

本文主要介紹了對區塊鏈系統中的延遲和吞吐量的測量,並提供了測量實驗的設計方式和對比系統部署的合理方法
原文:Understanding Blockchain Latency and Throughput(Paradigm)
編譯: EthereumCN
原用標題(譯後):了解區塊鏈延遲和吞吐量
封面: Photo by Pietro Jeng on Unsplash
大家鮮少提到如何正確地測量一個(區塊鏈)系統,但它卻是系統設計和評估過程中最重要的步驟。系統中有許多共識協議、各種性能的變量和對可擴展性的權衡。
然而,直到目前都沒有一種所有人都認同的可靠方法,能夠讓人進行蘋果對比蘋果這種同一範疇內的合理比較。在本文,我們將概述受到數據中心化系統測量機制啟發的一種方法,並探討在評估一個區塊鏈系統時可以避免的一些常見錯誤。
關鍵指標及其相互作用
在開發區塊鏈系統時,我們應該將兩個重要指標考量在內:延遲和吞吐量。
用戶關心的第一件事就是交易延遲,即發起交易或支付和收到確認交易有效性信息(比如,確認交易發起方有足夠的錢)之間的時間。
在傳統的 BFT 系統中(如 PBFT、Terdermint、Tusk 和 Narwhal 等),一旦交易被確認就會被敲定,而最長鏈共識機制(如 Nakamoto Consensus、Solana/Ethereum PoS)中,一筆交易可能會被打包進區塊,然後再重組。結果就是,我們需要一直等到交易達到 “k 個區塊深” 了才能進行敲定,這就導致了延遲的時間大大超過了單次確認的時間。
其次,系統的吞吐量一般對於系統設計者來說十分重要。這就是系統每單位時間所處理的總負載,一般表達為每秒交易量 (TPS)。
乍一看,這兩個關鍵指標看起來是完全相反的東西。但因為吞吐量由每秒的交易量得出,而延遲則是以秒為單位進行測量。自然而然地,我們會認為吞吐量= 負載/延遲。
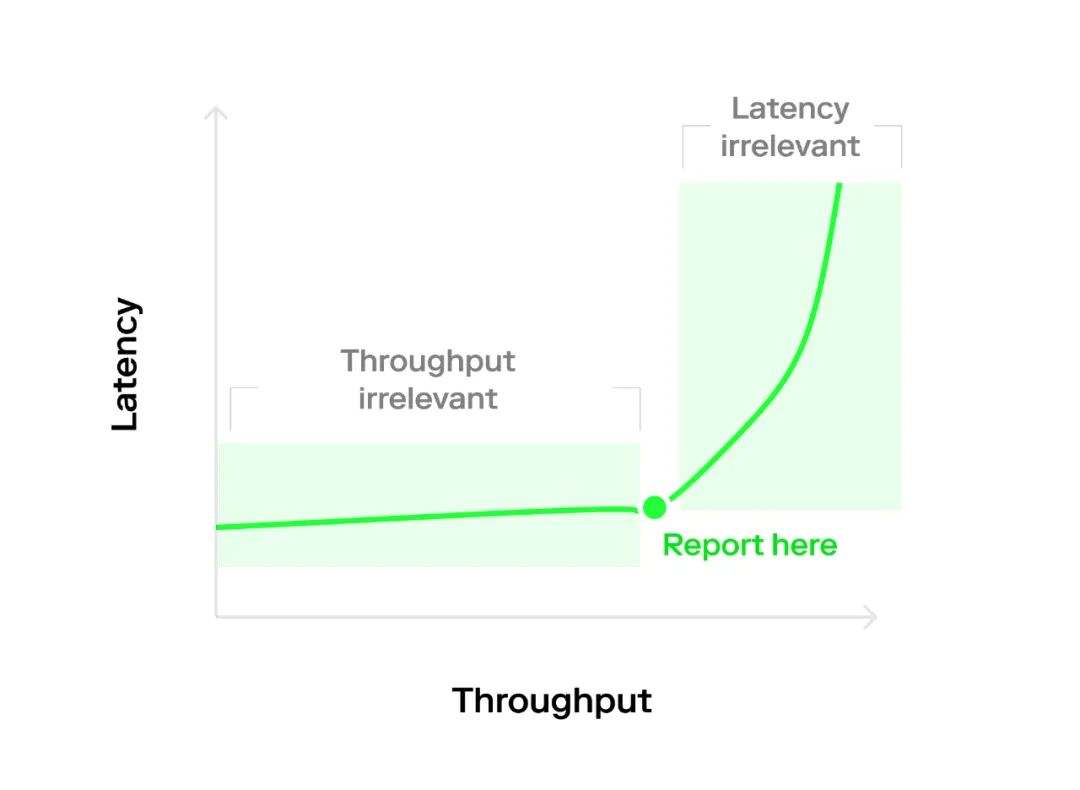
但事實並非如此。因為許多系統傾向於生成在 y 軸上展示吞吐量或延遲,而在 x 軸上展示節點數量的圖表,所以這種計算方式的實現是不可能的。相反,我們能生成一個更好的、包含吞吐量/延遲指標的圖表,它以非線性的方式呈現讓圖表清晰易讀。

當沒有競爭時,延遲是恆定的,僅是改變系統的負載,就可以改變吞吐量。會發生這種情況,是因為低競爭情況下,發送交易的最小開銷是固定的,且隊列延遲為 0,致使 “無論進來什麼,都能直接出去”。
在競爭激烈的情況下,吞吐量是恆定的,但僅是改變負載就可以讓延遲發生變化。
這是因為系統已經超負載了,而增加更多負載會造成等待隊列無限變長。更反常的是,延遲似乎會隨著實驗長度而發生變化,這是一個無限增長隊列的人為結果。
