

目标读者:开发者以及对区块链领域的技术感兴趣的朋友。本文希望尽量以通俗的方式说明智能合约当前遇到的难题以及 Move 的一些尝试,尽量少用代码,期望不懂编程语言的朋友也能大致理解,但这个很难,希望读者给一点反馈。
作者:jolestar
原用标题:为什么是 Move 之编程语言的生态构建
作为一个 Move 的鼓吹者,每次给开发者推广 Move 的时候都会遇到这样的问题。Move 有什么优势吗?为什么是 Move?就像你给好友介绍自己的新恋人,总会遇到类似的问题。但这种问题其实不易回答,如果一条一条列举优缺点,总是会有人质疑,毕竟新语言的生态都不成熟,选择只能基于它的潜力来判断。我先说一个论断: Move 是最有潜力构建出 Solidity 这样的生态系统,甚至超越的智能合约编程语言。
智能合约的两条路
如果把时间拖回到几年前,新公链上支持图灵完备智能合约的编程语言主要有两种方式:
一种是基于现有的编程语言进行裁剪,然后运行在 WASM 等通用的虚拟机里。这种方案的优势是可以沿用当前编程语言以及 WASM 虚拟机的生态。
一种是新造一个专门的智能合约编程语言,以及虚拟机,从头构造语言以及虚拟机生态。Solidity 就是这条路线,Move 也是这条路线。
那时候大家普遍其实不太看好 Solidity&Evm 生态,觉得 Solidity 除了用来发 Token,貌似也没有什么用,性能也不好,工具也孱弱,像是个玩具。很多链的目标是让开发者用已有的语言来进行智能合约编程,觉得前一条路更被看好,很少有新公链直接复制 Solidity&Evm。
但经过几年的发展,尤其 DeFi 崛起之后,大家突然发现 Solidity 的生态不一样了。而走前一条路的智能合约生态反倒没有成长起来,为什么呢?我总结有几个原因。
- 区块链的程序运行环境和面向操作系统的程序运行环境区别很大,如果抛弃掉操作系统调用,文件 IO,硬件,网络,并发等相关的库,再考虑链上的执行成本,已有编程语言能和智能合约共享的代码库非常少。
- 第一种方案理论上能支持的语言很多,但实际上带有 Runtime 的编程语言编译到 WASM 等虚拟机后文件会非常大,不适合区块链场景使用,能用的也主要是 C, C++, Rust 等。而这几种语言的学习门槛实际上并不比 Solidity 这种专门的智能合约编程语言的成本更低,并且同时支持多个语言可能会导致早期生态的割裂。
- 各链的状态处理机制不一样,即便都用都是 WASM 虚拟机,各链的智能合约应用也不能直接迁移,无法共享一个共同的编程语言以及开发者生态。
对应用开发者来说,直接面对的就是智能合约编程语言,编程语言的基础库,有没有可复用的开源库。DeFi 的安全性要求智能合约代码要经过审计,而经过审计的代码每一行都代表着钱,大家基于已有的代码略做修改进行复制,就能降低审计成本。
现在看来 Solidity 虽然走了一个看起来慢的路,但实际上更快的构建出了生态。现在很多人已经认为 Solidity&EVM 就是智能合约的终点了,很多链都开始兼容或者移植 Solidity&Evm。这时候,新的智能合约编程语言需要证明自己有更强的生态构建能力,才能说服大家关注与投入。
那新的问题就是,一个编程语言语言,如何衡量它的生态构建能力?
