

在本文中,Vitalik 對上述眾多涉及可擴充性相關技術路線的歷史研究、最新研發進展進行了承上啟下的總結與分析,並補充闡述新的技術條件下無信任(trustless)、L1 原生 rollups 等新可能性。
原文:Possible futures of the Ethereum protocol, part 2: The Surge(vitalik.eth)
作者:vitalik.eth
編譯:183Aaros,Yewlne,LXDAO
譯者的話
“打破可擴展性三難困境非常困難,但並非不可能,它需要以某種方式跳出論證所暗示的思維定式。” —— Vitalik Buterin。
為了可擴展性三難困境(scalability trilemma),乙太坊在各歷史時期有著眾多技術設想與嘗試,從狀態通道(state channels)、分片(sharding),到 rollups、Plasma,再到現如今生態裡共同聚焦的大規模 “數據可用性(data availability)”。 直至 2023 年 The Surge 路線圖,乙太坊才選擇了這條遵 “以 L1 的魯棒性與去中心化為中心,多元化(pluralistic)L2s 多樣發展”、或許能超越三難困境的技術哲學道路。 作為前文《乙太坊協定可能的未來(一):The Merge》的續篇,在本文中,Vitalik 對上述眾多涉及可擴展性相關技術路線的歷史研究、最新研發進展進行了承上啟下的總結與分析,並補充闡述新的技術條件下無信任(trustless)、L1 原生 rollups 等新可能性。
本文概述
本文共約 11000 字,有 7 個部分,閱讀完本文預計需要 60 分鐘。
- 補充:可擴展性三難困境
- 數據可用性採樣(data availability sampling)的進一步進展
- 資料壓縮(data compression)
- 通用 Plasma
- 成熟的 L2 證明系統(proof systems)
- 跨 L2 互操作性和用戶體驗改進
- L1 上的擴展執行
正文內容
《乙太坊協定可能的未來(二):The Surge》
特別感謝 Justin Drake、Francesco、Hsiao-wei Wang、@antonttc 和 Georgios Konstantopoulos
最初,乙太坊在其路線圖中有兩種擴展策略。 一種(參見 2015 年的這篇早期論文)是 “分片(sharding)”:每個節點只需驗證和存儲一小部分交易,而不是驗證和存儲鏈中的所有交易。 其他點對點網路(例如 BitTorrent)也是這樣運作的,所以我們當然可以讓區塊鏈以同樣的方式工作。 另一種是 Layer 2 協議:位於乙太坊之上的網路,可以充分利用其安全性,同時將大多數數據和計算保留在主鏈之外。 “Layer 2 協定” 在 2015 年意味著狀態通道(state channels),2017 年意味著 Plasma,然後是 2019 年的 rollups。 rollups 比狀態通道或 Plasma 更強大,但它們需要大量的鏈上數據頻寬。 幸運的是,到 2019 年,分片研究已經解決了大規模驗證「數據可用性(data availability)」的問題。 結果,兩條路徑彙聚在一起,我們得到了以 rollup 為中心的路線圖,這仍然是當今乙太坊的擴展戰略。
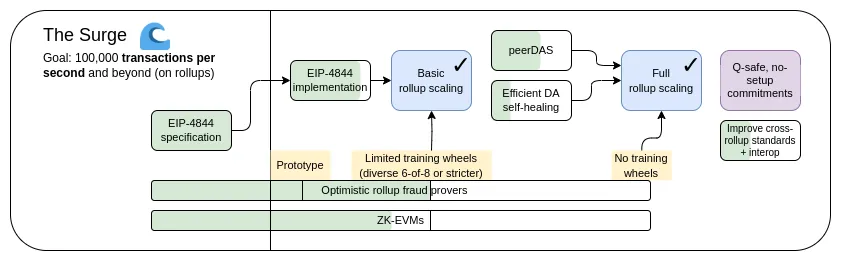
以 rollup 為中心的路線圖提出了一種簡單的分工:乙太坊 L1 專注於成為一個魯棒且去中心化的基礎層,L2 則承擔説明生態系統擴展的任務。 這種模式在社會中隨處可見:法院系統(L1)不是為了極度高效而存在,而是為了保護契約和產權,企業家(L2)則要在堅固的基礎層(layer)之上構建並將人類帶上(比喻和字面意義上的)火星。
今年,以 rollup 為中心的路線圖取得了重要的成功:隨著 EIP-4844 blob 的出現,乙太坊 L1 數據頻寬大幅提升,多個 EVM rollup 現已處於第 1 階段。 一種高度異構與多元化分片應用的路徑已經成為現實,其中每個 L2 都充當一個具有自己內部規則和邏輯的 “分片”。 但正如我們所見,走這條路有其獨特的挑戰。 所以現在我們的任務是完成以 rollup 為中心的路線圖,並解決這些問題,同時保持乙太坊 L1 的魯棒性(robustness)與去中心化。
The Surge:主要目標
- L1+L2 上 100,000+ 的 TPS
- 保持 L1 的去中心化和魯棒性
- 至少一些 L2 完全繼承了乙太坊的核心屬性(無需信任、開放、抗審查)
- 最大化 L2 之間的互操作性。 乙太坊應該讓人感覺像一個生態系統,而不是 34 個不同的區塊鏈。
本章內容
- 補充:可擴展性三難困境
- 數據可用性採樣(data availability sampling)的進一步進展
- 資料壓縮(data compression)
- 通用 Plasma
- 成熟的 L2 證明系統(proof systems)
- 跨 L2 互操作性和用戶體驗改進
- L1 上的擴展執行
補充:可擴展性三難困境(scalability trilemma)
可擴展性三難困境是於 2017 年提出 的一個想法,主要討論的是以下三個屬性之間矛盾:去中心化(更具體地說:運行節點的成本低)、可擴充性(更具體地說:處理高交易數量的能力)和安全性(更具體地說:攻擊者需要先破壞網路的大部分節點才能使單筆交易失敗)。
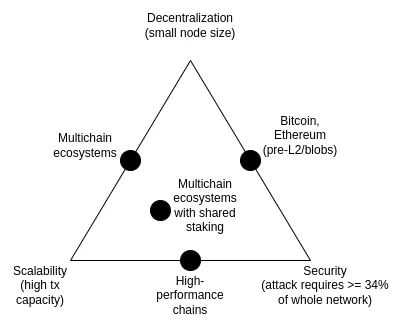