這些表現都可以在典型的 “曲棍球圖” 或 “L 型圖” 上看到,它取決於到達間隔的分佈(下文會談論到)。因此,這篇文章的關鍵要點是,我們應該在熱區進行測量,這裡的吞吐量和延遲都會影響我們的基準;而不用測量邊緣區域,這裡的吞吐量和延遲只有一個是重要的。
測量方法論
在做實驗時,實驗者有三種主要的設計選項:
開環 vs. 閉環
現在有兩種可以控制對目標發出請求流的主要方法。開環系統基於 n = ∞ 個客戶端進行建模,這些客戶端根據速率λ 和到達間隔分佈(例如 Poisson)向目標發送請求。閉環系統會在任何給定時間內限制未完成請求的數量。開環系統和閉環系統的區別是特定部署的特點,同一個系統可以部署在不同的場景中。
例如,一個鍵值存儲(key-value store)可以在一個開環部署中為數千個應用程序服務器提供服務,或在一個閉環部署中只為幾個阻塞客戶端提供服務。
對正確的部署場景進行測試是必不可少的,因為比起閉環系統的延遲通常受制於潛在的未完成請求數量,而開環系統可能會產生大量的等待隊列,所以,延遲會更長。一般來說,區塊鏈協議可以被任意數量的客戶端使用,所以在開環環境下對其做評估會更準確。
綜合基準測試的到達間隔分佈
在創建合成工作負載時,我們必然會問:如何向系統提交請求?許多系統在測量之前會先預加載事務,但這會使測量產生偏差,因為系統從異常狀態 0 開始運行。此外,預加載的請求已經在主存儲器中,也因此繞過了其網絡堆棧。
更好一些的方法則是以確定的速率發送請求(比如,1000 TPS),這會導致 L 型的圖表(橙線)的出現,因為系統的容量得到了最佳使用。
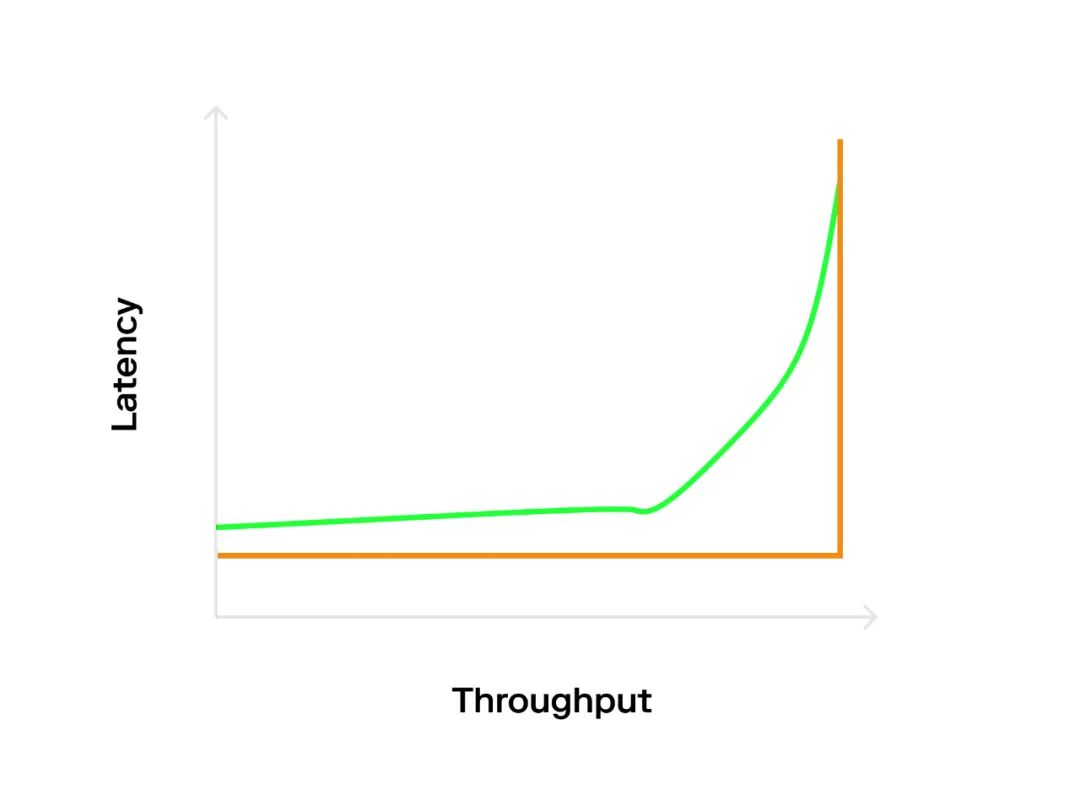
然而,開放系統往往不以可預測的方式運作。相反,它們有處於高負載和低負載的時間段。為了對此進行建模,我們可以採用概率間隔分佈,該分佈一般是基於泊松分佈。它將導致 “曲棍球” 圖表(藍線),因為即使平均速率低於最佳值,泊松爆發也會導致一些排隊延遲(最大容量)。但這對我們十分有利,因為我們可以看到系統如何處理高負載以及負載恢復正常時,系統恢復的速度有多快。
熱身階段
最後要考慮的一點是何時開始測量。我們希望流水線在開始之前充滿事務;否則,將需要測量預熱延遲。理想情況下,預熱延遲的測量應該通過熱身階段中的延遲測量來完成,直到測量結果遵循預期的分佈。
如何進行比較
最後一個難題是合理比較系統的各種部署。同樣,難點在於延遲和吞吐量是相互依賴的,因此我們可能難以生成公平的吞吐量/節點數圖表。
最好的方法是定義服務級別目標 (SLO) 並測量當時的吞吐量,而不是簡單地將每個系統推到其最高吞吐量(這種情況下,延遲毫無意義)。在吞吐量/延遲圖上繪製一條與延遲軸相交 SLO 處的水平線並對相交點進行採樣,這是一種可視化的好方法。
