

加密領域開發一定會出現一種更加便捷和原生的鏈上數據處理體系,或許 shadow 能夠給我們帶來對未來數據基建的驚鴻一瞥。
作者:Masterdai
未來闖入我們之間,為了能在它發生之前很久就先行改變我們。 —里爾克
引言
自從 Dune Analytics 於 2018 年在挪威奧斯陸成立以來,已經過去了整整六年。 在這六年的時間里,Dune Analytics 從一個僅有 18 人的小公司,成長為估值超過 10 億美元的加密獨角獸。 它的業務也從最初僅為分析師提供數據分析圖表,擴展到向開發者提供數據服務,並成功實現盈利。
不只是 Dune Analytics,隨著越來越多的開發者加入加密行業,鏈上專案的業務邏輯也變得日益複雜。 這種複雜性也推動了對數據基礎設施的需求,通過一張圖表,我們可以直觀地看到這一點:

根據 PrimoData 的數據統計(https://www.primodata.org/blockchain-data-landscape),截至 2024 年,僅「鏈上數據」這一類別就涵蓋了 58 個專案方。 毫無疑問,這些專案大多採用了類似雲數據倉庫的架構。 我之前曾撰寫過一篇介紹這類架構的原理及其優劣勢的文章,在這裡就不再贅述。
值得一提的是,當我兩年前撰寫這些架構原理時,並沒有預見到區塊鏈行業將發生的一些翻天覆地的變化。 在我看來,這些變化可能會使得一些專案從破壞性創新的角度顛覆整個行業,例如圖表中的 Shadow 和 Ghostlog。
變化與挑戰
區塊鏈開發的技術門檻正在降低,這得益於二層網路技術的成熟、模組化區塊鏈的引入,以及像 Optimism 等生態相關代碼的開源。 這些變化顯著加速了新公鏈的誕生,但也帶來了多鏈環境下的額外存儲和解析成本。 隨著用戶數量增加和鏈上活動頻繁,鏈上數據的解析速度常常跟不上新鏈的開發速度。
智慧合約的複雜度也在增加,特別是新的開發框架如 Mud 和 Dojo,這些專門為全鏈遊戲開發設計的框架使得智慧合約複雜度遠超傳統的 DeFi 合約。 新的 DeFi 應用和其他應用需要設計更複雜的合約邏輯,而一旦合約變得複雜,傳統的數據解析方式就會變得緩慢或失效。 儘管 Subgraph 曾是合約數據解析的佼佼者,但在處理這些複雜合約時,即便結合其他 API 使用,也顯得力不從心。 使用者的快速增加帶來了數據量的爆炸性增長,使得數據變得更加複雜和多樣化。
這些技術進步和市場的變化不僅對鏈上數據基建項目帶來了直接挑戰,也對加密開發的兩類關鍵人員產生了負面干擾。
第一類是加密數據基礎設施公司雇傭的後端工程師。 在獲取 DeFi 數據的過程中,這些工程師需要花費大量時間來理解和處理智能合約。 由於缺乏行業內的統一標準,他們在理解 Solidity 的基礎上,花費了約 90% 的時間,剩下的時間才用於數據的部署和清洗。 這導致即使是完成同樣的任務,不同公司的工程師處理出的數據格式也各不相同,比如 A 公司和 B 公司就可能有不同的數據輸出格式。
第二類是使用這些數據的下游開發者,他們常常需要同時調用多個公司的 API。 由於每個公司提供的數據格式不統一,這增加了下游開發者的工作量,因為他們不得不在開發過程中處理各種不一致的數據格式,這不僅增加了開發的複雜性,還可能影響到最終應用的性能和可靠性。
對於數據基建專案方而言,他們面臨著兩方面的壓力。 在供給端,隨著鏈上數據量的爆炸性增長,雲數據倉庫的成本也在不斷上升。 而在需求端,伴隨著開發者、存量付費使用者以及公鏈商務相關人員的不斷呼籲,迫使專案方不得不採納一些並不重要的公鏈和更加複雜的數據格式。 進一步增加自己運維和服務端端壓力。
正因如此,數據基建專案方的處境可以比喻為溫水中的青蛙,逐漸適應不斷惡化的環境,卻未必察覺到逼近的危機。 未來,隨著新需求帶來的收益無法覆蓋不斷增加的雲服務成本,這些專案可能會陷入資源耗竭的困境。 這種持續的資源消耗戰可能導致資金雄厚的公司以慘烈的方式贏得市場,而資源較少的公司則有可能淪為競爭中的犧牲品
如此背景下,我們不禁要問:現有的數據基礎設施是否足以應對這些挑戰?或者,我們是否需要一種全新的思路和方法來應對這些變化?
