

當我們回看 23 年中至今, 高額融資主要集中在遊戲我們曾討論過 AI 和 Web3 能夠如何各取所長,在計算網路、代理平臺和消費應用等各個垂直產業上相輔相成。 當聚焦在數據資源這一垂直領域,Web 新興代表專案為數據的獲取,共用和利用提供了新的可能性。
作者: IOSG Ventures
原用標題:去中心化數據層:AI 時代的新基礎設施 #247
封面:Photo by Google DeepMind on Unsplash

本文僅供學習交流使用,不構成任何投資建議。 轉載請註明出處,並與 IOSG 團隊聯繫獲取授權及轉載須知。 文章中提及的所有項目並非推薦或投資建議。
TL/ DR
我們曾討論過 AI 和 Web3 能夠如何各取所長,在計算網路、代理平臺和消費應用等各個垂直產業上相輔相成。 當聚焦在數據資源這一垂直領域,Web 新興代表專案為數據的獲取,共用和利用提供了新的可能性。
- 傳統數據供應商難以滿足 AI 和其他數據驅動產業對高品質、即時可驗證數據的需求,尤其在透明度、使用者控制和隱私保護方面存在局限
- Web3 方案正致力重塑數據生態。 MPC、零知識證明和 TLS Notary 等技術確保數據在多個來源之間流通時的真實性和隱私保護,分散式存儲和邊緣計算則為數據的實時處理提供了更高的靈活性和效率。
- 其中去中心化數據網路這一新興基礎設施萌生了幾個代表性專案 OpenLayer(模組化的真實數據層),Grass(利用使用者閑置頻寬和去中心化的爬蟲節點網路)和 Vana(使用者數據主權 Layer 1 網路),以不同的技術路徑為 AI 訓練和應用等領域開闢新的前景。
- 通過眾包的容量、無信任的抽象層和基於代幣的激勵機制,去中心化數據基礎設施能夠提供比 Web2 超大規模服務商更私密、安全、高效且經濟的解決方案,並且賦予使用者對其數據和其相關資源的控制權,構建一個更加開放、安全和互通的數位生態系統。
1. 數據需求浪潮
數據已成為各行業創新和決策的關鍵驅動。 UBS 預測全球數據量預計將在 2020 年至 2030 年間增長超過十倍達到 660 ZB,到 2025 年,全球每人每天將產生 463 EB(Exabytes,1EB=10 億 GB)的數據。 數據即服務(DaaS)市場在快速擴張,根據 Grand View Research 的報告,全球 DaaS 市場在 2023 年的估值為 143.6 億美元,預計到 2030 年將以 28.1% 的複合年增長率增長,最終達到 768 億美元。 這些高增長的數字背後是多個產業領域對高品質、即時可信賴數據的需求。
AI 模型訓練依賴大量數據輸入,用於識別模式和調整參數。 訓練后也需要數據集測試模型的性能和泛化能力。 此外,AI agent 作為未來可預見的新興智慧應用形式, 需要即時可靠的數據源,以確保準確的決策和任務執行。
商業分析的需求也在變得多樣和廣泛,並成為驅動企業創新的核心工具。 比如社交媒體平臺和市場研究公司需要可靠的使用者行為數據來制定策略和洞察趨勢,整合多個社交平臺的多元數據, 構建更全面的畫像。
對於 Web3 生態,鏈上也需要可靠真實數據來支援一些新型金融產品。 隨著越來越多新型資產在被通證化,需要靈活且可靠的數據介面,以支援創新產品的開發和風險管理,讓智慧合約可以基於可驗證的實時數據執行。
除了以上,還有科研,物聯網(IoT)等等。 新用例表面各行業對於多樣、真實、實時的數據需求激增,而傳統系統可能難以應對快速增長的數據量和不斷變化的需求。
2. 傳統數據生態的局限性和問題
