

Plasma 無法解決數據扣留問題,也不利於把合約狀態遷移到 Layer1,必然被廢棄
作者:Faust,極客 Web3
封面:Photo by Conny Schneider on Unsplash
關於 Plasma 為何被長期埋沒,以及 Vitalik 會大力支援 Rollup,線索主要指向兩點:在乙太坊鏈下實現 DA 是不可靠的,很容易發生數據扣留,而數據扣留一旦發生,欺詐證明就難以展開; Plasma 的機制設計本身對智慧合約極其不友好,尤其難以支援合約狀態遷移到 Layer1。 這兩點使得 Plasma 基本只能採用 UTXO 或近似的模型。
為了理解上述兩個核心觀點,我們先從 DA 和數據扣留問題講起。 DA 的全稱是 Data Avalibility,字面譯作數據可用性,現在被很多人誤用,以至於和 “ 歷史數據可查「嚴重混淆」。 但實際上,“ 歷史數據可查「以及」存儲證明「是 Filecoin 和 Arweave 等早已解決的問題。 按照乙太坊基金會和 Celestia 的說法,DA 問題單純探討數據扣留場景。
Merkle Tree 和 Merkle Root 及 Merkle Proof
為了說明數據扣留攻擊與 DA 問題究竟指什麼,我們需要先簡單講一下 Merkle Root 和 Merkle Tree。 在乙太坊或絕大多數公鏈中,用一種稱作 Merkle Tree 的樹狀數據結構,充當全體賬戶狀態的摘要/目錄,或記錄每個區塊內打包的交易。
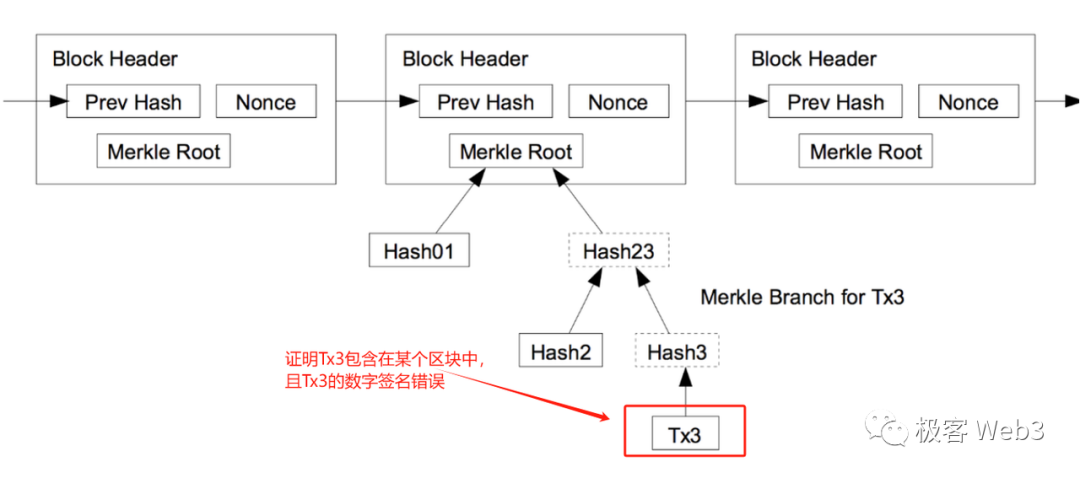
Merkle Tree 最底層的葉子節點,由交易或賬戶狀態等原始數據的 hash 構成,這些 hash 兩兩一組求和,反復迭代,最終可以算出一個 Merkle Root.
