

以太坊已经转向以 rollup 为中心的路线图。
原文:The Hitchhiker's Guide to Ethereum(Delphi Digital)
作者:Jon Charbonneau
编译:zCloak Network
原用标题(译后):以太坊漫游指南(上篇)
封面:William Tempest(Ethereum)
主要观点
- 以太坊是唯一一个旨在建立可扩展、并将结算和数据可 用性层统一的主要协议。
- Rollups 在利用以太坊安全性的同时扩展了计算能力。
- 所有的道路最终都通向中心化生成区块、去中心化和无需信任的区块验证以及抗审查。
- 诸如出块者-区块打包者分离和弱无状态等创新,形成了(创建和验证)权力分离,以实现在不牺牲安全性或去中心化情况下的可扩展性。
- MEV(矿工攫取的价值)现在处于核心重要位置 —— 许多设计都是为了减轻其危害和防止其中心化倾向。
- Danksharding 结合了多种前沿研究途径,为以太坊以 rollup 为中心的路线图提供所需的可扩展基础层。
- 我确实期待 Danksharding 在我们的有生之年得以实现。
目录
| 引言 |
| 第一部分:通往 Danksharding 之路 |
| 1) 原始数据分片设计——独立分片出块者 |
| 2) 数据可用性取样 |
| 3) KZG 承诺 |
| 4) KZG 承诺 vs. 欺诈证明 |
| 5) 协议内提议者-构建者分离 |
| 6) 抗审查清单(crList) |
| 7) 二维 KZG 方案 |
| 8) Danksharding |
| 9) Danksharding – 诚实多数验证 |
| 10) Danksharding – 重构 |
| 11) Danksharding – 恶意多数安全与隐私随机抽样 |
| 12) Danksharding – 主要收获 |
| 13) Danksharding – 区块链可扩展性的限制 |
| 14) Proto-danksharding (EIP-4844) |
| 15) 多维 EIP-1559 |
| Part II – 历史和状态管理 |
| 1) Calldata Gas 成本降低与总 Calldata 限制(EIP-4488) |
| 2) 在执行客户端中约束约束历史数据(EIP-4444) |
| 3) 恢复历史数据 |
| 4) 弱无状态 |
| 5) Verkle Tries |
| 6) 状态数据不可用 |
| 第三部分 – MEV |
| 1) 当前的 MEV 供应链 |
| 2) MEV-Boost |
| 3) 委员会驱动的 MEV 均匀分配 |
| 4) 单槽最终确定性 |
| 5) 单个秘密领袖选举 |
| 第四部分 – 合并:工作原理 |
