此文包含 B^2 Network 官方文檔未披露的內容,趕緊來先睹為快吧
作者:Faust,極客 Web3
封面:Photo by Shubham Dhage on Unsplash
摘要:· B^2 Network 在比特幣鏈下設置了名為 B^2 Hub 的 DA 層,該 DA 層網络借鑒了 Celestia 的思路,引入數據採樣與糾刪碼,確保新增數據可以快速的分發給大量的外部節點,並極力避免數據扣留的發生。 同時,B^2 Hub 網路中的 Committer 會把 DA 數據的存儲索引以及數據 hash 上傳到比特幣鏈上,供任何人讀取;
· 為了減輕 DA 層節點的壓力,B^2 Hub 中的歷史數據不會永久保存,所以 B^2 又嘗試搭建起一個存儲網络,通過類似於 Arweave 的存儲激勵方式,刺激更多節點存儲更完備的歷史數據集,以獲取存儲激勵;
· 在狀態驗證方面,B^2 採用了混合式的驗證方案,在鏈下驗證 ZK 證明,鏈上通過 bitVM 的思路,挑戰 ZK 證明驗證痕跡,只要有 1 個挑戰者節點在檢測到錯誤后發起挑戰,B^2 網路就是安全的,這符合欺詐證明協定的信任模型,但由於用到了 ZK,這種狀態驗證實際上是混合型的。
·按照 B^2 Network 的未來路線圖,EVM 相容的 B^2 Hub 可以成為對接多個比特幣 Layer2 的鏈下驗證層與 DA 層,成為一個類似於 BTCKB 的比特幣鏈下功能拓展層。 由於比特幣本身無法支援很多場景,這種鏈下搭建功能拓展層的方式將會成為 Layer2 生態裡越來越常態化的現象。
B^2 Hub:比特幣鏈下的通用 DA 層與驗證層
如今的比特幣生態可謂是一片機會與騙局共存的藍海,這個因銘文之夏而煥發生機的全新領域簡直是一片肥沃的處女地,到處都瀰漫著金錢的氣息。 隨著今年 1 月比特幣 Layer2 如雨後春筍般集體湧現,這片原本如荒蕪原野的土地瞬間就成為了無數造夢者的搖籃。
但回歸到最本質的問題:什麼是 Layer2,人們似乎始終沒有達成共識。 側鏈是嗎? 索引器是嗎? 搭個橋的鏈就叫 Layer2 嗎? 一個依賴於比特幣和乙太坊的簡易外掛程式,可不可以當做一個 Layer? 這些問題就像一組難解的方程式,始終都沒有一個確切的結局。
而按照乙太坊和 Celestia 社區的思路,Layer2 只是模塊化區塊鏈的特殊情況,在這種情況下,所謂的「二層」與「一層」之間會存在緊密的耦合關係,二層網路可以很大程度,或一定程度繼承 Layer1 的安全性。 至於安全性這個概念本身,可以拆解為細分的多個指標,包括:DA、狀態驗證、提款驗證、抗審查性、抗重組等。