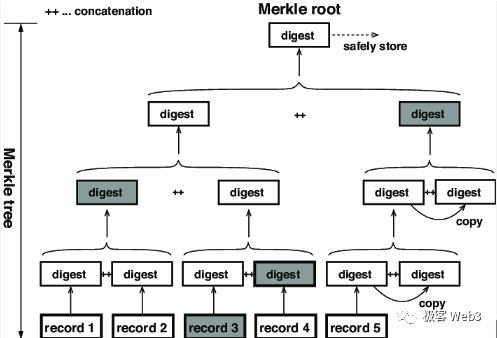
Merkle Root 有一個性質:如果 Merkle Tree 底層某個葉子節點發生變化,計算得到的 Merkle Root 也會發生變化。 所以,對應不同原始數據集的 Merkle Tree,會有不同的 Merkle Root,就好比不同的人有不同的指紋。 而被稱作 Merkle Proof 的證明驗證技術,利用了 Merkle Tree 的這個性質。
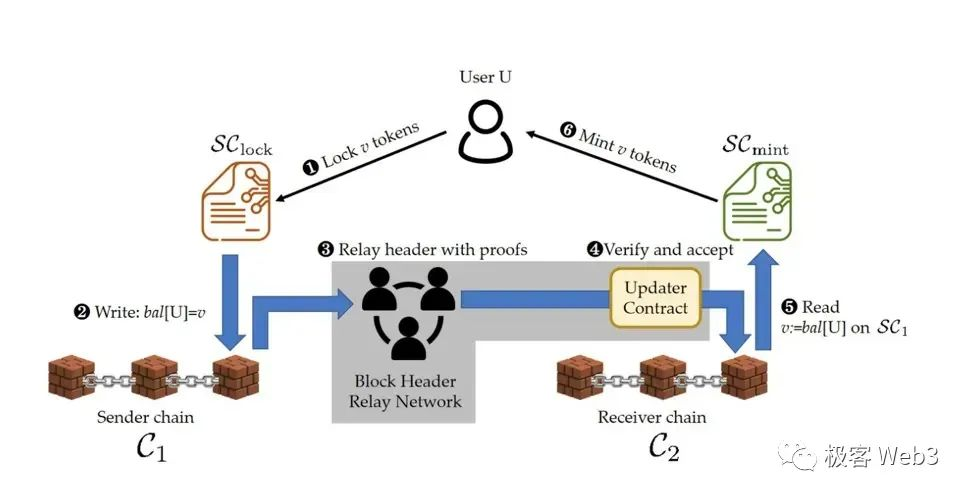
以上圖為例,假如李剛只知道圖中 Merkle Root 的數值,不知道完整的 Merkle Tree 包含哪些數據。 我們要向李剛證明,Record 3 的確和圖中的 Root 有關聯性,或者說,證明 Record 3 的哈希存在於 Root 對應的那棵 Merkle Tree 上。
我們只需要把 Record3,以及標記為灰色的那 3 個 digest 數據塊,提交給李剛,而不必把整個 Merkle Tree 或其所有葉子節點都提交過去,這就是 Merkle Proof 的簡潔性。 當 Merkle Tree 底層記錄的葉子特別多時,比如包含了 2 的 20 次冪個數據塊(約 100 萬),Merkle Proof 最少只需要包含 21 個數據塊。
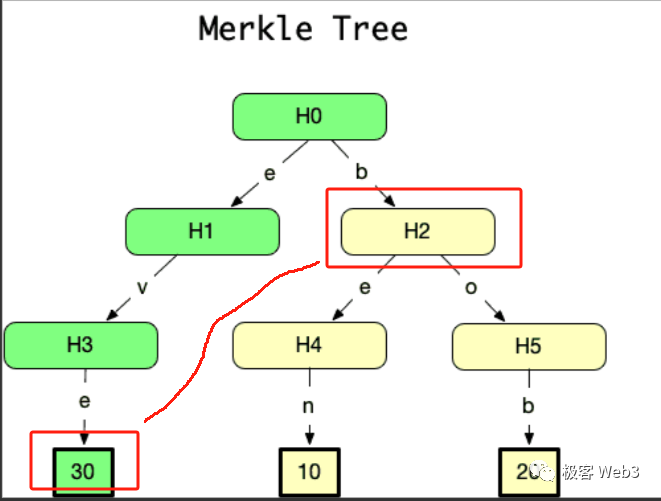
在比特幣、乙太坊或跨鏈橋中,經常用到 Merkle Proof 的這種「簡潔性」。。 我們所知的輕節點,其實就是上文提到的李剛,他只從全節點那裡接收區塊頭 header,而不是完整的區塊。 這裡需要強調,乙太坊用稱為 State Trie 的默克爾樹,充當全體帳戶的摘要。 只要 State Trie 關聯著的某個帳戶狀態發生變化,State Trie 的 Merkle Root——稱為 StateRoot 就會變化。
乙太坊的區塊頭中,會記錄 StateRoot,同時也會記錄交易樹的 Merkle Root(簡稱 Txn Root),交易樹和狀態樹的一個區別,在於底層葉子所代表的數據不同。 假如第 100 號 block 內包含 300 筆交易,則交易樹的葉子,代表的就是這 300 筆 Txn。
另一個區別在於,State Trie 整體的數據量特別大,它的底層葉子對應著乙太坊鏈上所有位址(實際上還有很多過時的狀態哈希),所以 State Trie 對應的原始數據集不會發佈到區塊中,只在區塊頭記錄下 StateRoot。 而交易樹的原始數據集就是每個區塊內的 Txn 數據,這棵樹的 TxnRoot 會記錄在區塊頭裡。