破局
換言之,隨著區塊鏈應用的增多和數據量的激增,傳統的區塊鏈基礎設施已經顯得捉襟見肘。 開發者正尋求一種更高效、成本更低的解決方案來處理這些問題。 此時,Shadow Fork 影子分叉技術應運而生,提供了一個創新的出路。
Shadow Fork 是一種允許開發者在不影響主鏈的情況下,創建和測試新的區塊鏈協定或改動的技術。 這種方法可以看作是一個沙盒環境,它類比主鏈的當前狀態,允許開發者在一個封閉和控制的環境中進行實驗和驗證。
有意思的是,早期的 Shadow Fork 技術並非被設計用來索引鏈上數據。 相反,它首先被視為一種工具,使開發者能在一個類比的環境中自由創造事件和進行合約調試。 在這個虛擬的「沙盒」中,開發者不需要擔心合約的長度限制,可以自由地測試和修改代碼。 這種使用方式極大地節省了將功能部署到主網時調用產生的 gas 費用。 然而,隨著時間的推移,開發者發現這種模擬環境不僅適用於測試和開發,它也能夠有效地用作獲取和分析鏈上數據的平臺。
Shadow Fork 技術解析
想像一下,在不久的將來,醫學技術經歷了巨大的飛躍,納米機器人的發明被廣泛應用於監測人體的各種生命體征,如血糖和激素水準。 然而,這項技術面臨一個挑戰:它無法獲取納米機器人發明之前人們的醫療數據。 這意味著對於那些在納米技術尚未出現時就已經活躍的病人,現代醫療技術無法提供有效的診斷。
在這種情況下,一個具有前瞻性的年輕駭客提出了一個解決方案。 他通過大數據類比技術,重現了一個病人從出生至今的生活歷程,創建了一個與現實生活完全一致的虛擬環境。 在這個環境中,納米機器人可以被植入類比出的嬰兒狀態的病人體內,並隨著虛擬環境中時間的加速,直到與現實世界同步。 這一過程使得醫生能夠獲得病人完整的生命歷程數據,為診斷和治療提供了前所未有的深度和準確性。
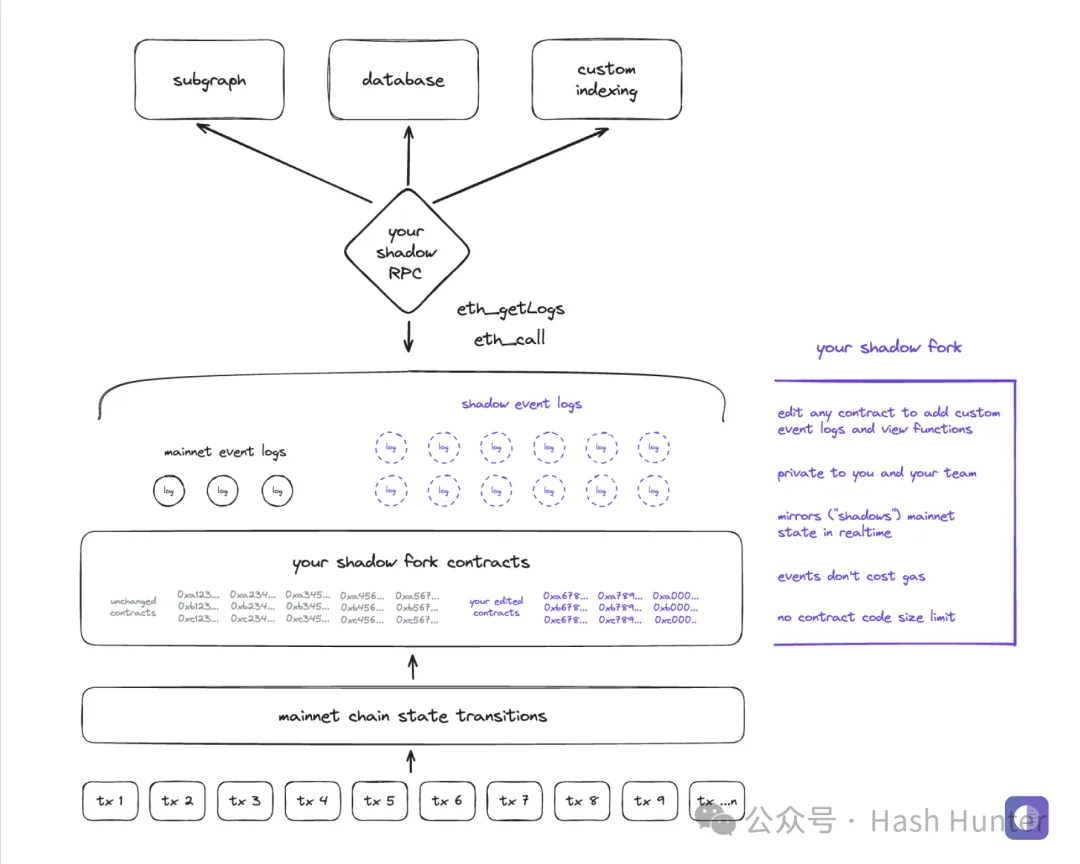