由於比特幣網路本身存在諸多問題,其天生不利於支援較完備的 Layer2 網路。 比如在 DA 上,比特幣的數據輸送量遠低於乙太坊,以其平均 10min 的出塊時間來計算,比特幣最大的數據輸送量僅為 6.8KB/s,差不多是以太坊的 1/20,如此擁擠的區塊空間自然而然造就了高昂的數據發佈成本。
如果 Layer2 直接把新增的交易數據發佈到比特幣區塊里,既不能實現高輸送量,也不能實現低手續費。 所以要麼就通過高度壓縮,把數據尺寸壓縮的盡可能小,再上傳到比特幣區塊。 目前 Citrea 採用了這種方案,它們聲稱,將把一段時間內的狀態變化量(state diff),也就是多個帳戶上發生的狀態變更結果,連同對應的 ZK 證明,一起上傳到比特幣鏈上。
這種情況下,任何人都可以從比特幣主網下載 state diff 和 ZKP,驗證其是否有效,但上鏈的數據尺寸卻可以輕量化。
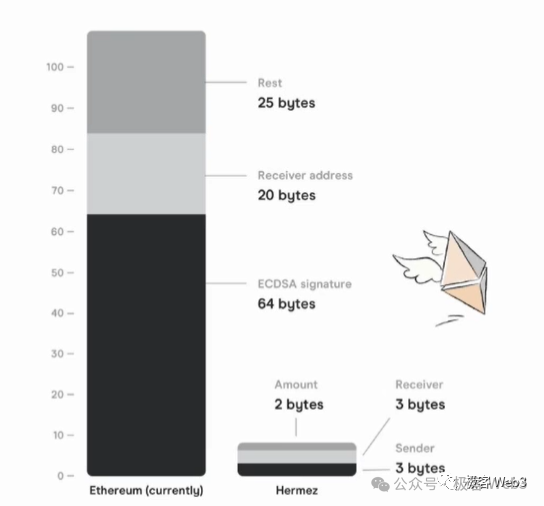
這種方案在極大程度壓縮了數據尺寸的同時,最終還是容易遇到瓶頸。 比如,假設在 10 分鐘內發生了幾萬筆交易,使得上萬個帳戶發生了狀態變更,你最終還是要把這些帳戶的變化情況,匯總上傳到比特幣鏈上。 雖然比起直接上傳每筆交易數據,要輕量很多,但還是會產生很可觀的數據發佈成本。
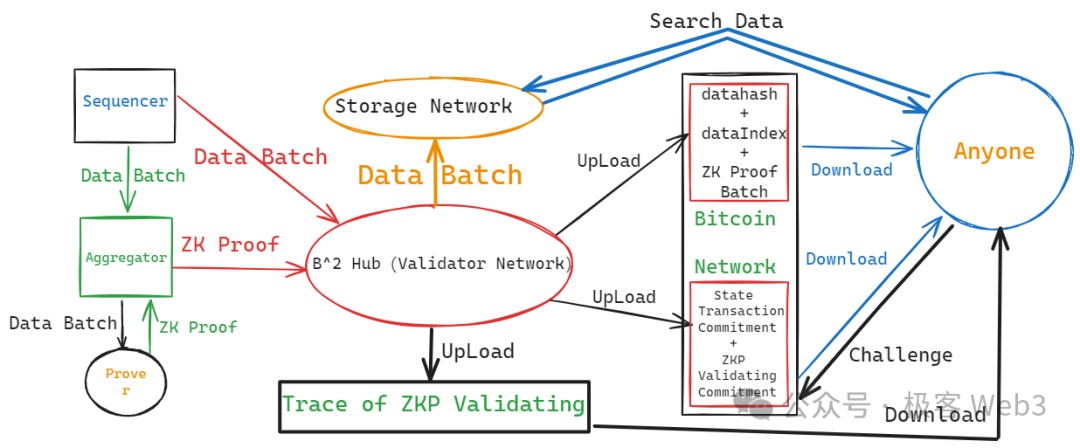
所以很多比特幣 Layer2 乾脆就不把 DA 數據上傳到比特幣主網,直接採用 Celestia 等第三方 DA 層。 而 B^2 採用了另一種方式,直接在鏈下搭建一個 DA 網路(數據分發網路),名為 B^2 Hub。 在 B^2 的協議設計中,交易數據或 state diff 等重要數據存放於鏈下,只向比特幣主網上傳這些數據的存儲索引,以及數據 hash(其實是 merkle root,為了表述方便說成數據 hash)。
這些數據 hash 和儲存索引,以類似銘文的方式寫入到比特幣鏈上,只要你運行一個比特幣節點,就可以把數據 hash 和存儲索引下載到本地,根據索引值,能從 B^2 的鏈下 DA 層或儲存層中,讀取到原始數據。 根據數據 hash,你可以判斷,自己從鏈下 DA 層獲取的數據是否正確(能否和比特幣鏈上的數據 hash 相對應)。 通過這種簡單的方式,Layer2 可以避免在 DA 問題上過度依賴比特幣主網,節約手續費成本並實現高輸送量。

