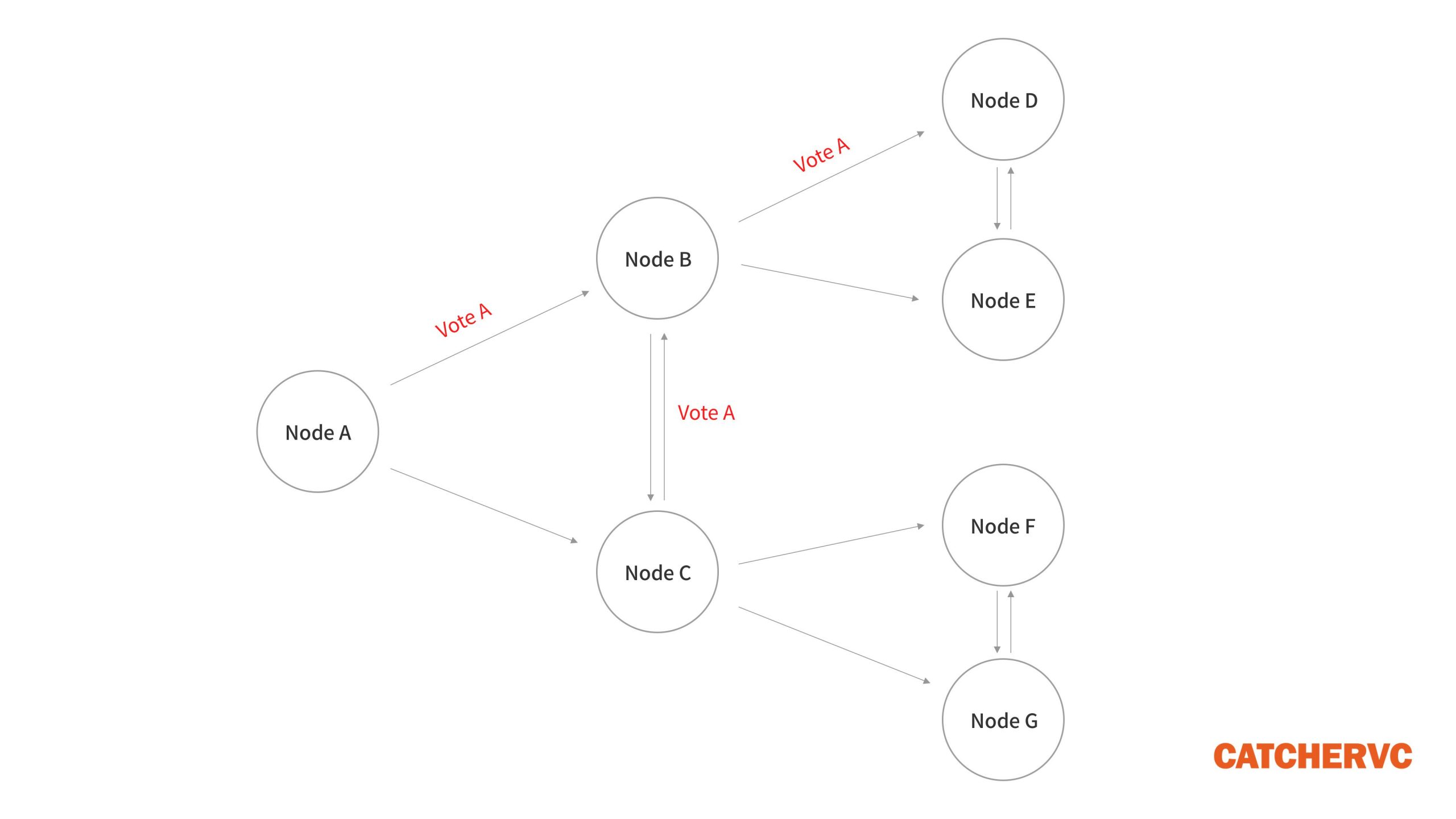
更為重要的是,在絕大多數 POS 共識協議或 PBFT 類算法中,針對新區塊的投票 Vote (一個區塊要得到網絡內 2/3 節點的肯定票才能敲定),往往由各個節點通過 “流言協議”,以類似 1 對 1 交流的方式發送或收集,有點類似於病毒式隨機擴散,實質等價於每兩個節點間都要通訊一次,其複雜度和耗時遠高於 Solana 的共識協議。
在 Tendermint 等 PBFT 算法中,單個 Validator 節點至少要收集網絡內 2/3 的節點發出的單張投票。如果全網節點數量為 N,則每個節點至少接收 2/3×N 個投票,整個網絡產生的通訊次數至少為 2/3×N²,顯然這個數量級太大了(和 N 的平方成正比)。如果節點數量很多,其共識過程的耗時往往會陡增。
(相關科普:《雪崩 DEX 開發者為你詳解 Avalanche 共識機制》)
對此,Solana 和 Avalanche 以不同的方式改良了節點收集投票的通訊過程,降低了時間複雜度。通俗的講,Leader 集中匯總所有 Validator 發出的投票,再把這些投票打包在一起(寫進交易序列裡),一次性推送到網絡中。
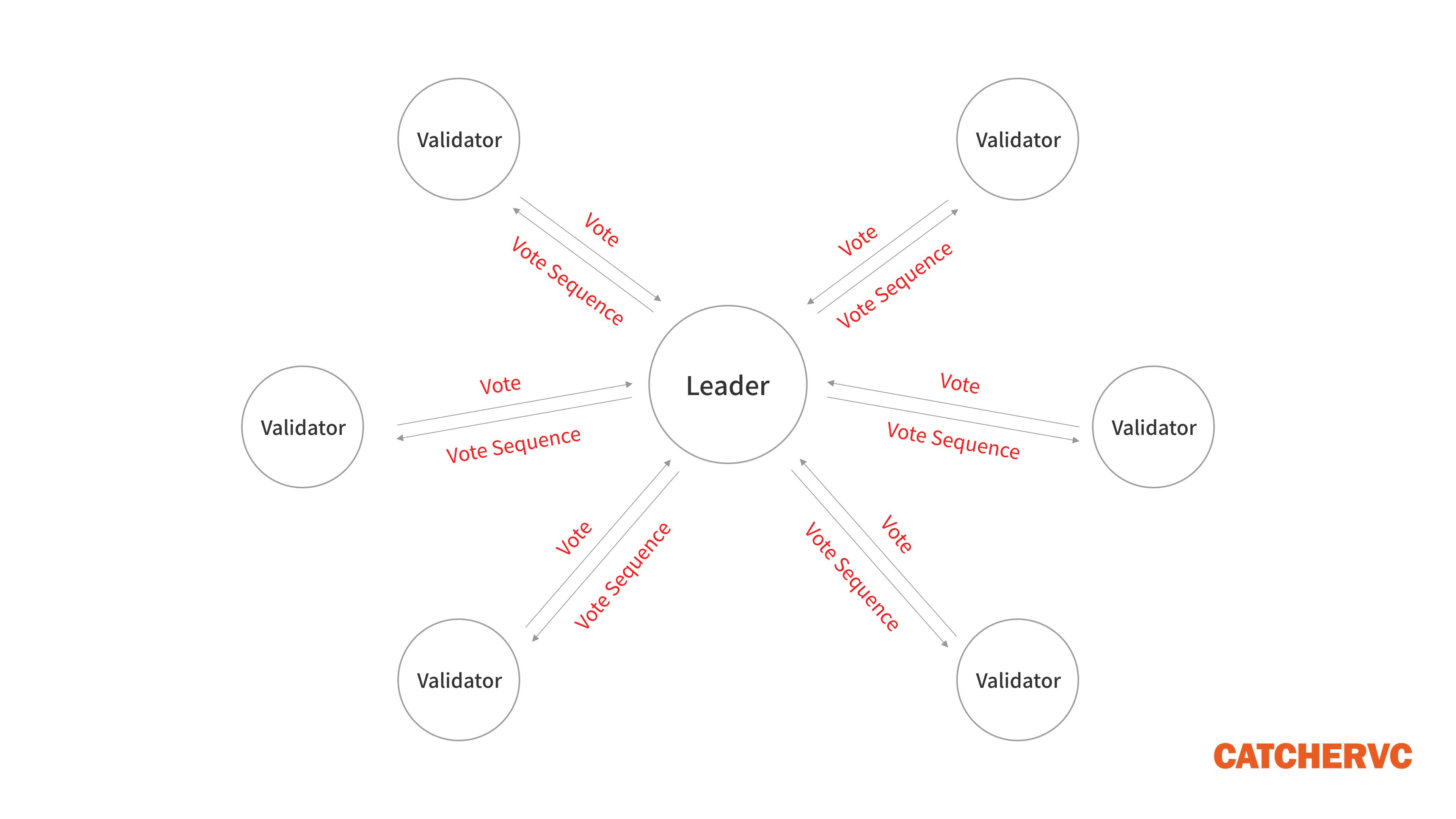
這樣一來,節點們無需再通過 “流言協議” 頻繁的、1 個 1 個的互換投票信息,通訊次數降低到了常數 N 甚至是 logN 的數量級,這在很大程度上縮短了出塊時間,大幅提高了 TPS。
目前 Solana 出塊週期基本和單個 Slot 的時長一致,為 0.4~0.8 秒,甚至比 Avalanche 還快出 3 倍。(Solana 瀏覽器顯示的區塊,實質是每個 Slot 內 Leader 發布的交易序列)。
但這也帶來了另一個問題:由 Leader 在交易序列(區塊)內發布節點們的投票信息,會佔用區塊空間。在 Solana 的設定中,Leader 實質將共識投票作為一種交易事件來處理,其發布的交易序列包含節點投票 Vote,而這些投票正是 Solana TPS 的主要成分(一般佔 70% 以上)。
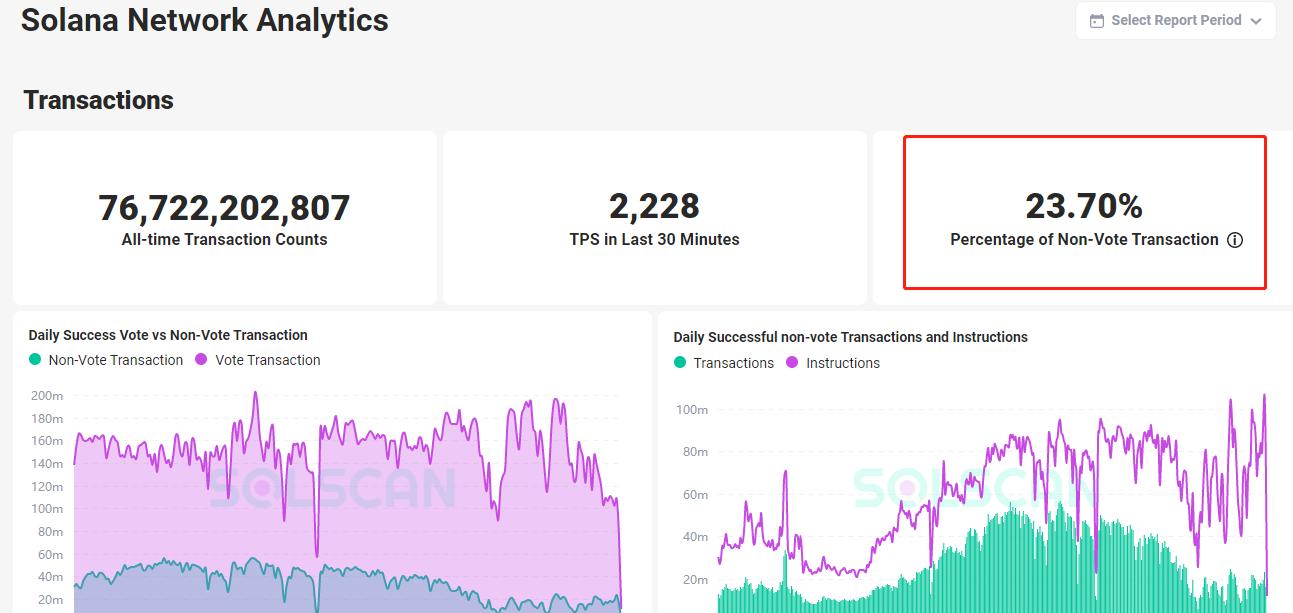
按照 Solana 瀏覽器裡的數據統計,其實際 TPS 維持在 2000~3000 左右,其中 70% 以上是與普通用戶無關的共識投票訊息,與用戶交易相關的實際 TPS 維持在 500~1000,雖然比 BSC 和 Polygon、EOS 等高性能公鏈還高出 1 個量級,但仍無法達到官方所鼓吹的上萬級別。
同時,如果 Solana 未來不斷的提升去中心化程度,允許更多的節點參與共識投票(目前有近 2000 個 Validator),則 Leader 發布的交易序列中必將包含更多的投票訊息,會持續壓縮與用戶交易相關的 TPS 空間。這標誌著 Solana 在不分片的前提下,基本難以取得更高的 TPS。
某種程度來看,Solana 每秒 500~1000 筆的交易處理能力已達到無分片公鏈的巔峰,在節點數量較多、不分片且支持智能合約的前提下,新公鏈基本難以超越 Solana 的 TPS 量級,除非它們採用 “委員會” 模式,只允許少量節點參與共識,或者退化為中心化服務器。只要參與共識的節點數量很多,就難以取得比 Solana 更高的 “可證實的 TPS”。
格外值得注意的是,由於每個 Epoch 內 (2~4 天)的出塊者名單是提前公開的,Solana 的共識協議與原始的 Tendermint 算法並無本質區別,實際都沒有賦予出塊者以不可預測性,所有人都能預知未來某個時間點由誰來出塊,這就會在 可用性/安全性上產生諸多隱患。