| 1) 合并后的客户端 |
| 2) 合并后的共识 |
| 结束寄语 |
引言
自从 Vitalik 说今天出生的人有 50-75% 的机会活到 3000 年,而他希望能长生不老,我就对合并的时机持怀疑态度。但管他呢,让我们找点乐子,向前看看以太坊雄心勃勃的路线图吧。

这不是一篇速成文。如果你想对以太坊雄心勃勃的路线图有一个广泛而细微的了解,请给我一个小时的时间,我将为你节省几个月的工作量。
以太坊的研究有很多值得关注的地方,但所有的一切最终都会编织成一个总目标 —— 不牺牲去中心化验证的可扩展计算。
尽管在区块链中字母"C "(译者注:“中心化” 单词的首字母)是可怕的,但 Vitalik 仍在其著名的《Endgame》一文中承认,需要一些中心化来进行扩展。我们只是需要通过去中心化和无需信任的验证来控制这种中心化的权力,没有任何妥协可言。
特定的行为主体将为 L1 和基于 L1 的东西构建区块。以太坊通过简单的去中心化验证保持了令人难以置信的安全性,而 rollups 则从 L1 继承其安全性。以太坊同时提供了结算和数据可用性,以允许 rollup 扩展。这篇文章中的所有研究最终都是为了优化结算和数据可用性这两个角色,同时使得完全验证一条区块链比以往更容易。
第一部分:通往 Danksharding 之路
希望你听说过以太坊已经转向以 rollup 为中心的路线图,它不再有执行分片,而是将为需要大量数据的 rollup 进行优化。这将通过以太坊计划的数据分片或 Celestia 计划的大区块来实现。
共识层不解释分片数据,它只有一个任务,即确保数据可用性(Data Availability)。
接下来我将假设你熟悉一些基本概念,如 rollup、欺诈证明、零知识证明,以及假设你明白为什么数据可用性这么重要。
最初的数据分片设计(分片 1.0)—— 独立的出块者
该部分描述的设计已经不复存在,但仍是有价值的内容。为了简单起见,将其称为 "分片 1.0"。
64 个分片区块中的每一个都有各自独立的出块者和委员会,它们在验证者集中被轮换分配到每个分片区块,他们各自验证自己的分片数据是可用的,所以最初这依赖于每个分片验证者集中的诚实多数完整地下载数据,并不是现在使用的数据可用性抽样。
最初的设计带来了不必要的复杂性、更糟糕的用户体验和攻击方法,且在分片之间重排(轮换)验证者是非常麻烦的。
如果不引入非常紧密的同步假设,就很难保证投票将在单个时间槽内完成。信标区块(Beacon Block)的出块者需要收集所有独立委员会的投票,而这可能会有延迟。
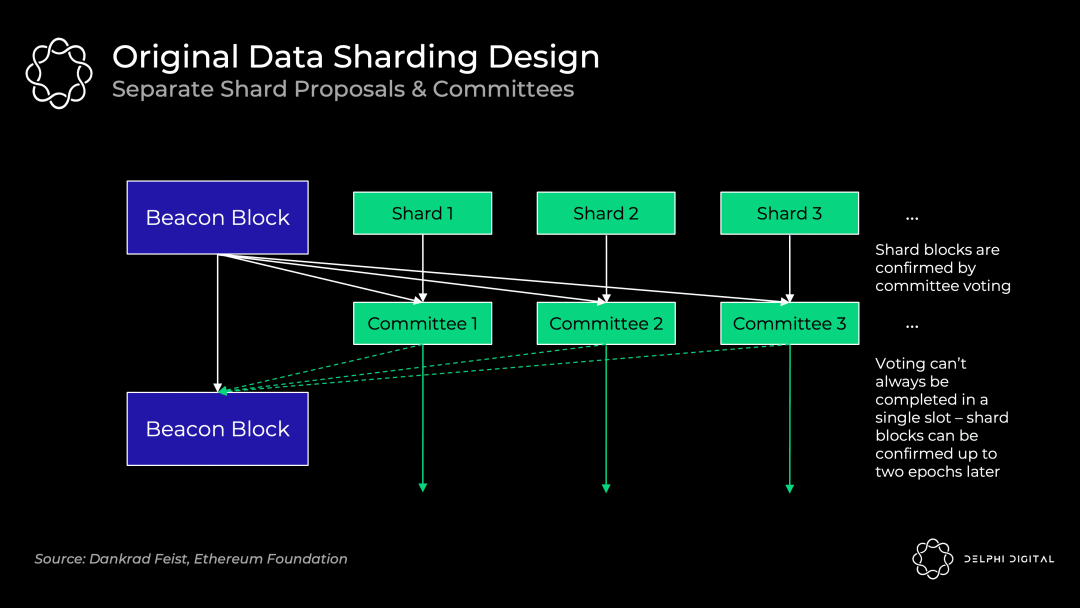
