

通過 ActLifter 和 ActCluster 工具,我們在 600 多萬個交易包中發現了 17 個未知類型的 MEV。
原文:EP11· 揭秘乙太坊交易包中的 MEV 活動 Part2· Web3 青年學者計劃分享
嘉賓:Zihao Li,香港理工大學博士生
整理:aididiao.eth,Foresight News
本文為 Web3 青年學者計劃中 香港理工大學博士生 Zihao Li 視頻分享的文字整理。 Web3 青年學者計劃由 DRK Lab 聯合 imToken 和 Crytape 共同發起,會邀請加密領域中知名的青年學者面向華語社區分享一些最新的研究成果。

大家好,我是 Zihao Li,香港理工大學三年級博士生,今天分享的主題是《揭秘乙太坊交易包中的 MEV 活動》。 簡單來說就是如何通過交易包發現乙太坊網路中未知類型的 MEV 活動。 首先我會做一個比較基礎的背景介紹,比如 MEV 概念、交易包機制以及我們工作的背景。 然後我會詳細介紹完整工作流以及一些設計思路,例如基於什麼樣的設計原則來設計的工作流; 我們的數據集有哪些; 我們使用了哪些工具在哪些指標上評估我們的工作流等。 最後我會介紹三個應用包括相關的實證分析結果。
背景介紹:MEV、交易包、動機

MEV 活动是指区块链中的套利者通过监控区块链网络包括区块状态等生成套利交易。一些交易信息是在区块链 P2P 网络上传播,或者说在矿工或者验证者的交易池中储存还没有正式上链的一些交易,当套利者监听到这些交易信息之后,他通过一些策略产生自己的套利交易,然后把套利交易指定在接下来区块某一个位置,比如说他要在下一个区块的头部,或者说在某个交易的后面紧跟着执行策略化交易来传播一样的套利交易。这样去指定某个位置的套利活动,我们可以把它认为是 MEV 活动。比如套利者监控到资产价格发生了波动,它就可以在价格低的交易池中购买到相应的资产,然后在另外一个价格高的资金池中高点卖出,这样我们认为是一个 MEV 的活动。
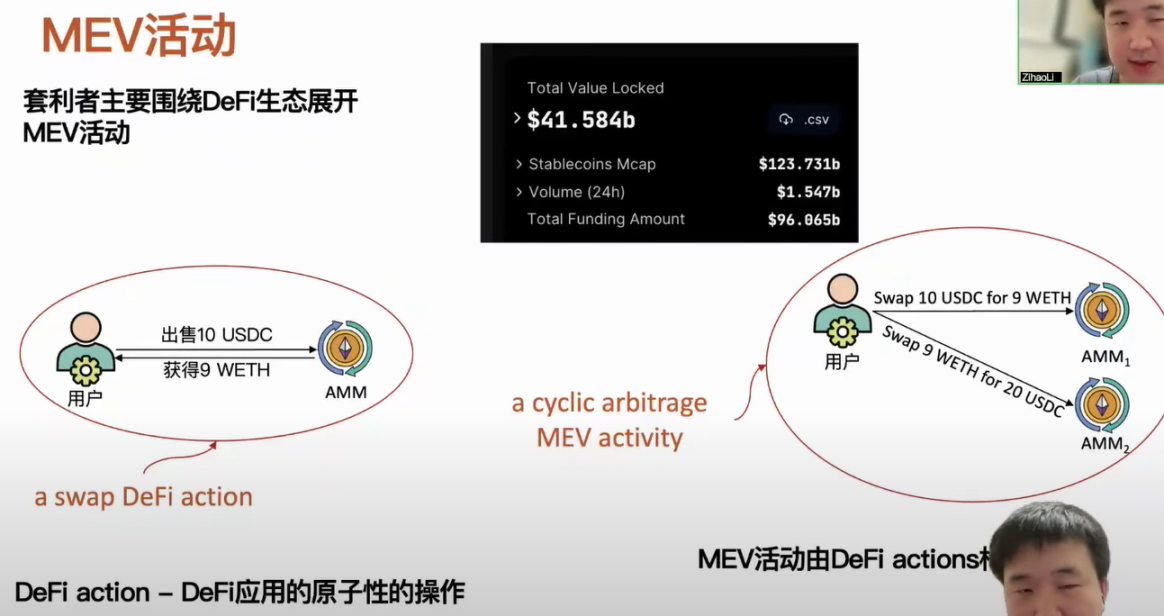
MEA 活动目前来说主要是套利者围绕 DeFi 生态展开的,因为 DeFi 生态目前主要聚集着资产,到目前为止,以太坊包括其他链 DeFi 生态已经吸引了超过 400 亿美元的资金量。这里需要提一个关于 DeFi 生态的概念,称之为 DeFi action,它对应的是一个 DeFi 应用提供的原子化服务操作,比如像我们知道 AMM 支持不同类型的资产之间进行兑换,用户可以出售一笔 USDC,然后得到一笔 ETH,这样的一个操作可以被定义为 DeFi action。我们可以用 DeFi action 将 MEV 活动表示出来,例如一个用户监测到不同 AMM 上面资产价格有些差距,用户就可以通过低买高卖的方式,最终获得这笔价差利润。我们可以将这个 MEV 活动表示为两个 DeFi action。