(Leader 易遭遇有預謀的 DDOS 攻擊,提高了故障率,若連續幾個 Leader 出現故障,則網絡容易宕機;且用戶可提前賄賂 Leader 等)
2.Gulf Stream 與網絡宕機: Solana 公開出塊者 Leader 名單還有一個更重要的目的:配合其獨創的 Gulf Stream(海灣流)機制,提高網絡處理交易的速度。

用戶發起交易後,往往被客戶端程序直接轉發給指定的 Leader,或者先被某個普通節點接收,再被該節點快速發送給 Leader。這種方式可以讓 Leader 盡快接收交易請求,提高響應速度。(稱為 Gulf Stream 機制,是 Solana 宕機的主因之一)
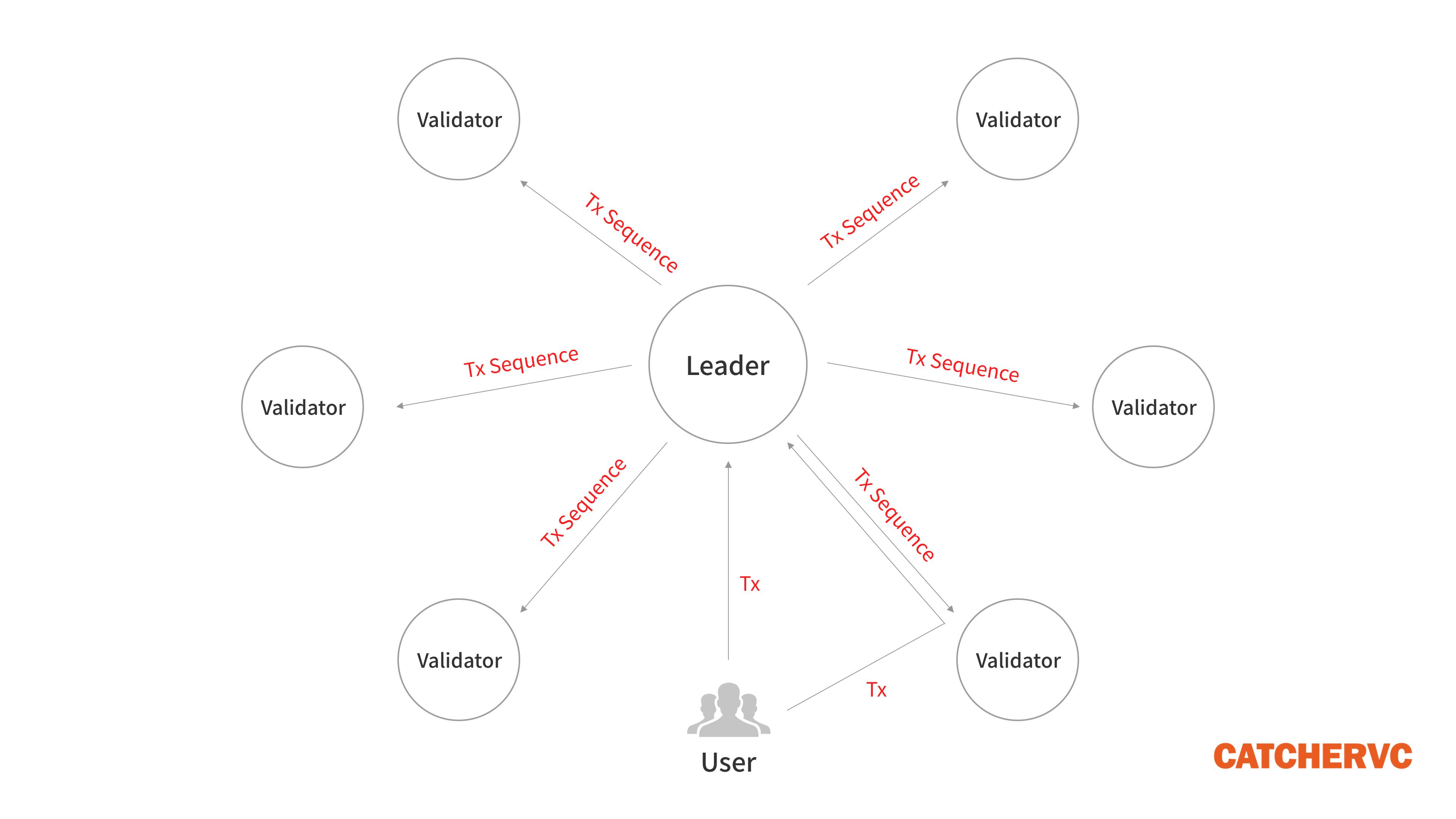
Solana 的這種設定,是與其他公鏈截然不同的交易提交方式。Gulf Stream 取締了比特幣和以太坊的 “全局交易池” 設定,普通節點不運行大容量的交易池。一個節點收到用戶的待處理交易後,只需交給 Leader,不必再發給其他節點,這種做法大幅提高了效率,但由於取締了交易池,普通節點無法高效攔截垃圾交易,容易導致 Leader 節點宕機。
為了深刻理解這一點,我們可以對比 ETH:
·以太坊的每個全節點都有名為交易池(內存池)的存儲區域,用於存放未上鍊、待處理的交易指令。
·當節點接收到新的交易請求後,會先進行過濾,判斷交易指令是否合規(是否為重複/垃圾交易),之後將其存入交易池,再轉發給其他節點(病毒式擴散)。
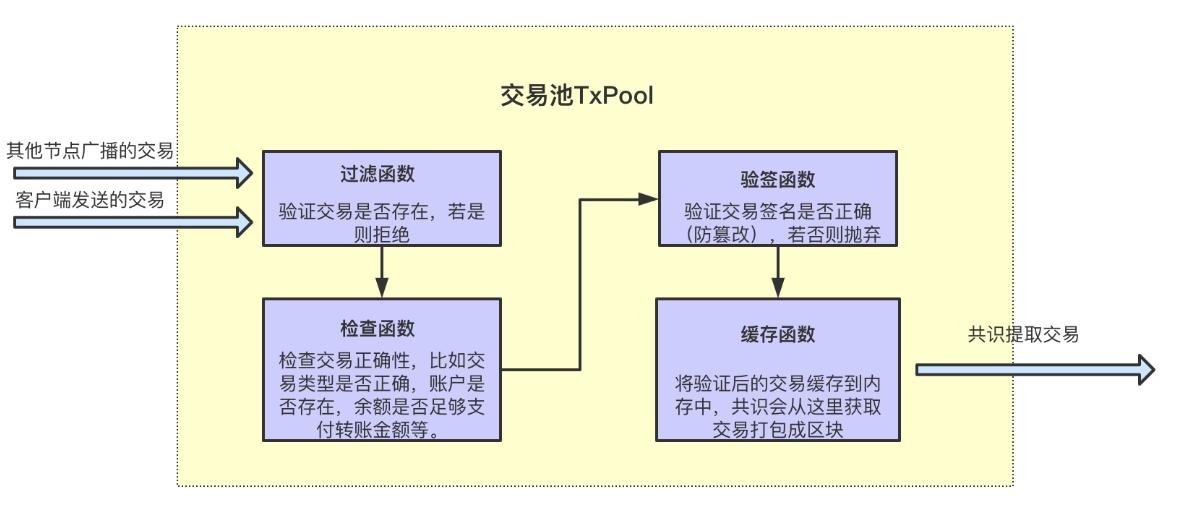
·最終,一筆合法的待處理交易會傳遍網絡,放入所有節點的交易池裡,這就讓不同節點都獲取到相同的數據,表現出 “一致性”。
以太坊和比特幣採取這種機制,理由很明確:不知道未來的出塊者是誰,所有人都有概率打包新區塊。所以,必須讓不同節點接收到相同的待處理交易,為打包區塊做準備。
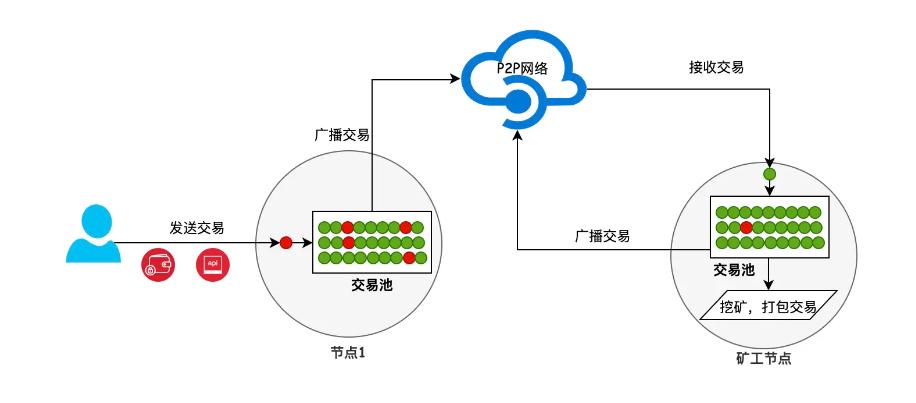
如果有礦池節點發布新區塊,接收區塊的節點會解析其中的交易序列,按次序執行,再把這部分交易指令從交易池中清掉。至此,一批待處理的交易就可以上鍊。
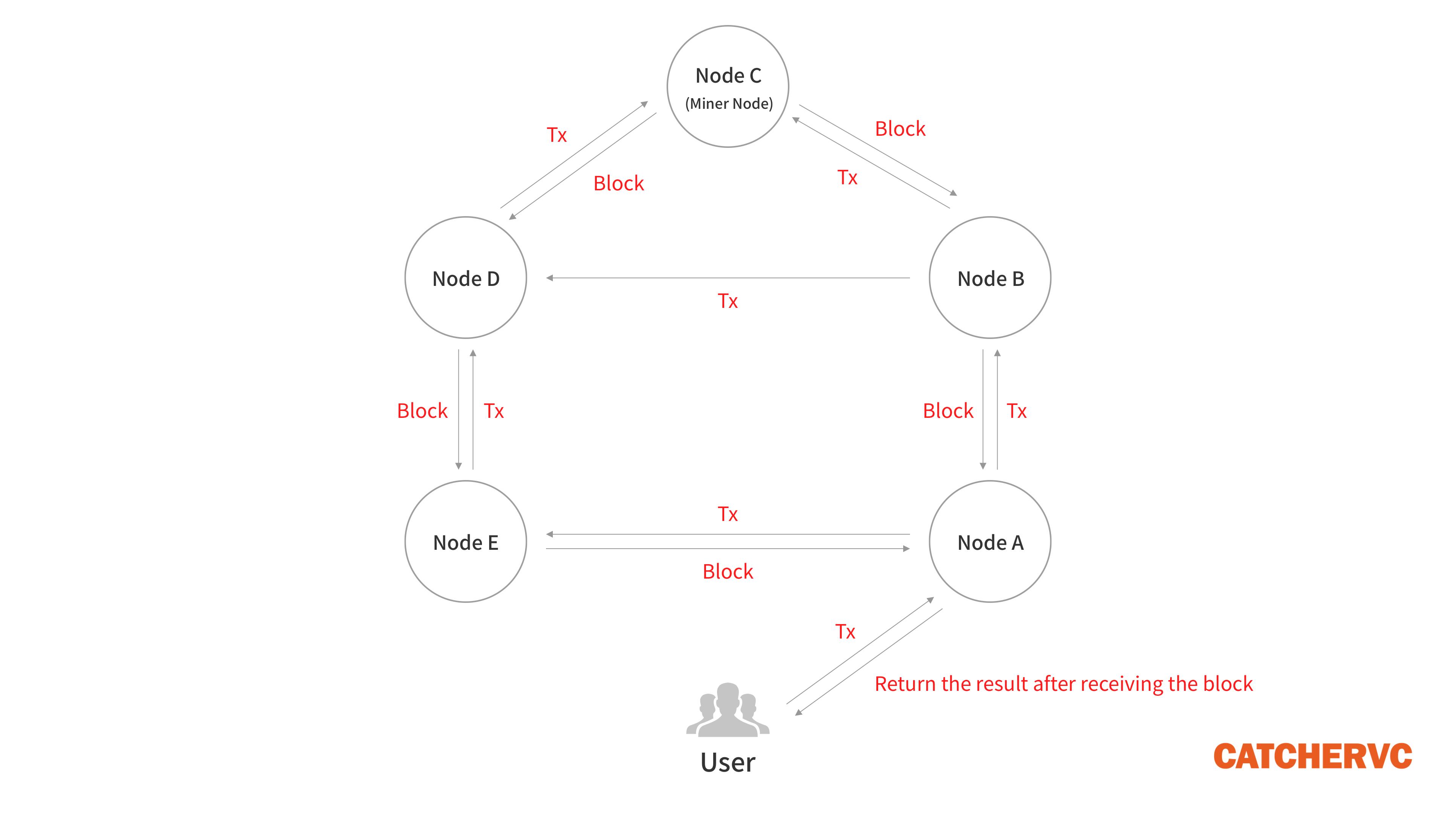
Solana 取締了以太坊的那種交易池,待處理的交易無需在網絡內隨機擴散,而被快速提交給指定的 Leader,再打包成交易序列一次性分發出去(類似於前文的分發投票的方式)。最終,一筆交易只需要夾在交易序列裡,在網絡內傳播 1 圈(以太坊實際是 2 圈)。在交易數量很大的情況下,這個細微差別可以大幅提高傳播效率。
但根據交易池 TxPool 的相關技術說明,交易池/內存池實質發揮了數據緩衝區和過濾器的作用,能提升公鏈可用性。所有節點都運行交易池,收錄網絡內全部待處理交易,不同節點就可以獨立過濾垃圾請求,第一時間攔截重複交易,分擔流量壓力。雖然採用交易池會放慢出塊速度,但如果有用戶發起重複交易(交易池裡有記錄的請求),或其他類型的垃圾請求,接收到交易的節點可在本地將其過濾,不會再轉發出去,這就讓過濾工作被全網節點分擔開。
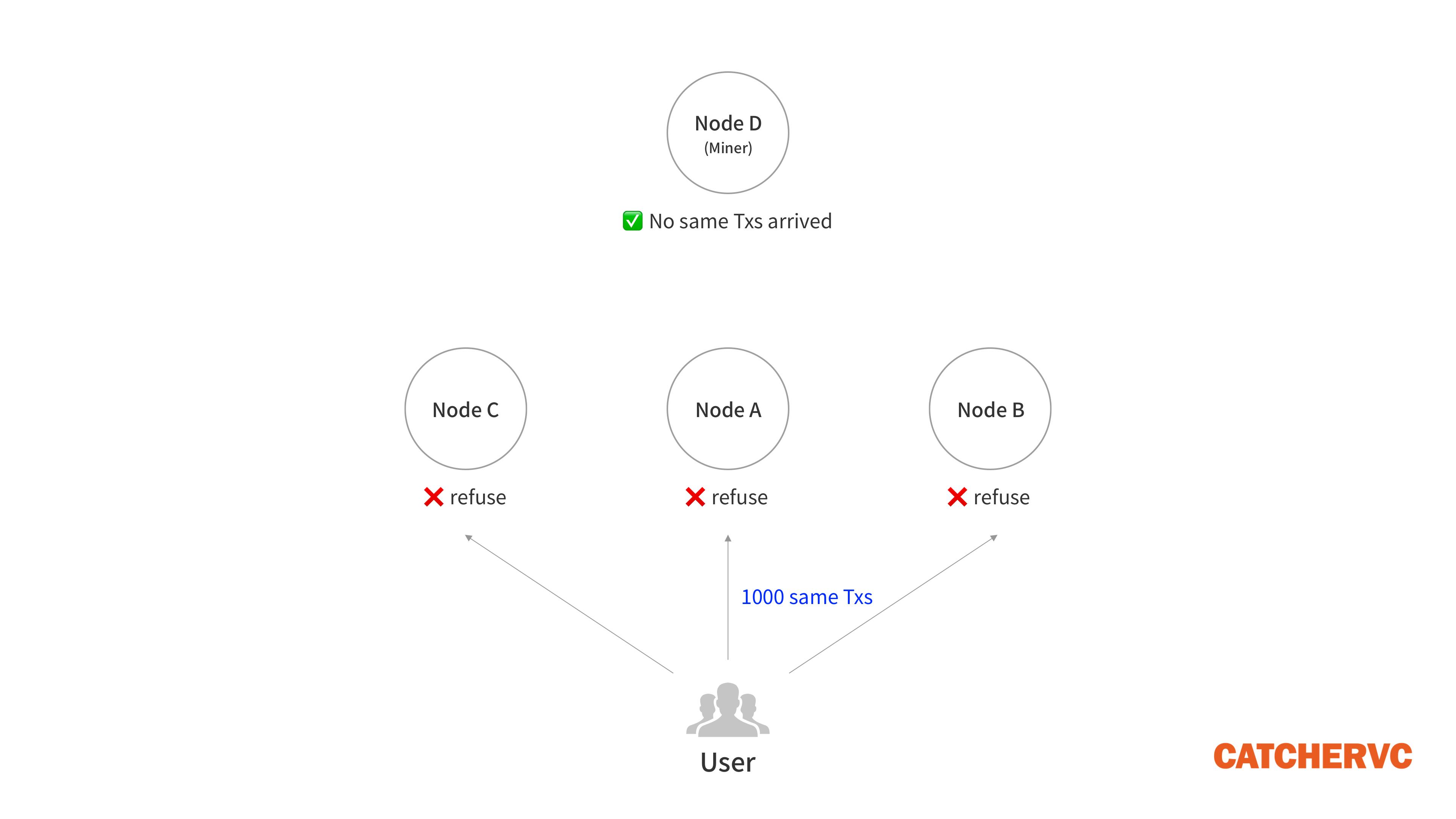
Solana 採取了背道而馳的做法。在 Gulf Stream 機制下,普通節點們不運營全網一致的交易池,無法高效攔截重複/垃圾交易。普通節點真正能做的,只是檢查交易數據包是否符合正確格式,無力辨別惡意重複請求。同時,由於普通節點 “一股腦” 的把交易指令推給 Leader,相當於把過濾交易的 “重擔” 甩給了 Leader 自己,在流量極大、重複交易數量極多的情況下,Leader 節點會因壓力過大而無法順利出塊,共識投票將無法順利傳播,網絡容易崩潰。