典型的數據生態系統包括數據收集、存儲、處理、分析和應用。 中心化模式的特點是數據集中收集並存儲、由核心企業 IT 團隊管理運維, 並實施嚴格的訪問控制。 比如谷歌的數據生態系統涵蓋了從搜尋引擎、Gmail 到 Android 作業系統等多個數據源,通過這些平臺收集用戶數據, 儲存在其全球分佈的數據中心, 然後使用演算法處理和分析,以支撐各種產品和服務的開發與優化。 在金融市場里舉例,數據和基礎設施 LSEG(前 Refinitiv)則通過從全球交易所、銀行和其他主要金融機構獲取即時和歷史數據,同時利用自有的 Reuters News 網路收集市場相關新聞,運用專有演算法和模型生成分析數據和風險評估作為附加產品。
傳統數據架構在專業服務方面有效,但集中化模式的局限性日益明顯。 特別是在新興數據源的覆蓋、透明度和用戶隱私保護方面,傳統數據生態系統正面臨挑戰。 這裡例舉幾個方面:
- 數據覆蓋不足:傳統數據供應商在快速捕捉和分析如社交媒體情緒、物聯網設備數據等新興數據源方面存在挑戰。 中心化系統難以高效地獲取和整合來自眾多小規模或非主流來源的「長尾」數據。
比如 2021 年 GameStop 事件就揭示了傳統金融數據供應商在分析社交媒體情緒時的局限性。 Reddit 等平臺上的投資者情緒迅速改變了市場走勢,但像 Bloomberg 和 Reuters 這樣的數據終端未能及時捕捉到這些動態,導致市場預測滯後。
- 數據可訪問性受限:壟斷限制了可訪問性。 許多傳統供應商通過 API/雲服務開放部分數據,但高昂的訪問費用和複雜授權流程仍然增加了數據整合的難度。 鏈上開發者難以快速接入可靠的鏈下數據,高質量數據被少數巨頭壟斷,訪問成本高。
- 數據透明度和可信度問題:許多中心化數據供應商對其數據收集和處理方法缺乏透明度,且缺乏有效的機制來驗證大規模數據的真實性和完整性。 大規模實時數據的驗證仍然是一個複雜的問題, 中心化的本質也增加了數據被篡改或操縱的風險。
- 隱私保護和數據擁有權:大型科技公司大規模商用了用戶數據。 用戶作為私人數據的創造者,很難從中獲得應有的價值回報。 使用者通常無法瞭解他們的數據如何被收集、處理和使用,也難以決定數據的使用範圍和方式。 過度收集和使用也導致嚴重的隱私風險。 例如,Facebook 的 Cambridge Analytica 事件就暴露了傳統數據供應商如何在數據使用透明度和隱私保護方面存在巨大漏洞。
- 數據孤島:此外,不同來源、格式的實時數據難以快速整合,影響了全面分析的可能性。 很多數據往往被鎖在組織內部,限制了跨行業和跨組織的數據共享和創新,數據孤島效應阻礙了跨域的數據整合和分析。 比如在消費行業,品牌需要整合來自電商平臺、實體店、社交媒體和市場研究的數據,但這些數據可能由於平臺形式不統一或被隔離,難以整合。 再例如,像 Uber 和 Lyft 這樣的共用出行公司,雖然它們都收集大量來自使用者的,關於交通、乘客需求和地理位置的實時數據,但由於競爭關係,這些數據無法提出並共用整合。
除此以外,還有成本效率、靈活性等問題。 傳統數據商正在積極應對這些挑戰, 但異軍突起的 Web3 技術為解決這些問題提供了新的思路和可能性。
3.Web3 數據生態
自 2014 年 IPFS(InterPlanetary File System)等去中心化存儲方案發佈以來,業界湧現出一系列新興專案,致力於解決傳統數據生態的局限性。 我們看到去中心化數據解決方案已經形成了一個多層次、相互連接的生態系統,涵蓋了數據生命週期的各個階段,包括數據生成、存儲、交換、處理與分析、驗證與安全,以及隱私與擁有權。
- 數據存儲:Filecoin 和 Arweave 的快速發展證明瞭去中心化存儲(DCS)正在成為存儲領域的範式轉變。 DCS 方案通過分散式架構減少了單點故障風險,同時以更具競爭力的成本效益吸引參與者。 隨著一系列規模化應用案例的湧現,DCS 的存儲容量呈現爆髮式增長(例如 Filecoin 網路的總存儲容量在 2024 年已達到 22 exabytes)。