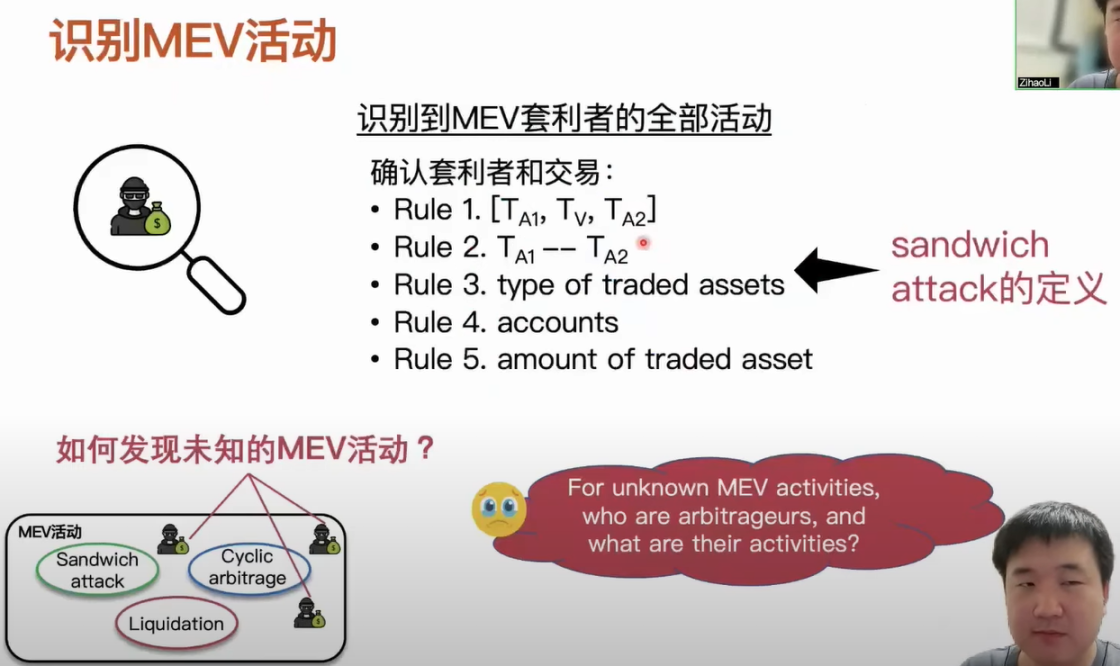
目前學術界對於 MEV 活動的研究主要分三類,分別是三明治攻擊、反向套利和清算,在我們工作的數據集裡面,我們發現這三種 MEV 活動出現次數超過 100 多萬筆。 這裏其實有一個問題,在我們知道這些 MEV 活動的定義之後,要怎麼去識別活動的發生。 如果我們想要識別這些 MEV 活動,我們就需要識別套利者的全部活動,比如說套利者產生哪些交易,這些交易裡面又有哪些類型的套利,然後我們才能確定當前是哪個類型的 MEV 活動在發生,而整個過程嚴重依賴於我們對已知 MEV 活動的定義。 以三明治攻擊舉例,我們知道三明治攻擊的定義之後,想要確定三明治攻擊的套利值,還有它對應的套利交易,我們需要從定義出發設置非常多的規則,然後通過這些規則篩選出候選三明治攻擊的套利值和交易。 當通過這種方式去識別已知 MEV 攻擊類型時,這裡會有兩個問題,第一個問題是我們已知三種常見的 MEV 活動是否能夠代表所有的 MEV 活動? 顯然是不能的,因為 DeFi 生態一直在發展,新的應用也一直在開發,而這些套利者本身的策略其實也是在一直反覆運算的。 第二個問題是我們怎麼才能去發現這些未知的 MEV 活動。 我們抱著這樣的問題來看一下交易包機制。

交易包機制最早是在 2021 年提出的,簡單來說就是使用者可以組織交易佇列,這個交易佇列的長度可以是一個交易,也可以是若干個交易,然後使用者將這些交易發給區塊鏈網路中的中繼者,中繼者將這些交易收集之後直接並且私密地發給相關的礦工或者驗證者。 目前中繼者會運行交易包去承接中繼任務。 交易包機制有一個非常重要的特徵,這些用戶在構造交易包的時候,他可以將其他人還沒有上鏈的交易放到一個交易包,並且交易包中的交易順序是可以任意操縱的。 這個時候交易包的使用者或者說使用交易包的套利者就可以設計他的套利規則。 比如說他可以設計更複雜的並且獲利更多的 MEV 活動策略。 以三明治攻擊為例,如果沒有使用交易包,一個三明治攻擊的套利者至少需要產生一對交易才能實現套利,而這一對套利交易只能針對這一筆交易。 這個攻擊交易產生套利需要必須是以一定順序執行才能確保它能夠套利成功。 但是如果一個套利者使用交易包時,他就可以收集很多筆可以套利的交易,只需要用一對相應的套利交易就可以同時對多筆交易產生套利。 這個交易包只要上鏈,它就一定套利成功,並且因為它同時對多筆可套利的交易進行套利,所以說它的套利結果也是收益更多的。