對此,Solana 創始人 Anatoly Yakovenko 於今年 1 月 27 日表示,某些熱門項目的公售時段,每秒最多有近 200 萬筆交易請求到達同一個 Leader 節點,其中 90% 以上是完全相同的重複交易,最終導致 Solana 宕機。
(參考資料:《深度調查:新公鏈們為何頻現宕機事故?》)
綜上所述,以太坊實質是犧牲效率換安全,Solana 則是犧牲安全換效率,它所面臨的問題可歸納為:
由於 Leader 輪換順序是給定的,必須按照這個輪換鏈條不斷的走下去。但由於流量分擔機制不完善,Leader 節點故障機率較高,如果某段時間內用戶流量過大(如某些火熱 NFT 開啟公售),可能使多個 Leader 先後出現故障(比如未來 40 個 Slot 的 Leader 都不能順利出塊),這樣一來,共識過程受阻,網絡會分叉、Leader 輪換鏈條會徹底斷裂,最終會徹底崩潰。
3. 類似 BT 種子的 Turbine 傳輸協議:在上文的 Gulf Stream 機製配合下,Leader 迅速接收一段時間內的全部交易請求,檢查其合法性,之後會執行交易。同時,Leader 採用稱為 POH(Proof of History)的機制,為每筆交易都蓋上一個序列號,為交易事件排序。(細節將於後文闡述)
Leader 把交易事件排好序後,會把交易序列切成 X 個不同的碎片,分別發送給質押資產最多的 X 個 Validator,再由他們傳播給其他 Validator。Validator 群體會自行交換收到的碎片,在本地拼湊完整的交易序列(區塊)。
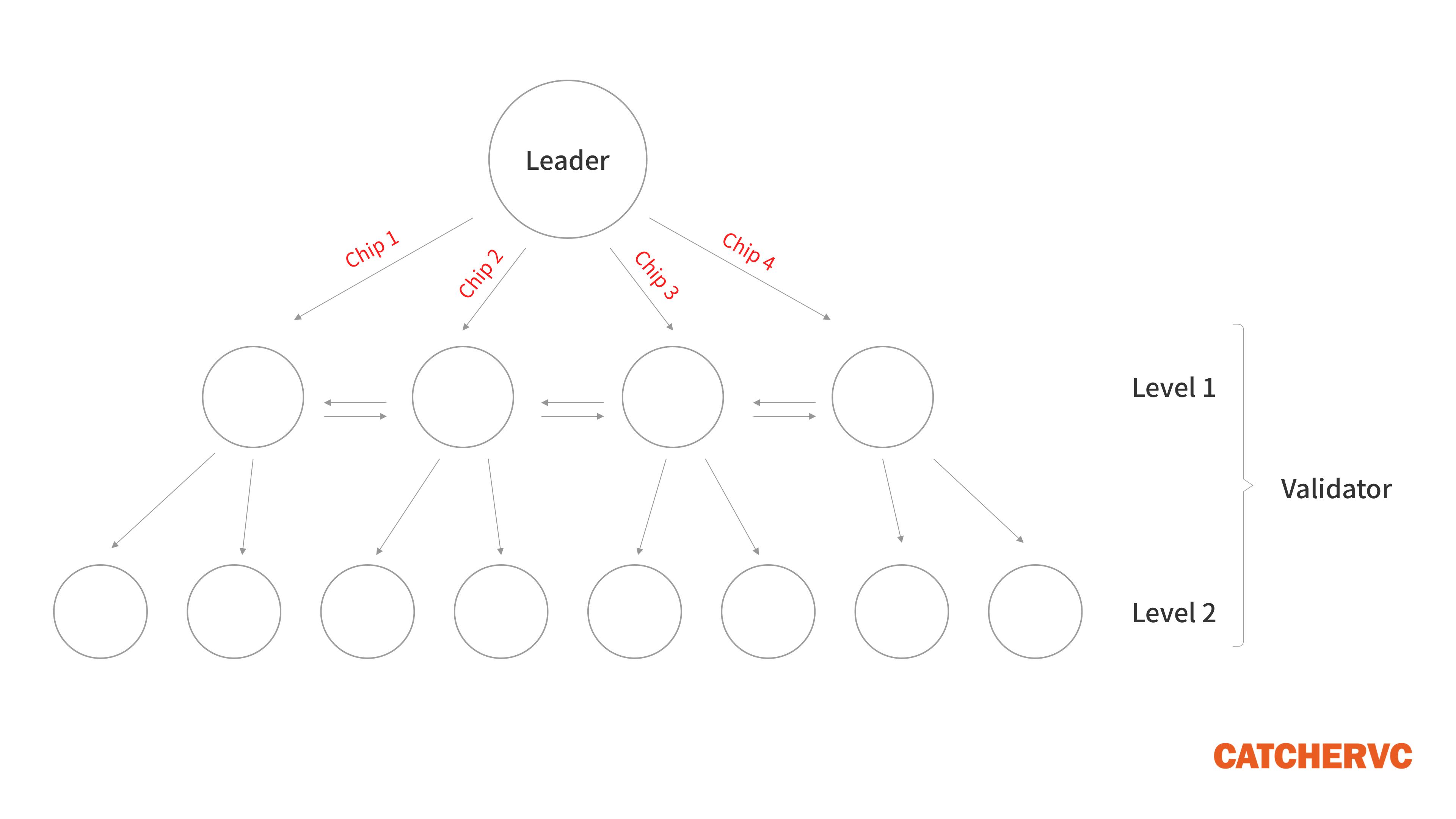
為了便於理解,我們可以將每個不同的碎片視作數據量縮減的小區塊。Leader 一次對外分發 X 個碎片,相當於發出 X 個不同的小區塊,讓不同的節點接收並進一步擴散。
Solana 的這種消息分發方式很特別,靈感來自於 BT 種子。(原理不易用文字表述,主旨在於同時利用多個節點的閒置帶寬,並行式的傳輸數據)。一般而言,交易序列被切分的碎片數越多,節點群體擴散碎片、拼湊交易序列的速度越快,數據同步效率也會顯著提升。
而在其他公鏈中,出塊者會向 X 個鄰居節點發送相同的區塊,相當於把一個區塊複製 X 份發出去,而非分發 X 個不同的碎片(小區塊),這種做法產生的數據冗餘和帶寬浪費很嚴重。究其根源,傳統的區塊 Block 式結構不可切分,根本無法靈活傳輸,而 Solana 乾脆以交易序列 Sequence 替代區塊式結構,結合類似 BT 種子的 Turbine 協議,可以實現高速的數據分發,極大提升了吞吐量 TPS。
Solana 官方曾表示,在 Turbine 傳輸協議下,網絡有 4 萬個節點時,可以在 0.5 秒內把一個交易序列同步給所有節點。
同時,在 Turbine 協議下,節點按照其質押資產的權重,被劃分為不同的層級(優先級),質押資產多的 Validator 率先收到 Leader 發出的數據,之後由這些節點傳遞給下一層。在這種機制下,佔全網質押資產 2/3 權重的節點群體,會最先收錄 Leader 發出的交易序列,加快賬本(區塊)的確認速度。
根據 Solana 瀏覽器披露的數據,目前 2/3 的質押權重被 132 個節點瓜分,再結合前文所說的傳播機制,這些節點最先收到 Leader 發出的交易序列,也會率先給出投票。而只要得到這 132 個節點的投票,Leader 發布的交易序列便可敲定。從某種角度看,這些節點搶跑在其他節點之前,如果他們串謀,便可產生某些作惡場景。
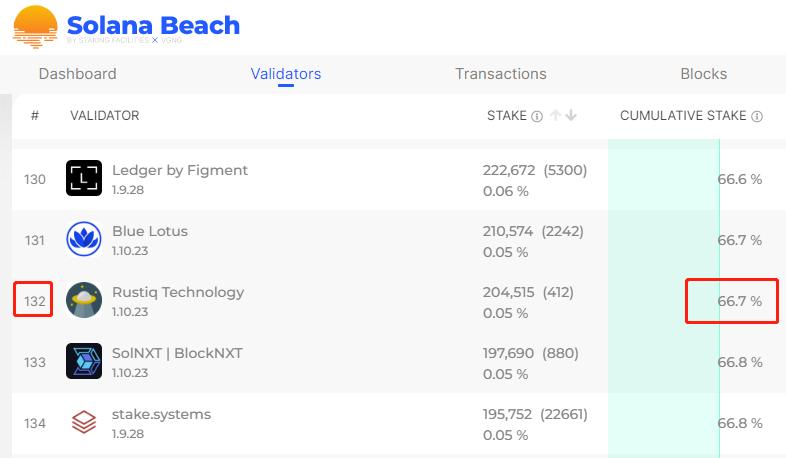