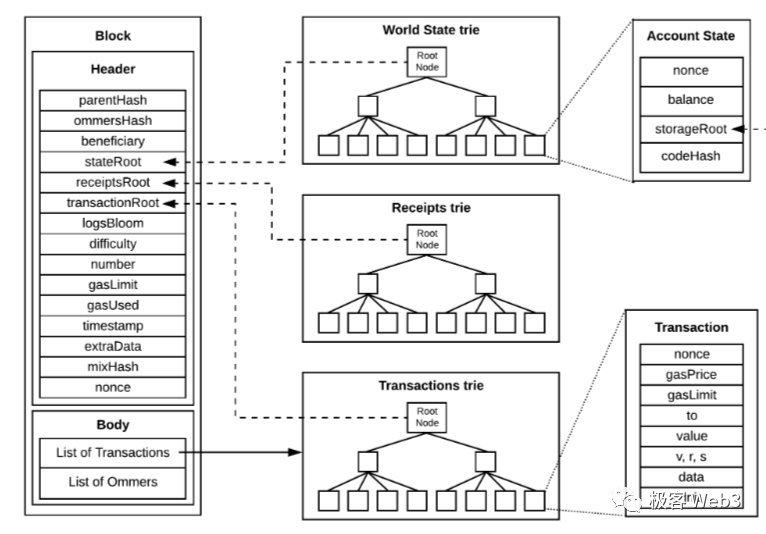
由於輕節點只接收區塊頭,只知道 StateRoot 和 TxnRoot,不能根據 Root 反推出完整的 Merkle Tree(這是由 Merkle Tree 和哈希函數的性質決定的),所以輕節點無法獲知區塊內包含的交易數據,也不知道 State Trie 對應的帳戶發生了哪些變化。
如果王強要向某個輕節點(前面提過的李剛)證明,第 100 號 block 中包含某筆交易,已知輕節點知道 100 號 block 的區塊頭,知道 TxnRoot,那麼上述問題轉化為:證明這筆 Txn 存在於 TxnRoot 對應的那棵 Merkle Tree 上。 這個時候,王強只要提交對應的 Merkle Proof 即可。
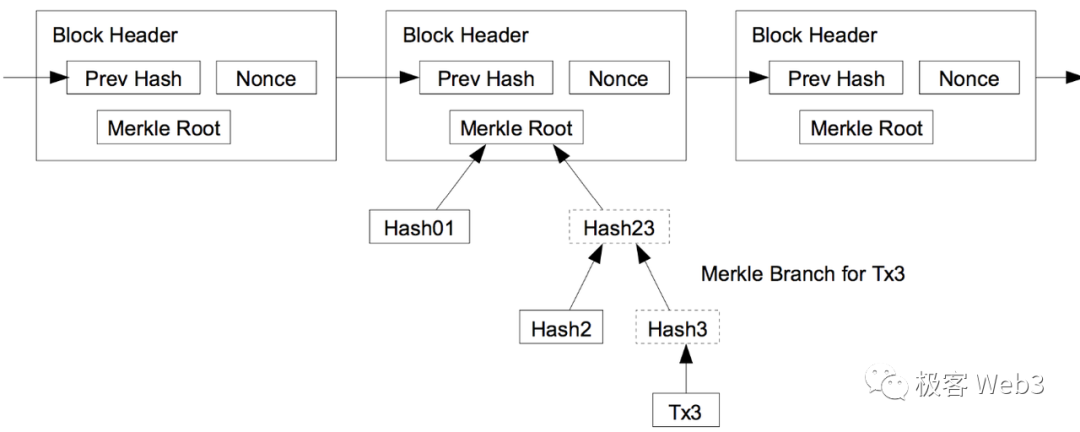
在很多基於輕用戶端方案的跨鏈橋中,常常會用到上面講到的,輕節點和 Merkle Proof 的輕量與簡潔性。 比如說,Map Protocol 等 ZK 橋,會在 ETH 鏈上設置一個合約,專門接收其他鏈的區塊頭(比如 Polygon)。 當 Relayer 向 ETH 鏈上的合約,提交 Polygon 第 100 個區塊的 header 後,合約會驗證 header 的有效性(比如是否湊足了 Polygon 網路內 2/3 POS 節點的簽名)。
如果 Header 有效,且某使用者聲明,自己發起了從 Polygon 到 ETH 的跨鏈 Txn,該 Txn 被打包進了 Polygon 第 100 個區塊。 他只要通過 Merkle Proof,證明自己發起的跨鏈 Txn,能對應上 100 號區塊頭的 TxnRoot(換句話說,就是證明自己發起的跨鏈 Txn 在 Polygon 的 100 號區塊內有記錄)。 只不過 ZK 橋會通過零知識證明,壓縮驗證 Merkle Proof 所需的計算量,進一步降低跨鏈橋合約的驗證成本。
DA 與數據扣留攻擊問題
講完了 Merkle Tree 和 Merkle Root、Merkle Proof,我們回到文章最開頭說到的 DA 與數據扣留攻擊問題,這一問題早在 2017 年以前就被人探討過,Celestia 原始論文有對 DA 問題的來源進行考古。 Vitalik 本人則在 2017~18 年的一個文檔中,談到出塊者可能故意隱瞞 block 的某些數據片段,對外發佈不完整的區塊,這樣一來,全節點就無法確認交易執行/狀態轉換的正確性。
此時,出塊者可以盜取用戶資產,比如把 A 帳戶中的幣全部划轉到別的位址,而全節點無法判斷 A 本人是否有這麼做,因為他們不知道最新區塊包含的完整交易數據。