當然,有一點不可忽視,就是這種鏈下的第三方 DA 平臺有可能搞數據扣留,拒絕讓外界獲取到新增的數據,這種場景有一個專用術語,叫 “數據扣留攻擊”,可以歸納為數據分發中的抗審查問題。 不同的 DA 方案有不同的解決辦法,但核心宗旨,都是要把數據盡可能快、盡可能廣泛的傳播出去,防止一小撮特權節點控制著數據獲取許可權不放。
按照 B^2 Network 官方新的路線圖,其 DA 方案借鑒了 Celestia。 在後者的設計中,第三方的數據提供者會不斷的向 Celestia 網路提供數據,Celestia 出塊者會把這些數據片段,組織為 Merkle Tree 的形態,塞到 TIA 區塊裡,廣播給網路里的 Validator/全節點。
由於這些數據比較多,區塊比較大,大多數人運行不起全節點,只能運行輕節點。 輕節點不同步完整區塊,只同步一個區塊頭,寫有 Mekrle Tree 的樹根 Root。
輕節點僅憑區塊頭,自然不知道 Merkle Tree 的全貌,不知道新增數據都有什麼,無法驗證數據是否有問題。 但輕節點可以向全節點索要樹上的某個葉子 leaf。 全節點會按照要求,把 leaf 和對應的 Merkle Proof,一併提交給輕節點,讓後者確信,這個 leaf 的確存在於 Celestia 區塊裡的 Merkle Tree 上,而不是被節點憑空杜撰出的虛假數據。
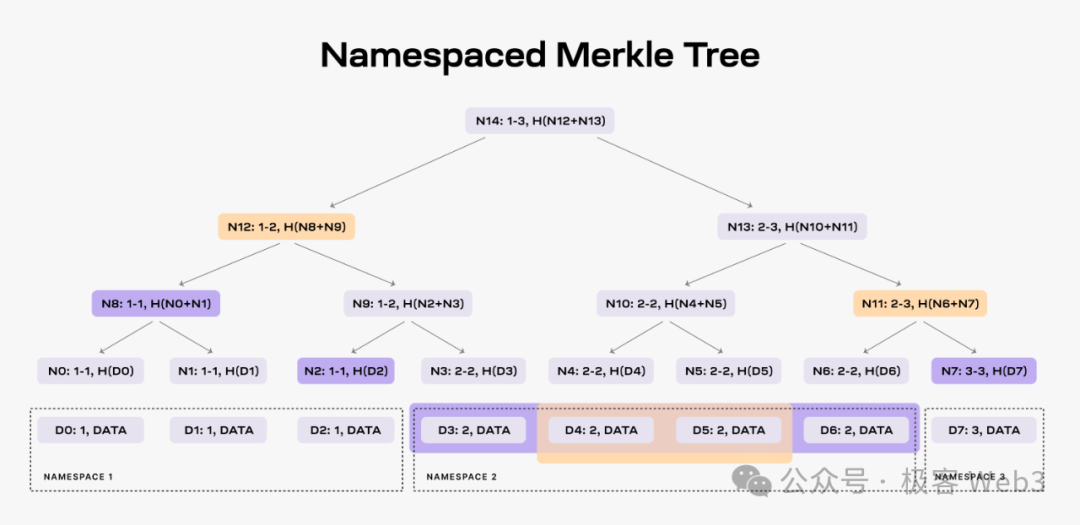
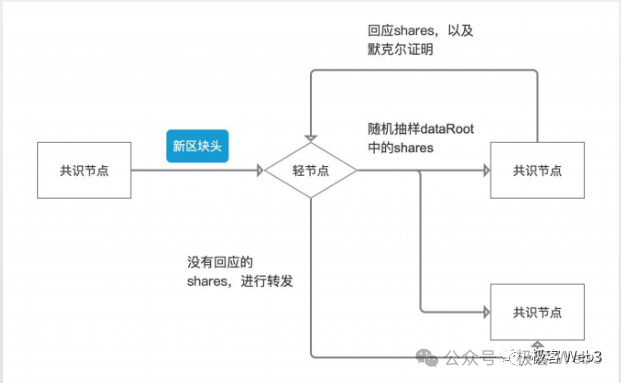
Celestia 網路里存在大量的輕節點,這些輕節點可以向不同的全節點發起高頻的數據採樣,隨機性的抽選 Merkle Tree 上的某幾個數據片段。 輕節點獲取到了這些數據片段后,也可以傳播給他能連接到的其他節點,這樣就可以快速的把數據分發給盡可能多的人/設備,以此來實現高效的數據傳播,只要足夠多的節點都能快速獲取最新的數據,人們就不用再信任一小撮數據提供者,這其實就是 DA/數據分發的核心目的之一。
當然,僅憑上面描述的方案,還是存在攻擊場景,因為它只能保證數據分發時,人們都能快速獲取到數據,但無法保證數據的生產源頭不作惡。 比如,Celestia 出塊者可能在區塊里摻雜一點垃圾數據,人們即便獲取了區塊中的全部數據片段,也無法還原出 “本應包含” 的完整數據集(注意:這裡 “本應” 這個詞很重要)。