有别于分片 1.0,Danksharding 则完全不同。验证者进行数据可用性抽样以确认所有的数据都是可用的(不再有单独的分片委员会)—— 一个专用的创建者用信标区块创建一个大区块,并将所有分片数据一起确认。因此,出块者-区块打包者分离(PBS:Proposer-builder Separation)是 Danksharding 保持去中心化的必要条件(一起构建大区块会占用大量资源)。

数据可用性采样
Rollups 会发布大量的数据,但我们不希望它给节点带来下载所有数据的负担。高资源需求会损害去中心化。
然而,数据可用性采样允许节点(甚至轻客户端)在无需要下载所有这些数据的情况下,轻松、安全地验证它们都是可用的。
- 朴素的解决方案:从区块中检查出一堆随机的数据块 。如果这些块都没有什么问题,就可以签出。但是,如果你错过了将你所有的 ETH 交给 Sifu 的那笔交易呢?如此资金就不再是安全的了。
- 聪明的解决方案:先对数据进行纠删编码,使用 Reed-Solomon 代码扩展数据,即数据被插值为多项式,然后在其它的一些位置求值。这很拗口,所以让我们来解读一下。
首先上一堂简单的数学课:
多项式是任何有限数量的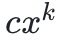 形式的项的求和表达式,其阶是最高的指数,例如
形式的项的求和表达式,其阶是最高的指数,例如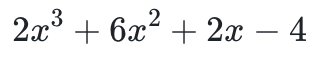 。是一个三阶的多项式。你可以基于任意包含 d +1 个坐标的多项式来重构任意的 d 阶多项式。
。是一个三阶的多项式。你可以基于任意包含 d +1 个坐标的多项式来重构任意的 d 阶多项式。
举个具体的例子:我们有四个数据块(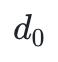 到
到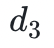 ),这些数据块可以被映射到多项式 f(X) 在给定点的值上,例如 f(0) =,现在你找到了贯穿这些值的最小阶多项式,也就是说基于这四个块我们可以得到三阶多项式。然后,我们可以通过再增加位于同一个多项式上的另外四个值(
),这些数据块可以被映射到多项式 f(X) 在给定点的值上,例如 f(0) =,现在你找到了贯穿这些值的最小阶多项式,也就是说基于这四个块我们可以得到三阶多项式。然后,我们可以通过再增加位于同一个多项式上的另外四个值(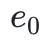 到
到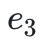 )来扩展该数据。
)来扩展该数据。

多项式的关键属性是我们可以通过任意四个点重构它,但不局限于我们最初使用的四个数据块。
现在让我们回到数据可用性抽样 —— 我们只需要确定被纠删编码的数据有任意的 50%(4/8)是可用的,如此即可重构整个区块。