在比特幣或乙太坊等 Layer1 公鏈中,誠實全節點會直接拒收上述無效區塊。 但輕節點則不同,他們只從網路中接收區塊頭 Header,只知道 StateRoot 和 TxnRoot,不知道 Header 和兩個 Root 對應的的原始區塊是否有效。
在比特幣白皮書中,其實有對這種情況作出腦洞,中本聰曾認為,大多數用戶會傾向於運行配置要求較低的輕節點,而輕節點無法判斷區塊頭對應的 block 是否有效,如果某個 block 無效,誠實全節點會向輕節點發出警報。
但中本聰沒有對這個方案進行更細緻的分析,後來 Vitalik 和 Celestia 創始人 Mustafa 在這個 idea 之上,結合其他前人的成果,引入了 DA 數據採樣,確保誠實全節點能夠還原出每個區塊的完整數據,並在必要時刻發出警報。

注:DA 數據採樣(DAS)與 Celestia 並不是本文要探討的重點,感興趣的讀者可以閱讀《極客 web3》過往文章:《對數據可用性的誤解:DA=數據發佈≠歷史數據檢索》
Plasma 的欺詐證明
簡單來說,Plasma 是一種只把 Layer2 的區塊頭發佈到 Layer1 上的擴容方案,區塊頭之外的 DA 數據(完整的交易數據集/每個帳戶的狀態變化)只在鏈下發佈。 換句話說,Plasma 就像基於輕用戶端的跨鏈橋一樣,在 ETH 鏈上用合約實現了 Layer2 的輕用戶端,當使用者聲明要把資產從 L2 跨到 L1 時,要提交 Merkle Proof,證明自己的確擁有這些資產。
資產從 L2 跨到 L1 的驗證邏輯,和前文中談到的 ZK 橋比較類似,只不過 Plasma 的橋接模型基於欺詐證明,而不是 ZK 證明,更接近於所謂的「樂觀橋」。。 Plasma 網路中從 L2 到 L1 的提款請求不會被立刻放行,而是有一個「挑戰期」,至於挑戰期的目的是什麼,我們會在下面講解。
Plasma 對數據發佈/DA 沒有嚴格要求,排序器/Operator 只是在鏈下廣播每個 L2 區塊,有意願獲取 L2 區塊的節點去自行獲取。 之後,排序器會把 L2 區塊的 Header 發佈到 Layer1。 比如說,排序器先在鏈下廣播第 100 號區塊,之後把區塊的 header 發佈到鏈上。 如果 100 號區塊中包含無效交易,任何 Plasma 節點都可以在「挑戰期」結束前,向 ETH 上的合約提交 Merkle Proof,證明第 100 號區塊頭能關聯到某筆無效交易,這就是欺詐證明涵蓋的一個場景。
Plasma 的欺詐證明應用場景還包括以下幾種:
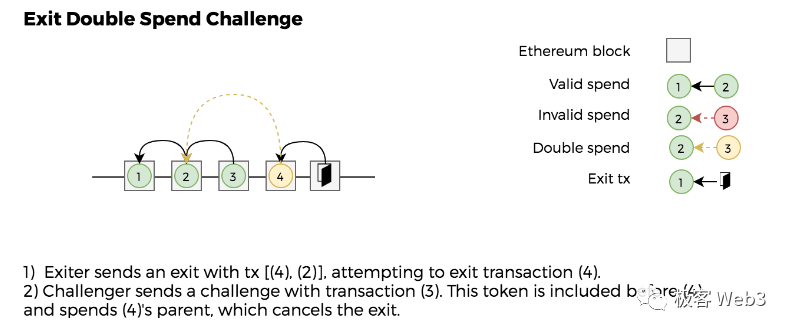
1. 假設 Plasma 網路的進度到了 200 號區塊,此時 A 用戶發起提款聲明,稱自己在第 100 號區塊時,有 10 枚 ETH。 但實際上,A 使用者在 100 號區塊之後,曾把賬上的 ETH 花掉。
所以,A 的行為實際上是:花掉 10 枚 ETH 后,聲明自己在以前有 10 枚 ETH,並嘗試把這些 ETH 提走。 這就是典型的「雙重提款」,雙花。 此時,任何人都可以提交 Merkle Proof,證明 A 使用者最新的資產狀況,不滿足其提款聲明,也就是證明 A 在 100 號區塊後,沒有提款聲明的那些錢(不同的 Plasma 方案針對這種情況的證明方法不一致,帳戶位址模型遠比 UTXO 的雙花證明麻煩的多)。
2. 如果是基於 UTXO 模型的 Plasma 方案(過去主要都是這種),區塊頭中是不包含 StateRoot 的,只有 TxnRoot(UTXO 不支援乙太坊式的帳戶位址模型,也沒有 State Trie 這種全域狀態設計)。 換言之,採用 UTXO 模型的鏈只有交易記錄,沒有狀態記錄。
此時,排序器自身可能發動雙花攻擊,比如把某個已經被花掉的 UTXO 再花一次,或者給某個使用者憑空增發 UTXO。 任何一個使用者都可以提交 Merkle Proof,證明該 UTXO 的使用記錄在過往區塊中出現過(被花過),或者證明某個 UTXO 的歷史來源有問題。
3. 對於 EVM 相容/支援 State Trie 的 Plasma 方案,排序器有可能提交無效的 StateRoot,比如說,在執行了第 100 個區塊中包含的交易后,StateRoot 應該轉換為 ST+,但排序器往 Layer1 提交的卻是 ST-。
這種情況下的欺詐證明比較複雜,需要在乙太坊鏈上重放第 100 號區塊中的交易,計算量和需要的輸入參數會消耗大量 gas。 早期採用 Plasma 的團隊難以實現如此複雜的欺詐證明,所以大多採用了 UTXO 模型,畢竟基於 UTXO 的欺詐證明很簡潔,也好實現(首個上線欺詐證明的 Rollup 方案 Fuel,就是基於 UTXO 的)
數據扣留與 Exit Game
當然,上述欺詐證明能生效的場景,都是在 DA/數據發佈有效時,才成立的。 如果排序器搞數據扣留,不在鏈下發佈完整的區塊,Plasma 節點就無法確認 Layer1 上的區塊頭是否有效,當然也無法順利發佈欺詐證明。