而 Shadow Fork 就是區塊鏈版本的虛擬環境。 與其他 data infra 通過構建雲數倉來存儲數據不同的是,shadow 實際上是重新魔改了乙太坊的節點代碼,並且將過去所有主網上的信息拷貝了下來。 通過將修改過的節點重新的部署到自己的私有環境,通過將歷史數據重放。 實現了影子分叉的功能,換句話說,影子分叉里的歷史合約和所有的使用者交易數據都是永遠和主網保持一致的,相當於主網路的平行世界,在 shadow fork 環境中,開發者不僅能訪問並修改過去部署的合約,還可以利用 shadow contract 進一步擴展和優化這些合約。
Shadow contract 是一種特殊的智能合約,其核心功能是允許開發者在不影響公鏈合約安全性和穩定性的前提下,增加新的事件和功能。 這種合約在 shadow fork 上運行,可以自由地添加或修改代碼,而不受主網智慧合約大小限制的約束。 這為開發者提供了前所未有的靈活性,使他們能夠實驗和部署新功能,而無需擔心影響現有用戶的體驗或合約的執行效率。
例如,如果一個開發者想要在已部署的合約中增加一個新的觀察功能或自定義事件,他可以在 shadow fork 上對該合約進行修改,創建一個 shadow contract,然後在這個新的合約版本中實現所需的功能。 這個過程不僅不會消耗任何 gas 費用,而且可以隨時更新和反覆運算,極大地增強了合約的可維護性和可擴充性。
同時,shadow event 是 shadow contract 的一個重要組成部分,它允許開發者定義特定的事件日誌,這些日誌僅存在於 shadow contract 中。 這意味著開發者可以創建用於特定分析、索引或測試目的的定製事件,而無需擔心這些操作會增加公鏈上的交易成本或數據存儲負擔。
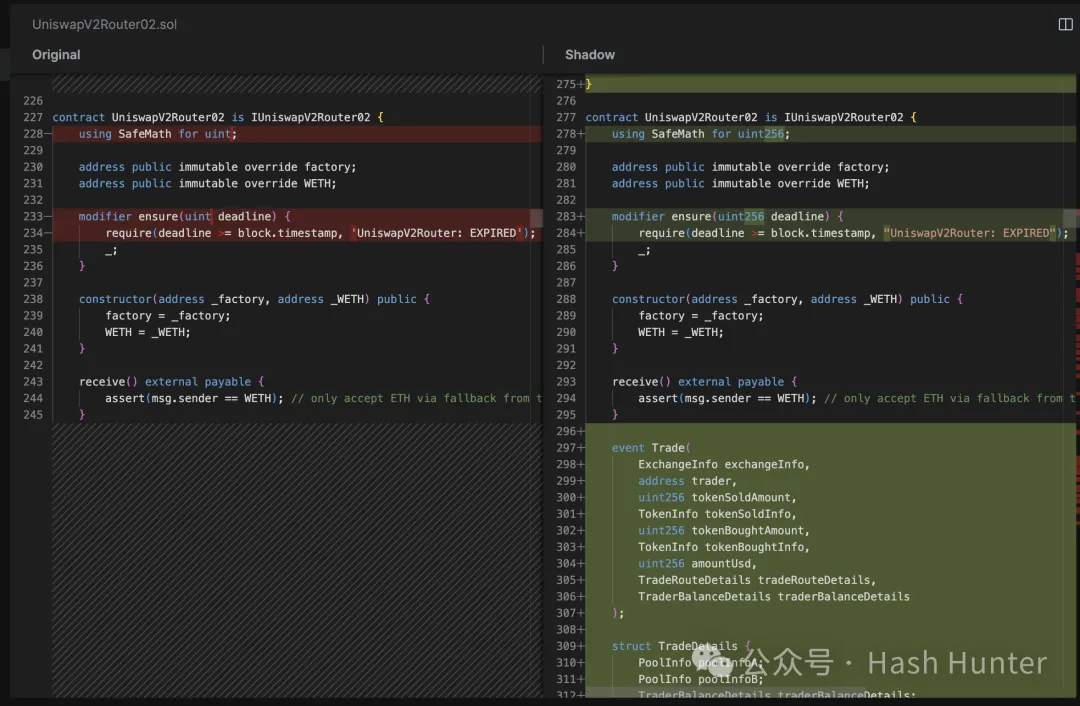