正因如此,攻击者必须隐藏超过 50% 的区块才能成功地欺骗数据可用性抽样节点,使其认为数据是可用的,但实际上并不是。
在多次成功的随机采样之后,数据可用性 <50% 的概率是非常小的。如果我们成功采样被纠删编码的数据 30 次,可用性<50% 的概率是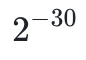
KZG 承诺
现在我们已经做了一堆数据可用性随机采样,且这些数据都是可用的。但还有一个问题 —— 数据是否被正确的纠删编码?不然有可能区块生成者在扩展区块时只是添加了 50% 的无用数据,那我们的采样就是毫无意义的。在这种情况下,我们无法重构数据。
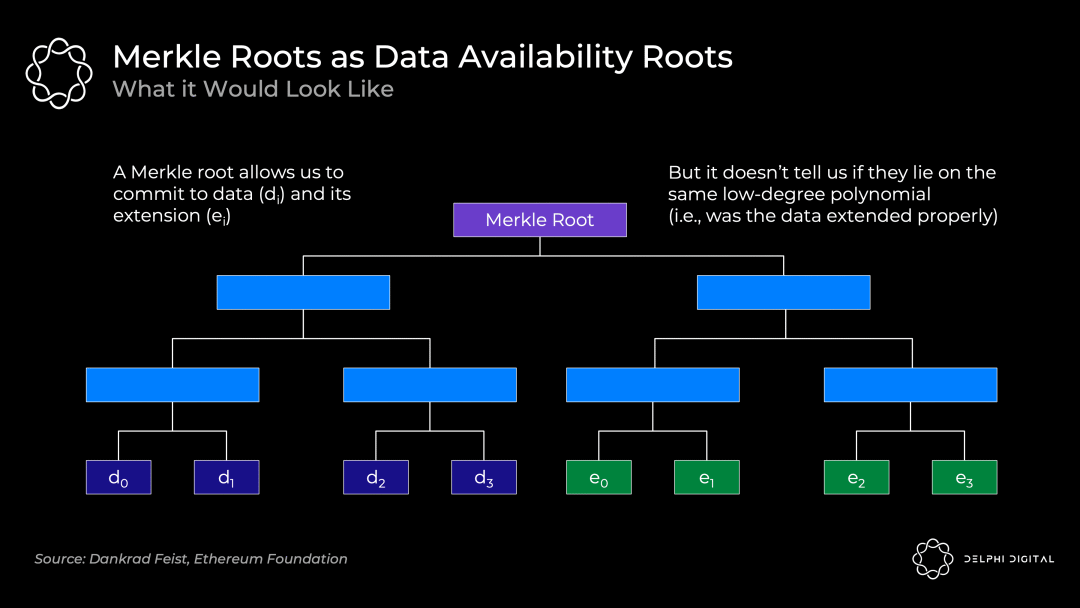
通常,我们只是通过使用 Merkle 根来承诺大量的数据,这对于证明在一个集合内包含一些数据来说是非常高效的。
但我们还需要知道的是,所有的原始数据和扩展数据都位于同一个低阶多项式上,而 Merkle 根不能证明这一点。所以如果使用 Merkle 根方案,就还需要欺诈证明,以防出现错误的验证。
开发人员正从两个方向来处理这个问题:
- Celestia 走的是欺诈证明路线。该路线需要有人观察,如果区块被错误地纠删编码,这些人会提交一个欺诈证明来提醒大家。这需要标准的诚实少数假设和同步假设(即,除了有人给我发送欺诈证明,还需要假设我是连接到网络的,并将在一个有限的时间内收到这个欺诈证明)。
- 以太坊 和 Polygon Avail 正在走一条新路线 —— KZG 承诺(也叫做 Kate 承诺),它移除了欺诈证明安全性对诚实少数和同步假设的需要。
当然也存在其它的解决方案,但它们并没有被积极的使用。例如,可以使用零知识证明,但目前在计算上零知识证明是不切实际的,然而它有望在未来几年内取得极大的改善,所以以太坊很可能会在未来转向 STARKs,因为 KZG 承诺不具备抗量子计算攻击的能力。

回到 KZG 承诺,它们是一种多项式承诺方案。
承诺方案只是一种可证明承诺某些值的加密方式。最好的比喻是把一封信放在一个上了锁的盒子里,然后把它递给别人。这封信一旦放进去就不会发生改变,但可以用钥匙打开并证明确实有这样的一封信。你对这封信作出承诺,而钥匙就是证明。
在我们的案例中,我们将所有的原始数据和扩展数据映射到一个 X,Y 网格上,然后找到贯穿它们的最小阶多项式(这个过程被称为 Lagrange 插值)。该多项式即是证明者要承诺的:

以下是主要要点:
- 我们有一个 "多项式" f(X)
- 证明者对该多项式做出 "承诺" C(f)
- 这依赖于具有可信设置的椭圆曲线密码学
- 对于这个多项式的任意 "值" y = f(z),证明者可以计算出一个 "证明" π(f,z)