值得注意的是,三難困境並不是一個定理,介紹三難困境的文章也沒有提供數學證明。 它確實給出了一個啟發式的數學論證:如果支援去中心化的節點(如消費級筆記型電腦)每秒可以驗證 N 筆交易,且存在一條每秒處理 k*N 筆交易的鏈,那麼要麼(i)每筆交易僅被 1/k 的節點看到,這意味著攻擊者只需要破壞幾個節點就能推動惡意交易通過,要麼(ii)節點非常強大,難以去中心化。 本文並不是表明打破三難困境不可能; 相反,本文旨在闡明為什麼打破三難困境非常困難 —— 它需要以某種方式跳出論證所暗示的思維定式。
多年來,一些高性能鏈常常聲稱:不需要在基礎架構層面精妙設計,使用軟體工程技巧來優化節點就能解決三難困境。 這樣的言論具有誤導性,在這樣的鏈上運行節點比在乙太坊中困難得多。 這篇博文深入探討了為什麼會出現這種情況(以及為什麼僅靠 L1 用戶端軟體工程無法擴展乙太坊本身)。
然而,數據可用性採樣(data availability sampling)和 SNARK 的結合確實解決了三難困境:它允許客戶端驗證一定數量的數據可用性,並且在只下載那部分數據的一小部分的情況下,用更少的計算量來驗證是否正確執行了一些計算步驟。 SNARK 是無需信任(trustless)的。 數據可用性抽樣有一個微妙的少數節點信任模型(few-of-N trust model),但它仍保留了不可擴展鏈所擁有的基本屬性 —— 即使是 51% 攻擊也無法強迫網路接受惡意區塊。
解決三難困境的另一種方法是 Plasma 架構,它使用巧妙的技術以激勵相容的方式將監視數據可用性的責任推給使用者。 早在 2017-2019 年,對擴展計算這一目標,我們所能做只有欺詐證明(fraud proofs)時,Plasma 的安全功能非常有限。 當 SNARK 成為主流,Plasma 架構的用例也變得比以前更加的廣泛。
數據可用性採樣(data availability sampling)取得進一步進展
我們要解決什麼問題?
截至 2024 年 3 月 13 日,當 Dencun 升級上線時,乙太坊區塊鏈每 12 秒時隙(slot)有 3 個大約 125 kB 的 “blob”,或者說數據可用帶寬為大約 375 kB 每時隙。 假設交易數據直接在鏈上發佈,一筆 ERC20 轉帳約為 180 位元組,則乙太坊上 rollups 的最大 TPS 為:
375000 / 12 / 180 = 173.6 TPS
如果加上乙太坊的 calldata [理論最大值:每時隙 3000 萬 gas / 每位元組 16 gas = 每時隙 1,875,000 位元節],這個數位就會變成 607 TPS。 如果使用 PeerDAS,計劃是將 blob 計數目標增加到 8-16,加上 calldata 後速度為 463-926 TPS 。
與乙太坊 L1 相比,這已經是很大的提升。 但這還遠遠不夠,我們還想要更好的可擴充性。 我們的中期目標是每時隙 16 MB,如果結合 rollup 數據壓縮的改進, 速度將提升至 大約 58,000 TPS。
它是什麼,如何做到的?
PeerDAS 是對「一維採樣(1D sampling)」相對簡單的實現。 乙太坊中的每個 blob 都是 253 位素數域上的 4096 階多項式(degree-4096 polynomial over a 253-bit prime field)。 我們廣播多項式的「份額(shares)」,每個份額由 16 個 evaluation 組成,位於相鄰的、從 8192 個座標組中抽取的 16 個座標。 8192 個 evaluation 中的任意 4096 個(使用當前建議的參數:128 個可能樣本中的任意 64 個)都可以恢復 blob。
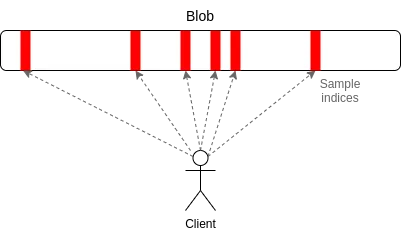
PeerDAS 的工作原理是:每個用戶端僅監聽少數子網,其中第 i 個子網負責廣播 blob 的第 i 個樣本; 當用戶端需要獲取其他子網上的 blob 時,可以通過全球 p2p 網路向監聽不同子網的節點發起請求。 與 PeerDAS 相比之下,SubnetDAS 的方案更為保守,它僅保留了子網機制,去除了節點間相互詢問的流程。 根據當前提案,參與權益證明的節點將採用 SubnetDAS,而其他節點(即 “用戶端”)則使用 PeerDAS。
理論上一維採樣(1D sampling)的擴展空間相當大:如果我們將 blob 的最大數量提升至 256(相應的 target 為 128),就能達到 16MB 的 target 容量。 在這樣的情況下,每個節點進行數據可用性採樣所需的頻寬開銷計算如下:
16 個樣本 × 128 個 blob × 512 位元組(每個 blob 的單個樣本大小)= 1MB 帶寬/時隙 ;
這個頻寬要求剛好處於可接受範圍的邊緣:雖然技術上可行,但頻寬受限的用戶端將無法參與採樣。 我們可以通過減少 blob 數量並增加單個 blob 的大小來優化這一方案,但這類數據重構的方案成本更高。
為進一步提升性能可以採用二維採樣(2D sampling)技術 —— 既在單個 blob 內部進行採樣,又在不同 blob 之間進行採樣,利用 KZG 承諾(KZG commitments)的線性特性來 “擴展” 區塊中的 blob 集合,生成一系列新的 “虛擬 blob”,這些 “虛擬 blob” 通過冗餘編碼的方式存儲相同的資訊。
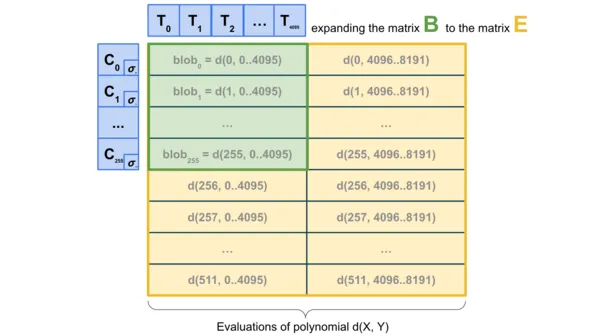
這個方案有一個重要特點:計算承諾的擴展過程無需獲取完整的 blob 數據,這使得它天然適合分散式區塊的構建。 具體而言,負責構建區塊的節點只需持有 blob 的 KZG 承諾,就能通過 DAS 系統驗證這些 blob 的可用性。 同樣一維 DAS(1D DAS)也具備這類構建分散式區塊的優勢。
與現有研究有哪些聯繫?
