

本文介紹了 zk-SNARK 技術的工作原理和難點、多項式以及多項式承諾如何讓 zk-SNARK 的實現更加高效
原文:What kind of layer 3s make sense?(vitalik.ca)
編譯: EthereumCN
封面: Photo by Clever Visuals on Unsplash
特別感謝 Georgios Konstantopoulos、Karl Floersch 以及 Starkware 團隊的反饋和校對。
在 L2 擴容探討中經常會出現的話題是 “layer3(L3)” 這個概念。如果我們可以構建一個錨定 L1 安全性並在其之上增加可擴展性的 L2 協議,那麼我們也一定可以構建一個錨定於 L2 安全性並在其之上增加更多可擴展性的 L3 協議,以此實現更多擴容?
簡要地說,這種觀點是這樣的:如果你擁有一個能夠讓你進行二次方擴容的方案,那你可以將這個方案構建在它自己之上,然後達到指數級的擴容嗎?
我在自己 2015 年的可擴展性論文、Plasma 論文中的多層擴容想法等地方都講到了類似的觀點。不幸的是,這種關於 L3 的簡單構思並不能像上述觀點那樣輕易實現。
這種方案的設計中總是會有一些無法直接堆疊的東西,只能在可擴展性上帶來一次提升—— 因為數據可用性的限制,緊急提款依賴於 L1 寬帶等多種問題。
如 Starkware 提議的框架等較新的關於 L3 觀點變得更複雜:這些 L3 方案不只是在自己的網絡之上堆棧疊相同的方案,而是為 L2 和 L3 分配不同的用途。這種方法的一些形式可能會是好主意—— 如果它能夠以正確的方式實現。本文將會詳細介紹在三層架構下哪些可能有意義,而哪些可能無意義。
(譯者註:上述 StarkWare 文章中文版《分形式擴容:從 L2 到 L3》)
為什麼無法通過將 rollup 堆疊在 rollup 之上一直擴容
rollup(在這裡閱讀關於 rollup 更長的文章。譯者註:鏈接文章中文版《Vitalik:Rollups 不完全指南》) 是結合各種技術解決區塊鏈運行中兩大主要擴展瓶頸的擴容技術:計算和數據。計算可以通過欺詐證明或是 SNARK(譯者註:鏈接文章的中文版在這裡)解決,兩種方式依賴於很少的行動者就能對每個區塊進行處理和驗證,只需要其他參與者運行一小部分的計算來檢查證明過程是否正確完成了。
這些方案尤其是 SNARK 幾乎可以無限地擴展,你真的就可以通過保持構建 “在一個 SNARK 證明之上構建多個 SNARK 證明”,為單個證明擴展更多算力。
數據則不同。rollup 使用許多壓縮技巧來減少一筆交易在鏈上存儲所需的數據量:一筆簡單的貨幣轉賬從大約 100 字節減至大約 16 字節,兼容 EVM 的鏈上的一筆 ERC-20 代幣轉賬從大約 180 字節減至 23 字節左右,而一筆保護隱私的 ZK-SNARK 交易可以從 600 字節左右壓縮至 80 字節左右。
基本所有情況下的數據都能壓縮至原來的 1/8。但是,rollup 還是需要在某一中介上讓數據具有鏈上可用性,保證用戶能夠進行訪問和驗證,因此,用戶可以自主地計算 rollup 的狀態,並在現有證明生成者下線的情況下作為證明生成者加入證明過程。
數據只能壓縮一次,無法再次壓縮—— 如果數據可以再次壓縮,那麼通常有一種方式將第二個壓縮器的邏輯放入第一個的邏輯中,只要壓縮一次就能讓第二個壓縮器或跟第一個壓縮器相同的效果。所以說,事實上 “在 rollup 之上構建 rollup” 並不能在可擴展性方面提供巨大的收益—— 不過,這種模式可以用於其他的用途,正如下面我們將看到的一樣。
所以 “合理的” L3 版本是什麼樣的?