- 處理和分析:Fluence 等去中心化數據運算平臺通過邊緣計算(Edge Computing)技術提高了數據處理的即時性和效率,特別適用於物聯網(IoT)和 AI 推理等對即時性要求較高的應用場景。 Web3 專案利用聯邦學習、差分隱私、可信執行環境、全同態加密等技術在計算層上提供靈活的隱私保護和權衡。
- 數據市場/交換平臺:為了促進數據的價值量化和流通,Ocean Protocol 通過代幣化和 DEX 機制, 創建了高效且開放的數據交換管道, 例如説明傳統製造公司(賓士母公司 Daimler)合作開發數據交換市場,以説明其供應鏈管理中的數據分享。 另一方面,Streamr 則創造了適用於 IoT 和即時分析場景的無許可、訂閱式數據流網路,在交通、物流專案中顯示了出色的潛力(例如與芬蘭智慧城市專案合作)。
隨著數據交換和利用的日益頻繁,數據的真實性、可信度和隱私保護成為了不可忽視的關鍵問題。 這促使 Web3 生態系統將創新延伸到了數據驗證和隱私保護領域,催生了一系列突破性的解決方案。
3.1 數據驗證與隱私保護的革新
許多 web3 技術及原生專案正致力於解決數據真實性和私有數據保護問題。 除了 ZK,MPC 等技術發展被廣泛應用,其中傳輸層安全協定公證(TLS Notary)作為一種新興的驗證方法尤其值得關注。
TLS Notary 簡介
傳輸層安全協定(TLS)是一種廣泛用於網路通信的加密協定,旨在確保客戶端和伺服器之間的數據傳輸的安全性、完整性和保密性。 它是現代網路通信中常見的加密標準,被用於 HTTPS、電子郵件、即時通訊等多個場景。
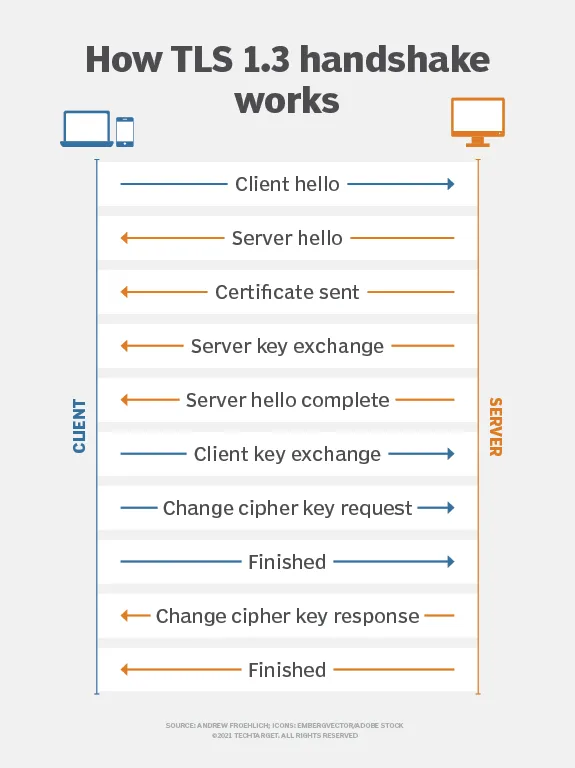
十年前誕生之際,TLS Notary 的最初目標是通過在用戶端(Prover)、伺服器以外引入第三方「公證人」來驗證 TLS 會話的真實性。
使用密鑰分割技術,TLS 會話的主金鑰被分為兩部分,分別由用戶端和公證人持有。 這種設計允許公證人作為可信第三方參與驗證過程,但不能訪問實際通信內容。 這種公證機制旨在檢測中間人攻擊、防止欺詐性證書,確保通信數據在傳輸過程中沒有被篡改,並允許受信任的第三方確認通信的合法性,同時保護通信隱私。
由此,TLS Notary 提供了安全的數據驗證,並有效平衡了驗證需求和隱私保護。
在 2022 年, TLS Notary 專案由乙太坊基金會的隱私和擴展探索(PSE)研究實驗室重新構建。 新版本的 TLS Notary 協定從頭開始用 Rust 語言重寫, 融入了更多先進的加密協定(如 MPC), 新的協定功能允許使用者向第三方證明他們從伺服器接收到的數據的真實性,同時不洩露數據內容。 在保持原有 TLS Notary 核心驗證功能的同時,大幅提升了隱私保護能力,使其更適合當前和未來的數據隱私需求。
3.2 TLS Notary 的變體與擴展
近年 TLS Notary 技術也在持續演進,在基礎上發展產生了多個變體,進一步增強了隱私和驗證功能:
- zkTLS:TLS Notary 的隱私增強版本,結合了 ZKP 技術,允許使用者生成網頁數據的加密證明,而無需暴露任何敏感資訊。 它適用於需要極高隱私保護的通信場景。
- 3P-TLS(Three-Party TLS):引入了用戶端、伺服器和審計者三方,在不洩露通信內容的情況下,允許審計者驗證通信的安全性。 這一協定在需要透明度但同時要求隱私保護的場景中非常有用,如合規審查或金融交易的審計。
Web3 專案們使用這些加密技術來增強數據驗證和隱私保護,打破數據壟斷,解決數據孤島和可信傳輸問題,讓使用者得以不洩露隱私地證明如社媒賬號擁有權、用以金融借貸的購物記錄,銀行信用記錄、職業背景和學歷認證等資訊,比如:
- Reclaim Protocol 使用 zkTLS 技術,生成 HTTPS 流量的零知識證明,允許使用者從外部網站安全導入活動、聲譽和身份數據,而無需暴露敏感資訊。
- zkPass 結合 3P-TLS 技術,允許使用者無洩露地驗證真實世界的私有數據,廣泛應用於 KYC、信用服務等場景,並且與 HTTPS 網路相容。
- Opacity Network 基於 zkTLS,允許使用者安全地證明他們在各個平臺(如 Uber、Spotify、Netflix 等)的活動,而無需直接訪問這些平臺的 API。 實現跨平臺活動證明。
Web3 數據驗證作為數據生態鏈條上的一個重要環節,應用前景十分廣闊,其生態的興榮正引導著一個更開放、動態和以使用者為中心的數字經濟。 然而,真實性驗證技術的發展僅僅是構建新一代數據基礎設施的開始。
4. 去中心化數據網路
一些專案則結合上述的數據驗證技術,在數據生態的上游,即數據溯源、數據的分散式採集和可信傳輸上做出更深入的探索。 下面重點討論幾個代表性專案:OpenLayer,Grass 和 Vana,它們在構建新一代數據基礎設施方面展現出獨特的潛力。
4.1 開放層
OpenLayer 是 a16z Crypto 2024 春季加密創業加速器專案之一,作為首個模組化的真實數據層,致力於提供一個創新的模組化解決方案,用於協調數據的收集、驗證和轉換,以同時滿足 Web2 和 Web3 公司的需求。 OpenLayer 已吸引了包括 Geometry Ventures、LongHash Ventures 在內的知名基金和天使投資者的支援。
傳統數據層存在多重挑戰:缺乏可信驗證機制,依賴中心化架構導致訪問性受限,不同系統間的數據缺乏互操作性和流動性,同時也沒有公平的數據價值分配機制。
一個更加具象化的問題是,當今 AI 訓練數據正變得日益稀缺。 在公共互聯網上,許多網站開始通過反爬蟲限制措施來防止 AI 公司大規模抓取數據。
而在私密專有數據方面,情況則更為複雜,許多有價值的數據由於其敏感性質而以隱私保護的方式存儲,缺乏有效的激勵機制。 在這種現狀下,用戶無法安全地通過提供私人數據獲得直接收益,因此不願意共用這些敏感數據。
為了解決這些問題,OpenLayer 結合數據驗證技術搭建了一個模組化真實數據層(Modular Authentic Data Layer),並以去中心化+經濟激勵的方式來協調數據收集、驗證和轉換過程,為 Web2 和 Web3 公司提供一個更安全、高效率、靈活的數據基礎設施。
4.1.1OpenLayer 模組化設計的核心元件
OpenLayer 提供了一個模組化的平臺以簡化數據的收集、可信驗證和轉換過程流程:
a)開放節點
OpenNodes 是 OpenLayer 生態系統中負責去中心化數據收集的核心元件,通過使用者的行動應用、瀏覽器擴展等管道收集數據,不同的運營商/節點可以根據其硬體規格執行最適合的任務而優化回報。
OpenNodes 支援三種主要的數據類型,以滿足不同類型任務的需求:
- 公開可用的互聯網數據(如金融數據、天氣數據、體育數據和社交媒體流)
- 使用者私人資料(如 Netflix 觀看歷史、Amazon 訂單記錄等)
- 來自安全來源的自報告數據(如由專有擁有者簽名或特定可信硬體驗證的數據)。
開發者可以輕鬆添加新的資料類型, 指定新的資料來源,需求和數據檢索方法, 使用者可以選擇提供去識別化的數據以換取獎勵。 這種設計使得系統可以不斷擴展以適應新的數據需求,多樣化的數據源使得 OpenLayer 能夠為各種應用場景提供全面的數據支援,也降低了數據提供的門檻。
b) OpenValidators
OpenValidators 負責收集之後的數據驗證,允許數據消費者確認使用者提供的數據與數據源的完全匹配。 所有提供的驗證方法可以進行加密證明的, 驗證結果可以在事後被證實。 同一類型的證明, 有多個不同的供應商提供服務。 開發者可以根據自己的需求選擇最適合的驗證供應商。