但我設置了 5 秒的 SLO,它只需要 2 秒
有人可能想要增加這裡的負載,以便利用飽和點之後稍高的可用吞吐量。但是這很危險。如果系統操作配置不足,意外的請求爆發將導致系統達到完全飽和,致使延遲激增且很快會違背 SLO。實質上,在飽和點之後運行會導致一種不穩定的平衡。
因此,有兩點需要考慮:
- 過度配置系統。本質上,系統應該在飽和點以下運行,以便吸收到達間隔分佈中的爆發,而不會導致排隊延遲增加。
- 如果 SLO 下方有空間,請增加 batch 的大小。這會增加系統關鍵路徑上的負載,而不會增多排隊延遲,它為你提供更高的吞吐量以獲得你所要的更高延遲權衡。
我正在產生巨大的負載,該如何測量延遲呢?
當系統的負載很高時,嘗試訪問本地時鐘,並為到達系統的每個事務添加時間戳可能會導致結果出現偏差。
相反,還有兩個更可行的選擇。第一種也是最簡單的方法是對事務進行抽樣;例如,在某些事務中可能存在一個魔數(magic number),而這些事務是客戶端為其保留計時器的事務。在提交時間之後,任何人都可以檢查區塊鏈以確定這些事務何時提交,從而計算它們的延遲。這種做法的主要優點是,它不會干擾到達間隔分佈。但是,因為必須修改某些事務,所以它可能被認為是 “hacky(具有攻擊性質的)”。
而更系統的方法則是使用兩個負載生成器。第一個是主要的負載生成器,由它來遵循泊松分佈。第二個請求生成器則用來測量延遲,並且它的負載會低得多;與系統的其餘部分相比,可以將這個請求生成器視為單個客戶端。即使系統向每個請求發送回复(就像某些系統所做的那樣,例如一個鍵值存儲),我們也可以輕鬆地將所有回复放到負載生成器中,並只測量來自請求生成器的延遲。
唯一棘手的部分是,實際的到達間隔分佈是兩個隨機變量的總和;但是,兩個泊松分佈的總和仍然是泊松分佈,所以數學並不難: )。
總結
測量大規模分佈式系統對於識別瓶頸和分析壓力下的預期行為是至關重要的。希望通過使用上述方法,我們都可以朝著公用語言邁出第一步,這最終將讓區塊鏈系統更適用於他們所做的工作以及他們對終端用戶的承諾。
在未來的工作中,我們計劃將此方法應用於現有的共識機制中,如果有興趣,請在 Twitter 上聯繫!
致謝:所有這些都是我在設計和實施 Narwhal & Tusk(最佳論文獎 @ Eurosys 2022)期間與我的合著者吸取的經驗教訓,還有之前 Marios Kogias、Joachim Neu、Georgios Konstantopoulos 和 Dan Robinson 對草稿的評論。
免責聲明:作為區塊鏈信息平台,本站所發布文章僅代表作者及嘉賓個人觀點,與 Web3Caff 立場無關。文章內的信息僅供參考,均不構成任何投資建議及要約,並請您遵守所在國家或地區的相關法律法規。