更值得注意的是,目前 Solana 有 25 個節點佔據了 1/3 的質押權重,按照拜占庭容錯理論,只要這 25 個節點集體串謀(比如故意不向某個 Leader 發出投票),足以讓 Solana 網絡陷入混亂。某種程度來講,Solana 面臨的 “寡頭政治” 問題是所有採用 POS 投票制的公鏈都應該去重視的。

4.POH(Proof Of History):前文提到,Turbine 協議允許 Leader 將交易序列切碎,把不同的碎片發佈出去。這種做法要有一個保障:交易序列被切碎後,要容易被拼湊復原。為了解決這個問題,Solana 特意在數據包中摻雜糾刪碼(可防止數據丟失),並且引入獨創的 POH(Proof Of History)機制為交易事件排序。

在 Solana 白皮書中,Yakovenko 以哈希函數 SHA256 為案例,展示了 POH 的原理。為了便於理解,本文將以下面的例子解釋 POH 機制:
(由於 POH 及對應的時間演進邏輯較難用語言描述,建議先閱讀 Solana 中文白皮書對 POH 的解讀, 再將本文以下橋段作為輔助閱讀)
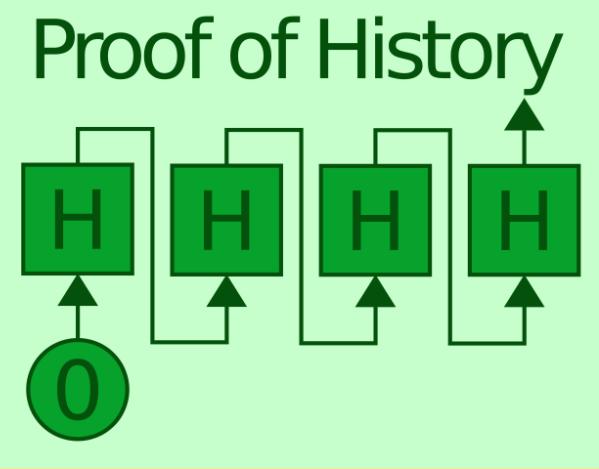
·SHA256 函數的輸入值和輸出值是唯一映射的(1 對 1),輸入參數 X 後,僅有唯一的輸出結果 SHA256(X)=?;不同的 X 會得到不同的?=SHA256(X);
·如果循環、遞歸的計算 SHA256,比如:
定義 X2 = SHA256 ( X1 ), 再用 X2 計算 X3 = SHA256 (X2),再算 X4 = SHA256 (X3),如此重複迭代下去,Xn = SHA256 ( X[n-1] );
·反复執行這個過程,最終我們會得到一個 X1,X2,X3......Xn 的序列,該序列有個特點:Xn = SHA256 ( X[n-1] ),排在後面的 Xn 是前面 X[n-1] 的 “後代”。
·將該序列公開發布後,如果有外人想驗證序列的正確性,比如他想判斷 Xn 是否真的是 X[n-1] 的 “合法後代”,可以直接將 X[n-1] 代入 SHA256 函數去算,看結果和 Xn 是否相同。
·在這種模式下,沒有 X1 就得不到 X2,沒有 X2 得不到 X3...... 沒有 Xn 得不到後面的 X[n+1]。這樣一來,序列就具有了連續性和唯一性。
·最關鍵的一點:交易事件可以被插進序列裡。比如:
在 x3 出生後、x4 未出現時,交易事件 T1 可作為外部輸入,和 X3 迭加在一起,得到 x4 = SHA256(X3+T1)。其中,X3 的出現略早於 T1,X4 則為(T1+X3)孕育的後代,T1 實質被夾在 X3 和 X4 的 “生日” 之間。
以此類推,T2 可以在 X8 產生後,作為外界的輸入參數,計算 X9=SHA256(T2+X8),這樣 T2 的出現時間就被夾在 x8 和 x9 的 “生日” 之間;
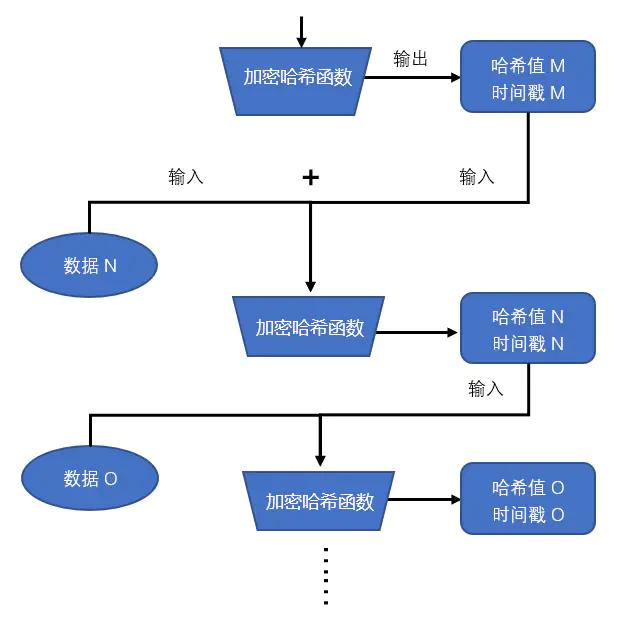
•在上面的場景中,實際的 POH 序列為以下形式:

其中,交易事件 T1 和 T2 是外界插入序列裡的數據,在 POH 序列的時間記錄上,他晚於 X3 早於 X4。
只要給出 T1 在 POH 序列裡的次序號,可得知它之前發生了多少次 SHA256 計算(T1 前面有 X1、X2、X3,發生了 3 次 SHA256 計算)。
同樣的道理,T2 前面有 X1~X8 八個 X,發生了 8 次計算。
以上過程的白話解釋如下:有個人拿著秒錶在那里數秒,每當他收到一封信,他就按照秒錶的讀數,在信封上記下時間。收到十封信後,這十封信上記錄的秒數肯定不同,有先后區分,這就給不同的信件排了序,根據信件上的記錄還可以知道兩封信之間隔多久。