编程语言的生态构建能力
编程语言的生态构建能力,简单的来说就是它的代码的复用能力,主要体现在两个方面:
- 编程语言模块之间的依赖方式。
- 编程语言模块之间的组合方式。“可组合性” 是智能合约标榜的一个特性,但实际上编程语言都有组合性,我们发明的 Interface, Trait 等都是为了更方便的组合。
先说说依赖方式,编程语言实现实现依赖主要通过三个方式:
- 通过静态库(Static-Libraries)的方式,在编译期静态链接,将依赖打包在同一个二进制中。
- 通过动态库(Dynamic-Libraries)的方式,运行时动态链接,依赖并不在二进制中,但要预先在目标平台上部署。
- 通过远程调用(RPC)在运行期依赖。这里泛指各种可以远程调用的 API。
1,2 一般都用在基础库依赖的场景下。基础库一般是无状态的,因为应用如何处理状态,比如写哪个文件里,还是存哪个数据库表里,基础库是很难假设。这种调用是在同一个进程同一个方法调用的上下文里,共享调用栈,共享内存空间,没有安全隔离(或者说隔离很弱),需要可信环境。
3 实际上调用的是另外的进程或者另外的机器上的进程,互相通过消息通信,各进程负责自己的状态,所以可以提供状态的依赖,调用也有安全隔离。
这三种方法各有优劣。1 在最终二进制中包含依赖的库,优点是对目标平台的环境无依赖,但缺点是二进制比较大,2 的优势是二进制比较小,但对运行环境有前置要求,3 可以构建跨语言的依赖关系,一般用在跨服务,跨机构合作的场景中,为了方便开发者调用,一般通过 SDK 或者代码生成模拟成方法调用。