交易包的特性是有非常豐富且複雜的 MEV 活動。 因為使用交易包的使用者將自己完整的交易封裝在交易包中,然後發給 P2P 網路的中繼者,最後發給相應的礦工和驗證者。 我們通過交易包可以準確且完整的去識別到全部活動。 因此我們是可以通過交易包媒介去比較準確的識別到一些未知的 MEV 活動。
工作流與設計思路
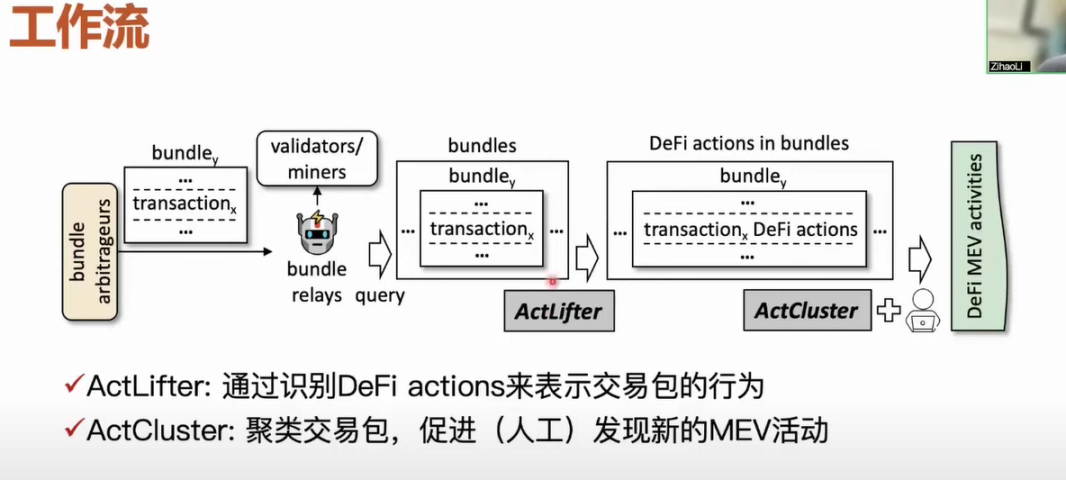
接下來具體介紹一下我們的工作流。 我們是怎麼通過交易包這樣的媒介去發現未知的 MEV 活動的呢? 核心工作流包括兩個工具,首先我們在中繼者收集到交易包之後使用 ActLifter 工具將交易包中的每一筆 DeFi actions 識別出來,在拿到結果之後,再將這個交易包中所有行為表示出來。 然後用 ActCluster 工具通過聚類的方法將有著相似活動的交易包聚集到一起,通過聚類出來的結果,更快地發現新的 MEV 活動。 如果我們想要發現未知的 MEV 活動,那麼不可避免地需要人工最終確認 MEV 活動是不是一個未知類型,當然我們工作設計的目標盡可能的讓人工工作量最小化的,並且讓整個過程是盡可能自動化地開展。
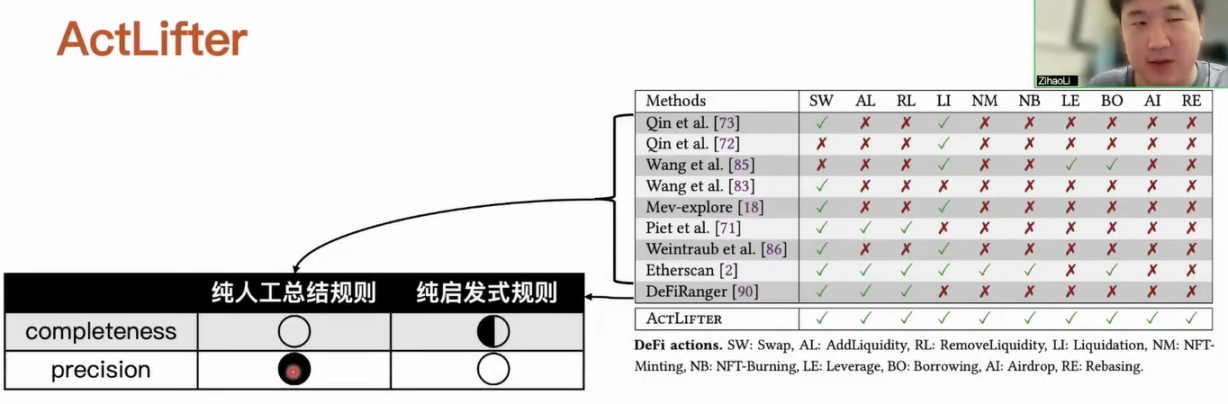
目前已經有一些工具可以從交易中識別 MEV 活動。 我們可以粗略分為兩類,第一類是純人工總結規則; 第二類是純啟發式規則,也就是用一個純自動化的啟發式規則識別特定類型的 MEV 活動。 例如它識別到目前的一些轉帳信息之後,檢查有沒有滿足啟發式規則,如果滿足之後,就能夠識別到對應的活動。 第一種純人工總結規則的方法能達到比較好的精度,因為這個過程完全是人工分析特定的應用,然後它可以保證檢測結果是準確的,但是分析任務需要涉及到非常大的工作量,所以不能覆蓋到各個 DeFi 應用。 第二個工作雖然說可以實現純自動化,但是啟發式規則也只能覆蓋到一些特定類型。 另一方面啟發式規則在設計上是有些問題的,導致它的識別精度不能讓人滿意。
我們綜合兩類方法的優點設計了我們工作流程。 我們可以識別到十種目前比較主要的 DeFi action。 我們只需要人工確定出來 DeFi 應用裡面哪一個事件在發起之後是對應著哪一個類型 DeFi action 之後,我們就可以不需要人工分析,後面就可以完全交給自動化分析。 第二類方法可以完全自動化識別到 DeFi action,但是它不能確定分析的物件是和 MEV 活動相關的。 比如說我們識別到 SWAP 轉帳,它可能會將兩個完全不相關的轉帳組合去識別成一個 DeFi action,自然它識別的結果是錯誤的。 但我們可以藉助這個資訊去篩選出來真正和 DeFi action 相關的資訊。 而拿到這些資訊之後,我們可以通過自動化方法規避掉像第二類方法中發生的一些錯誤情況。
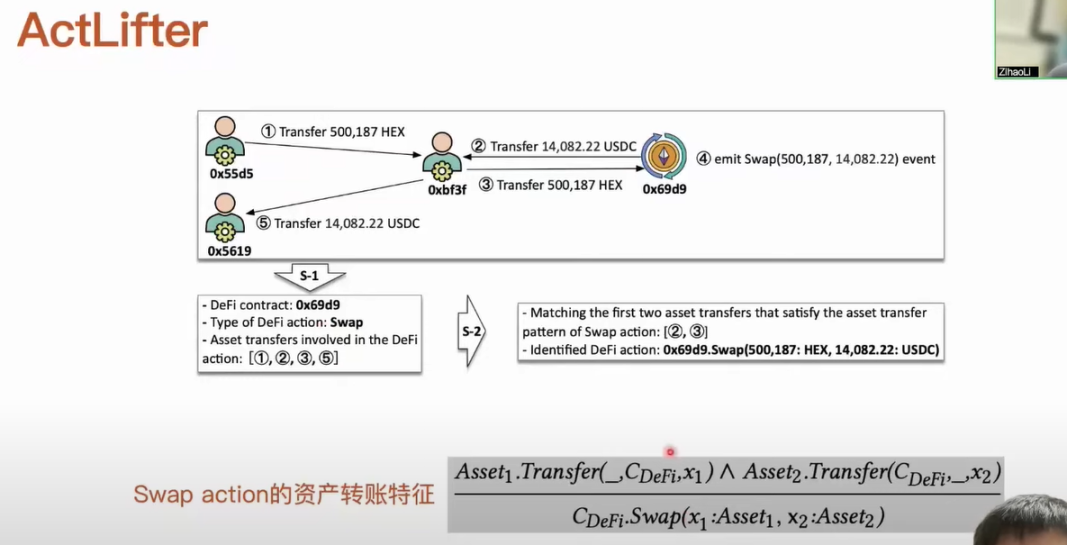