進一步說,原始數據集中可能有 100 筆交易,其中某筆交易的數據沒有被完整傳播給外界。 這時,只需要隱藏 1% 的數據片段,外界就無法解析出完整數據集。 這正是最早的數據扣留攻擊問題中,所探討的場景。
其實,根據這裡描述的場景來理解數據可用性,可用性這個詞描述的是區塊里的交易數據是否完整,是否可用,能否直接交由其他人去驗證,而不是像很多人理解的那樣,可用性代表區塊鏈歷史數據能否被外界讀取到。 所以,Celestia 官方和 L2BEAT 創始人曾指出,數據可用性應該改名為數據發佈,意指區塊里是否發佈了完整可用性的交易數據集。
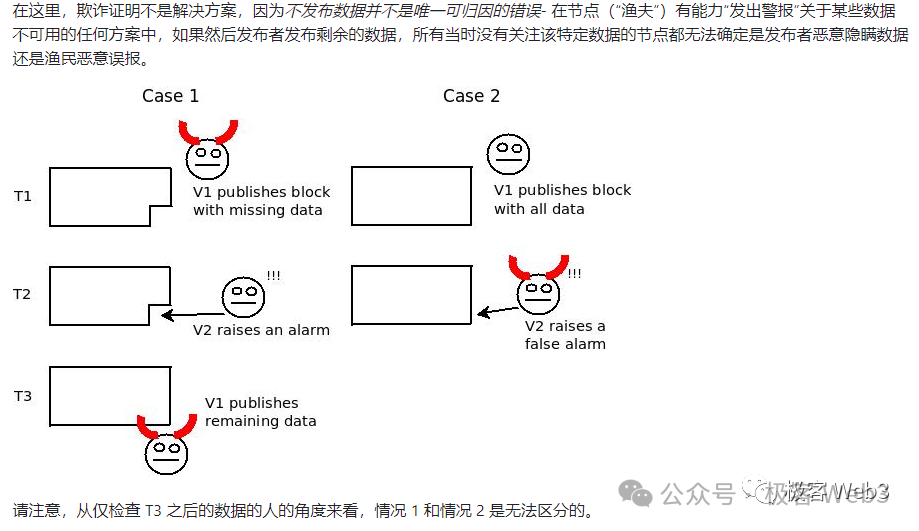
Celestia 引入了二維糾刪碼,解決上面描述的數據扣留攻擊。 只要區塊裡包含的 1/4 的數據片段(糾刪碼)有效,人們就可以還原出對應的原始數據集。 除非出塊者在區塊里摻雜 3/4 的垃圾數據片段,才能讓外界無法還原出原始數據集,但這種情況下,區塊裡包含的垃圾數據太多了,很容易就會被輕節點們檢測出來。 所以對於區塊生產者而言,還是不要作惡來的更好些,因為作惡幾乎很快就被無數人察覺到。
通過前面描述的方案,可以有效防止「數據分發平臺」出現數據扣留,而 B^2 Network 未來會以 Celestia 的數據採樣作為重要參考,可能結合 KZG 承諾等密碼學技術,進一步降低輕節點執行數據採樣和驗證的成本。 只要執行數據採樣的節點足夠多,就能讓 DA 數據的分發變得有效且去信任。
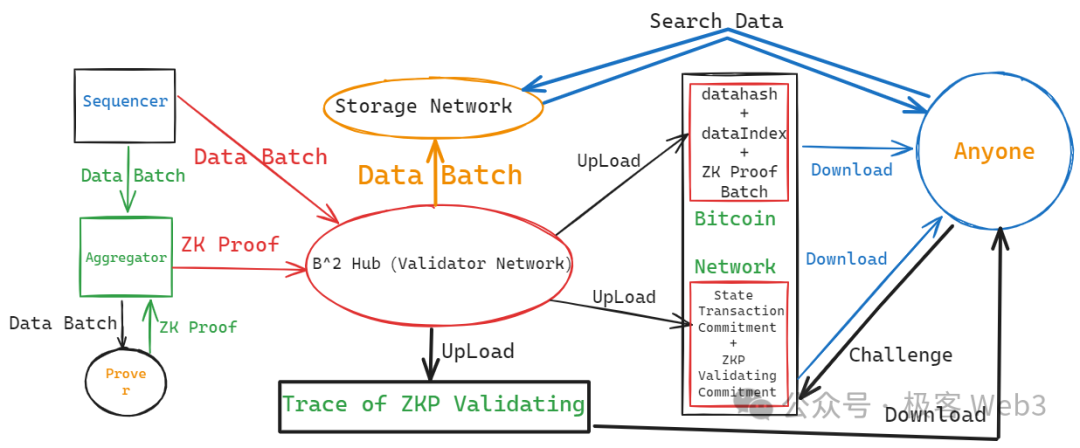
當然,上述方案只解決了 DA 平臺自身的數據扣留問題,但在 Layer2 的底層結構中,有能力發動數據扣留的不止 DA 平臺,還有排序器(Sequencer)。 在 B^2 Network 乃至大多數 Layer2 的工作流程中,新增數據是由排序器 Sequencer 產生的,它會把使用者端發來的交易匯總處理,附帶這些交易執行後的狀態變更結果,打包成批次(batch),再發送給充當 DA 層的 B^2 Hub 節點們。