- 给出承诺 C(f),证明 π(f,z),任意位置 z,以及多项式在 z 处的值 y,验证者可以证实的确 f(z)=y
- 也就是说,证明者将这些零散的信息交给任意验证者,该验证者可以证实某个点的值(代表源数据)正确地位于被承诺的多项式上
- 这就证明了原始数据被正确地扩展了,因为所有的值都位于同一个多项式上
- 注意,验证者不需要多项式 f(X)
- 重要属性 —— 有 O(1) 的承诺大小,O(1) 的证明大小 ,以及 O(1) 的验证时间 。即使对证明者来说,承诺和证明生成也只是 O(d) 的(其中 d 是多项式的阶)。
- 也就是说,即使 n(X 中值的数量)增加(即数据集随着分片 Blob 的增大而增大),承诺和证明的大小也保持不变,验证需要的工作量也是恒定的
- 承诺 C(f) 和证明 π(f,z) 都只是配对友好曲线(BL12-381)上的一个椭圆曲线元素。在这种情况下,它们各自只有 48 字节(真的很小)
- 因此,证明者承诺的大量原始和扩展数据(表示为多项式上的许多值)仍然只有 48 字节,而证明也将只有 48 字节
- 总而言之,是高度可扩展
KZG 根(一个多项式承诺)将类似于 Merkle 根(一个向量承诺):
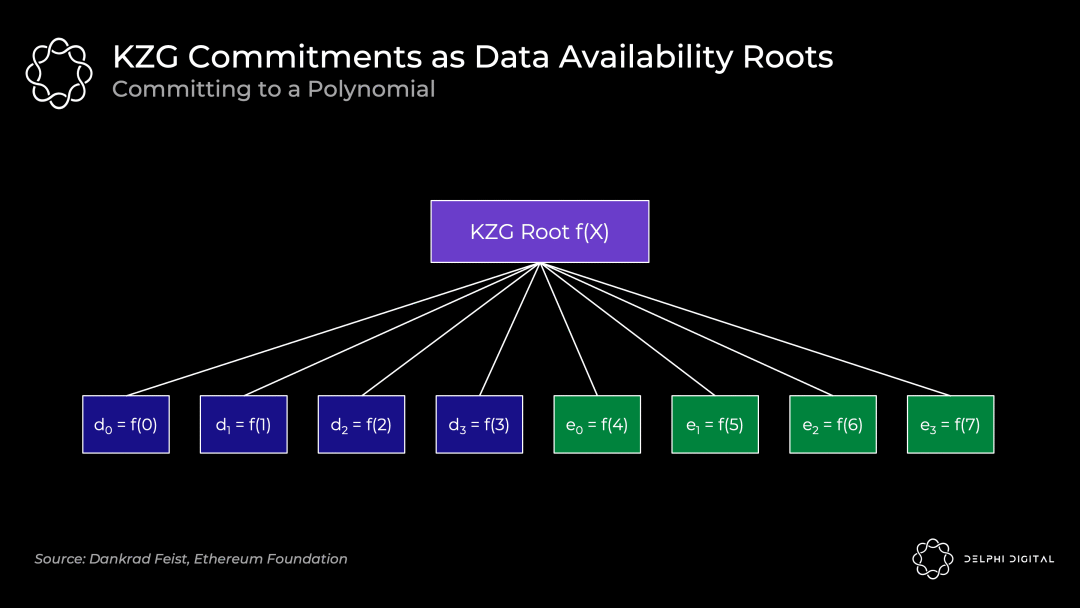
原始数据是多项式 f(X) 在 f(0) 到 f(3) 位置的值,然后我们通过在 f(4) 到 f(7) 位置计算出多项式的值以扩展它。所有的点 f(0) 到 f(7) 都保证是在同一个多项式上。
总之,数据可用性抽样允许我们检查被纠删编码的数据是可用的。KZG 承诺向我们证明了原始数据被正确地扩展,并承诺所有多项式上的数据。

好了,今天的代数就讲到这里。
KZG 承诺 vs. 欺诈证明
我们已经了解了 KZG 的工作原理,现在来比较一下这两种方法。
KZG 的缺点是它不是抗量子的,且需要一个可信设置。这些并不令人担忧,因为 STARKs 提供了一个抗量子的替代方案,而可信设置(是开放参与的)只需要一个诚实的参与者。
KZG 相较欺诈证明场景的优势是其延迟更低(GASPER 无论如何不会有快速最终确定性),而且它在没有引入欺诈证明中固有的同步假设和诚实少数假设的情况下,确保了可以适当的进行纠删编码。
然而,考虑到以太坊仍然会在区块重构中再次引入这些假设,所以实际上并没有消除这些假设带来的影响。数据可用性层,总是需要为区块最初可用但随后因节点需要相互通信而将区块重新构建起来的情况进行规划。这种重构需要两个假设:
- 有足够多的(轻或全)节点对数据进行采样,以至于它们共同拥有足够多的数据可以拼凑起来。这是一个相当弱的、不可避免的诚实少数假设,所以不是什么大问题。