·Leader 在對外發布交易序列時,只要在 T1 的數據包裡給出 X3 的數值,並告知 X3 的序號(第 3 個),接收數據包的 Validator 便可解析出 T1 之前的完整 POH 序列;
只要在 T2 的數據包裡,提供 X8 的數值,及其序號 8,Validator 便可解析出 T2 之前的完整 POH 序列;

·按照 POH 的設定,只要標記出每筆交易在 POH 序列裡的序號(Counter),並給出緊挨著它的 X 值(Last Valid Hash),就可以披露出每筆交易的次序。由於 SHA256 函數本身的特性,這種通過哈希計算來敲定的次序,難以被篡改。
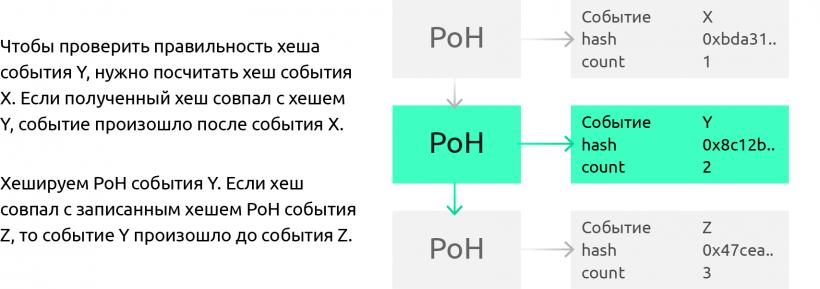
同時,Validator 知道 Leader 得出 POH 序列的方式,他們可以執行相同的操作,還原出完整的 POH 序列,驗證 Leader 發布的數據的正確性。
For example,如果 Leader 發布的交易序列數據包為:
T1,序號 3,緊鄰 X3;
T2,序號 5,緊鄰 X5;
T3,序號 8,緊鄰 X8;
T4,序號 10,緊鄰 X10;
POH 序列初始值 X1;
Validator 接收到以上數據包後,便可把 X1 作為初始參數,循環代入 SHA256 函數自行計算,解析出完整的 POH 序列為:

這樣一來,只要知道序列裡總共包含多少個 X,就可得知計算者做了幾次 SHA256 計算。事先估計好每次哈希計算的耗時,就可以知道不同交易的時間間隔(比如 T1 和 T2 之間隔了 2 個 x,就隔著 2 次 SHA256 計算,約為??毫秒)。得知了不同交易之間相隔的秒數後,可以更方便的確定每筆交易發生的時間點,省去了很多麻煩的工作。
·一般而言,Leader 會時刻不停的執行 SHA256 函數,得到新的 X,把序列不斷向前推進。如果有交易事件,就將其作為外部輸入,插進序列裡;
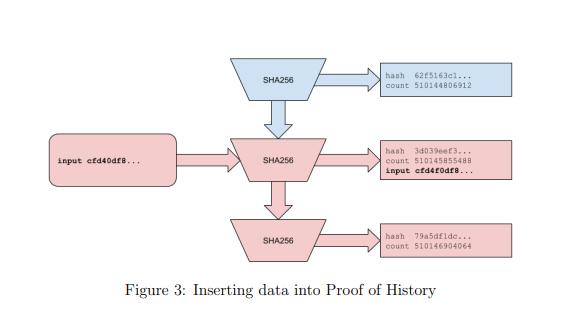
·如果有節點嘗試在網絡中發布摻水的序列,替換 Leader 發布的版本,比如把上文中的 X2 替換為 X2' ,序列變為 X1,X2',X3......Xn,顯然其他人只要對比 X3 和 SHA256(X2'), 就可以發現兩者對不上號,序列造假了。
所以,造假者必須把 X2' 之後的 X 全部替換才行,但這樣做成本很高,尤其在 X 的個數很龐大的情況下,造假將非常浪費時間。此情此景,最好的辦法就是不去造假,收到了 Leader 發出的序列後原方不動的轉發給別的節點。
再考慮到 Leader 會在發布的每個數據包裡加上自己的數字簽名,在網絡內傳播的序列其實是 “唯一的”“難以被篡改的”;
5. 全網一致的時間推進: Solana 的創始人 Yakovenko 曾強調,POH 最大的作用是提供了一個 “全局一致的單一時鐘” (其實應該轉譯為:全網一致的時間推進)
。這句話其實可以這樣理解:
Leader 節點在網絡內發布了一個唯一的、難以篡改的交易序列。根據該交易序列的數據包,節點可以解析出完整的 POH 序列,而 POH 序列是 Solana 獨創的計時方式,可以作為時間參照物。
如前文所述,由於 Leader 會時刻不停的執行 SHA256 哈希計算,把 POH 序列不斷向前推進,這個序列記錄了 N 次哈希計算的結果,對應著 N 次計算過程,包含了時間推移。而 Solana 把計算的次數當做獨特的計時方式。