- 介紹數據可用性的原始帖子(Original post introducing data availability)(2018 年):https://github.com/ethereum/research/wiki/A-note-on-data-availability-and-erasure-coding
- 後續論文(Follow-up paper):HTTPs://arxiv.org/abs/1809.09044
- 關於 DAS、Paradigm 的解釋帖子(Explainer post on DAS, paradigm):https://www.paradigm.xyz/2022/08/das
- 具備 KZG 承諾的二維可用性(2D availability with KZG commitments):https://ethresear.ch/t/2d-data-availability-with-kate-commitments/8081
- ethresear.ch 上的 PeerDAS(ethresear.ch 上的 PeerDAS):https://ethresear.ch/t/peerdas-a-simpler-das-approach-using-battle-tested-p2p-components/16541,以及論文:https://eprint.iacr.org/2024/1362
- Francesco 關於 PeerDAS 的演講(Presentation on PeerDAS by Francesco):https://www.youtube.com/watch?v=WOdpO1tH_Us
- EIP-7594:https://eips.ethereum.org/EIPS/eip-7594
- ethresear.ch 上的 SubnetDAS:https://ethresear.ch/t/subnetdas-an-intermediate-das-approach/17169
- 2D 採樣中可恢復性的細微差別(Nuances of recoverability in 2D sampling):https://ethresear.ch/t/nuances-of-data-recoverability-in-data-availability-sampling/16256
還有什麼要做,需要權衡什麼?
當前的首要任務是完成 PeerDAS 的開發和部署工作。 接下來就是循序漸進的推動 —— 通過持續監控網路狀況和優化軟體性能、確保系統安全的同時,穩步提升 PeerDAS 的 blob 處理容量。 同時,我們需要推動更多學術研究,對 PeerDAS 及其他 DAS 變體的正式驗證,並深入研究它們與分叉選擇規則安全性等問題之間的相互作用。
在未來的工作中,我們需要進一步研究確定二維 DAS 的最優實現形式,並對其安全性進行嚴格證明。 另一個長期目標是尋找 KZG 的替代方案,新方案需要同時具備抗量子特性和免信任設置(trusted-setup-free)的特點。 然而,目前我們尚未找到任何適合分散式區塊構建的候選方案。 甚至連使用遞歸(recursive)STARK 來生成行與列、重建有效性證明這種計算成本高昂的「暴力」方法也不是很有效 —— 儘管從理論上看,採用 STIR 後 STARK 的大小僅需 O(log(n)* log(log(n))個哈希值,但實際應用中 STARK 的數據量仍然接近一個完整 blob 的大小。
從長遠來看,我認為有以下幾條可行的發展路徑:
- 採用理想的二維 DAS 方案
- 繼續採用一維 DAS 方案 —— 雖然會犧牲採樣頻寬效率,需要接受較低的數據容量上限,但能確保系統簡單、穩定(robustness)
- (重大轉向)完全放棄數據可用性採樣(DA),轉而將 Plasma 作為重點發展的 Layer 2 架構方案
我們可以從以下幾個維度來權衡這些方案的利弊:
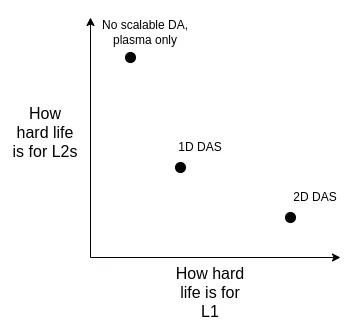
需要特別指出的是,即使我們決定直接在 L1 上進行擴容,這些技術選擇的權衡問題仍然存在。 這是因為:如果 L1 要支援高 TPS,區塊大小會顯著增加,在這種情況下,客戶端節點就需要高效的驗證機制來確保區塊正確。 這就意味著我們不得不在 L1 上應用那些原本用於 rollup 的底層技術(比如 ZK-EVM 和 DAS 等)。
它如何與路線圖的其他部分互動?
數據壓縮(data compression)(詳見後文)的落地將顯著降低或推遲對二維 DAS(2D DAS)的需求; 如果廣泛採用 Plasma,需求還將進一步下降。 不過,DAS 也給分散式區塊的構建帶來了新的挑戰:儘管從理論上看 DAS 有利於分散式重建,但在實際應用中,我們需要將其與納入清單(inclusion list)提案以及相關的分叉選擇機制進行無縫整合。
資料壓縮(data compression)
我們要解決什麼問題?
在 rollup 中,每筆交易都需要在鏈上佔用可觀的數據空間:一筆 ERC20 轉帳交易約需 180 位元組。 即便採用理想的數據可用性採樣機制,這仍然會限制二層協定的可擴充性。 按照每個時隙 16 MB 的數據容量計算,易得:16000000 / 12 / 180 = 7407 TPS
除了優化分子部分,如果我們還能處理分母問題 —— 即降低 rollup 中每筆交易在鏈上的位元組佔用量,會帶來什麼效果?
它是什麼,如何做到的?