在初始用例中, 特別是針對來自互聯網 API 的公共或私有數據, OpenLayer 以 TLSNotary 作為驗證解決方案,從任何 Web 應用程式匯出數據, 並在不損害隱私的情況下證明數據的真實性。
不局限於 TLSNotary,得益於其模組化設計, 驗證系統可以輕鬆接入其他驗證方法,以適應不同類型的數據和驗證需求包括但不限於:
- Attested TLS connections: 利用可信執行環境(TEE)建立經過認證的 TLS 連接, 確保數據在傳輸過程中的完整性和真實性。
- Secure Enclaves: 使用硬體級別的安全隔離環境(如 Intel SGX)來處理和驗證敏感數據, 提供更高級別的數據保護。
- ZK Proof Generators: 集成 ZKP, 允許在不洩露原始資料的情況下驗證資料的屬性或計算結果。
c) OpenConnect
OpenConnect 是 OpenLayer 生態系統中負責資料轉換,實現可用性的核心模組,處理來自各種來源的數據, 確保數據在不同系統間的互操作性, 以滿足不同應用的需求。 例如:
- 將數據轉換為鏈上預言機(Oracle)格式, 便於智慧合約直接使用。
- 將非結構化原始數據轉換為結構化數據, 為 AI 訓練等目的進行預處理。
對於來自使用者私人賬戶的數據,OpenConnect 提供了數據脫敏功能以保護隱私,也提供了元件來增強數據共享過程中的安全性, 減少數據洩露和濫用。 為了滿足 AI 和區塊鏈等應用對實時數據的需求, OpenConnect 支援高效的即時數據轉換。
當下,通過和 Eigenlayer 的集成,OpenLayer AVS 運營商監聽數據請求任務, 負責抓取數據並進行驗證, 然後將結果報告回系統,通過 EigenLayer 質押或重質押資產, 為其行為提供經濟擔保。 如惡意行為被證實, 將面臨質押資產被罰沒的風險。 作為 EigenLayer 主網上最早的的 AVS(主動驗證服務)之一,OpenLayer 已經吸引了超過 50 個營運商和 40 億美元的再質押資產。
總的來說,OpenLayer 所構建的去中心化數據層在不犧牲實用性和效率的前提下,擴展了可用數據的範圍和多樣性, 同時通過加密技術和經濟激勵,確保了數據的真實性和完整性。 其技術對於尋求獲取鏈下資訊的 Web3 Dapp、需要用真實輸入來訓練和推斷的 AI 模型,以及希望根據現有身份和聲譽來細分和定位使用者的公司都有廣泛的實際用例。 使用者也得以價值化他們的私有數據。
4.2 Grass
Grass 是由 Wynd Network 開發的旗艦專案,旨在創建一個去中心化的網路爬蟲和 AI 訓練數據平臺。 在 2023 年末,Grass 專案完成了由 Polychain Capital 和 Tribe Capital 領投的 350 萬美元種子輪融資。 緊接著,在 2024 年 9 月,專案又迎來了由 HackVC 領投的 A 輪融資,Polychain、Delphi、Lattice 和 Brevan Howard 等知名投資機構也參與其中。
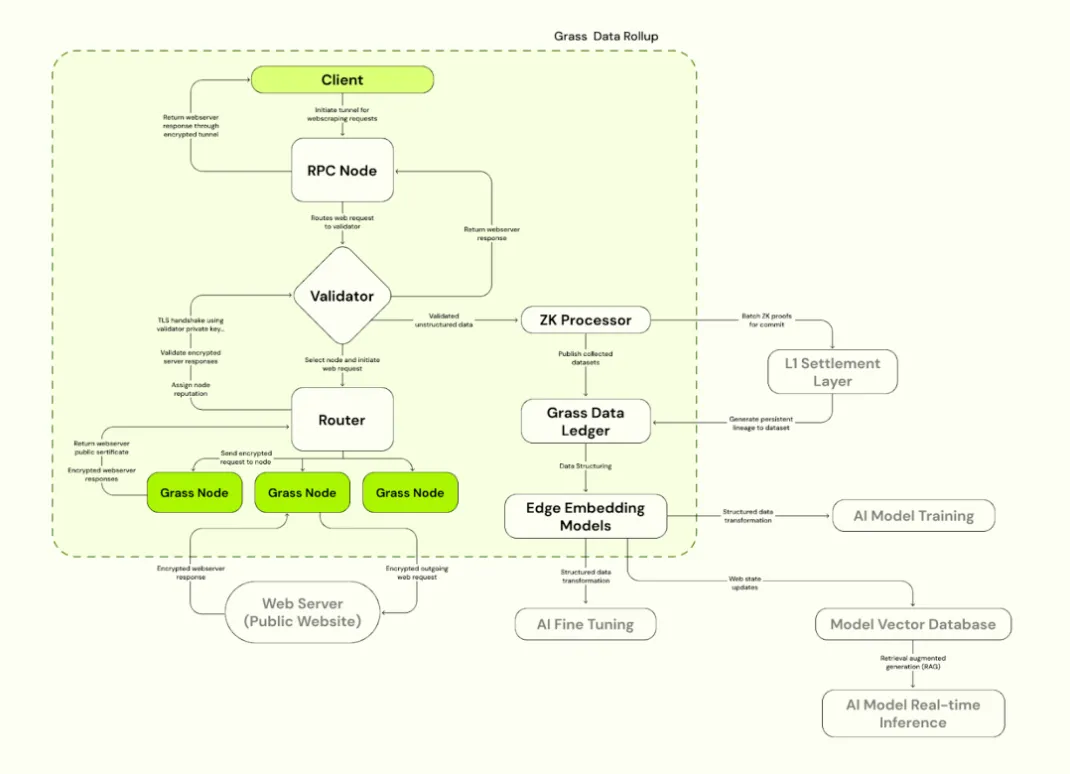
我們提到 AI 訓練需要新的數據敞口,而其中一個解決方案是使用多 IP 來突破數據訪問的許可權,為 AI 進行數據餵養。 Grass 由此出發,創造了一個分散式爬蟲節點網路, 專門致力於以去中心化物理基礎設施的方式,利用使用者的閑置頻寬為 AI 訓練收集並提供可驗證數據集。 節點通過使用者的互聯網連接路由 web 請求, 存取公開網站並編譯結構化數據集。 它使用邊緣計算技術進行初步數據清理和格式化, 提高數據品質。