好吧,讓我們一起看看 StarkWare 在關於 L3 的文章中倡導的是什麼(譯者註:該文章的中文版在上面)。StarkWare 團隊由非常聰明且實際上理智的加密學家所組成,所以如果他們倡導 L3,那麼他們的觀點會比 “如果 rollup 的數據壓縮至 1/8,那麼很明顯,構建於 rollup 之上的 rollup 會將數據壓縮為原來的 1/64” 的觀點更為複雜。
這是 StarkWare 文章中的圖表:
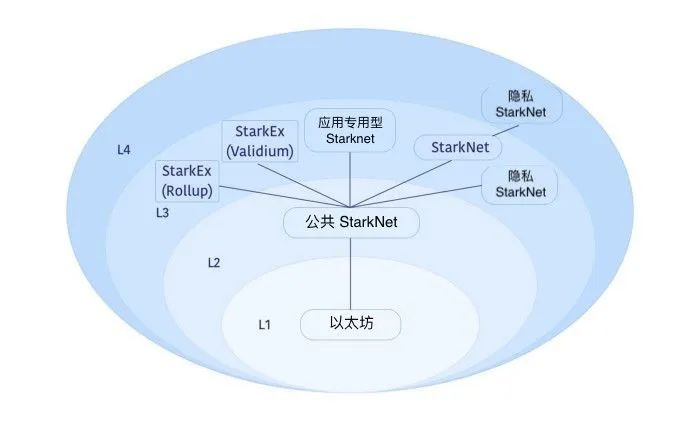
以下是一些引用:
第一張示例圖中描述了這樣一種生態系統的例子,其 L3 包括:
● 使用 Validium 數據可用性方案的 StarkNet,比如,為定價上具有極度敏感性的應用程序提供多種用途。
● 應用專用型 StarkNet 系統可以定制更好的應用程序性能,比如,通過採用指定的存儲結構或數據可用性壓縮方式。
● 使用 Validium 或 Rollup 數據可用性解決方案的 StarkEx 系統(比如那些服務於 dYdX、Sorare、Immutable 和 DeversiFi 的系統),會很快地為 StarkNet 帶來經過長期考驗的可擴展性效果。
● 隱私 StarkNet 的例子(在這個例子中也作為 L4)可以在不將交易打包至公共 StarkNet 的情況下進行隱私保護交易。
我們可以將這篇文章壓縮為 “L3s” 的三個願景:
- L2 用於擴容,L3 用於定制功能,如隱私。這個願景的 L3 無意於提供 “可擴展性平方”;不如說,會有一層堆棧幫助應用程序進行擴展,然後還有一些獨立的堆棧層用於滿足不同用例定制功能的需求。
- L2 用於通用型擴容,L3 用於定制型擴容。定制型擴容可能會有不同的形式:專用型應用可以使用 EVM 以外其他虛擬機來進行計算, rollup 的數據壓縮也會圍繞定制型應用程序的數據結構進行優化(包括將 “數據” 從 “證明” 中分離出來,並使用每個區塊中的單個 SNARK 完全替換掉這個區塊中所有的交易證明)。
- L2 用於去信任擴容(如 rollup),L3 用於弱信任擴容(如 Validium)。Validiums 指使用 SNARK 驗證計算結果的系統,但是它將數據可用性放在了受信任的第三方或委員會處。在我看來,Validium 被大大低估了:尤其是,運行 Validium 證明生成器並定期提交哈希上鍊的中心化服務器也許真的可以很好地服務於許多 “企業區塊鏈” 應用程序。Validium 的安全性指數比 rollup 低,但是相較之下便宜很多。
在我看來,這三種願景本質上是合理的。“專用型/定制型數據壓縮服務需要有自己的平台” 的想法可能是所有主張中最不能令人信服的—— 設計一個通用型基礎層壓縮方案 L2 很容易,因為用戶可以使用應用專用型的子壓縮器進行擴展—— 而除此之外的用例都是合理的。但這還是留下了很大的疑問:三層結構是實現這些目標的正確方式嗎?將 Validium、隱私系統和定制型環境錨定 L2 而不僅僅錨定 L1 的意義在哪?這個疑問的答案很複雜。
哪一個更好?
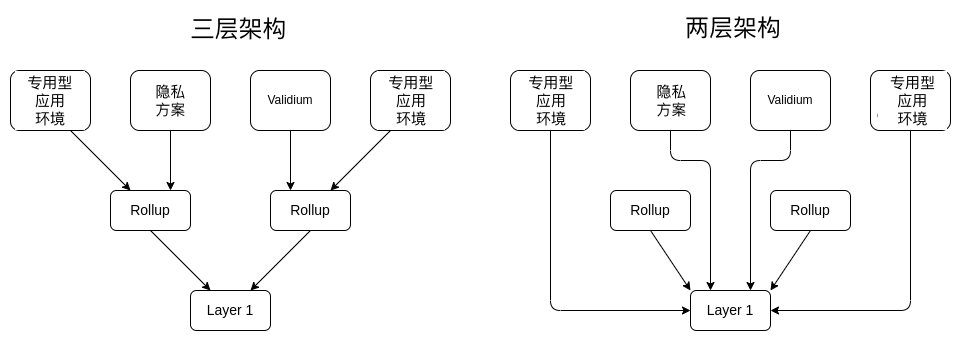
存款和提款在 L2 的子樹(sub-tree)中會變得更便宜、更容易嗎?