我認為最好的解釋是兩年前的這張圖:
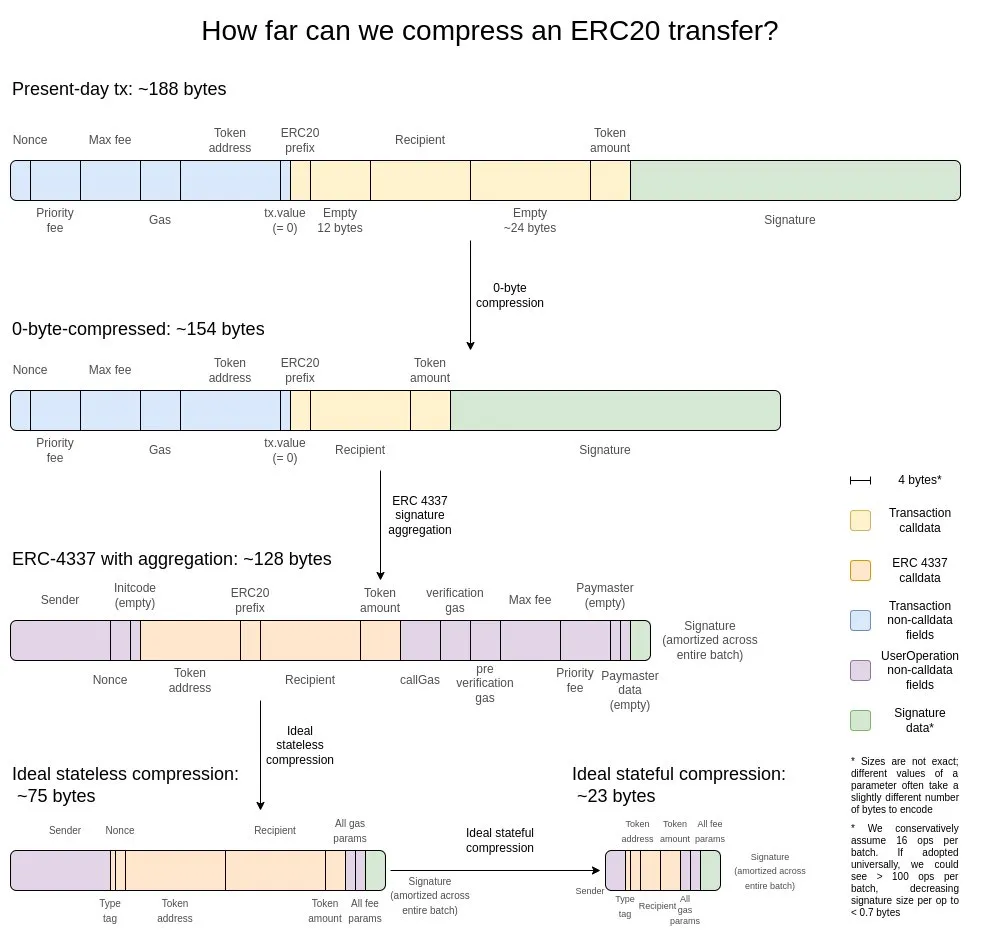
首先是最基礎的優化手段 —— 零位元組壓縮:用兩個字節來表示連續的零位元組序列的長度,從而替代原始的零位元組串。 要實現更深層的優化,我們可以利用交易的以下特性:
- 簽名聚合(signature aggregation)—— 將簽名系統從 ECDSA 遷移至 BLS,後者能夠將多個簽名合併為單個簽名,同時驗證所有原始簽名的有效性。 雖然由於驗證的計算開銷較大(即便是在聚合場景下),這一方案並不適用於 L1,但在 L2 這樣的數據受限環境中,其優勢就顯得非常明顯。 ERC-4337 的聚合特性為實現這一目標提供了可行的技術路徑。
- 位址指標替換機制 —— 對於歷史上出現過的位址,我們可以用 4 位元組的指標(指向歷史記錄中的位置)來替代原本的 20 位元組位址。 這種優化能帶來最大的收益,但實現起來相對複雜,因為它要求將區塊鏈的歷史記錄(至少是部分歷史)實質性地整合到狀態集中。
- 交易金額的自定義序列化(serialization)方案 —— 大多數交易金額實際上只包含少量有效數位。 例如,0.25 ETH 在系統中被表示為 250,000,000,000,000,000 wei。 gas 的最大基礎費率(max-basefee)和優先費率(priority fee)也具有類似特點。 基於這一特性,我們可以採用自定義的十進位浮點格式,或建立常用數值字典,從而大幅壓縮貨幣數值的存儲空間。
與現有研究有哪些聯繫?
- 來自 sequence.xyz 的探索(Exploration from sequence.xyz):https://sequence.xyz/blog/compressing-calldata
- 來自 ScopeLift 的針對 L2s 的 Calldata 優化合約(Calldata-optimized contracts for L2s, from ScopeLift):https://github.com/ScopeLift/l2-optimizoooors
- 替代策略 - 基於有效性證明的 rollups(又名 ZK rollups)發佈狀態差異而不是交易(An alternative strategy - validity-proof-based rollups(又名 ZK rollups)發佈狀態差異而不是交易):https://ethresear.ch/t/rollup-diff-compression-application-level-compression-strategies-to-reduce-the-l2-data-footprint-on-l1/9975
- BLS 錢包 —— 通過 ERC-4337 實現 BLS 聚合(BLS wallet - an implementation of BLS aggregation through ERC-4337):https://github.com/getwax/bls-wallet
還有什麼要做,需要權衡什麼?
目前的首要任務是將上述方案落地實施。 這涉及以下幾個關鍵的權衡:
- BLS 簽名遷移 —— 轉換至 BLS 簽名體系需要投入大量工程資源,同時會降低與安全增強型可信硬體(TEE)的相容性。 對此,一個可行的替代方案是採用其他簽名演算法的 ZK-SNARK 封裝。
- 動態壓縮實現 —— 實施如位址指標替換等動態壓縮機制會顯著提高用戶端代碼的複雜度。
- 狀態差異發佈 —— 選擇向鏈上發佈狀態差異而非完整交易會削弱系統的可審計性,同時導致區塊瀏覽器等現有基礎設施無法正常運行。
它如何與路線圖中的其他部分互動?
通過引入 ERC-4337 並最終將其部分功能在 L2 EVM 中標準化化,將顯著加速聚合技術的部署進程。 同樣,將 ERC-4337 的部分功能納入 L1 也將促進其在 L2 生態中的快速落地。
通用 Plasma 架構
我們要解決什麼問題?