比如這裡有一筆交易一共涉及到了四筆轉帳,它們的發生順序、資金數量和類別等用序號標示出來。 在這個過程中,AMM 其實是發起了一個和 Swap action 相關的事件。 第一類方法在確定到這個事件發起之後,它要通過事件的一些參數來恢復出來當前的內容。 例如它需要看 699 合約的代碼、業務邏輯和一些函數變數恢復出來當前的內容。 我們在拿到這些資訊之後,針對它特有的資產轉帳特徵設計了一個規則,比如說我們提煉的規則就是當前操作 DeFi 的合約是有收到和轉出不同類型資產,當我們發現有兩筆這樣的資產轉帳是符合這樣的特徵之後,我們就可以恢復出來對應的一個 Swap action 內容。 第二類方法就直接去匹配兩筆資產轉帳,這兩筆資產轉帳帳戶是收到和轉出了不同類型的資產。 第一筆和第五筆這兩筆轉帳它就會認為是一對相關的轉帳,並且認為中間的帳戶是一個 AMM,顯然我們可以很直觀看到識別結果是不準確的。
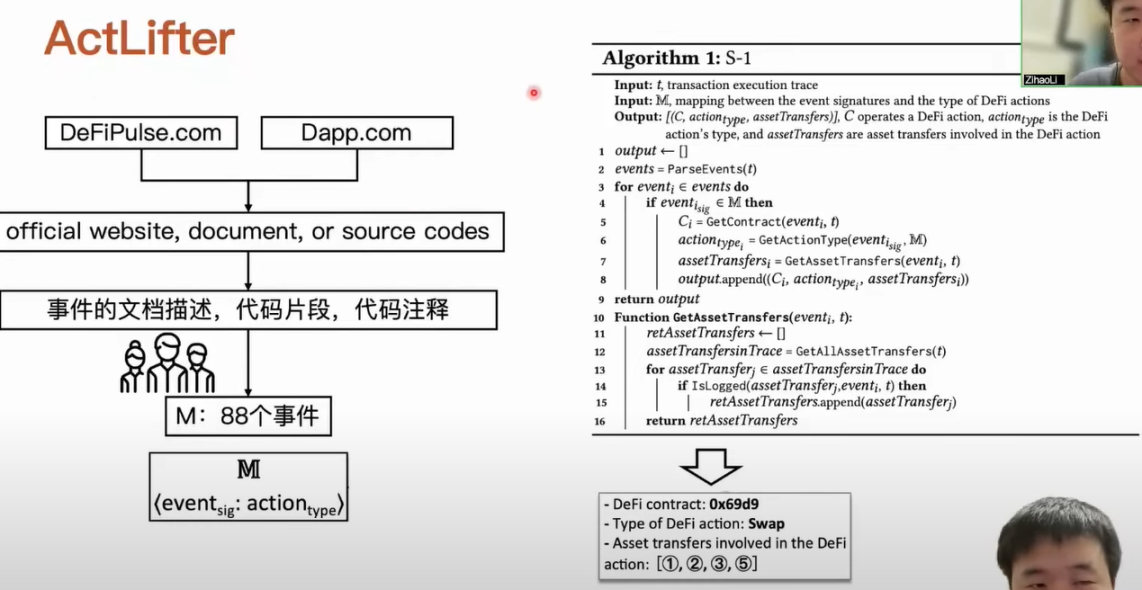
我们通过人工分析总结出来的规则是相关事件对应的 DeFi action 类型的,虽然说结果是通过人工分析总结出来的,但是我们还是尽量把人工分析的过程提炼成一个半自动化的过程,从而确保我们整个过程的可靠性。我们会从 DeFiPulse.com 和 Dapp.com 官网查询 DeFi 应用的官网、开发者文档,包括一些合约源码。我们开发解析工具能够从这些涉及到的材料中提取出关于事件在文档中的一些描述,例如这个事件是怎么用代币定义的以及在哪些函数里面,这些事件被使用的代码片段和代码注释。我们把这些东西提取之后,通过我们人工分析加讨论,最后确定出来有 88 个事件分别对应着不同类型的 DeFi action。
我们将待分析的交易输入这个字典当中,从交易中解析它发生了哪些事件。然后当事件在这个字典中出现之后,我们根据相应的规则提取出关键信息,例如是哪个合约在操作这个 DeFi action,然后这个 DeFi 的类型是什么,以及哪些资产转账是和这个 DeFi action 相关的。在拿到这样的内容之后,我们会对应总结出来资产转账的特征规则,然后用这个规则匹配最终的 DeFi action。我们从十个 DeFi action 定义出发,将资产转账的特征规则做了总结。我们在前一步收集到这些信息之后,我们会用这些匹配规则进行匹配,最终帮助我们识别到这个交易中有哪些 DeFi 发生了哪些具体内容。在 ActCluster 识别出来交易包中的每一笔交易之后,我们就可以表示出交易包的行为。
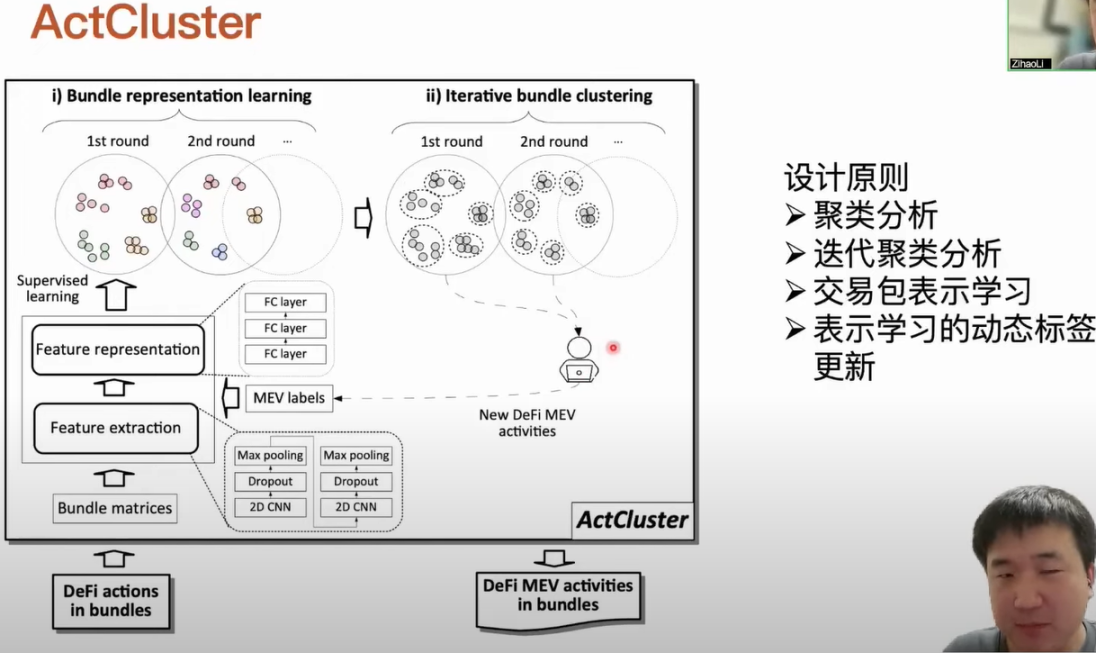