這種三層模型優於兩層模型的一個論證可能是:三層模型允許整個子生態系統存在於單個 rollup 中,這讓生態系統內的跨域操作可以非常便宜地進行,不需要經由昂貴的 L1。
但事實證明,即使是向同一個 L1 提交數據的兩個 L2(甚至 L3)之間,存款和提款也可以很便宜!關鍵是要意識到,代幣和其他資產不一定非得在底部鏈中發行。換句話說,你可以在 Arbitrum 上持有一種 ERC20 代幣,然後在 Optimism 上創建它的封裝合約,並在兩者之間來迴轉移資產而無需創建任何 L1 交易!
讓我們來看看這樣一個系統如何進行運作。現在有兩種智能合約:Arbitrum 上的基礎合約和 Optimism 上的代幣封裝合約。要從 Arbitrum 轉移資產到 Optimism,你需要將代幣發送到基礎合約,這會生成一個收據。一旦 Arbitrum 敲定了這筆交易,你就可以獲取該收據的 Merkle 證明,它植根於 L1 狀態,並將其發送到 Optimism 上的代幣封裝合約中。封裝合約會對它進行驗證並向你發放封裝代幣。要將代幣往迴轉移的話,則可以反向執行相同的操作。
儘管證明 Arbitrum 存款所需的 Merkle 路徑會檢查 L1 的狀態,但 Optimism 只需要讀取 L1 狀態根以處理存款—— 不需要創建 L1 交易。請注意,由於 rollup 數據是最稀缺的資源,所以此類方案的可行實現將是使用 SNARK 或 KZG 證明以節省空間,而不是直接使用 Merkle 證明。
對比根植於 L1 的代幣,這種方案有一個關鍵的弱點,至少在 optimistic rollup 上有這樣的問題:存款也需要等待欺詐證明的窗口期到來。如果代幣是在 L1 上的,那麼從 Arbitrum 或 Optimism 上往 L1 的提款則需要一周的延遲時間,而存款則是即時的。
然而,這種方案中的存款和提款都需要一周時間。也就是說,尚不清楚 optimistic rollup 上三層架構是否會更好:因為要確保欺詐證明博弈會在一個自己運行欺詐證明機制的系統內安全地進行,這存在很多技術上的複雜性。
幸運的是,這些問題都不會在 ZK rollup 上出現。出於安全方面的原因,ZK rollup 不會要求一周時長的等待窗口,但他們確實還會有較短窗口期的要求(第一代技術可能需要 12 個小時的等待期)。
原因有二,首先,特別是更複雜的通用型 ZK-EVM rollup 需要較長的時間來囊括區塊證明過程中的不可並行計算時間;其次,這其中還有經濟考量:需要不那麼頻繁地提交證明以最大程度減少證明交易相關的固定開銷。包括專用型硬件在內的下一代 ZK-EVM 技術將會解決上述的第一個問題,而架構更好的 batch 驗證技術可以解決第二個問題。這其實是我們接下來會討論的優化和批量提交證明的問題。
rollup 和 validium 的確認期 vs. 固定開銷權衡。L3 們可以幫忙解決這個問題,但還有哪些方案可以幫忙解決?