如上圖所示。 在左邊的代碼中,我們看不到任何有關 Trade 事件的定義,這表明它是原始的、在主網上的 uniswap v2 的合約代碼。 然而,在右邊的「Shadow」版本中,我們可以看到一個新增的『Trade』事件,這個事件在合約中被定義,當交易發生時被觸發。 也就是說當主網上出現一筆新交易時,這筆交易就會變重放到 shadow fork 環境中,並且以定製化的版本再跑一次從而溢出你想要的資訊。
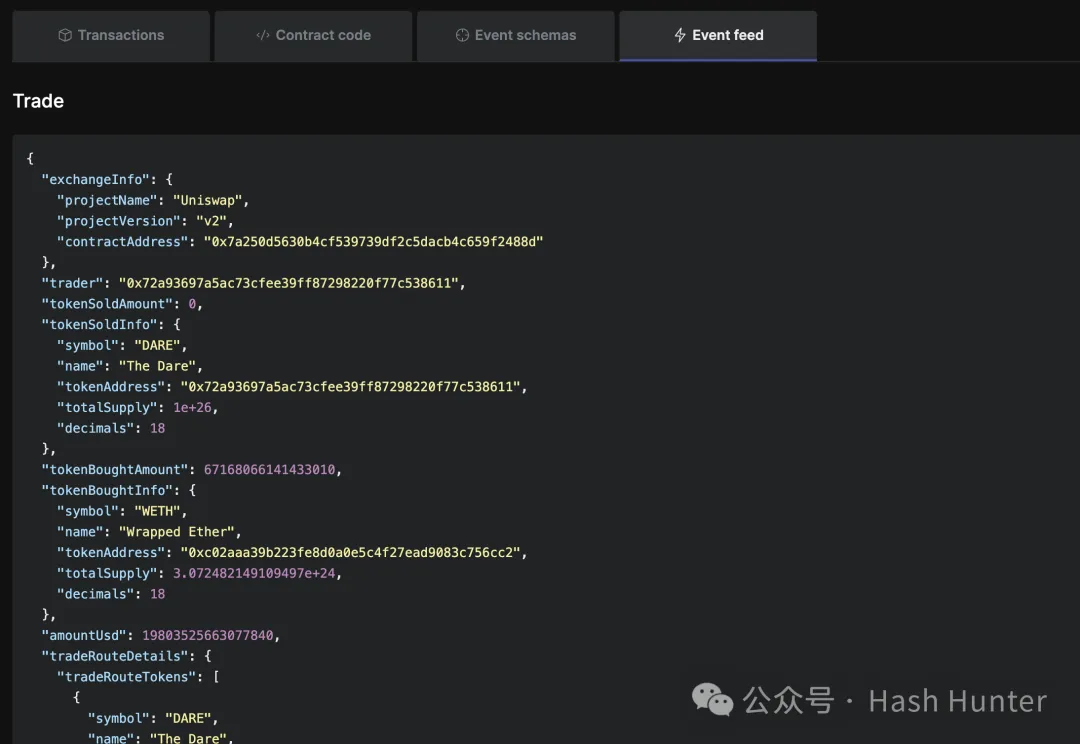
從這段數據返回中我們可以看到。 'Trade' 事件記錄了交易相關的一系列參數,如 'exchangeInfo'、'trader'、'tokenSoldAmount'、'tokenBoughtAmount' 等等。 這些參數提供了交易的詳細資訊,包括交易者位址、賣出和買入的代幣數量及其相應的資訊。
通過這些詳細數據,開發者可以監控交易活動,並進行複雜的數據分析和索引,這在傳統的公鏈合約中可能需要昂貴的 gas 費用和複雜的數據管道來實現。
對現有基礎設施的顛覆
在傳統領域中,開發者主要通過兩種管道獲取鏈上數據:一種是直接從公共或自建節點請求實時數據,如區塊高度和特定地址的餘額; 另一種是通過第三方數據供應商獲取處理過的歷史數據,如位址聚合持倉或特定交易的 MEV 情況。 儘管這些方法被廣泛採用,但在實際操作中,開發者常常面臨效率低下和使用不便的問題。
如某個加密社區分析師所說
– 數據團隊已經厭倦了處理數十個 rollup RPC。 沒人想再處理更多的 RPC。
– 我們大部分時間都在跨協定連接數據。 僅僅關聯 Compound 和 Aave 的標準版本就已經夠難的,我不想不得不在 “supply()” 事件的數十個變體之間切換。
這些問題突顯了現有基礎設施在處理鏈上數據時的局限性。 用戶實際需要的是易於理解的交易和活動數據,而不僅僅是一連串的原始數據。