即便結合了 16 MB blob 存儲和數據壓縮技術,58,000 TPS 的處理能力仍然不足以完全支撐消費支付、去中心化社交網路等高頻寬場景。 當我們考慮引入隱私保護機制時,這一問題會變得更加突出,因為隱私特性可能會使系統的可擴充性降低 3 至 8 倍。 目前,對於高吞吐、低價值內容的應用場景,一個可選方案是 validium。 它採用鏈下數據存儲模式,並實現了一個獨特的安全模型:運營商無法直接盜取用戶資產,但他們可能通過失聯來臨時或永久性地凍結用戶資金。 不過,我們有機會構建更優的解決方案。
它是什麼,如何做到的?
Plasma 是一種擴容解決方案,與 rollup 將完整區塊數據上鏈不同,Plasma 的運營商在鏈下生成區塊,僅將區塊的 Merkle 根記錄到鏈上。 對於每個區塊,運營商會向使用者分發 Merkle 分支,用以證明與該使用者資產相關的狀態變更(或未發生的變更)。 用戶可以通過提供這些 Merkle 分支來提取其資產。 一個關鍵特性是:這些 Merkle 分支不必指向最新狀態 —— 這意味著即使在數據可用性出現故障的情況下,使用者仍然可以通過提取其所掌握的最新可用狀態來找回資產。 如果有使用者提交了無效的分支(比如嘗試提取已轉移給他人的資產,或運營商試圖憑空創造資產),鏈上的挑戰機制可以對資產擁有權進行仲裁。
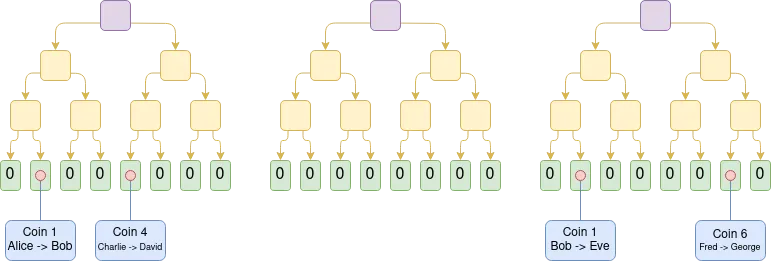
Plasma 的早期實現僅限於支付場景,難以實現更廣泛的功能擴展。 然而,如果我們引入 SNARK 來驗證每個根節點,Plasma 的能力將得到顯著提升。 由於這種方式可以從根本上消除大部分運營商作弊的可能性,挑戰機制可以大大簡化。 同時,這也為 Plasma 技術開闢了新的應用路徑,使其能夠擴展到更多樣化的資產類型。 更重要的是,在運營商誠實行為的情況下,使用者可以即時提取資金,無需等待為期一周的挑戰期。
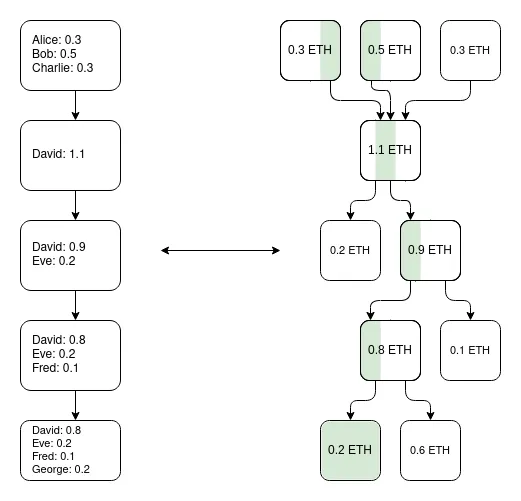
一個重要的洞見是:Plasma 系統無需追求完美。 即便它只能保護部分資產(比如僅保護過去一周內未發生轉移的代幣),也已經大大改善了超可擴展(ultra-scalable)EVM 的現狀,這是一個 validium。
另一種架構方案是 plasma/rollup 的混合模式,Intmax 就是典型代表。 這類架構在鏈上僅存儲極少量的用戶數據(每個使用者約 5 位元元組),從而在特性上達到了 plasma 和 rollup 的平衡點:以 Intmax 為例,它實現了極高的可擴展性和隱私性,但即便在 16 MB 數據容量的場景下,其理論輸送量也被限制在約 266,667 TPS(計算方式:16,000,000/12/5)。
與現有研究有哪些聯繫?
- 原始 Plasma 論文(Original Plasma paper):https://plasma.io/plasma-deprecated.pdf
- Plasma 現金(Plasma Cash):https://ethresear.ch/t/plasma-cash-plasma-with-much-less-per-user-data-checking/1298
- Plasma 現金流(Plasma Cashflow):https://hackmd.io/DgzmJIRjSzCYvl4lUjZXNQ?view#
 -Exit
-Exit - Intmax(2023 年):https://eprint.iacr.org/2023/1082
還有什麼要做,需要權衡什麼?
當前的核心任務是將 Plasma 系統推向生產環境。 如前所述,Plasma 與 Validium 的關係並非非此即彼:任何 validium 都可以通過在其退出機制中整合 Plasma 特性來提升其安全屬性,哪怕是細微的改進。 研究重點包括:
- 為 EVM 尋找最優性能參數(從信任假設、L1 最壞情況 gas 開銷和抗 DoS 能力等維度考量)
- 探索特定應用場景的替代性架構方案
同時,我們需要正面解決 Plasma 相比 rollup 在概念上更為複雜的問題,這需要通過理論研究與優化通用框架實現的雙重路徑來推進。
採用 Plasma 架構的主要權衡在於:它對運營商的依賴程度更高,且更難實現 “基礎化(based)”。 儘管混合 plasma/rollup 架構通常可以規避這一劣勢。
它如何與路線圖的其他部分互動?
Plasma 解決方案的效用越高,對 L1 層提供高性能數據可用性的壓力就越小。 同時,將鏈上活動遷移至 L2 也能夠降低 L1 層面的 MEV 壓力。
成熟的 L2 證明(proof)系統
我們要解決什麼問題?
目前,大多數 rollup 尚未實現真正的無信任機制 —— 它們都設有安全委員會,可以對(optimistic 或 validity)證明系統的行為進行干預。 某些情況下,證明系統甚至完全缺失,或僅具有「建議性」功能。 在這一領域最具進展的是:(i)一些應用特定的 rollup(如 Fuel),它們已實現了無信任機制;(ii)截至本文撰寫時,兩個完整的 EVM rollup —— Optimism 和 Arbitrum,已達到了稱為「階段一(stage 1)」的部分無信任里程碑。 rollup 未能進一步發展的主要障礙是對代碼漏洞的顧慮。 要實現真正無信任的 rollup,我們必須正面應對這一挑戰。
它是什麼,如何做到的?