我们先了解一下 ActCluster 设计原则。我们知道人工分析在这个过程中是不可避免的,它必须要依赖人工才能确定出来交易包的活动是不是一个未知类型的 MEV 活动。基于这点,我们的基本思路是通过聚类的方式,将一些活动相似的一些交易包聚到一起。对于每个聚类,我们只需要随机抽样一个或者是几个交易包分析,就能加速人工分析的过程,最终发现不同类型的 MEA 活动。我们使用聚类分析对交易包进行聚类时,会面临一个两难的问题。当我们把交易包的聚类力度设置的比较粗时,包含着不同类型活动的交易包会被聚到一起,这个时候虽然说聚类出来的数量是变少了,相应的人工分析任务也是变少了,但是有一些新的 MEV 活动会被漏掉。假如说我们把聚类的力度调的比较细的话,虽然说我们能区分出来一些相似但是不同的 MEA 活动对应的交易包,但是相关涉及到的人工分析的工作量大大增加了。
基于这样的一个问题,我们设计了迭代聚类分析的方法,它会多轮迭代地进行聚类分析。每一轮我们会把包含着已知的前几轮发现了新 MEV 活动交易包剔除出去,然后对接下来剩下的交易包提升聚类的力度。我们不能直接使用传统的聚类方法对交易包进行聚类的,因为交易包其实是包含着多笔交易,而一笔交易里面又可以包含着多个 DeFi action。整个交易包我们如果把它表示出来,它的结构其实是异构,是分层的。这个时候我们就用了表示学习的方法将这个交易包的内容表示到一个定位空间里面。我们使用表示学习的优点就是我们不需要对我们要分析处理的数据进行深度学习和理解,也不需要很丰富的领域知识,我们只需要单纯的做数据导向处理就可以了。
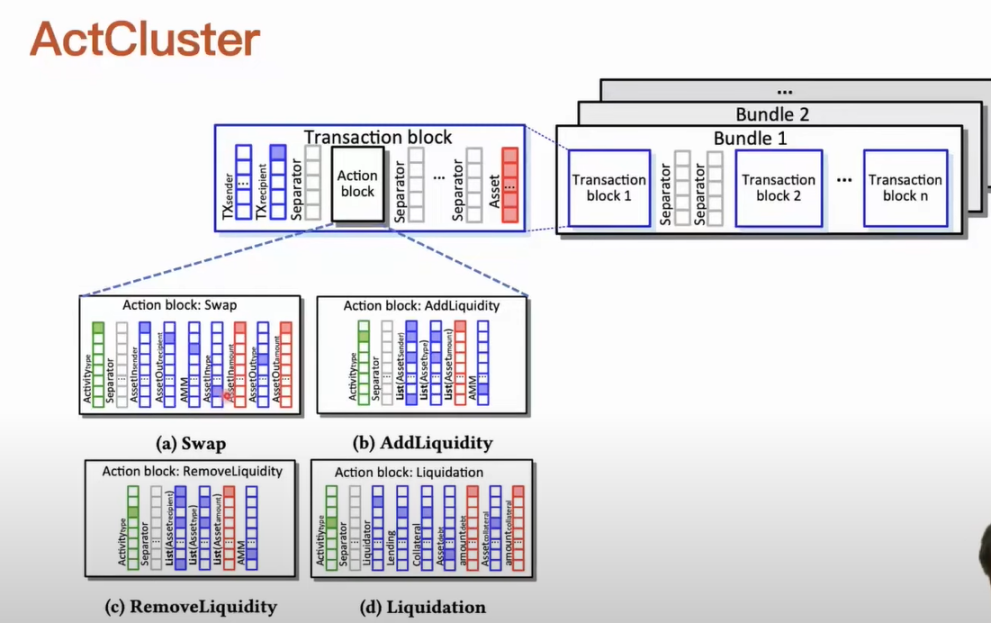
比如说我们只需要对交易包用标签标注一下交易包里面包含哪些 MEV 活动。如果知道一个 MEV 活动定义的话,我们是比较容易设计相应的规则,能够自动化的检测出来它有没有存在。我们可以自动化对这些要表示学习的交易包进行标签标注。我们的聚类分析是一个迭代类型的,而在每次迭代之后,我们可以发现新的 MEV 活动,这个时候我们其实是可以将这些新发现的 MEV 活动对应的标签丰富到我们表示学习的过程中。当我们表示学习过程中使用的标签被丰富的时候,整个表示学习模型训练的性能和效率是可以迭代提升的,而且这个表示学习对交易包的活动表示能力也可以迭代提高。一个交易包里面其实是可以有多笔交易的,而一笔交易里面其实也是可以有多笔 DeFi action 的,我们需要将交易包需表示出来。首先对于每一类的 DeFi action,我们定义出一个标准化参数,比如哪个合约在操作在进行的,然后收到的和转出的资产的数量和类型是什么?我们通过这种方式去定义出每种 DeFi action。如果我们识别到一个交易里面有多个 DeFi action,我们将它们用 action block 表示出来,从而能够将这个交易对应的 transaction block 表示出来,包含着交易的源信息,比如这个交易谁发起的,这个转向又是发给谁的等。