如果排序器一開始生成的 batch 就有問題,就還存在數據扣留的可能性,當然還包括其他形式的作惡場景。 所以,B^2 的 DA 網路(B^2 Hub)收到排序器生成的 Batch 後,會先對驗證 Batch 的內容,有問題就拒收。 可以說,B^2 Hub 不但充當了類似於 Celestia 的 DA 層,也充當了鏈下的驗證層,有點類似於 CKB 在 RGB++協定中的角色。
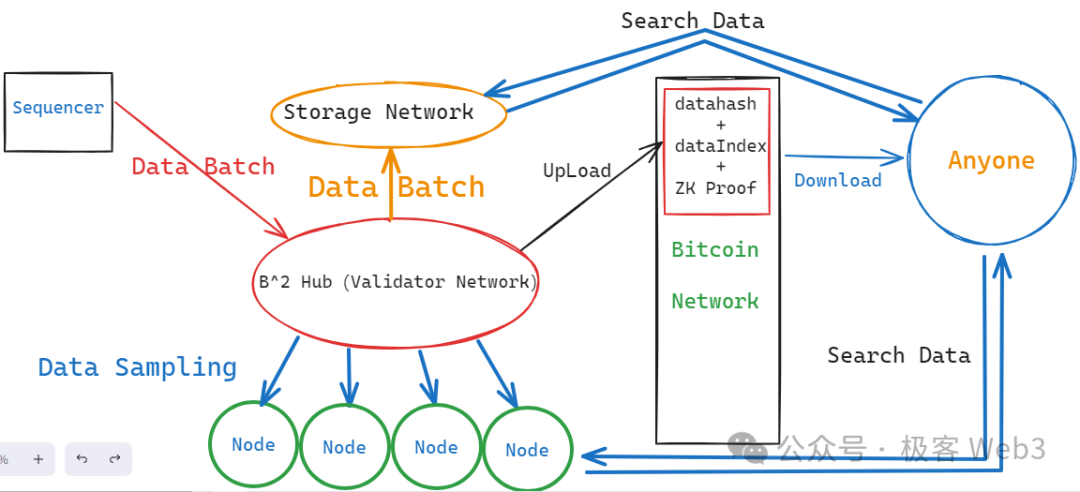
按照 B^2 Network 最新的技術路線圖,B^2 Hub 在收到並驗證了 Batch 後,只保留一段時間,過了這個視窗期,Batch 數據就會被過期淘汰,從 B^2 Hub 節點本地刪除掉。 為了解決類似於 EIP-4844 的數據淘汰及丟失問題,B^2 Network 設置了一組存儲節點,這些存儲節點會負責永存 Batch 數據,這樣一來,任何人在任何時候,都可以在存儲網路中搜索到自己需要的歷史數據。
不過,沒有人會平白無故的運行 B^2 儲存節點,如果想讓更多人來運行存儲節點,增強網路的去信任程度,就要提供激勵機制; 要提供激勵機制,就要先想辦法反作弊。 比如,假如你提出了一套激勵機制,任何人在自己的設備本地存儲了數據,就可以獲取獎勵,可能有人在下載了數據后,又偷偷的把一部分數據刪掉,卻聲稱自己存儲的數據是完整的,這就是最常見的作弊方法。
Filecoin 通過名為 PoRep 和 PoSt 的證明協定,讓存儲節點向外界出示存儲證明,證明自己在給定時間段內的確完整的保存了數據。 但這種存儲證明方案需要生成 ZK 證明,且計算複雜度很高,對存儲節點的硬體設備會有較高要求,可能不是一個經濟成本上可行的方法。
在 B^2 Network 的新版技術路線圖中,存儲節點會採用類似於 Arweave 的機制,需要爭奪出塊權來獲取代幣激勵。 如果存儲節點私自刪除了一些數據,則其成為下一個出塊者的概率會降低,而保留數據最多的節點,越有可能成功出塊,獲取到更多的獎勵。 所以對於大多數存儲節點而言,還是保留完整的歷史數據集比較好。
當然,有激勵的不只是存儲節點,還包括前面提到的 B^2 Hub 節點,按照路線圖,B^2 Hub 會組建成一個 Permissionless 的 POS 網络,任何人只要質押了足夠多的 Token,就可以成為 B^2 Hub 或存儲網路中的一員,通過這種方式,B^2 Network 嘗試在鏈下打造去中心化的 DA 平臺及存儲平臺,並在未來集成 B^2 以外的比特幣 Layer2,搭建通用的比特幣鏈下 DA 層與數據存儲層。
ZK 與欺詐證明混用的狀態驗證方案