rollup 每筆交易的開銷很便宜:只有 16 - 60 字節的數據,這取決於所使用的應用程序。但是 rollup 也必須在每次提交一個 batch 的交易至鏈上時支出一筆高昂的固定開銷:optimistic rollup 的每 batch 要支付 21000 L1 gas,而 ZK rollup 則要支付 400,000 gas 以上(如果你只想使用 STARK 這種量子安全的技術,可能會需要支付上百萬 gas)。
當然,rollup 可以選擇等著,直到有了價值 1 千萬 gas 的 L2 交易再打包提交 batch ,但這會讓 rollup 的 batch 間隔變得很長,迫使用戶在獲得高安全性確認之前等待更長的時間。因此,它們會有權衡:長時間的 batch 間隔和最優開銷,或者說較短的 batch 間隔和大大增加的開銷。
為了給出一些具體的數據,讓我們一起探討這樣一個 ZK rollup:它每 batch 開銷 600,000 gas,能處理完全優化過的 ERC-20 轉賬(23 字節),每筆交易會花費 368 gas。假設這種 rollup 在採用的早期和中期階段的平均每秒交易(TPS)為 5 筆。我們可以計算它的每筆交易的 gas vs. batch 間隔:
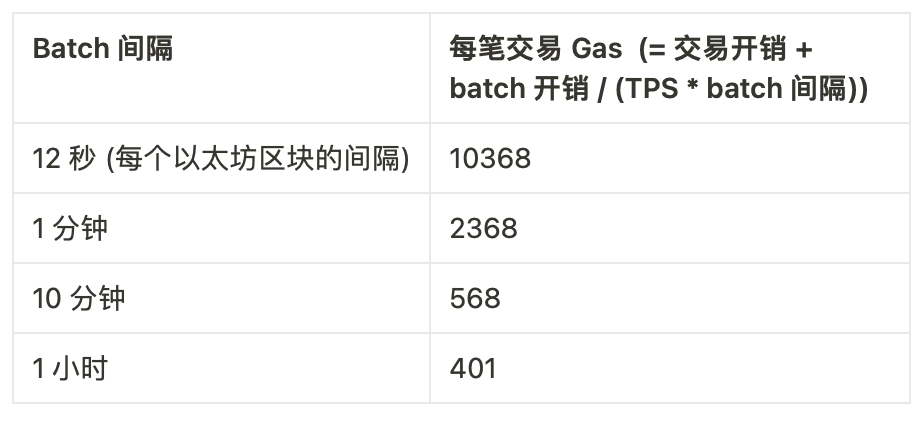
如果我們進入一個有著許多定制型 validium 和應用專用型環境的系統,那麼它們中的大多數都不會處理超過 5 TPS。所以,在確認時間和開銷之間的權衡開始變得至關重要。而實際上,“L3” 範式確實可以解決權衡上的問題!就算是以簡單的方式實現,一個 ZK rollup 套著另一個 ZK rollup 的方案也大約會有僅 8000 L1 gas 左右的固定開銷(證明佔 500 字節)。這就將上面的表格改為:
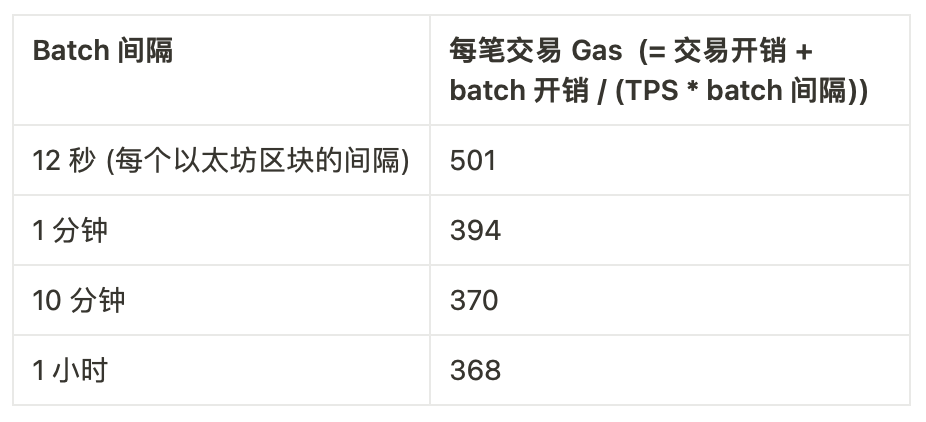
開銷的問題基本上都解決了。那麼,L3 是不是有益的?可能吧。但值得注意的是,還有一種可以解決這個問題的方法,這個方法受到了 ERC 4337 聚合驗證的啟發。
其對策如下。現在,如果每一個 ZK rollup 或 validium 收到了證明 S new=STF(S old,D) 的證明,即新的狀態肯定是正確處理了交易數據或舊狀態根上狀態變換的結果,那它們就會接收狀態根。
在這個新的方案中,ZK rollup 會從 batch 驗證器合約處接收消息,這個消息用於告知該驗證器已驗證了一個包含聲明的 batch 證明,其中的每個聲明都是 S new=STF(S old,D) 的形式。該 batch 證明可以通過遞歸 SNARK 方案或是 Halo 聚合進行構造。
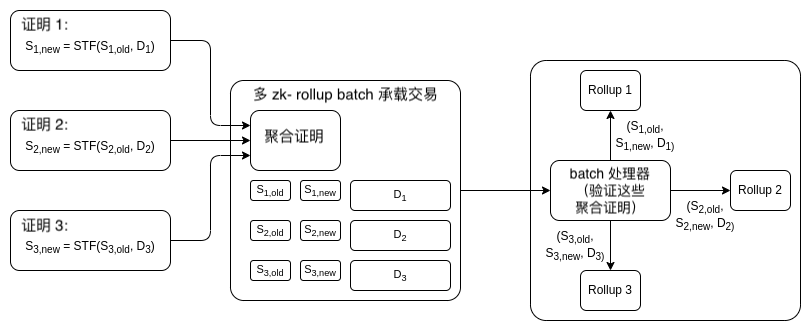
這是一個開放協議:任何 ZK-rollup 都可以加入,任何 batch 的證明生成者都可以從任何兼容的 ZK-rollup 中聚合證明,並從聚合器處獲得交易費的補償。batch 處理器合約會驗證一次證明,接著將包含該 rollup $(S_{old},S_{new},D)$ 三元組(triple)的消息傳遞至每一個 rollup;三元組來自 batch 處理器合約的事實會是交易有效性的證據。
如果優化得不錯,那麼這個方案中每個 rollup 的開銷則將近 8000 gas:5000 用於寫入新添加的更新狀態,1280 用於舊狀態根和新狀態根,還有剩下的 1720 用於有效利用各種數據。所以說,這種方案也能節省開銷。
StarkWare 實際上已經有了類似的方案,叫做 SHARP,儘管它還不是一個無需許可的開放協議。