技术历史上,很多编程语言,操作系统平台都花费了很大的精力想弥合远程调用和本地调用之间的差异,想实现无缝的远程调用和组合。随便举一些著名的技术词汇,COM(Component Object Model)/CORBA/SOAP/REST 等等,都是为了解决这些问题。虽然实现无缝调用组合的梦想破灭了,大家最后还是靠工程师人力拼接口,把整个 Web2 的服务给拼接在一起,但梦想的火种还在。
而智能合约,给应用间的依赖方式带来了新变化。
智能合约带来的改变
传统的企业应用之间的依赖方式可以用下图表示:
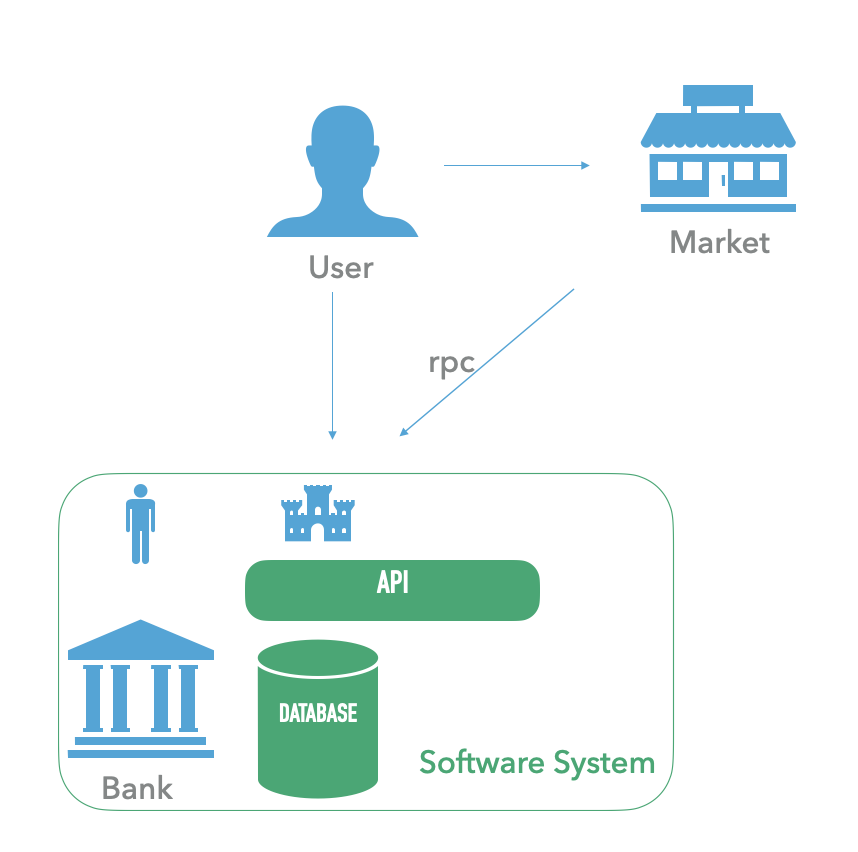
- 系统之间通过各种 RPC 协议把运行在不同的机器上的服务连接在一起。
- 机器之间有各种技术的,人工的 “墙” 进行隔离,保证安全。
而智能合约的运行环境是链的节点给构造出的沙箱环境,多个合约程序是运行在同一个进程内的不同的虚拟机沙箱中,如下图所示:
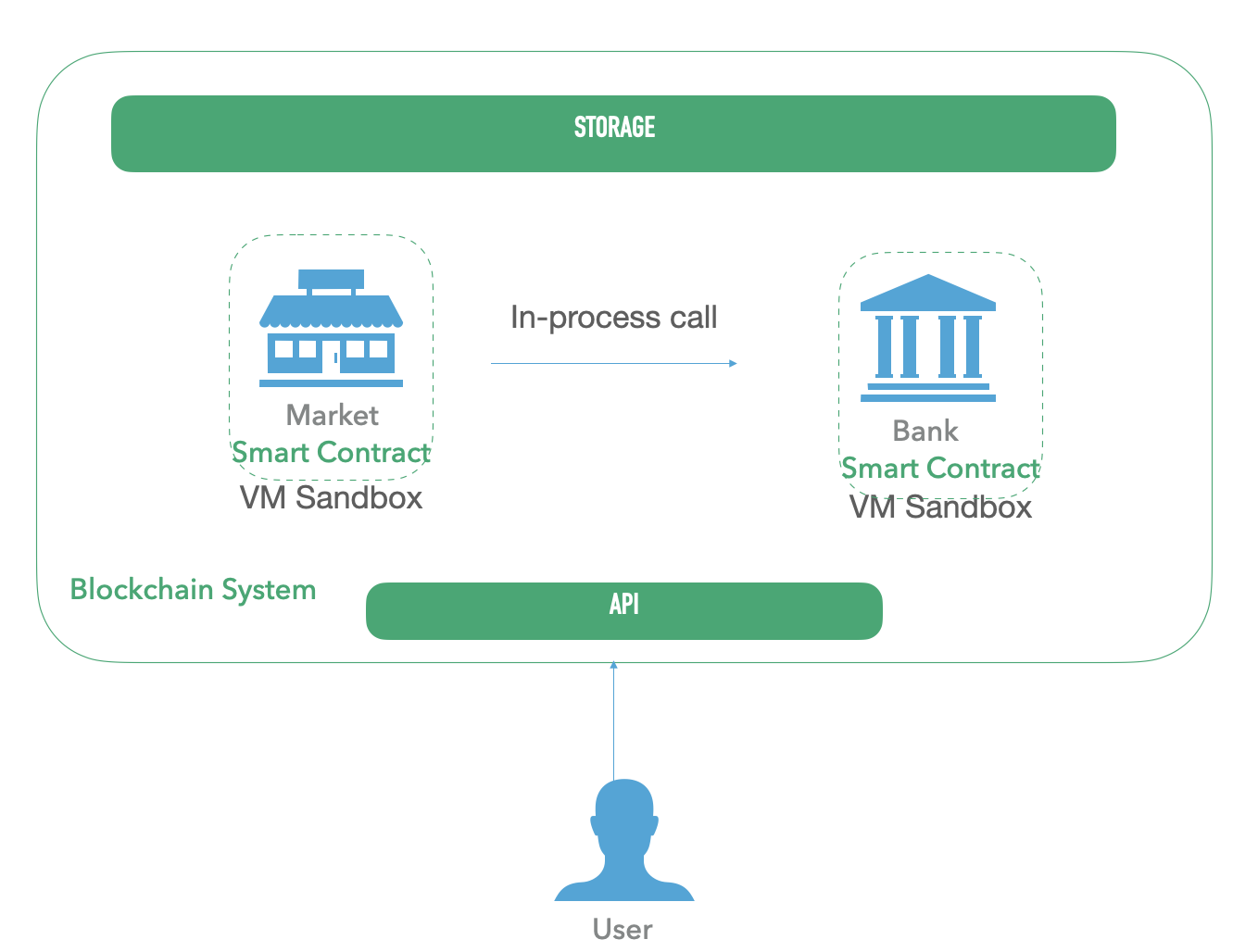
- 合约之间的调用是同一个进程内不同的智能合约虚拟机之间的调用。
- 安全依赖于智能合约虚拟机之间的隔离。
我们以 Solidity 为例子,Solidity 的合约(表明为 contract 的模块)将自己的函数声明为 public,然后其他合约就可以直接通过这个 public 方法调用该合约。以下图的一个 RPC 调用过程为例:
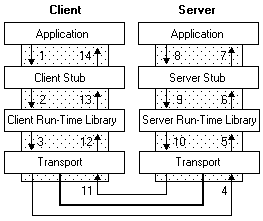
链实际上接管了上图中,Client 和 Server 之间通信的所有过程,自动生成 stub,实现序列化和反序列化,真正让开发者感觉到远程调用就像本地方法调用一样。
当然,技术并没有银弹,没有一劳永逸的方案,新的方案总带来新的难题需要解决。
智能合约的依赖难题
通过前面的分析,我们理解了智能合约之间的调用实际上是一种类似于远程调用的方法。那如果像要通过库的方式进行依赖调用呢?