在原始的參數設定中,默認 200 萬次哈希計算對應現實中 1 秒,每個 Slot 出塊週期為 400 ms,也就是說每個 Slot 產生的 POH 序列包含 80 萬次哈希計算。Solana 還創造了一個名為 Tick(滴答)的名詞,類比鐘錶指針前進時的滴答聲。按照設定,每個 Tick 應該包含 1.25 萬次哈希計算,1 個 Slot 週期包含 64 次 Tick,每 160 次 Tick 對應現實中 1 秒。
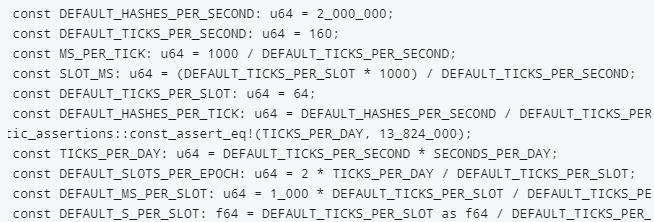
以上只是理想狀態下的設定,在實際的運行過程中,每秒可產生的哈希計算次數往往不固定,所以實際的參數應該是動態調整的。但以上說明可以解釋 POH 機制的大致邏輯,這種設計讓 Solana 節點在收到 POH 序列後,根據其中包含的哈希計算次數,判斷 1 個 Slot 是否結束,以及是否到了下一個 Leader 該出現的時候(4 個 Slot 一輪換)。
由於可以判斷每個 Slot 的起始點,Validator 會把起始點中間夾著的交易序列劃分為一個區塊。一旦得到敲定,就相當於把賬本向前推進了一個區塊,系統則向前推移了一個 Slot。
這就可以用一句話概括:
“時鐘的指針不會回頭,但我們可以用自己的手把它向前推”。—碇源渡《新世紀福音戰士 EVA》
換言之,只要節點都收到相同的交易序列,那麼他們解析出的 POH 序列,及對應的時間推進都是一致的。這就創造了一個 “全局一致的單一時鐘”(全網一致的時間推進)。
(在原始的 Tendermint 算法中,每個節點在本地的賬本上添加的是相同的區塊,區塊高度一致,幾乎從不分叉,所以按照 Solana 對 “時間推移” 的解釋,在 Tendermint 中,不同節點的時間推移應該也是一致的)
此外,由於交易事件在 POH 序列中的序號是給定的,節點僅憑自己計算就可獲知,不同的交易之間隔了多少次哈希計算(隔著幾個 X),也就能大致估算出不同交易之間的時間差△T。
有了大致的△T 和某個初始的時間戳 TimeStamp 0 後,就可以像多米諾骨牌一樣,粗略估算每起事件的發生時刻(時間戳)。
For example:
T1 發生於 01:27:01,T2 與 T1 之間隔著 1 萬次哈希計算(1 萬個 X),如果 1 萬次哈希計算耗時約為 1 秒,則 T2 大概發生在 T1 的 1 秒後,也就是 01:27:02。以此類推,所有交易事件發生的時間(時間戳)都可以粗略推算出來,這帶來了巨大便利,允許節點獨立確認某些數據的送達時間。
同時,POH 機制也方便統計各節點給出投票的時間點。Solana 白皮書中提出,Validator 應該在 Leader 每次發布 State 狀態信息後的 0.5 秒內提供投票。
如果 0.5 秒對應著 100 萬次哈希計算(前文的 100 萬個 X),而 Leader 發布 State 後,後面的序列裡連續 100 萬次哈希計算都沒有收錄進某節點的投票,大家就可以得知這個節點在偷懶,沒有在規定時間內履行投票的義務,屆時系統可以執行相應的懲罰措施 (Tower BFT)。
6. 與 Optimism 的相似性:以上即為 Solana 獨創的 POH(Proof Of History),類似於 Optimism 和 Arbitrum 的交易排序形式,都通過與哈希函數有關的計算,來確立一個 “不可篡改、唯一確定” 的交易事件序列,之後由 Leader/Sequencer 將這個序列發布給驗證節點 Validator/Verifier。
在 Optimism 中也有類似 Leader 的角色,叫 Sequencer(排序器),它在數據傳輸中也取締了區塊式結構,定期在以太坊某合約地址中發布交易序列,叫 Validator 自己去讀取並執行。不同的 Validator 收到的交易序列都是相同的,那麼他們執行下來後得到的狀態 State 也必定相同。這個時候再去對比 Sequencer 的狀態 State,各個 Validator 自己就能驗證其正確性,幾乎不需要和其他節點溝通。