首先,我們來回顧之前這篇文章介紹的「階段(stage)」系統。 雖然完整要求更為詳細,但主要內容概括如下:
- 階段 0:用戶必須能夠獨立運行節點並完成鏈同步。 驗證機制可以是完全中心化或基於信任的。
- 階段 1:系統必須實現 (無信任 trustless)證明機制,確保僅有效交易能被接受。 允許設立安全委員會對證明系統進行干預,但需達到 75% 的投票閾值。 同時,超過 26% 的委員會成員必須來自主要開發公司以外。 可以採用功能較弱的升級機制(例如 DAO),但必須設置足夠長的時間鎖,確保使用者能在惡意升級生效前安全提取資金。
- 階段 2:系統必須實現 (無信任 trustless)證明機制,確保僅有效交易能被接受。 安全委員會只能在出現明確的代碼缺陷時介入,比如:兩套證明系統產生衝突,或單個證明系統對同一區塊生成了不同的后狀態根(或在較長時間內,如一周,沒有生成任何結果)。 允許設置升級機制,但必須採用極長的時間鎖。
我們的最終目標是達到階段二。 邁向第二階段的關鍵挑戰是:確保人們對證明系統有足夠的信任,並認為它足夠可信。 目前有兩種主要的實現路徑:
- 形式化驗證:我們可以藉助現代數學和計算機科學技術,來證明(optimistic 或 validity)證明系統只會接受符合 EVM 規範的區塊。 雖然這類技術已有數十年歷史,但近期的技術突破(如 Lean 4)大大提升了其實用性,而 AI 輔助證明的發展有望進一步加快這一進程。
- 多重證明機制:構建多個證明系統,並將資金存入由這些系統和安全委員會(以及/或其他基於信任假設的元件,如 TEE)共同控制的 2/3 多簽(或更高閾值)合約中。 當各證明系統達成一致時,安全委員會不具有決策權; 當系統之間存在分歧時,安全委員會只能在現有結果中選擇其一,而不能強制推行自己的方案。
與現有研究有哪些聯繫?
- EVM K Semantics(2017 年開始的形式化驗證工作):https://github.com/runtimeverification/evm-semantics
- 關於多重證明器理念的演示(2022 年):https://www.youtube.com/watch?v=6hfVzCWT6YI
- Taiko 計劃使用多重證明(Taiko plans to use multi-proofs):https://docs.taiko.xyz/core-concepts/multi-proofs/
還有什麼要做,需要權衡什麼?
在形式化驗證方面,還有大量工作要做。 我們需要為 EVM 的完整 SNARK 證明器開發一個經過形式化驗證的版本。 這是一個極其複雜的項目,雖然我們已經著手進行。 不過,有一個技術方案可以顯著降低複雜度:我們可以先為最小化虛擬機(如 RISC-V 或 Cairo)構建一個經過形式化驗證的 SNARK 證明器,然後在這個最小化虛擬機上實現 EVM(同時形式化證明其與其他 EVM 規範的等價性)。
關於多重證明機制,還有兩個核心問題需要解決:首先,我們需要建立對至少兩個不同證明系統的充分信心。 這要求這些系統不僅各自都具備足夠的安全性,而且即使發生故障,也會因不同且無關的原因而失效(這樣就不會出現同時崩潰的情況)。 其次,我們需要對合併這些證明系統的底層邏輯建立極高的可信度。 這部分代碼量相對較小。 雖然有方法可以將其進一步簡化 —— 比如將資金存入一個 Safe 多簽合約,由代表各證明系統的合約作為簽名方 —— 但這種方案會帶來較高的鏈上 gas 開銷。 因此我們需要在效率和安全性之間尋找適當的平衡點。
它與路線圖的其他部分如何互動?
將鏈上活動遷移至 L2 能夠緩解 L1 的 MEV 壓力。
跨 L2 互操作性改進
我們要解決什麼問題?
當前 L2 生態系統面臨的一個主要挑戰是用戶難以在不同 L2 間無縫切換。 更糟糕的是,那些看似便捷的解決方案往往會重新引入信任依賴 —— 比如中心化跨鏈橋、RPC 用戶端等。 如果我們真正希望將 L2 作為乙太坊生態的有機組成部分,就必須確保使用者在使用 L2 生態時能夠獲得與乙太坊主網一致的統一體驗。
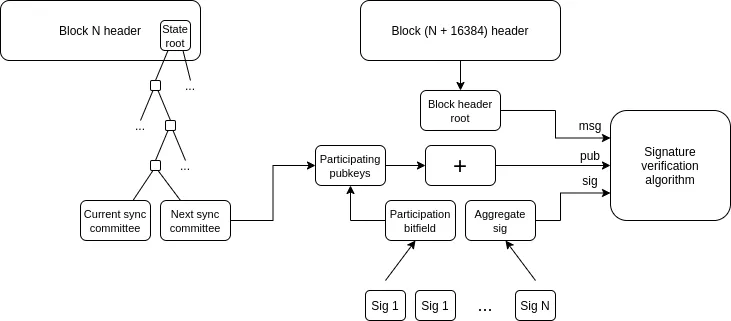
它是什麼,如何做到的?