交易里面发生 DeFi action,我们会按照顺序去用 action block 做填充。其中的每一笔交易用 transaction block 做一个表示,最后我们获得的交易包的结构,而这个可以认为是一个矩阵。在这个交易包表示出来之后,我们就可以拿去做表示学习。每个交易包是一个统一结构,然后我们就可以用模型进行批量处理了。
性能评估
接下来分享我们用了哪些方法来评估工作流性能。我们整个分析过程的数据集是通过 Flashbots 提供的 API,并且收集了 2021 年 2 月到 2022 年 12 月的交易包数据,包括了超过 600 万个交易包以及 2600 万个交易。
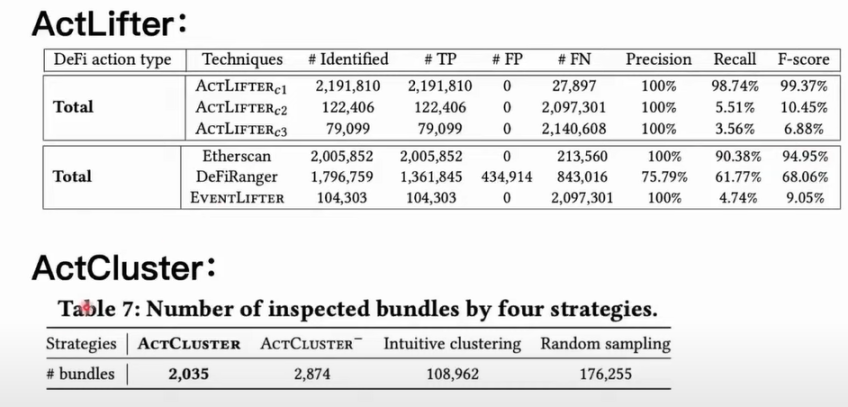
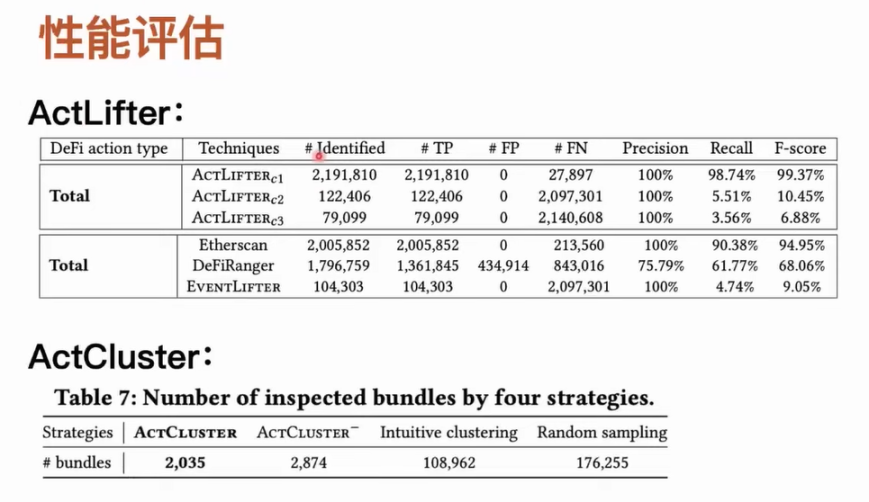
我们设计了一些工具用来比较 DeFi action 的精度和完整度。这里需要注意的是,在这些链上工具里面,目前只有 Etherscan 可以通过它的网页和它的提供的信息恢复出来交易里面的 DeFi action。而像 DeFiRanger,我们是根据他们的论文复现出来他们的方法。在此之外,我们设计了一个叫做 EventLifter 工具,尝试直接从交易事件去恢复出来 DeFi action。我们在不同的配置下测试了 ActLifter,同时用了多样工具去比较识别的精度。对于 ActCluster 来说,我们主要思路是采用消融学习的方式,我们对于能够识别到的新活动,在消融掉 ActCluster 一部分模块之后,我们如果还想识别到没有发现的一些新活动,我们需要人工分析多少交易包或者说我们人工分析的工作量是有多大。比如我们对 ActCluster 表示学习模块中的动态标签更新做了一个消融,我们其实就是把整个过程消融掉了。我们从 600 万个交易包中去随机抽样,然后看我们要人工分析多少个交易包才能发现同样数量的新 MEV 活动。

我们的工具在配置统一的情况下是能够达到接近百分之百的精度和完整度。但是像其他工具如 Etherscan 虽然它的精度能达到百分之百这比较满意的情况,但是会有漏掉非常多的 DeFi action。Etherscan 本身是没有开源方法的,我们推测它可能是用人工分析的方法总结规则来识别 DeFi action,它相应的会漏掉一些人工无法覆盖到的类型。这里需要注意一点 Etherscan 其实是没有提供自动化接口,如果你想去做大规模识别,其实是不能直接完成这样的任务。完全使用潜规则识别的 DeFiRanger 在精度和完整度上不能让人满意。我们对 ActCluster 做实验之后,发现可以通过四轮迭代分析,一共只需要分析 2000 个交易包就可以找出来 17 个未知 MEV 活动。像我们将其中的一些模块进行消融之后,我们最多可能需要人工分析 17 万个交易包,才能把刚刚提到的 17 种未知 MEV 活动识别出来。