前面我們闡述了 B^2 Network 的 DA 解決方案,接下來我們將重點講述其狀態驗證方案。 所謂的狀態驗證方案,就是指 Layer2 如何保證自己的狀態轉換足夠 “去信任”。
前面我們曾提到,在 B^2 Network 乃至大多數 Layer2 的工作流程中,新增數據是由排序器 Sequencer 產生的,它會把使用者端發來的交易匯總處理,附帶這些交易執行後的狀態變更結果,打包成批次(batch),發送給 Layer2 網路中的其他節點,包括普通的 Layer2 全節點,以及 B^2 Hub 節點。
B^2 Hub 節點在收到 Batch 數據後,會解析其內容並做出驗證,這裡就包含了前面提到的 “狀態驗證”。 其實狀態驗證,就是驗證排序器生成的 Batch 中,記錄的「交易執行後的狀態變化」是否正確。 如果 B^2 Hub 節點收到了包含錯誤狀態的 Batch,會將其拒收。
其實,B^2 Hub 本質是一條 POS 公鏈,會有出塊人和驗證人的分野。 每隔一段時間,B^2 Hub 的出塊人會生成新的區塊,並傳播給其他節點(驗證人),這些區塊裡包含了排序器提交的 Batch 數據。 剩下的工作流程和前面提到的 Celestia 有些許類似,有很多外部的節點,頻繁的向 B^2 Hub 節點索要數據片段,在這個過程中,Batch 數據會被分發給很多節點設備,也包括前面提到的存儲網路。
B^2 Hub 中存在名為 Committer(承諾人)的可輪換角色,它會把 Batch 的數據 hash(其實是 Merkle root),以及存儲索引,以銘文的形式提交到比特幣鏈上。 只要你讀取到這個數據 hash 和存儲索引,就有辦法在鏈下的 DA 層/存儲層獲取到完整的數據。 假設鏈下有 N 個節點存放著 Batch 數據,只要其中 1 個節點願意對外提供數據,就能讓任何人獲取到它需要的數據,這裡的信任假設是 1/N。

當然,我們不難發現,上述過程中,負責驗證 Layer2 狀態轉換有效性的 B^2 Hub,是獨立於比特幣主網的,只是一個鏈下的驗證層,所以這個時候,Layer2 的狀態驗證方案,在可靠性上無法等價於比特幣主網。
一般而言,ZK Rollup 可以完整的繼承 Layer1 的安全性,但目前比特幣鏈上只支援一些極為簡單的計算,無法直接驗證 ZK 證明,所以還沒有哪個 Layer2 可以在安全模型上等價於乙太坊的那種 ZK Rollup,包括 Citrea 和 BOB 等。