在 Solidity 中,表明为 library 的模块,就相当于静态库,它必须是无状态的。对 library 的依赖会在编译期打包到最终的合约二进制中。
这样带来的问题就是如果合约复杂,依赖过多,导致编译后的合约过大,无法部署。但如果拆成多个合约,则又无法直接共享状态,内部依赖变成远程服务间的依赖,增加了调用成本。
那是不是可以走第二条动态库加载的路呢?比如 Ethereum 上的大部分合约都依赖了 SafeMath.sol 这个库,每个合约都包含了它的二进制,既然代码都在链上了,为什么不能直接共享呢?
于是 Solidity 中提供了 delegatecall 的方法,类似于动态链接库的解决方案,把另外一个合约的代码,嵌入到当前合约调用的上下文中执行,让另外一个合约直接读写当前合约的状态。但这就有两个要求:
- 调用和被调用方要是完全信任的关系。
- 两个合约的状态要对齐。
非智能合约开发者可能不太理解这个问题,如果是 Java 开发者可以这样理解:Solidity 的每个合约都相当于一个 Class,它部署后运行起来是一个单例的 Object,如果想在运行时,加载另外一个 Class 的方法来修改当前 Object 里的属性,那这两个 Class 里定义的字段必须相同,并且新加载的方法相当于一个内部方法,Object 的内部属性完全对它可见。
这样就限制了动态链接的使用场景和复用程度,现在主要用来做内部的合约升级。
因为上面的原因,Solidity 很难像其他编程语言一样提供一个丰富的标准库(stdlib),提前部署到链上由其他合约依赖,只能提供有限的几个预编译方法。
这也导致了 EVM 字节码的膨胀。很多本来可以通过 Solidity 代码从状态中获取的数据,被迫实现成了通过虚拟机指令从运行时上下文中获取。比如区块相关的信息本可以通过标准库里的系统合约从状态中获取,编程语言本身不需要知道区块相关的信息。
这个问题是所有的链和智能合约编程语言都会遇到的问题。传统编程语言并没有考虑同一个方法调用栈内的安全问题(或者说考虑的比较少),搬到链上之后,也只能通过静态依赖,和远程依赖的方式解决依赖关系,一般连类似于 Solidity 中的 delegatecall 方案都很难提供。
那我们如何才能做到在智能合约之间实现类似动态库链接的方式调用?合约之间的调用可以共享同一个方法调用栈,并且可以直接传递变量?
这样做带来两个安全性方面的挑战:
- 合约的状态的安全性要通过编程语言内部的安全性进行隔离,而不能依赖虚拟机进行隔离。
- 跨合约的变量传递需要保证安全,保证不能随意丢弃,尤其是表达资产类型的变量。
智能合约的状态隔离
前面说到,智能合约实际上是把不同组织机构的代码放在同一个进程中执行,那合约的状态(简单理解就是合约执行时生成的结果,需要保存起来供下次执行的时候使用)的隔离就是必要的了,如果直接允许一个合约读写另外一个合约的状态,肯定带来安全问题。