對於這類方法的反應可能會是:但這不就是另一種 L3 方案嗎?比起 base layer <- rollup <- validium(基礎層← rollup ← validium)結構,你有 base layer <- batch mechanism <- rollup or validium(基礎層← batch 機制← rollup 或 validium)。
從一些哲學的建築角度來看,這可能是事實。但這裡有一個重要的區別:比起將中間層作為複雜完整的 EVM 系統,還不如說它是簡化且高度專業化的對象,所以它更可能是安全的,也更可能在還完全不需要其他專門的代幣的情況下構建起來,還更可能實現治理最小化且不會隨著時間改變。
總結:實際上什麼是 “層”?
在其自身網絡之上的堆疊相同擴容方案的三層擴容架構通常無法很好地運作。構建於 rollup 之上的 rollup,這兩層 rollup 當然不會使用相同的技術。
但是,可以使用第二層和第三層具有不同用途的三層架構。構建於 rollup 之上的 Validium 確實是有意義的,即使無法確定它們是否會是長期的最佳運作方式。
然而,一旦開始深入了解哪種架構有意義,我們就會陷入哲學問題:什麼是 “層”,什麼不是?base layer <- batch mechanism <- rollup or validium(基礎層← batch 機制← rollup 或 validium)模式與 base layer <- rollup <- rollup or validium(基礎層← rollup ← rollup 或 validium)模式執行著相同的工作。
但在工作方式方面,證明聚合層看起來更像是 ERC-4337,而不是 rollup。通常,我們不會將 ERC-4337 稱為 “L2”。同樣,我們不會將 Tornado Cash 稱為 “第 2 層” —— 所以如果要保持歸類上的一致,我們不會將構建於 L2 之上的以隱私為中心的子系統稱為第 3 層。因此,關於什麼對象應該首先被稱為 “層”,這存在一個未解決的語義爭論。
關於這個問題,可能有很多思想流派的不同看法。我個人偏向則會是保持 L2 這個術語限定於具有以下特點的事物:
- 其用途在於增加可擴展性
- 它們遵循著 “處於一條區塊鏈中的區塊鏈” 模式:它們有自己處理交易和內部狀態的機制
- 它們完全繼承了以太坊區塊鏈的安全性
所以,optimistic rollup 和 ZK rollup 是 L2,但是 validium、證明聚合方案、ERC-4337、鏈上隱私系統和 Solidity 則屬於其他方案。可能把這些方案中的一部分稱為 L3 是說得通的,但也許不能全都稱作 L3;任何情況下,在多 rollup 生態系統的架構確定下來之前就為其下定義可能為時過早了,而大部分討論也只是在理論上。
也就是說,語言上的爭論遠不如 “哪個結構實際上最有意義” 這種技術問題來得重要。顯然,服務於隱私等非擴容需求的某種 “層” 可以發揮重要作用,並且顯然需要以某種方式填補重要的證明聚合功能,最好由開放協議來填充這個位置。
但與此同時,我們有充分的技術理由,讓連接著面向用戶的環境和 L1 之間的中間層盡可能變得簡便;在許多情況下,將 “粘合層” 作為 EVM rollup 可能不是正確的運作方法。隨著 L2 擴容生態系統的成熟,我猜本文中描述的更複雜(和更簡單)的結構將開始發揮更大的作用。
免責聲明:作為區塊鏈信息平台,本站所發布文章僅代表作者及嘉賓個人觀點,與 Web3Caff 立場無關。文章內的信息僅供參考,均不構成任何投資建議及要約,並請您遵守所在國家或地區的相關法律法規。