Grass 採用了 Solana Layer 2 Data Rollup 架構, 建立在 Solana 之上以提高處理效率。 Grass 使用驗證器接收、驗證和批處理來自節點的 web 交易, 生成 ZK 證明以確保數據真實性。 驗證後的數據儲存在數據帳本(L2)中, 並連結到相應的 L1 鏈上證明。
4.2.1 Grass 主要元件
a)Grass 節點
與 OpenNodes 類似,C 端使用者安裝 Grass 應用或瀏覽器擴展並運行, 利用閒置頻寬進行網路爬蟲操作, 節點透過使用者的互聯網連接路由 web 請求, 訪問公開網站並編譯結構化數據集,使用邊緣計算技術進行初步數據清理和格式化。 用戶根據貢獻的頻寬和數據量獲得 GRASS 代幣獎勵。
b)路由器(Routers)
連接 Grass 節點和驗證器, 管理節點網路並中繼頻寬。 Routers 被激勵運營並獲得獎勵, 獎勵比例與通過其中繼的總驗證頻寬成正比。
c)驗證器(Validators)
接收、驗證和批處理來自路由器的 web 交易, 生成 ZK 證明,使用獨特的金鑰集來建立 TLS 連接, 為與目標 web 伺服器的通訊選擇適當的密碼套件。 Grass 目前採用中心化驗證器, 未來計劃轉向驗證器委員會。
d)ZK 處理器(ZK Processor)
接收來自驗證者的生成每個節點會話數據的證明,批處理所有 web 請求的有效性證明並提交到 Layer 1(Solana)。
e)Grass 數據帳本(Grass L2)
存儲完整的數據集,並連結到相應的 L1 鏈(Solana)上證明。
f)邊緣嵌入模型
負責將非結構化 web 資料轉換為可用與 AI 訓練的結構化模型。
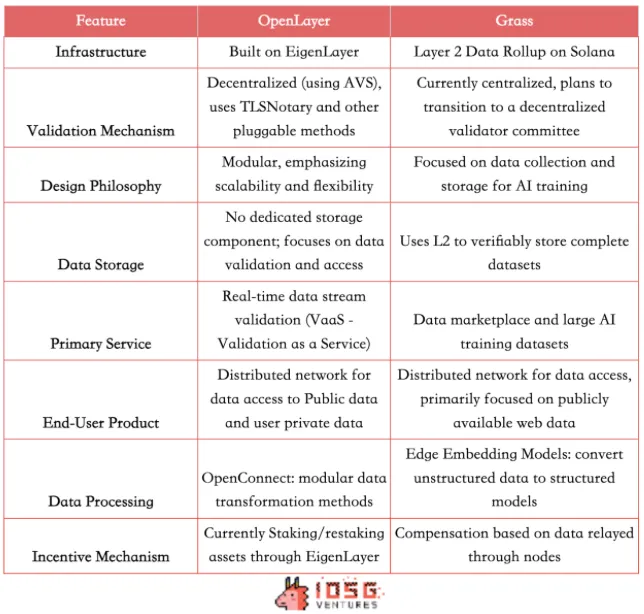
分析對比 Grass 和 OpenLayer
OpenLayer 和 Grass 都利用分散式網路為公司提供了訪問開放互聯網數據和需要身份驗證的封閉信息的機會。 以激勵機制促進了數據共享和高質量數據的生產。 兩者都致力於創造一個去中心化數據層(Decentralized Data Layer)以解決數據獲取訪問和驗證的問題, 但採用了略有不同的技術路徑和商業模式。
技術架構的不同
Grass 使用 Solana 上的 Layer 2 Data Rollup 架構, 目前採用中心化的驗證機制, 使用單一的驗證器。 而 Openlayer 作為首批 AVS,基於 EigenLayer 構建, 利用經濟激勵和罰沒機制實現去中心化的驗證機制。 並採用模組化設計,強調數據驗證服務的可擴展性和靈活性。
產品差異
兩者都提供了類似的 To C 產品,允許使用者通過節點進行數據的價值變現。 在 To B 用例上,Grass 提供了一個有趣的數據市場模型,並使用 L2 來可驗證地存儲完整的數據,來為 AI 公司提供結構化、高品質、可驗證的訓練集。 而 OpenLayer 並沒有暫時專用的數據儲存元件,但提供更廣泛的即時數據流驗證服務(Vaas),除了為 AI 提供數據,也適用於需要快速響應的場景,比如作為 Oracle 為 RWA/DeFi/預測市場專案餵價,提供即時社交數據等等。
因此,如今 Grass 的目標客戶群主要面向 AI 公司和數據科學家,提供大規模、結構化的訓練數據集,也服務於需要大量網路數據集的研究機構和企業; 而 Openlayer 則暫時面向需要鏈下數據源的鏈上開發者,需要即時、可驗證的數據流的 AI 公司,以及支援創新的用戶獲取策略,如驗證競品使用歷史的 Web2 公司。
未來的潛在競爭
然而,考慮到行業發展趨勢, 兩個專案的功能確實有可能在未來趨同。 Grass 不久後可能也將提供即時的結構化數據。 而 OpenLayer 作為一個模組化平臺, 未來也有可能擴展到數據集管理擁有自己的 data ledger, 因此兩者的競爭領域可能會逐漸重疊。