- 重新引入同步假设,使节点能在一定时间内进行通信,以便将这些数据重新组合起来。
以太坊验证者在原始的 Danksharding 方案中(Proto)需要完整地下载分片二进制数据块(Blob: binary large object),而在 Danksharding 中它们只会进行数据可用性抽样(下载指定的行和列),Celestia 则要求验证者下载整个区块。
需要注意的是,在任何一种情况下重构都需要同步假设。如果区块仅部分可用,则全节点必须与其它节点进行通信以将区块拼凑出来。
如果 Celestia 想从要求验证者下载全部的数据转变为只执行数据可用性抽样(尽管这种转变目前还没有计划好),那么 KZG 的延迟优势就会显现出来。然后他们也需要实现 KZG 承诺,因为等待欺诈证明意味着将显著增加区块间隔,并且意味着验证者投票给编码错误区块的危险性将特别高。
为深入探讨 KZG 承诺的工作原理,我推荐下以下阅读内容:(见文尾链接)
- [1](相对容易理解的)椭圆曲线密码学入门
- [2] 探索椭圆曲线配对—— Vitalik
- [3] KZG 多项式承诺—— Dankrad
- [4] 可信设置是如何工作的——Vitalik
协议内出块者-区块打包者分离
出块者-区块打包者分离(PBS: Proposer-Builder Separation)
今天的共识节点(矿工)和合并后的共识节点(验证者)担任两个角色:他们构建区块,然后将区块提交给将验证区块的共识节点。矿工在前一个区块上构建以进行 "投票",合并之后,验证者将直接投票决定区块是否有效。
PBS 将这个过程拆分,它明确地创建了一个新的协议内区块打包者角色。特定的区块打包者把区块放在一起,并投标出块者(验证者)选择他们的区块。这对抗了 MEV 的中心化力量。
回顾 Vitalik 的《Endgame》—— 所有的道路都通向基于无需信任和去中心化验证的中心化区块生成。PBS 对此进行了编码。我们需要一个诚实的区块打包者来为网络的活性和抗审查服务(这两点都是为了保持一个有效的市场),验证者集需要诚实多数假设。PBS 使出块者的角色尽可能简单,以支持验证者的去中心化。
区块打包者获得优先的费用小费,并且可以提取任何 MEV。在一个有效的市场中,有竞争力的区块打包者会出价到他们能从区块中提取的全部价值(其中会减去他们的摊销成本,如强大的硬件等)。所有的这些价值都会渗透到去中心化的验证者集 —— 这正是我们想要的。
确切的 PBS 实现仍在讨论中,但双槽 PBS 可能看起来像这样:
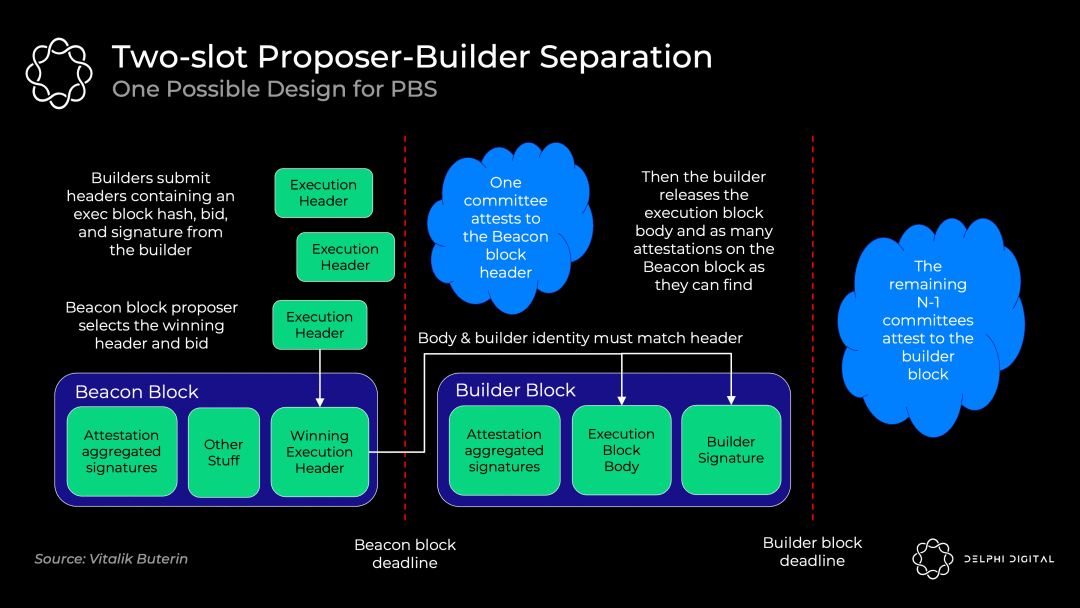
- 区块打包者对区块头和他的出价一起进行承诺
- 信标区块出块者选择获胜的区块头和投标,并将无条件得到中标费,即使区块打包者未能生成区块体。
- 证人委员会确认获胜的区块头