在 Optimism 的共識機制中,並沒有要求不同 Validator 之間進行互動,也沒有收集投票的步驟,“共識” 其實是隱式的。如果有 Validator 執行完交易序列後,發現 Sequencer/Leader 提供的狀態信息 State 不對,就可以發起 “挑戰”,質疑 Sequencer/Leader。但在這種模式下,Optimism 為交易事件提供了 7 天的敲定窗口期,Sequencer 發布交易序列後,需要 7 天無人質疑,才能最終確認,這顯然是 Soalna 無法接受的。
Solana 要求 Validator 盡快給出投票,目的在於讓網絡快速達成共識,快速敲定交易序列,這樣可以比 Optimism 具備更高的效率。
此外,Solana 分發和驗證交易序列的方式更靈活,允許將一個序列切碎,以碎片的形式分發,這為 Turbine 協議的實行創造了完美的土壤;
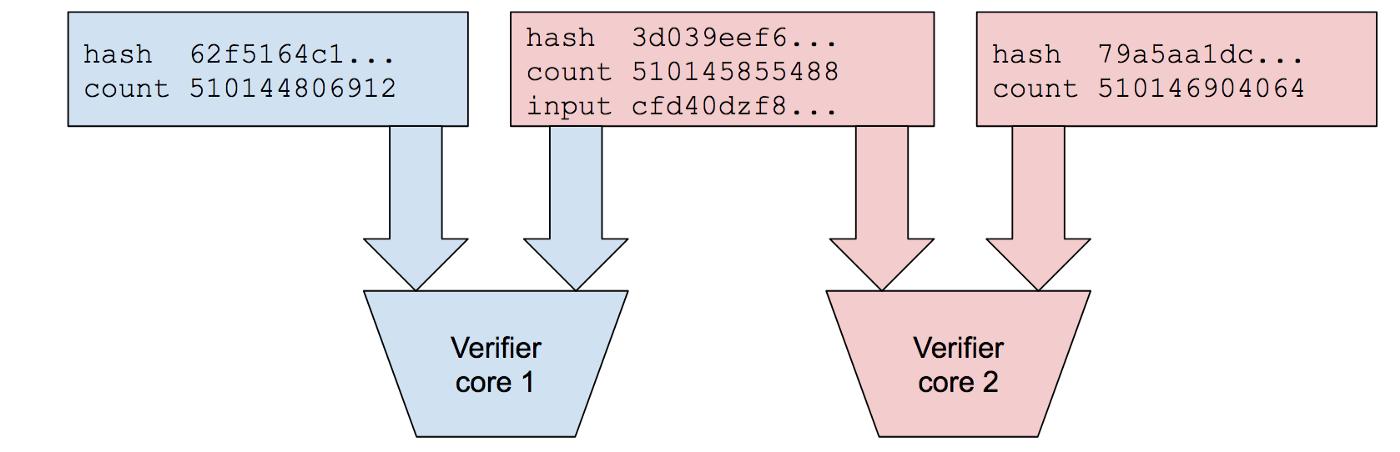
同時,Solana 允許節點同時運行多個計算部件,並行式的驗證不同碎片的正確性,把驗證工作分擔開,大幅節約時間。在 OP 和 Arbitrum 中則不允許這種做法,Optimism 直接以 1 筆交易對應 1 個執行後狀態 State 的方式,通過 Transcation—State 映射的形式給出交易序列,只能由一個 CPU 核心從頭到尾一步一步的去計算一遍,才能驗證整個序列的正確性,相對而言笨重低效很多。Solana 的 POH 序列可以從任意一個位置開始驗證,多個計算單元可以同時驗證不同的 POH 片段,這就為多線程並行式的驗證模式提供了基礎。
7. 針對節點本身的縱向擴容:以上是 Solana 在出塊流程、共識機制和數據傳輸協議上的改良,除此之外,Solana 還創建了名為 Sealevel 和 Pipeline、 Cloudbreak 的機制,支持多線程、並行、並發的執行模式,並支持以 GPU 來作為執行計算的部件,大幅提高了節點處理指令的速度,優化了硬件資源的利用效率,屬於縱向擴容的範疇。由於相關技術細節較為複雜,且與本文的側重點並無關聯,在此不展開贅述。
雖然 Solana 的縱向擴容大幅提升了節點設備處理交易指令的速度,但也抬高了對硬件配置的要求。目前 Solana 的節點配置要求很高,被許多人評為 “企業級硬件水平”,並被斥責為 “節點設備最昂貴的公鏈”。
以下為 Solana 的 Validator 節點硬件要求:
Cpu 12 或 24 核,內存至少 128 GB,硬盤 2T SSD,網絡帶寬至少達到 300 MB/s,一般為 1GB/s。
再對比當前以太坊節點的硬件要求(轉型 POS 前):
CPU 4 核以上,內存至少 16 GB,硬盤 0.5 T SSD,網絡帶寬至少 25 MB/s。
考慮到以太坊轉型 POS 後節點硬件配置要求會調低,Solana 對節點硬件的要求遠遠高於前者。根據部分說法,一個 Solana 節點的硬件成本,相當於幾百個轉型 POS 後的以太坊節點。由於節點運行成本過高,Solana 網絡的運行工作很大程度上成為了鯨魚和專業機構、企業的專利。
對此,以太坊前 CTO、Polkadot 創始人 Gavin Wood 曾在去年 Solana 首次宕機後評論稱:真正的去中心化和安全性比高效率更有價值。如果用戶不能自己運行網絡的全節點,那麼這樣的項目將和傳統銀行毫無區別。
全文總結