但是對於 shadow 消費者來說,只需要在 shadow fork 裡面修改合約代碼並且將交易重放即可。 而這樣的數據甚至可能會比原有數據管道的方式更加的精準和方便。 同理,當使用者需要全量的歷史數據查詢時,例如我需要這一個交易對從近兩年的所有交易時,也可以通過這種重放的方式來完成。 並且由於這是一種私人的節點網路,他也不會受到公共存檔節點的限速限制。
未來的展望
那麼,我們是否可以將 Shadow 視為對現有加密數據基礎設施的挑戰者乃至顛覆者呢?在我看來,這並不僅僅是因為其技術的先進性或宏大的敘述,而是這個產品是否真正滿足了開發者和數據分析者的需求,並且利用新的技術和方式使得原有的摩擦成本降到最低。 defi 就是一個成功的創新他極大程度的降低了傳統金融的交易摩擦。 使得其成為帕累托最優解。
當前,大量的尾端數據仍然未被有效利用,而大部分數據基建正是圍繞這些顯而易見的數據展開。 這種情況不僅給開發者帶來了不必要的數據適配負擔,還增加了冗餘的 API 調用。 這種現狀與過去互聯網的發展歷程頗有相似之處:就如同搜尋引擎系統取代黃頁一樣,人們厭倦了在龐大的數據頁中尋找所需資訊,而更傾向於使用定製的演算法來解決問題。
如果從今天的角度來看,我們現有的數據基礎設施是否也正變成了一個龐大的「數字黃頁」呢?
在加密數據領域,data warehouse 這種模式本質上並非 crypto-native 的創新,歸根結底,它是過去大數據團隊對現有加密數據業務的拙劣模仿和遷移。 與其說是面向開發者,不如說是向風險投資者的一種敘事框架轉移。 而從 shadow 這一種專而從節點網路進行優化和改造的路徑,看上去卻更像是加密原生的做法。
隨著未來 shadow fork 的開源和更多這一類項目的出現,加密領域開發一定會出現一種更加便捷和原生的鏈上數據處理體系,或許 shadow 能夠給我們帶來對未來數據基建的驚鴻一瞥。
免責聲明:作為區塊鏈資訊平臺,本站所發佈文章僅代表作者及嘉賓個人觀點,與 Web3Caff 立場無關。 文章內的資訊僅供參考,均不構成任何投資建議及要約,並請您遵守所在國家或地區的相關法律法規。