实证分析和应用
我们这样能够识别到未知类型 MEV 活动的方法有哪些具体的应用呢?第一它是否能够增强当前存在的 MEV 缓解措施,能够去防御一些 MEV 活动。第二个是利用分析结果,我们是否能够更全面的分析 MEV 活动对区块链生态的影响,包括对区块林分叉重组和用户金融安全的影响。
我们前面有提到过 MEV boost 网络攻击者会运行工具将交易包从用户这里拿到,然后最后分发给连接他们的这些矿工和验证者。中继者会把他们收到的交易包中包含着 MEA 活动的交易包剔除出去,他们通过这样的方式能够减少 MEA 活动对区块链的一些负面影响。这个环节主要的思路是通过已有的 MEV 活动的定义设计相应的规则去检测交易包里面有没有包含 MEV 活动。显然这些中继者是无法排除掉一些包含未知 MEV 活动的交易包。基于我们的工作流,我们就设计了一个 MEVHunter 工具,这个工具可以把我们检测到的新类型 MEV 活动从交易包里面检测出来。
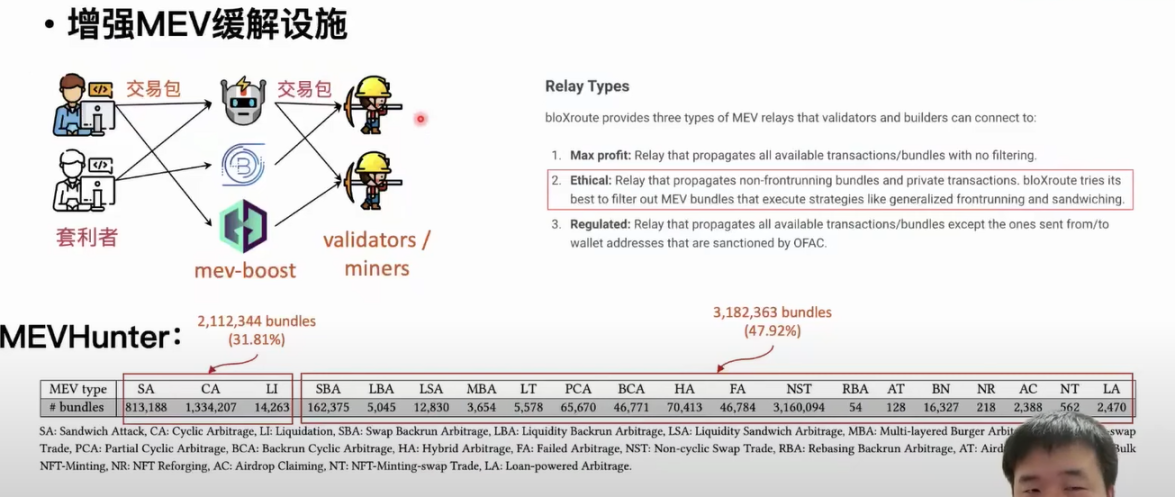
检测结果显示有 100 多万个交易包里面是包含反向套利 MEV 活动的,另外 600 万个交易包里面有 30% 的交易包是包含三种已知的 MEV 活动。对于我们新发现的 MEV 活动,我们发现接近一半的交易包是只包含这些新 MEV 活动的。如果中继器用 MEVHunter 工具的话,可以帮助他们筛选出来 300 万个包含着 MEV 活动的交易包,然后可以选择把这些交易包去剔除出去,降低 MEV 活动对区块链的负面影响。
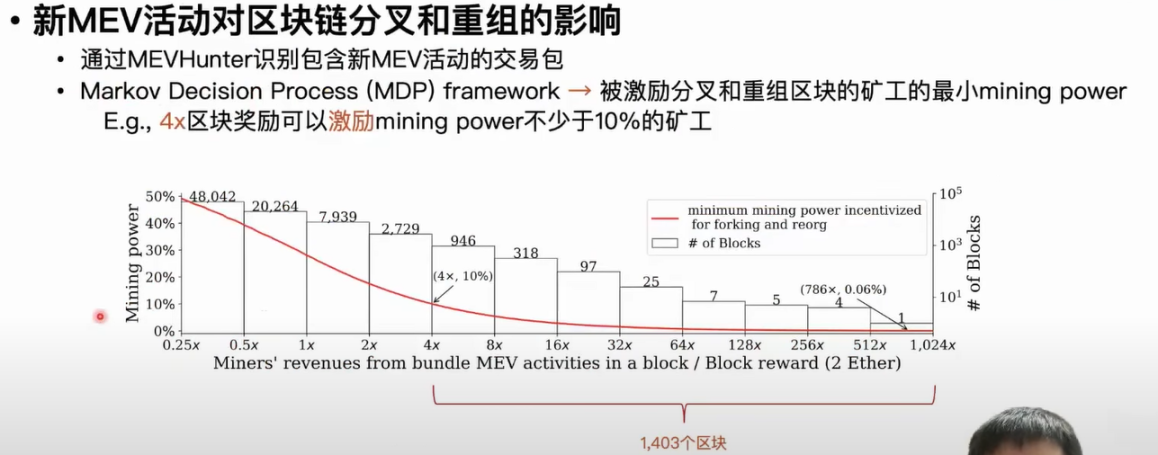
第二个应用是我们去探究新型 MEV 活动对区块链分叉和重组的影响。之前的一些研究有报道说一些金融性的矿工会被一些 MEV 活动的收益所激励,从而去分叉和重组当前的区块链,自己去进行 MEV 活动并享有收益。比如当一个区块的 MEV 活动的收益是区块奖励的 4 倍时,就会有不少于 10% 的矿工对这个区块进行分叉和重组。
我们首先根据刚刚提到的 MEVHunter 工具识别到哪些交易包包含新的 MEV 活动,然后通过这些交易包中矿工的收益去预估这些 MEV 活动相应的强度。这里需要介绍一个概念,在交易包机制里面,这些套利者为了确保自己的套利交易包能够上链,通常会将 MEV 活动收益的一部分分享给矿工,然后矿工最终会选择收益最高的交易包上链。我们用这一笔收益是可以统一预估出来每个交易包中 MEV 活动的。根据我们的统计结果发现 MEV 收益是区块奖励的四倍到八倍的区块一共有 900 多个,另外有一个区块的 MEV 奖励甚至是区块奖励的 700 多倍。我们用马尔科夫决策的框架确定给定一个 MEV 收益,最少能够激励多少矿工进行区块分叉和重组。我们最终发现有 1000 多个区块是可以激励不少于 10% 的矿工去做区块分叉和重组。而像最严重的区块,有不少于万分之六比例的矿工去做区块分叉和重组的。