跨 L2 互操作性的改進涉及多個維度。 從理論上看,以 rollup 為中心的乙太坊架構本質上等同於 L1 的執行分片(sharding)。 因此,我們可以通過對比這一理想模型,來發現當前乙太坊 L2 生態在實踐中存在的差距。 以下是幾個主要方面:
- 鏈特定位址:鏈標識(如 L1、Optimism、Arbitrum 等)應該成為地址的組成部分。 實現後,跨層轉帳流程將變得簡單:使用者只需在「發送」欄輸入位址,錢包就能自動處理後續操作(包括調用跨鏈橋協定)。
- 鏈特定支付請求:應建立標準化機制,簡化「在鏈 Z 上發送 X 數量的 Y 類型代幣給我」這類請求的處理。 主要應用場景包括:
- 支付場景:包括個人間轉帳和商戶支付
- DApp 資金請求:如上述 Polymarket 的例子
- 跨鏈兌換與 gas 支付:需要建立標準化的開放協議來處理跨鏈操作,例如:
- “我將在 Optimism 上支付 1 ETH,以換取他人在 Arbitrum 上支付給我的 0.9999 ETH”
- “我將在 Optimism 上支付 0.0001 ETH,給任何願意在 Arbitrum 上打包此交易的人”
- 輕客戶端:用戶應該能夠直接驗證所交互的鏈,而不是完全依賴 RPC 服務提供者。 A16z crypto 開發的 Helios 已經在乙太坊主網實現了這一功能,現在我們需要將這種去信任特性擴展到 L2 網路。 ERC-3668(CCIP-read)提供了一種可行的實現方案。
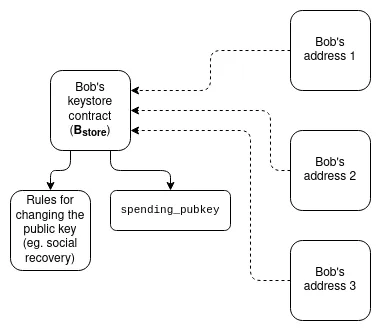
密鑰庫錢包:目前,如果您希望更新控制智慧合約錢包的密鑰,必須在該錢包存在的所有 N 條鏈上進行更新。 密鑰庫錢包是一種技術,允許密鑰僅存在於一個地方(要麼在 L1 上,或者將來可能在 L2 上),然後從任何擁有錢包副本的 L2 讀取。 這意味著更新只需進行一次。 為了提高效率,密鑰庫錢包需要 L2 提供一種標準化的方式來無成本地讀取 L1; 為此,有兩個提案是 L1SLOAD 和 REMOTESTATICCALL。
- 更激進的「共用代幣橋」理念:想像一個世界,所有的 L2 都是有效性證明的 rollup,每個時隙都提交到乙太坊。 即使在這種情況下,想要在 L2 之間「原生地」移動資產,仍然需要提現和存款,這需要支付大量的 L1 gas 費用。 解決這個問題的一種方法是創建一個共用的最小化 rollup,其唯一功能是維護每個 L2 擁有的各種類型代幣的餘額,並允許這些餘額通過任何 L2 發起的一系列跨 L2 發送操作進行整體更新。 這將使跨 L2 轉賬能夠發生,而無需為每次轉帳支付 L1 的 gas 費用,也不需要像 ERC-7683 這樣的基於流動性提供者的技術。
- 同步可組合性(synchronous composability):允許在特定的 L2 和 L1 之間,或多個 L2 之間進行同步調用。 這可能有助於提高 DeFi 協定的金融效率。 前者可以在無需任何跨 L2 協調的情況下完成; 後者則需要使用共用排序。 based rollup 對所有這些技術都天然友好。
與現有研究有哪些聯繫?
- 鏈特定位址:ERC-3770(鏈特定位址:ERC-3770):https://eips.ethereum.org/EIPS/eip-3770
- ERC-7683:https://eips.ethereum.org/EIPS/eip-7683
- RIP-7755:https://github.com/wilsoncusack/RIPs/blob/cross-l2-call-standard/RIPS/rip-7755.md
- Scroll 金鑰庫錢包設計(Scroll keystore wallet design):https://hackmd.io/@haichen/keystore
- Helios:https://github.com/a16z/helios
- ERC-3668(有時稱為 CCIP-read):https://eips.ethereum.org/EIPS/eip-3668
- Justin Drake 提出的 “Based(共用)預確認” 提案(Proposal for “based(shared)preconfirmations” by Justin Drake):https://ethresear.ch/t/based-preconfirmations/17353
- L1SLOAD(RIP-7728):https://ethereum-magicians.org/t/rip-7728-l1sload-precompile/20388
- Optimism 中的 REMOTESTATICCALL(REMOTESTATICCALL in Optimism):https://github.com/ethereum-optimism/ecosystem-contributions/issues/76
- AggLayer,包括共用代幣橋接理念(AggLayer, which including shared token bridge ideas):https://github.com/AggLayer
還有什麼要做,需要權衡什麼?
上述許多範例都面臨著標準化的常見困境:何時標準化,以及在哪些層面進行標準化。 如果過早標準化,可能會使劣質的解決方案根深蒂固; 如果過晚標準化,則可能導致不必要的分裂。 在某些情況下,既存在性能較弱但易於實施的短期解決方案,也存在需要相當長時間才能實現但 “最終正確” 的長期解決方案。
這部分的的獨特之處在於,這些任務不僅是技術問題,甚至可能主要是社會問題。 它們需要 L2、錢包和 L1 的合作。 我們成功處理這一問題的能力,是對我們作為一個社區團結一致能力的考驗。
它與路線圖的其他部分如何互動?
這些提案大部分都是「高層」結構,因此對 L1 層面的考慮影響不大。 唯一的例外是共用排序,它對 MEV 有著重大影響。
在 L1 上擴展執行
我們要解決什麼問題?
如果 L2 變得非常可擴展且成功,但 L1 仍然只能處理極少量的交易,那麼乙太坊可能會面臨許多風險:
- ETH 資產的經濟狀況會變得更具風險性,進而影響網路的長期安全。
- 許多 L2 受益於與 L1 上高度發達的金融生態系統的緊密聯繫,如果這個生態系統大幅削弱,成為 L2(而非獨立的 L1)的動機也會減弱。
- L2 要達到與 L1 完全相同的安全保證還需要很長時間。
- 如果一個 L2 發生故障(例如,由於惡意行為或運營者消失),使用者仍需要通過 L1 來恢復他們的資產。 因此,L1 需要足夠強大,至少能夠偶爾實際處理 L2 的高度複雜和混亂的關閉過程。
出於這些原因,繼續擴展 L1 本身,並確保其能夠繼續滿足日益增長的使用需求,是非常有價值的。
它是什麼? 它是如何工作的?