並且,兩個專案都可能會考慮加入數據標註(data labelling)這一關鍵環節。 Grass 在這方面可能會更快推進, 因為他們擁有龐大的節點網路 - 據報導已超過 220 萬個活躍節點。 這一優勢使 Grass 有潛力提供基於人類反饋的強化學習(RLHF)服務, 利用大量標註數據來優化 AI 模型。
然而,OpenLayer 憑藉其在數據驗證和實時處理方面的專長, 其在私人數據的專注,可能會在數據品質和可信度方面保持優勢。 此外,OpenLayer 作為 Eigenlayer 的 AVS 之一, 可能在去中心化驗證機制上有更深入的發展。
儘管兩個專案可能在某些領域展開競爭, 但它們各自的獨特優勢和技術路線也可能導致它們在數據生態系統中佔據不同的利基市場。
4.3 VAVA
作為一個以使用者為中心的數據池網路,Vana 同樣致力於為 AI 和相關應用提供高質量數據。 相比 OpenLayer 和 Grass,Vana 採用了更不同的技術路徑和商業模式。 Vana 在 2024 年 9 月完成 500 萬美元融資,由 Coinbase Ventures 領投,此前獲得 Paradigm 領投的 1800 萬美元 A 輪融資,其他知名投資者包括 Polychain, Casey Caruso 等。
最初於 2018 年作為 MIT 的一個研究項目啟動,Vana 旨在成為一個專門為使用者私有數據設計的 Layer 1 區塊鏈。 其在數據擁有權和價值分配上做出的創新使用戶能夠從基於其數據訓練的 AI 模型中獲利。 Vana 的核心在於通過無需信任、私密且可歸因的數據流動性池(Data Liquidity Pool)和創新的 Proof of Contribution 機制來實現私人數據的流通和價值化:
4.3.1. 數據流動性池(Data Liquidity Pool)
Vana 引入了一個獨特的資料流動性池(DLP)概念:作為 Vana 網路的核心元件,每個 DLP 都是一個獨立的點對點網路,用於聚合特定類型的數據資產。 用戶可以將他們的私人數據(如購物記錄、瀏覽習慣、社交媒體活動等)上傳至特定 DLP,並靈活選擇是否將這些數據授權給特定的第三方使用。 數據通過這些流動性池被整合和管理,這些數據經過去識別化處理,確保使用者隱私的同時允許數據參與商業應用,例如用於 AI 模型訓練或市場研究。
使用者向 DLP 提交數據並獲得相應的 DLP 代幣(每一個 DLP 都有特定的代幣)獎勵,這些代幣不僅代表使用者對數據池的貢獻,還賦予使用者對 DLP 的治理權和未來利潤分配權。 用戶不僅可以分享數據,還可以從數據的後續調用中獲取持續的收益(並提供可視化追蹤)。 與傳統的單次數據售賣不同,Vana 允許數據持續參與經濟迴圈。
4.3.2. Proof of Contribution 機制
Vana 的另一核心創新之一是 Proof of Contribution(貢獻證明)機制。 這是 Vana 確保數據品質的關鍵機制,讓每個 DLP 可以根據其特性定製獨特的貢獻證明函數,以驗證數據的真實性和完整性,並評估數據對 AI 模型性能提升的貢獻。 這一機制確保使用者的數據貢獻得到量化和記錄,從而為使用者提供獎勵。 與加密貨幣中的「工作量證明」(Proof of Work)類似,Proof of Contribution 根據使用者貢獻的數據質量、數量以及被使用的頻次來為使用者分配收益。 通過智慧合約自動執行,確保貢獻者獲得與其貢獻匹配的獎勵。
Vana 的技術架構
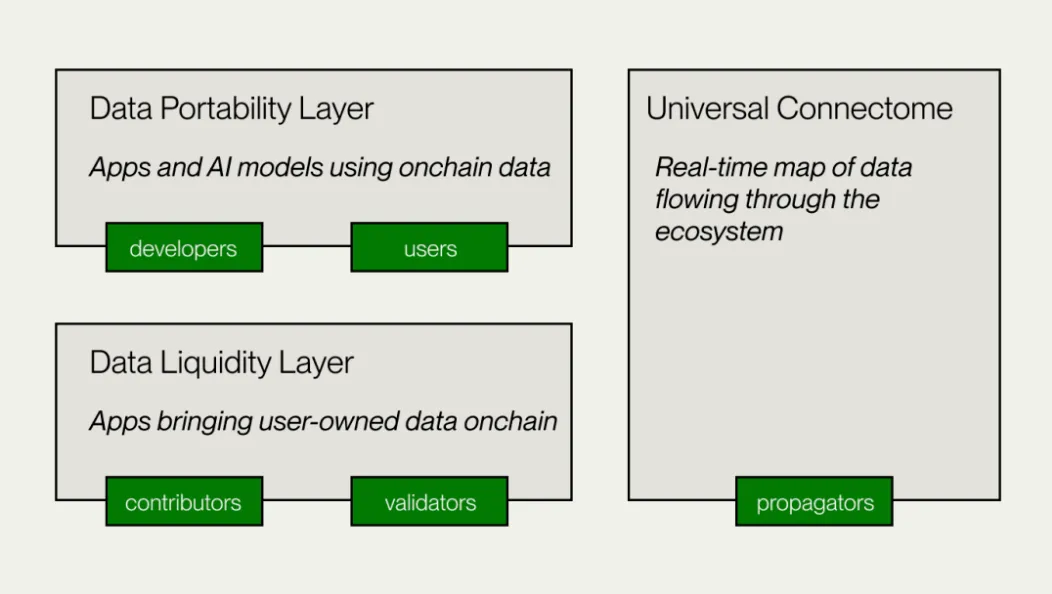
- 數據流動性層(Data Liquidity Layer)