第三个应用是探究 MEV 活动对区块链用户金融安全的影响。MEV 活动其实是可以导致区块链用户的交易在交易池或者 P2P 网络上等待上链的时间会被延长,这也是 MEV 活动对用户的金融安全主要威胁之一。如果用户的交易被延迟上链了,那么套利者就可以有更多的时间设计更复杂且获利更多的 MEV 活动。第三个应用是比较 MEV 活动对于用户交易最后上链需要等待时间的影响。第一步我们同样是收集交易的等待时间。我们主要是通过在网络上部署节点,然后记录第一次发现在网络上发现这个交易的时间,以及这个交易最终上链的时间,最后算出它需要等待的时间。我们用每个区块中所有交易的等待时间的三个四分位点去做统计,这样我们就可以以每个区块为单位将交易的等待时间整理成一个时间序列。然后对应每个区块里面的 MEV 活动也是用每个区块里面矿工从包含着新 MEV 活动的交易包中获得的收益刻画出来,这样的话我们就拿到了多条时间序列。我们通过格兰杰因果测试评估 MEV 活动对于交易时间的影响,因果测试可以确定一条时间序列里面的波动是否导致另外一条时间序列的波动,以及它在多长范围内影响或者导致了另外时间序列里面的波动。当 MEV 活动发生波动的时候,它是否导致用户的交易的等待时间变长,以及在后续的多少个区块范围内影响是存在的。
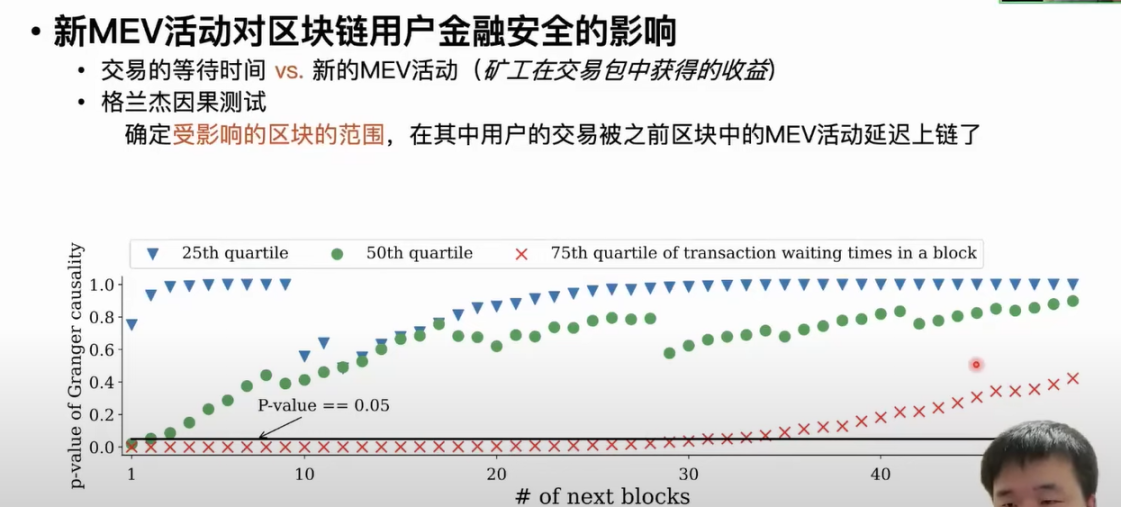
因果測試的 P 值小於等於 0.05 時,意味著這個區塊內的交易等待時間被之前的 MEV 活動影響而延長了。 根據分析結果可以發現當發生 MEV 活動時,後續兩個區塊內 50% 的交易等待時間會被延長。 當 MEV 活動發生之後,接下來 30 個區塊內 25% 的交易等待時間會被延長。 礦工或者驗證者會把 Gas 費比較低的交易放到封裝區塊的尾部,使用者交易 Gas 越低,受到 MEV 活動的影響範圍就會越大,等待時間會被延長的更久。
最後總結,我們首先分享了如何通過工作流找到未知的 MEV 活動,以及工作流中兩個模組的詳細設計,然後我們通過實證分析驗證了工作流的有效性,同時列舉了三個應用。 目前,我們用工作流發現了 17 種新的 MEV 活動。
免責聲明:作為區塊鏈資訊平臺,本站所發佈文章僅代表作者及嘉賓個人觀點,與 Web3Caff 立場無關。 本文內容僅用於資訊分享,均不構成任何投資建議及要約,並請您遵守所在國家或地區的相關法律法規。