目前看來,「比較可行」的思路是 BitVM 白皮書中所闡述的那樣,複雜的計算過程挪到比特幣鏈下,僅在必要時把某些簡單的計算挪到鏈上進行。 比如驗證 ZK 證明時產生的計算痕跡,可以公開,交由外界去檢查。 如果人們發現其中某個比較細微的計算步驟有問題,就可以在比特幣鏈上驗證這道「有爭議的計算」。 這裡面需要用比特幣的腳本語言,類比出 EVM 等特殊虛擬機的功能,消耗的工程量可能會非常巨大,但並不是不可行。
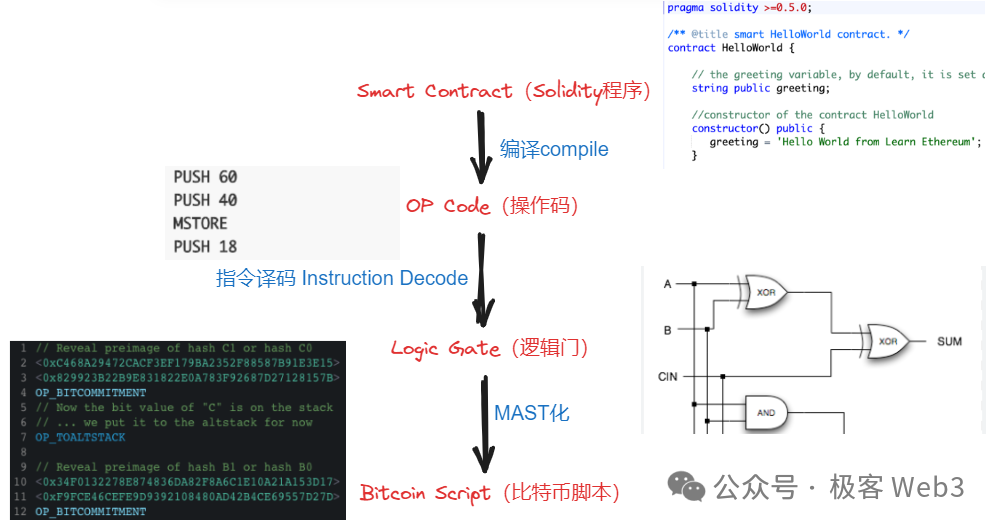
在 B^2 Network 的技術方案中,排序器產生了新的 Batch 後,會轉發給聚合器以及 Prover,後者把 Batch 的數據驗證過程 ZK 化,生成 ZK 證明,最終轉發給 B^2 Hub 節點。 B^Hub 節點是 EVM 兼容的,通過 Solidity 合約來驗證 ZK Proof,這其中涉及的全部計算過程,會被拆分為非常底層的邏輯門電路形態,這些邏輯門電路又會以比特幣腳本語言的形式表達出來,全部提交至輸送量足夠大的第三方 DA 平臺中。
如果人們對這些披露出來的 ZK 驗證痕跡存在疑問,覺得某個小步驟有錯誤,就可以在比特幣鏈上進行「挑戰」,要求比特幣節點直接檢查這個有問題的步驟,並適當做出懲罰。
那麼是誰被懲罰呢? 其實是 Committer。 在 B^2 Network 的設定中,Committer 不但會把前面說的數據 hash 發佈到比特幣鏈上,還要把 ZK 證明的驗證 “承諾” 發佈到比特幣主網。 通過比特幣 Taproot 的一些設定,你可以隨時在比特幣鏈上,對 Committer 發佈的 “ZK 證明驗證承諾” 進行質疑和挑戰。
這裡解釋下什麼「承諾」(Commitment)。 “承諾” 的含義在於,某些人聲稱,某些鏈下數據是準確無誤的,並在鏈上發佈對應的聲明,這個聲明就是 “承諾”,承諾值與特定的鏈下數據相綁定。 在 B^2 的方案中,如果有人認為 Committer 發佈的 ZK 驗證承諾有問題,就可以進行挑戰。
可能有人會問,前面不是提到 B^2 Hub 在收到 Batch 後,會直接驗證其有效性嗎,這裏為何又要 “多次一舉” 的驗證 ZK 證明? 為什麼不直接把驗證 Batch 的過程公開披露,讓人們直接挑戰,非要引入 ZK 證明幹什麼? 這其實是為了把計算痕跡壓縮的足夠小,如果直接把驗證 Layer2 交易、產生狀態變更的計算流程,全部以邏輯門電路和比特幣腳本的形式公開披露,將會產生極大的數據尺寸。 而 ZK 化之後,可以把數據尺寸極大程度壓縮后,再發佈出去。