這是 Vana 的核心層,負責數據的貢獻、驗證和記錄到 DLPs,將數據作為可轉移的數位資產引入鏈上。 DLP 建立者部署 DLP 智慧合約,設定數據貢獻目的、驗證方法和貢獻參數。 數據貢獻者和託管者提交數據進行驗證,貢獻證明(PoC)模組會執行數據驗證和價值評估,根據參數給予治理權和獎勵。
- 資料可移植層(Data Portability Layer)
這是數據貢獻者和開發者的開放數據平臺,也是 Vana 的應用層。 Data Portability Layer 為數據貢獻者和開發者提供一個協作空間,以使用 DLPs 中積累的數據流動性構建應用。 為 User-Owned 模型分散式訓練,AI Dapp 開發提供基礎設施。
- 通用連接群組(Connectome)
一個去中心化帳本,也是一個貫穿整個 Vana 生態系統的實時數據流圖,使用權益證明共識(Proof of Stake)記錄 Vana 生態系統中的實時數據交易。 確保 DLP 代幣的有效轉移並為應用提供跨 DLP 數據訪問。 與 EVM 相容,允許與其他網路、協定和 DeFi 應用程式互操作。
Vana 提供了一條較為不同的路徑,專注於用戶數據的流動性和價值賦能,這種去中心化的數據交換模式不僅適用於 AI 訓練、數據市場等場景,也為 Web3 生態系統中用戶數據的跨平臺互通與授權提供了一個新的解決方案,最終創建一個開放的互聯網生態系統,讓使用者擁有並管理自己的數據,以及由這些數據創造的智慧產品。
5. 去中心化數據網路的價值主張
數據科學家克萊夫·哈姆比(Clive Humby)在 2006 年說過數據是新時代的石油。 近 20 年間,我們見證了 “提煉” 技術的飛速發展。 大數據分析、機器學習等技術使得數據價值得到了空前釋放。 根據 IDC 的預測,到 2025 年,全球數據圈將增長到 163 ZB,其中大部分將來自個人使用者,隨著 IoT、可穿戴設備、AI 與個人化服務等新興科技的普及,未來大量需要商用的數據將也將來源於個人。
傳統方案的痛點:Web3 的解鎖創新
Web3 數據解決方案通過分散式節點網路,突破了傳統設施的局限,實現了更廣泛、更高效的數據採集,同時提升了特定數據的實時獲取效率和驗證可信度。 在此過程中,Web3 技術確保了數據的真實性和完整性,並能有效保護使用者隱私,從而實現更公平的數據利用模式。 這種去中心化的數據架構,推動了數據獲取的民主化。
不管是 OpenLayer 和 Grass 的用戶節點模式,還是 Vana 通過使用者私有數據的貨幣化,除了提高特定數據採集的效率,也讓普通使用者共用數據經濟的紅利,創造一種使用者與開發者雙贏的模式,讓使用者真正掌控和獲益於他們的數據和相關資源。
通過代幣經濟,Web3 數據方案重新設計了激勵模型,創造了一個更加公平的數據價值分配機制。 吸引了大量使用者、硬體資源與資本的注入,從而協調並優化了整個數據網路的運行。
比起傳統數據解決方案,它們也擁有模組化與可擴充性:比如 Openlayer 的模組化設計,為未來的技術反覆運算和生態擴展提供了靈活性。 得益於技術特性,優化 AI 模型訓練的數據獲取方式,提供更豐富、更多樣化的數據集。
從數據生成、存儲、驗證到交換與分析,Web3 驅動的解決方案通過獨有技術優勢解決者傳統設施的諸多弊端,同時也賦予使用者對個人數據的變現能力,引發數據經濟模式的根本轉變。 隨著技術進一步發展演進和應用場景的擴大,去中心化數據層有望和其他 Web3 數據解決方案一起,成為下一代關鍵基礎設施,為廣泛的數據驅動型產業提供支援。
免責聲明:作為區塊鏈資訊平臺,本站所發佈文章僅代表作者及嘉賓個人觀點,與 Web3Caff 立場無關。 文章內的資訊僅供參考,均不構成任何投資建議及要約,並請您遵守所在國家或地區的相關法律法規。