- Solana 擴容主要基於:高效利用網絡帶寬、減少節點間通訊次數、加快節點處理事務的速度三大方面,這些措施直接縮短了出塊和共識通訊的時間,但也降低了系統可用性(安全)。
- Solana 提前公開每個出塊週期 Slot 內的出塊者 Leader 名單,實質揭示了單一可信的數據來源,藉此大幅精簡了共識通訊的流程。但公開 Leader 信息會帶來賄賂、針對性攻擊等潛在安全隱患。
- Solana 將共識通訊(投票信息)作為一種交易事件來處理,TPS 成分中往往超過 70% 都是共識訊息,真實與用戶交易相關的 TPS 約為 500—1000;
- Solana 的 Gulf Stream 機制實質取締了全局性交易池,雖然這提高了交易處理速度,但普通節點無法高效攔截垃圾交易,Leader 會面臨巨大壓力,容易致使其宕機。若 Leader 宕機,則共識訊息無法正常發布,網絡容易分叉甚至崩潰;
- Solana 的 Leader 節點發布的是交易序列,而非真實的區塊。結合 Turbine 傳輸協議,交易序列可以被切碎後分發給不同節點,最終的數據同步速度極快。
- POH(Proof Of History)實質為一種計時和計數方式,它可以給不同的交易事件蓋上不可篡改的序號,生成交易序列。同時,由於同一時間只有單一的 Leader 發布交易序列,其中蘊含 POH 計時序列,Leader 實質上發布了全網一致的計時器(時鐘)。在一個很短的窗口期內,不同節點的賬本推進、時間推移都是一致的;
- Solana 有 132 個節點佔據 67% 的質押份額,其中的 25 個節點佔據 33% 的質押份額,基本構成了 “寡頭政治” 或 “元老院”。如果這 25 個節點串謀,足以導致網絡陷入混亂;
- Solana 對節點硬件水準要求較高,它在抬高設備成本的基礎上,實現了縱向擴容。但這也致使運行 Solana 節點的個體多為鯨魚或機構、企業,不利於真正意義的去中心化。
從某種角度來看,Solana 實際成為了公鏈中最特立獨行的存在,它以高級的節點硬件水準、顛覆性的共識機制與網絡傳輸協議,將 Layer1 擴容的敘事推向了極端,基本觸及了無分片公鏈可長期維持的 TPS 瓶頸,但 Solana 的多次宕機,似乎已經說明了犧牲可用性/安全性來換取效率的最終結局。
從長遠看,去中心化和安全性始終是公鏈領域的核心敘事,雖然 Solana 靠著一時的 TPS 數值與 SBF 等金融大鱷的推波助瀾,一度成為資本簇擁下的瑰寶,但 EOS 的結局已經昭示,Web3 世界不需要單純的營銷和高效率,只有真正具備可用性的事物,能夠在歷史洪流的沖刷中屹立不倒,永世長存。
(在此特別感謝《嵌入式系統安全》的作者劉洋先生、Rebase 社區及 W3.Hitchhiker 團隊對本文作者的幫助)
參考文獻
1.Solana 白皮書中文版
2.Gulf Stream: Solana's Mempool-less Transaction Forwarding Protocol
6. 與幣安錢包合作的高性能公鏈 Solana 是如何提速的?
13.Tendermint-2-共識算法:Tendermint-BFT 詳解
14.Cardano(ADA)的共識算法 Ouroboros
16. 深度解讀 Optimism:基本架構、Gas 機制與挑戰| CatcherVC Research
17. 剖析新版 Metis:Gas 最低 Layer2 的去中心化進行時|CatcherVC Research
免責聲明:作為區塊鏈信息平台,本站所發布文章僅代表作者及嘉賓個人觀點,與 Web3Caff 立場無關。本文內容僅用於信息分享,均不構成任何投資建議及要約,並請您遵守所在國家或地區的相關法律法規。