- 区块打包者披露获胜的区块体
- 不同的认证人委员会选出获胜的区块体(如果中标的区块打包者不出示区块体,则投票证明该区块体不存在)
使用标准 RANDAO 机制从验证人集中选出出块者,然后使用一个可以确保在区块头被委员会确认之前不会披露完整区块体的承诺-披露方案。
承诺-披露方案效率更高(发送数百个完整的区块体可能会超出 p2p 层的带宽),且还可以防止 MEV 盗取。如果区块打包者提交它们的完整区块,则另一个区块打包者可以观察到并找出策略与之合并,进而迅速发布一个更好的区块。此外复杂的出块者可以检查并复制使用的 MEV 策略,而无需补偿对区块打包者。如果这种 MEV 盗取行为成为一种均衡,那么它将激励区块打包者和出块者合并。这就是为什么我们要用承诺-披露方案来避免这种情况。
在出块者选择了获胜的区块头后,委员会对其进行确认,并将其固定在在分岔选择规则中。然后获胜的区块打包者会公布它们获胜了的完整的 "区块打包者区块" 体。如若公布即及时,下一届委员会将会对该 "区块打包者区块" 体进行认证;如若公布不及时,区块打包者仍需向出块者支付全额标价(并失去了所有的 MEV 和费用)。这种无条件的支付不再需要出块者信任区块打包者。
延时是这种 "双槽" 设计的缺点。合并后的区块将有一个固定的 12 秒,所以如果我们在这里不想引入任何新的假设,那么我就需要一个 24 秒的完整区块时间(两个 12 秒的插槽)。每槽 8 秒(16 秒区块时间)似乎是一个安全的妥协,不过研究正在进行中。
抗审查清单(crList)
不幸的是,PBS 增强了区块打包者审查交易的能力。也许区块打包者只是不喜欢你,所以他们忽略你的交易;也许他们的工作能力很强,以至于其它打包者都放弃工作了;也可能他们会对区块漫天要价,只是因为真的很不喜欢你。

抗审查清单对以上这些权力进行检查。具体的实现方式仍然是一个开放的设计空间,不过 "混合 PBS "似乎是最受欢迎的,即出块者指定一个它们在存储池中看到的所有符合条件的交易列表,区块打包者将强制包含它们(除非区块已满):
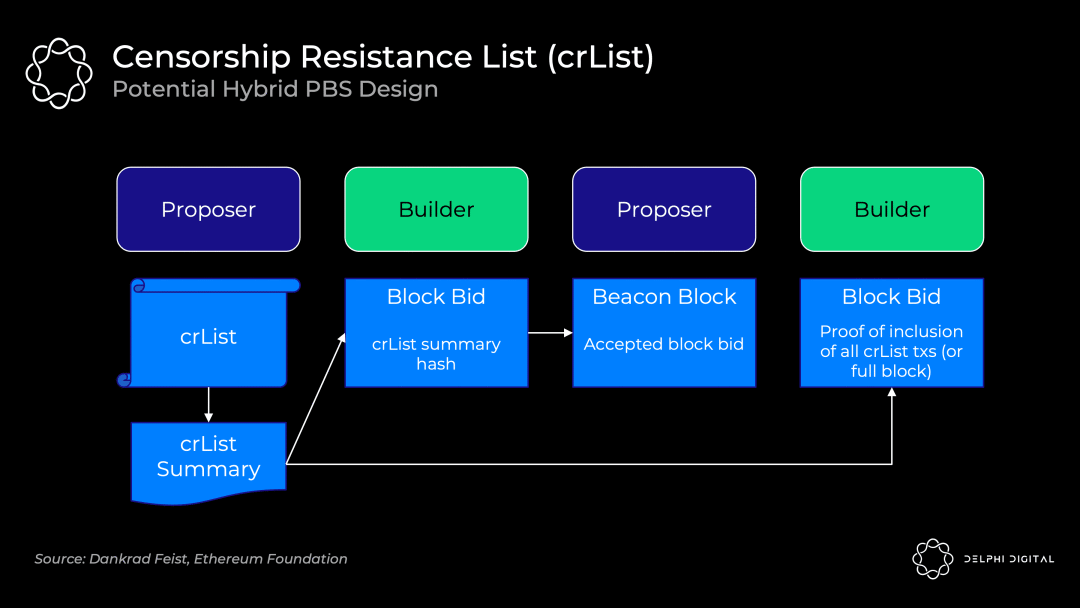
- 出块者发布一个抗审查清单和包含所有符合条件的交易的抗审查清单摘要
- 区块打包者创建一个被提议了的区块体,然后提交投标,其中包括抗审查清单摘要的哈希,以证明他们已看到该提议区块体
- 出块者接受获胜区块打包者的出价和区块头(此时出块者还没有看到区块体)
- 区块打包者发布他们的区块和一个可以证明他们已经包含了抗审查清单中所有交易或区块已经满了的证明,否则该区块不会被分岔选择规则接受
- 认证者检查所发布的区块体的有效性
