

加密领域开发一定会出现一种更加便捷和原生的链上数据处理体系,或许 shadow 能够给我们带来对未来数据基建的惊鸿一瞥。
作者:Masterdai
未来闯入我们之间,为了能在它发生之前很久就先行改变我们。—里尔克
引言
自从 Dune Analytics 于 2018 年在挪威奥斯陆成立以来,已经过去了整整六年。在这六年的时间里,Dune Analytics 从一个仅有 18 人的小公司,成长为估值超过 10 亿美元的加密独角兽。它的业务也从最初仅为分析师提供数据分析图表,扩展到向开发者提供数据服务,并成功实现盈利。
不只是 Dune Analytics,随着越来越多的开发者加入加密行业,链上项目的业务逻辑也变得日益复杂。这种复杂性也推动了对数据基础设施的需求,通过一张图表,我们可以直观地看到这一点:

根据 PrimoData 的数据统计 (https://www.primodata.org/blockchain-data-landscape),截至 2024 年,仅 “链上数据” 这一类别就涵盖了 58 个项目方。毫无疑问,这些项目大多采用了类似云数据仓库的架构。我之前曾撰写过一篇介绍这类架构的原理及其优劣势的文章,在这里就不再赘述。
值得一提的是,当我两年前撰写这些架构原理时,并没有预见到区块链行业将发生的一些翻天覆地的变化。在我看来,这些变化可能会使得一些项目从破坏性创新的角度颠覆整个行业,例如图表中的 Shadow 和 Ghostlog。
变化与挑战
区块链开发的技术门槛正在降低,这得益于二层网络技术的成熟、模块化区块链的引入,以及像 Optimism 等生态相关代码的开源。这些变化显著加速了新公链的诞生,但也带来了多链环境下的额外存储和解析成本。随着用户数量增加和链上活动频繁,链上数据的解析速度常常跟不上新链的开发速度。
智能合约的复杂度也在增加,特别是新的开发框架如 Mud 和 Dojo,这些专门为全链游戏开发设计的框架使得智能合约复杂度远超传统的 DeFi 合约。新的 DeFi 应用和其他应用需要设计更复杂的合约逻辑,而一旦合约变得复杂,传统的数据解析方式就会变得缓慢或失效。尽管 Subgraph 曾是合约数据解析的佼佼者,但在处理这些复杂合约时,即便结合其他 API 使用,也显得力不从心。用户的快速增加带来了数据量的爆炸性增长,使得数据变得更加复杂和多样化。
这些技术进步和市场的变化不仅对链上数据基建项目带来了直接挑战,也对加密开发的两类关键人员产生了负面干扰。
第一类是加密数据基础设施公司雇佣的后端工程师。在获取 DeFi 数据的过程中,这些工程师需要花费大量时间来理解和处理智能合约。由于缺乏行业内的统一标准,他们在理解 Solidity 的基础上,花费了约 90% 的时间,剩下的时间才用于数据的部署和清洗。这导致即使是完成同样的任务,不同公司的工程师处理出的数据格式也各不相同,比如 A 公司和 B 公司就可能有不同的数据输出格式。
第二类是使用这些数据的下游开发者,他们常常需要同时调用多个公司的 API。由于每个公司提供的数据格式不统一,这增加了下游开发者的工作量,因为他们不得不在开发过程中处理各种不一致的数据格式,这不仅增加了开发的复杂性,还可能影响到最终应用的性能和可靠性。
对于数据基建项目方而言,他们面临着两方面的压力。在供给端,随着链上数据量的爆炸性增长,云数据仓库的成本也在不断上升。而在需求端,伴随着开发者、存量付费用户以及公链商务相关人员的不断呼吁,迫使项目方不得不采纳一些并不重要的公链和更加复杂的数据格式。进一步增加自己运维和服务端端压力。
正因如此,数据基建项目方的处境可以比喻为温水中的青蛙,逐渐适应不断恶化的环境,却未必察觉到逼近的危机。未来,随着新需求带来的收益无法覆盖不断增加的云服务成本,这些项目可能会陷入资源耗竭的困境。这种持续的资源消耗战可能导致资金雄厚的公司以惨烈的方式赢得市场,而资源较少的公司则有可能沦为竞争中的牺牲品
如此背景下,我们不禁要问:现有的数据基础设施是否足以应对这些挑战?或者,我们是否需要一种全新的思路和方法来应对这些变化?