最簡單的擴容方式就是直接增加 gas 上限。 然而,這可能導致 L1 的中心化,從而削弱乙太坊 L1 作為強大基礎層的另一個重要特性:其可信度。 關於簡單增加 gas 上限的可持續程度,一直存在爭議,而且這也取決於為了讓更大區塊更易於驗證,將實施哪些其他技術(例如歷史數據過期、無狀態化、L1 EVM 有效性證明)。 另一個需要持續改進的重要方面是以太坊用戶端軟體的效率,如今的用戶端比五年前已優化了許多。 一個有效的 L1 gas 上限增加策略將涉及加速這些驗證技術的推進。
另一種擴展策略涉及確定可以降低成本且不會損害網路去中心化或其安全屬性的特定功能和計算類型。 這方面的例子包括:
- EOF:一種新的 EVM 位元組碼格式,更有利於靜態分析,允許更快速的實現。 考慮到這些效率,EOF 位元組碼可以被賦予更低的 gas 成本。
- 多維(multidimensional)gas 定價:為計算、數據和存儲分別建立基礎費用和限制,可以在不增加乙太坊 L1 最大容量(從而避免新的安全風險)的情況下,提高其最大容量。
- 降低特定操作碼和預編譯的 gas 成本:歷史上,為了避免拒絕服務攻擊,我們曾提高了好幾輪某些定價過低操作的 gas 成本。 我們較少做的、但可以大力推進的,是降低那些定價過高操作的 gas 成本。 例如,加法比乘法便宜得多,但目前 ADD 和 MUL 操作碼的成本是相同的。 我們可以使 ADD 更便宜,甚至像 PUSH 這樣更簡單的操作碼也可以更便宜。
- EVM-MAX 和 SIMD:EVM-MAX(“模算術擴展”)是一個提案,允許在 EVM 的一個獨立模組中更高效地進行原生大數模運算。 EVM-MAX 計算出的值只可被其他 EVM-MAX 操作碼訪問,除非被有意導出; 這允許以優化的格式存儲這些值,提供更大的空間。 SIMD(“單指令多數據”)是一個提案,允許在一組值上高效地執行相同的指令。 兩者結合可以在 EVM 旁創建一個強大的協處理器,可用於更高效地實現加密操作。 這對於隱私協定和 L2 證明系統尤其有用,因此有助於 L1 和 L2 的擴容。
這些改進將在未來的 Splurge 博文中更詳細地討論。
最後,第三種策略是原生 rollup(或 “內置 rollup” 英文原文:“enshrined rollups”):本質上,創建多個並行運行的 EVM 副本,形成一個與 rollup 所能提供的功能等價的模型,但更原生地集成到協定中。
與現有研究有哪些聯繫?
- Polynya 的乙太坊 L1 擴展路線圖(Polynya's Ethereum L1 scaling roadmap):https://polynya.mirror.xyz/epju72rsymfB-JK52_uYI7HuhJ-W_zM735NdP7alkAQ
- 多維 gas 定價(Multidimensional gas pricing):https://vitalik.eth.limo/general/2024/05/09/multidim.html
- EIP-7706:https://eips.ethereum.org/EIPS/eip-7706
- EOF:https://evmobjectformat.org/
- EVM-MAX:https://ethereum-magicians.org/t/eip-6601-evm-modular-arithmetic-extensions-evmmax/13168
- SIMD:https://eips.ethereum.org/EIPS/eip-616
- 原生 rollups:https://mirror.xyz/ohotties.eth/P1qSCcwj2FZ9cqo3_6kYI4S2chW5K5tmEgogk6io1GE
- 採訪 Max Resnick 談論擴展 L1 的價值(Interview with Max Resnick on the value of scaling L1):https://x.com/BanklessHQ/status/1831319419739361321
- Justin Drake 談論使用 SNARK 和原生 rollups 進行擴展(Justin Drake on the use of SNARKs and native rollups for scaling):https://www.reddit.com/r/ethereum/comments/1f81ntr/comment/llmfi28/
還有什麼要做,需要權衡什麼?
L1 擴容有三種策略,可以單獨或並行推進:
- 改進技術(例如用戶端代碼、無狀態用戶端、歷史數據過期)以使 L1 更易於驗證,然後提高 gas 上限。
- 降低特定操作的成本,在不增加最壞情況風險的情況下提高平均容量。
- 原生 rollup(即 “創建 N 個並行運行的 EVM 副本”,同時可能在部署的副本參數上為開發者提供很大的靈活性)。
需要理解的是,這些是不同的技術,有著各自的權衡取捨。 例如,原生 Rollup 在可組合性方面與常規 rollup 有許多相同的弱點:您無法像在同一個 L1(或 L2)上的合約那樣,發送一個單一交易在多個 rollup 上同步執行操作。 提高 gas 上限,會削弱通過使 L1 更易於驗證所能獲得的其他好處,例如增加運行驗證節點的使用者比例和提高獨立質押者的數量。 根據具體實現方式,降低 EVM 中特定操作的成本可能會增加 EVM 的整體複雜性。
任何 L1 擴容路線圖需要回答的一個重要問題是:究竟什麼應該屬於 L1,什麼應該屬於 L2? 顯然,讓所有內容都運行在 L1 上是不現實的:潛在的用例可能需要每秒處理數十萬筆交易,這將使 L1 完全無法驗證(除非我們採用原生 rollup 路線)。 但我們確實需要一些指導原則,以確保我們不會陷入這樣的局面:將 gas 上限提高 10 倍,嚴重損害乙太坊 L1 的去中心化,結果卻只是將 99% 的活動在 L2 上降低到 90%,因此整體結果幾乎沒有變化,但卻不可逆轉地失去了乙太坊 L1 的許多獨特價值。
它與路線圖的其他部分如何互動?
將更多使用者引入 L1 意味著不僅要提高可拓展性,還需要改進 L1 的其他方面。 這意味著更多的 MEV 將留在 L1(而不是僅僅成為 L2 的問題),因此需要更緊迫地明確處理它。 這也極大地提高了在 L1 上實現縮短時隙消耗時間的價值。 此外,這在很大程度上取決於 L1 的驗證(即 “Verge” 階段)的順利推進。
免責聲明:作為區塊鏈資訊平臺,本站所發佈文章僅代表作者及嘉賓個人觀點,與 Web3Caff 立場無關。 文章內的資訊僅供參考,均不構成任何投資建議及要約,並請您遵守所在國家或地區的相關法律法規。