这里仍然有一些重要的问题需要理清楚,例如基于这种情况的主流经济策略是出块者提交一个空名单,这样一来,只要谁出价最高谁就能获胜,即使是审查创建者也能赢得竞标。有一些想法可以解决这个问题和其它一些问题,但在这里只是强调设计并不是一成不变的。
二维 KZG 方案
我们已经知道了 KZG 承诺是如何让我们承诺数据并证明它是被正确地扩展的,然而我简化了以太坊实际要做的事情:一个区块将使用许多 KZG 承诺,因为无法在一个单一的 KZG 承诺中承诺所有数据。
我们已经有专用的区块打包者,那么为什么不能直接让它们创建一个巨大的 KZG 承诺呢?因为这需要一个强大的超级节点来进行重构。我们可以接受初始构建阶段的超级节点需求,但我们需要避免重构时的假设。我们需要更低的资源实体处理重构,而将这些重构拆分成许多 KZG 承诺是使之可行的。重构甚至可能是相当常见的,或者说在该给定数据量的设计中,重构就是该设计中的基本情况假设。
为了使重构更容易,每个区块将包括编码到 m 个 KZG 承诺中的 m 个分片 blob 。虽然这样做会导致大量的采样,即你会在每个分片 blob 上执行数据可用性采样,以知道它都是可用的(在 m*k 样本中,k 是每个 blob 的样本数)。
但以太坊将使用二维 KZG 方案,即再次使用 Reed-Solomon 编码将 m 个承诺扩展到 2m 个承诺:

我们通过在和 0-255 同样的多项式之上再添加额外的 KZG 承诺(这里是 256-511)来使其成为一个二维方案。现在我们只需在上面的表格上中执行数据可用性抽样,以确保所有跨分片数据可用。
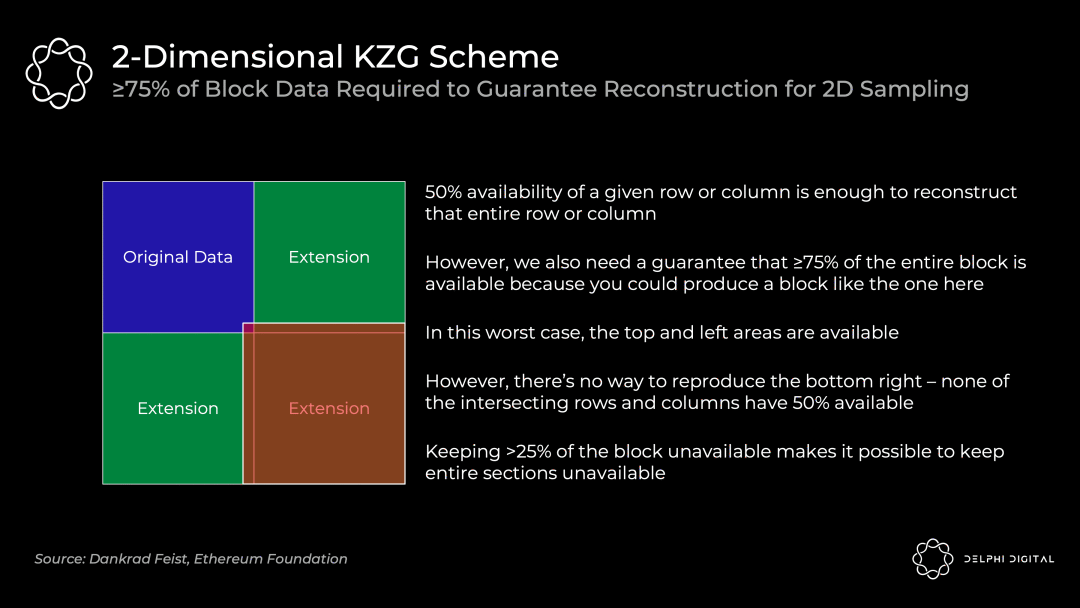
二维抽样要求 ≥75% 的数据是可用的(不是之前的 50%),这意味着需要更多的固定抽样。在前文中有提到,在一个简单的一维方案中需要 30 个数据可用性抽样的样本,但在二维方案中将需要 75 个样本才能确保重构一个可用区块的概率相同。
分片 1.0(有一个一维 KZG 承诺方案)只需要 30 个样本,但如果你想检查所有 1920 个样本的全部数据可用性,你需要对 64 个分片进行采样,每个样本是 512 B,所以这就需要。
(512 B x 64 个分片 x 30 个样本) / 16 秒 = 60 KB/s 带宽
在现实中,验证者是被轮换的,不会逐一检查所有的分片。现在,与二维 KZG 承诺方案相结合的区块使检查全部数据可用性变得轻而易举,只需要一个统一区块的 75 个采样样本:
(512 B x 1 个区块 x 75 个样本) / 16 秒 = 2.5 KB/s 宽带
(因本文篇幅过长,后续详见中、下篇)
免责声明:作为区块链信息平台,本站所发布文章仅代表作者及嘉宾个人观点,与 Web3Caff 立场无关。本文内容仅用于信息分享,均不构成任何投资建议及要约,并请您遵守所在国家或地区的相关法律法规。