隔离方案理解起来其实也很简单,就是给每个合约一个独立的状态空间。执行智能合约的时候,将当前智能合约的状态空间和虚拟机绑定,这样智能合约就只能读取自己的状态了。如果要读取另外的合约,则需要前面提到的合约间的调用,实际上是在另外一个虚拟机里执行。
但如果想要通过动态库的方式进行依赖的时候,这样的隔离就不够了。因为实际上,另外一个合约是在当前合约的执行栈中运行的,我们需要基于语言层面的隔离,而不是虚拟机的隔离。
另外,基于合约的状态空间的隔离同时带来的一个问题是状态所有权的问题。这种情况下,所有的状态都属于合约,并没有区分合约的公共状态和个人的状态,给状态计费带来难题,长远来看会有状态爆炸的问题。
那如何在智能合约语言层面做状态隔离呢?思路其实也很简单,基于类型。
- 利用编程语言对类型提供的可见性的约束,这个特性大多数编程语言都支持。
- 利用编程语言对变量提供的可变性约束,许多编程语言区分引用的可变与不可变,比如 Rust。
- 提供基于类型为 Key 的外部存储,限制当前模块只能用自己定义的类型作为 Key 来读取外部存储。
- 在编程语言层面对类型提供声明
copy,drop的能力, 保证资产类的变量不可以被随意复制和丢弃。
Move 语言就是用了以上解决方案,其中第 3,4 点是 Move 特有的。这个解决方案其实也比较容易理解,如果不能在虚拟机层面给每个智能合约程序一个单独的状态空间,在合约内部做状态隔离,基于类型是比较容易理解的方式,因为类型有明确的归属和可见性。
这样在 Move 中,智能合约之间的调用变成如下图所示:
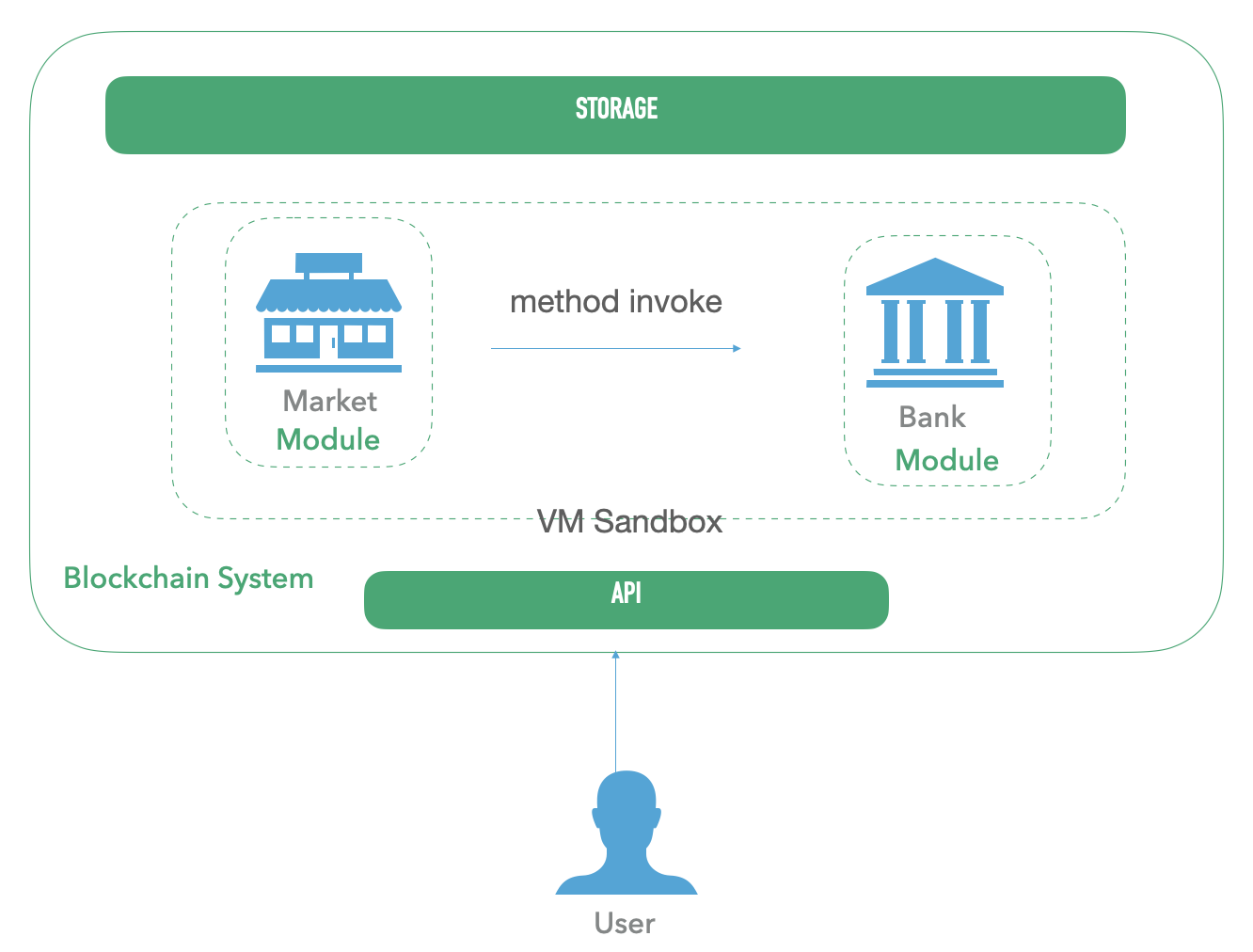
不同组织和机构的程序,通过动态库的方式,组合成同一个应用运行,共享同一个编程语言的内存世界。组织之间不仅可以传递 消息,同时可以传递 引用 ,和 资源 。组织之间的交互规则和协议,只受编程语言的规则约束。(关于 资源 的定义后文中有描述)。
这个改变同时带来几个方面的变化:
- 编程语言以及链可以提供一个功能丰富的基础库,提前部署到链上。应用直接依赖复用并不需要在自己的二进制中包含基础库部分。
- 由于不同组织之间的代码在同一个编程语言的内存世界状态里,可以提供更丰富和复杂的组合方式。这个话题在后面会详述。
Move 的这种依赖方式虽然和动态库的模式类似,但它同时利用了链的状态托管的特性,给编程语言带来了一种新的依赖模式。
这种模式下,链既是智能合约的运行环境,同时也是智能合约程序的二进制仓库。开发者通过依赖将链上的智能合约自由组合起来提供一个新的智能合约程序,并且这种依赖关系是链上可追踪的。
当然 Move 现在还很早期,这种依赖方式提供的能力尚未充分发挥出来,不过雏形以及出现。可以设想,未来肯定可以出现基于依赖关系的激励机制,以及基于这种激励模式构建出的新的开源生态。后面我们继续谈一谈可 “组合性” 的问题。
智能合约的可组合性