此時,排序器可以盜取用戶資產,比如私自把 A 帳戶的幣全部划轉到 B 帳戶,再從 B 帳戶給 C 轉帳,最後用 C 的名義發起提款。 B 和 C 帳戶是排序器自己擁有的,B->C 這筆轉帳就算對外公示,也無傷大雅; 但排序器可以扣留 A->B 這筆無效轉帳的數據,人們無法證明 B 和 C 的資產來源有問題(要證明 B 的資產來源有貓膩,就要指出 “ 給 B 轉帳的某筆 Txn” 的數位簽名有誤)。
基於 UTXO 的 Plasma 方案有針對性的舉措,比如任何人發起提款時,都要提交資產的全部歷史來源,當然後來有更多的改良措施。 但如果是 EVM 相容的 Plasma 方案,會在這塊顯得軟弱無力。 因為如果涉及與合約相關的 Txn,在鏈上驗證狀態轉換過程會產生巨量成本,所以支持帳戶位址模型和智慧合約的 Plasma,不好實現針對提款有效性的驗證方案。
此外,拋開上面的話題,無論是基於 UTXO 還是基於帳戶位址模型的 Plasma,一旦發生數據扣留,基本都會引發人們的恐慌,因為你不知道排序器都執行了哪些交易。 Plasma 的節點會發現不對勁,但又無法針對性的發佈欺詐證明,因為欺詐證明所需的數據,Plasma 排序器沒發出來。
這個時候,人們只能看到對應的區塊頭,但不知道區塊裡面都有什麼,不知道自己的帳戶資產變成了什麼樣,大家會集體發起提款聲明,用對應著歷史區塊的 Merkle Proof 嘗試提款,引發被稱作 “Exit Game” 的極端場景,這種情況會導致 “踩踏”,使得 Layer1 嚴重擁堵,並仍會導致一些人資產受損(沒有接收到誠實節點通知或者不刷推特的人,根本不會知道排序器正在盜幣)。

所以,Plasma 是一種不可靠的 Layer2 擴容方案,一旦發生數據扣留攻擊,就會觸發 “Exit Game”,很容易讓使用者蒙受損失,這是其被廢棄的一大原因。
Plasma 難以支援智能合約的原因
在講過了 Exit Game 和數據扣留問題後,再來看 Plasma 為什麼難以支持智能合約,主要是兩個理由:
其一,如果是 Defi 合約的資產,該由誰來提取到 Layer1? 因為這本質上就是把合約的狀態從 Layer2 遷移到 Layer1,假設有人往 DEX 的 LP 池子充了 100 個 ETH,之後 Plasma 的排序器作惡了,人們要緊急提款,這時候使用者的 100 個 ETH 都還為 DEX 合約所控制,請問這個時候這些資產該由誰提到 Layer1 上?
最好的辦法,似乎是先讓使用者從 DEX 贖回資產,再由使用者自己去把錢提到 L1 上,但問題是 Plasma 排序器已經作惡了,隨時可能拒絕使用者請求。
那麼,如果我們事先給 DEX 合約設置 Owner,允許他在緊急情況下,把合約資產提到 L1 上呢? 顯然這會賦予合約 Owner 以公共資產的擁有權,他可以隨時把這些資產提到 L1 上並跑路,這豈不是太可怕了?