這裡大致總結下 B^2 的工作流程:
- B^2 的排序器 Sequencer 負責產生新的 Layer2 區塊,並將多個區塊聚合為 data batch(數據批次)。 data batch 會被送給聚合器 Aggregator,以及 B^Hub 網络中的 Validator 節點。
- 聚合器會將 data Batch,發送給 Prover 節點,讓後者生成對應的零知識證明。 ZK 證明隨後會被發送給 B^2 的 DA 與驗證者網路(B^2Hub)。
- B^2Hub 節點會驗證聚合器發來的 ZK Proof,能否和 Sequencer 發過來的 Batch 相對應。 若兩者可以對應,則通過驗證。 通過驗證的 Batch,其數據 hash 與存儲索引,會被某個指定的 B^Hub 節點(稱為 Committer)發送至比特幣鏈上。
- B^Hub 節點會將其驗證 ZK Proof 的整個計算過程公開披露,將計算過程的 Commitment 發送到比特幣鏈上,允許任何人對其進行挑戰。 如果挑戰成功,則發佈 Commitment 的 B^Hub 節點將受到經濟懲罰(它在比特幣鏈上的 UTXO 將被解鎖並轉移給挑戰者)
B^2 Network 的這種狀態驗證方案,一面引入了 ZK,一面採用了欺詐證明,實際上屬於混合型的狀態驗證方式。 只要鏈下存在至少 1 個誠實的節點,在檢測出錯誤后願意發起挑戰,就可以保證 B^2 Network 的狀態轉換是沒有問題的。
按照西方比特幣社區成員的看法,未來比特幣主網可能會進行適當的分叉,以支援更多的計算功能,也許在未來,直接在比特幣鏈上驗證 ZK 證明會成為現實,屆時將為整個比特幣 Layer2 帶來新的範式級變革。 而 B^2 Hub 作為一個通用的 DA 層與驗證層,不但可以作為 B^2 Network 的專用模組,還可以賦能其他比特幣二層,在比特幣 Layer2 的大爭之世中,鏈下功能拓展層必將越來越重要,而 B^Hub 和 BTCKB 的湧現,或許才剛剛揭開這些功能拓展層的冰山一角。
免責聲明:作為區塊鏈資訊平臺,本站所發佈文章僅代表作者及嘉賓個人觀點,與 Web3Caff 立場無關。 文章內的資訊僅供參考,均不構成任何投資建議及要約,並請您遵守所在國家或地區的相關法律法規。