编程语言模块之间的可组合性是构建编程语言生态的另外一个重要特性。可以说,正因为模块之间有可组合性,才产生依赖关系,而不同的依赖方式也提供了不同的组合能力。
根据前面对依赖方式的分析,在 Solidity 生态谈论智能合约的可组合性的时候,实际上主要说的是 contract 之间的组合,而不是 library 之间的组合。而我们前面也说了, contract 之间的依赖是一种类似与远程调用的依赖,互相传递的实际上是消息,而不能是 引用 或者 资源。
这里用 资源 (resource) 这个词,主要是强调这种类型的变量在程序内不能随意的复制 (copy) 或者丢弃 (drop),这是线性类型带来的特性,这个概念在编程语言中还不普及。
线性类型来自于线性逻辑,而线性逻辑本身是为了表达经典逻辑无法表达的资源消耗类的逻辑。比如有 “牛奶”,逻辑上可以推导出 “奶酪”,但这里没办法表达资源消耗,没办法表达 X 单位的 “牛奶” 可以得出 Y 单位的 “奶酪” 这样的逻辑,所以才有了线性逻辑,编程语言里也有了线性类型。
编程语言中首先要处理资源就是内存,所以线性类型的一个应用场景就是追踪内存的使用,保证内存资源被正确的回收,比如 Rust。但如果将这个特性普遍推广,我们就可以在程序中模拟和表达任意类型的资源。
那为什么组合时能进行资源 传递非常重要呢?我们先来理解一下当前的基于 Interface 的组合方式,大多数编程语言,包括 Solidity 都是这样的组合方式。
我们要将多个模块组合起来,最关键的是约定好调用的函数以及函数的参数和返回值类型,一般叫做函数的 “签名”。我们一般用 Interface 来定义这种约束,但具体的实现由各方自己实现。
比如大家常说的 ERC20 Token,它就是一个 Interface,提供以下方法:
function balanceOf(address _owner) public view returns (uint256 balance)
function transfer(address _to, uint256 _value) public returns (bool success)
这个接口的定义中,有给某个地址转帐的方法,也有查询余额的方法,但没有直接提款(withdraw)的方法。因为在 Solidity 中,Token 是一个服务,而不是一种类型。下面是 Move 中定义的类似的方法:
module Token{
struct Token<TokenType>{
value: u128,
}
}
module Account{
withdraw(sender: &signer, amount):Token<STC>;
deposit(receiver: address, token: Token<STC>);
transfer(sender, receiver, amount);
}
可以看出,Token 是一种类型,可以从账号 withdraw 出来一个 Token 对象。有人要问,这样做有什么意义呢?