顯然,該怎麼處置這些由 Defi 合約所支配的「公共財產」,是一個巨大的雷。 這其實涉及到公權力分配的難題,此前響馬曾在訪談《高性能公鏈難出新事,智慧合約涉及權力分配》中談到過這點。

其二,如果不允許合約遷移狀態,會使其蒙受巨額損失; 如果允許合約把自己的狀態遷移到 Layer1,會出現 Plasma 欺詐證明難以解決的雙重提款:
比如,我們假設 Plasma 採用乙太坊的帳戶位址模型,支援智慧合約,有一個混幣器,目前存入了 100 枚 ETH,混幣器的 Owner 由 Bob 控制;
假設 Bob 在第 100 個區塊時,從混幣器提走 50 枚 ETH。 之後 Bob 發起提款聲明,把這 50 枚 ETH 跨到了 Layer1 上;
之後,Bob 用過去的合約狀態快照(比如第 70 個區塊),把混幣器過去的狀態遷移到 Layer1 上,這會把混幣器 “曾經擁有” 的 100 枚 ETH 也跨到 Layer1 上;
顯然,這是典型的「雙重提款」,也就是雙花。 有 150 枚 ETH 被 Bob 提到了 Layer1,但 Layer2 網路使用者只向混幣器/Bob 付出 100 枚 ETH,有 50 枚 ETH 被憑空抽走。 這很容易把 Plasma 的儲備金抽乾。 理論上人們可以發起欺詐證明,證明混幣器合約的狀態在第 70 個區塊之後有變化。
但假如在第 70 號區塊之後,所有和混幣器合約產生交互的 Txn,都沒有改變合約狀態,除了 Bob 抽走 50 枚 ETH 那筆交易; 如果你要出示證據,指出混幣器合約在第 70 號區塊後有變化,就要在乙太坊鏈上把上述提及的所有 Txn 跑一遍,最終才能讓 Plasma 合約確定,混幣器合約狀態的確發生過變化(之所以這麼複雜,是由 Plasma 本身的構造決定的)。 如果這批 Txn 數量極大,欺詐證明根本無法在 Layer1 上發布(會超出乙太坊單個區塊的 gas 上限)。

理論上來說,上面的雙花場景中,似乎只要提交混幣器當前的狀態快照(其實就是對應 StateRoot 的默克爾證明),但實際上,由於 Plasma 不在鏈上發佈交易數據,合約無法確定你提交的狀態快照是否有效。 這是因為排序器自己可能發動數據扣留,提交無效的狀態快照,惡意指證任何一名提款者。
比如說,當你聲明自己賬上有 50 枚 ETH 併發起提款時,排序器可能私自把你帳戶清 0,然後發動數據扣留,把一個無效的 StateRoot 發到鏈上,並提交對應的狀態快照,誣告你帳戶裡沒錢了。 這個時候大家沒法證明排序器提交的 StateRoot 和狀態快照無效,因為他發動了數據扣留,你得不到欺詐證明需要的足量數據。
為了防止這種情況,Plasma 節點在出示狀態快照證明某人有雙花行為時,還要重放這段時間內的交易記錄,這可以防止排序器用數據扣留來阻止別人提款。 而在 Rollup 中,如果遇到上述雙重提款,理論上不需要重放歷史交易,因為 Rollup 不存在數據扣留問題,會「強制要求」排序器在鏈上發布 DA 數據。 Rollup 排序器如果提交一個無效 StateRoot-狀態快照,要麼無法通過合約驗證(ZK Rollup),要麼很快就會被挑戰(OP Rollup)。
其實除了上面談到的混幣器的例子外,多簽合約等場景一樣可以導致 Plasma 網路發生雙重提款。 而欺詐證明對這種場景的處理效率很低。 在 ETH Research 中有對這種情況作出分析。
綜上所述,由於 Plasma 方案不利於智能合約,基本不支援合約狀態遷移到 Layer1,主流的 Plasma 只好選用 UTXO 或類似的機制,因為 UTXO 不存在資產擁有權衝突問題,並且能很好的支援欺詐證明(尺寸小很多),但代價是應用場景單一,基本只能支援轉帳或者訂單簿交易所。
此外,因為欺詐證明本身對 DA 數據有較強的依賴,如果 DA 層不可靠,將難以實現高效率的欺詐證明系統。 而 Plasma 對於 DA 問題的處理太簡陋,無法解決數據扣留攻擊問題,隨著 Rollup 的崛起,Plasma 慢慢就淡出了歷史舞臺。
免責聲明:作為區塊鏈資訊平臺,本站所發佈文章僅代表作者及嘉賓個人觀點,與 Web3Caff 立場無關。 文章內的資訊僅供參考,均不構成任何投資建議及要約,並請您遵守所在國家或地區的相關法律法規。