我们可以通过一种比较通俗的类比来比较二者的组合方式的区别。Token 对象类似于生活中的现金,你想去一个商场购买东西,有两种支付方式:
- 商场和银行对接好接口,接入电子支付系统,你支付的时候直接发起请求让银行划账给商场。
- 你从银行取出现金,直接在商场支付。这种情况,商场并不需要提前和银行对接接口,只要接受这种现金类型就行。至于接收现金后,商场是将现金锁在保险柜里,还是继续存到银行中,这个由商场自己解决。
而后一种组合类型,可以称做基于资源类型的组合方式,我们可以把这种在不同组织的合约之间流动的资源叫做 “自由状态”。
基于自由状态的组合方式,更像是物理世界中的组合方式。比如光碟和播放机,各种机器的配件。这种组合方式和基于接口的组合方式也并不冲突。比如多个交易所(swap)想对外提供统一的接口,方便第三方集成,则使用接口的组合方式更合适。
基于自由状态的组合的关键优势有两个:
- 可以有效的降低基于接口组合的嵌套深度,对这个感兴趣的朋友可以参看以前我一次分享中关于闪电贷的例子。考虑到有的读者对闪电贷背景不清楚,这里就不详述里。
- 可以明确的将资源的定义和基于资源的行为拆分开来,这里有一个典型的例子是灵魂绑定的 NFT。
灵魂绑定的 NFT 这个概念是 Vitalik 提出的,想用 NFT 来表达一种身份关系,而这种关系不应该是可以转让的,比如毕业证,荣誉证书等。
而 ETH 上的 NFT 标准,都是一个接口,比如 ERC721 的几个方法:
function ownerOf(uint256 _tokenId) external view returns (address);
function safeTransferFrom(address _from, address _to, uint256 _tokenId) external payable;
如果想扩展新的行为,比如绑定,就需要定义新的接口。还会影响旧的方法,比如转让 NFT 的时候,如果 NFT 已经灵魂绑定了,就无法转让,势必带来兼容性问题。更难的是开始允许转让流通,但绑定后就无法流通的场景,比如部分游戏道具。
但如果我们把 NFT 设想成一个物品,这个物品本身只决定了它如何展示,有哪些属性,至于能否转让,这个应该是上层的封装。
比如下面是用 Move 定义的 NFT,它是一种类型。
struct NFT<NFTMeta: copy + store + drop, NFTBody: store> has store {
creator: address,
id: u64,
base_meta: Metadata,
type_meta: NFTMeta,
body: NFTBody,
}
然后我们可以把上层封装设想成不同容器,不同的容器有不同的行为。比如 NFT 放在个人展览馆里的时候,是可以拿出来的,但一旦放一些特殊容器中,想要拿出来则需要有其他规则限制,这就实现了 “绑定”。
比如 Starcoin 的 NFT 标准实现了一种灵魂绑定 NFT 的容器叫做 IdentiferNFT :
/// IdentifierNFT 中包含了一个 Option 的 NFT,默认是空的,相当于一个可以容纳 NFT 的箱子
struct IdentifierNFT<NFTMeta: copy + store + drop, NFTBody: store> has key {
nft: Option<NFT<NFTMeta, NFTBody>>,
}
/// 用户通过 Accept 方法初始化一个空的 IdentifierNFT 在自己的账号下
public fun accept<NFTMeta: copy + store + drop, NFTBody: store>(sender: &signer) {
move_to(sender, IdentifierNFT<NFTMeta, NFTBody> {
nft: Option::none(),
});
}
/// 开发者通过 MintCapability 给 receiver 授予该 nft,将 nft 嵌入到 IdentifierNFT 中
public fun grant_to<NFTMeta: copy + store + drop, NFTBody: store>(_cap: &mut MintCapability<NFTMeta>, receiver: address, nft: NFT<NFTMeta, NFTBody>) acquires IdentifierNFT {
let id_nft = borrow_global_mut<IdentifierNFT<NFTMeta, NFTBody>>(receiver);
Option::fill(&mut id_nft.nft, nft);
}
/// 开发者也可以通过 BurnCapability 将 `owner` IdentifierNFT 中的 NFT 取出来
public fun revoke<NFTMeta: copy + store + drop, NFTBody: store>(_cap: &mut BurnCapability<NFTMeta>, owner: address): NFT<NFTMeta, NFTBody> acquires IdentifierNFT {
let id_nft = move_from<IdentifierNFT<NFTMeta, NFTBody>>(owner);
let IdentifierNFT { nft } = id_nft;
Option::destroy_some(nft)
}
这个箱子里的 NFT,只有 NFT 的发行方可以授予或者收回,用户自己只能决定是否接受,比如毕业证书,学校可以颁发和收回。当然开发者也可以实现其他规则的容器,但 NFT 标准是统一但。对这个具体实现感兴趣的朋友,可以参看文末链接。
这段阐述了 Move 基于线性类型带来的一种新的组合方式。当然,只有语言的特性优势并不能自然带来编程语言的生态,还必须有应用场景。我们继续来讨论 Move 语言的应用场景扩展。
智能合约的应用场景扩展
Move 最初作为 Libra 链的智能合约编程语言,设计之处就考虑到了不同的应用场景。当时 Starcoin 正好在设计中,考虑到它的特性正好符合 Starcoin 追求的目标,就将其应用在公链场景里。再后来 Libra 项目搁浅,又孵化出几个公链项目,在几个不同的方向上探索:
- MystenLabs 的 Sui 引入了不可变状态,试图在 Move 中实现类似 UTXO 的编程模型。
- Aptos 在探索 Layer1 上的交易的并行执行,以及高性能。
- Pontem 试图将 Move 带入 Polkadot 生态。
- Starcoin 在探索 Layer2 乃至 Layer3 的分层扩展模式。
同时 Meta(Facebook)的原 Move 团队在尝试将 Move 运行在 Evm 之上,虽然会损失合约之间的传递资源的特性,但有助于 Move 生态的扩展以及 Move 生态和 Solidity 生态的融合。
当前 Move 项目已经独立出来,作为一个完全社区化的编程语言。现在面临几个挑战:
- 如何在不同的链的需求之间寻找最大公约数?保证语言的通用性。
- 如何让不同的链实现自己的特殊语言扩展?
- 如何在多个链之间共享基础库和应用生态?
这几个挑战同时也是机遇,它们之间是冲突的,需要有取舍,需要在发展中寻找一种平衡,还没有一种语言做过这种尝试。这种平衡可以保证 Move 有可能探索更多的应用场景,而不仅仅是和区块链绑定。
这点上,Solidity 通过指令和链交互带来的一个问题是 Solidity&EVM 生态完全和链的绑定了,运行就需要模拟一个链的环境。这限制了 Solidity 拓展到其他场景。
关于智能合约编程语言的未来,有许多不同的看法,大体上有四种:
- 不需要图灵完备的智能合约语言,Bitcoin 的那种 script 就够用了。没有图灵完备的智能合约,就很难实现通用的仲裁能力,会局限住链的应用场景。这点可以看我以前的一篇文章《开启比特币智能合约的「三把锁」》。
- 不需要专门的智能合约语言,用已有的编程语言就够了,这个观点我们上面已经分析了。
- 需要一种图灵完备的智能合约语言,但应用场景也仅仅在链上,类似于数据库中的存储过程脚本。这是大多数当前智能合约开发者的观点。
- 智能合约编程语言会推广到其他场景,最终变为一种通用的编程语言。
最后一种可以称做智能合约语言最大化主义者,我个人持这种观点。理由也很简单,在 Web3 世界里,无论是游戏还是其他应用,如果遇到争议,需要有一种数字化的争议仲裁方案。而区块链和智能合约关键的技术点就是关于状态和计算的证明,当前这个领域摸索出来的仲裁机制,完全可以使用到更通用的场景中去。当用户安装一个应用,担心应用不安全,希望应用能提供状态和计算证明的时候,也就是应用开发必须要选择用智能合约实现应用核心逻辑的时候。
总结
这篇从链上智能合约的实现途径上,以及当前智能合约在依赖和组合性上遇到的难题,用尽可能通俗的语言阐述了 Move 在这个方向上做的尝试,以及基于这些尝试带来的生态构建的可能性。
考虑到文章也比较长了,很多方面还没表述到,我会基于这个题目写一个系列,这里做个预告:
为什么是 Move 之生态构建能力
这是本文。
为什么是 Move 之智能合约的安全
智能合约的安全是一个广泛关注的问题,布道 Move 的文章也喜欢提 “安全” 这个特性。但如何比较不同的编程语言之间的安全性?有句俗话说,你不能阻止一个人向自己的脚开枪,编程语言是一个工具,开发者用这个工具向自己的脚开枪的时候,编程语言本身能做些什么事情?智能合约让不通组织的程序运行在同一个进程中,最大化了编程语言的作用,但也带来了新的安全挑战。这篇文章将从一个整体的视角去讨论这个问题。
为什么是 Move 之状态爆炸与分层
Move 在编程语言内部实现了状态隔离,同时也给这个领域的解决方案提供了更多的可能性。合约可以更自由的处理状态的存储位置,比如将状态存储在用户自己的状态空间,这样更利于实现状态计费,激励用户释放空间。比如是否可以真正实现状态在不同的层之间的迁移,从而将 Layer1 的状态迁移到 Layer2 ,从而在根本上解决状态爆炸问题?这篇文章将探讨一些这个方向的可能性。
相关链接
- https://github.com/move-language/move Move 项目的新仓库
- awesome-move: Code and content from the Move community 一个 Move 相关项目的资源集合,包括公链以及 Move 实现的库
- Soulbound (vitalik.ca) Vitalik 关于 NFT 灵魂绑定的文章
- SIP22 NFT Starcoin 的 NFT 标准,包括 IdentifierNFT 的说明
- 开启比特币智能合约的「三把锁」(jolestar.com)
免责声明:作为区块链信息平台,本站所发布文章仅代表作者及嘉宾个人观点,与 Web3Caff 立场无关。本文内容仅用于信息分享,均不构成任何投资建议及要约,并请您遵守所在国家或地区的相关法律法规。