破局
换言之,随着区块链应用的增多和数据量的激增,传统的区块链基础设施已经显得捉襟见肘。开发者正寻求一种更高效、成本更低的解决方案来处理这些问题。此时,Shadow Fork 影子分叉技术应运而生,提供了一个创新的出路。
Shadow Fork 是一种允许开发者在不影响主链的情况下,创建和测试新的区块链协议或改动的技术。这种方法可以看作是一个沙盒环境,它模拟主链的当前状态,允许开发者在一个封闭和控制的环境中进行实验和验证。
有意思的是,早期的 Shadow Fork 技术并非被设计用来索引链上数据。相反,它首先被视为一种工具,使开发者能在一个模拟的环境中自由创造事件和进行合约调试。在这个虚拟的 “沙盒” 中,开发者不需要担心合约的长度限制,可以自由地测试和修改代码。这种使用方式极大地节省了将功能部署到主网时调用产生的 gas 费用。然而,随着时间的推移,开发者发现这种模拟环境不仅适用于测试和开发,它也能够有效地用作获取和分析链上数据的平台。
Shadow Fork 技术解析
想象一下,在不久的将来,医学技术经历了巨大的飞跃,纳米机器人的发明被广泛应用于监测人体的各种生命体征,如血糖和激素水平。然而,这项技术面临一个挑战:它无法获取纳米机器人发明之前人们的医疗数据。这意味着对于那些在纳米技术尚未出现时就已经活跃的病人,现代医疗技术无法提供有效的诊断。
在这种情况下,一个具有前瞻性的年轻黑客提出了一个解决方案。他通过大数据模拟技术,重现了一个病人从出生至今的生活历程,创建了一个与现实生活完全一致的虚拟环境。在这个环境中,纳米机器人可以被植入模拟出的婴儿状态的病人体内,并随着虚拟环境中时间的加速,直到与现实世界同步。这一过程使得医生能够获得病人完整的生命历程数据,为诊断和治疗提供了前所未有的深度和准确性。
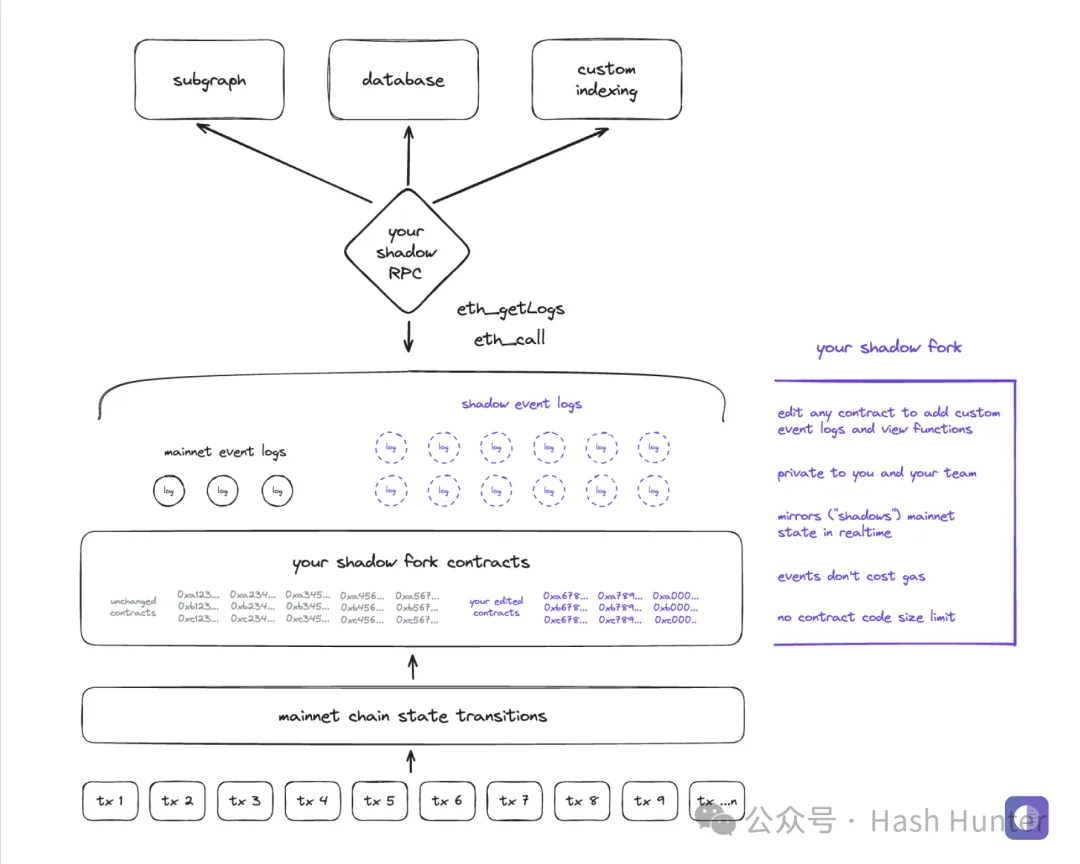
而 Shadow Fork 就是区块链版本的虚拟环境。与其他 data infra 通过构建云数仓来存储数据不同的是,shadow 实际上是重新魔改了以太坊的节点代码,并且将过去所有主网上的信息拷贝了下来。通过将修改过的节点重新的部署到自己的私有环境,通过将历史数据重放。实现了影子分叉的功能,换句话说,影子分叉里的历史合约和所有的用户交易数据都是永远和主网保持一致的,相当于主网络的平行世界,在 shadow fork 环境中,开发者不仅能访问并修改过去部署的合约,还可以利用 shadow contract 进一步扩展和优化这些合约。
Shadow contract 是一种特殊的智能合约,其核心功能是允许开发者在不影响公链合约安全性和稳定性的前提下,增加新的事件和功能。这种合约在 shadow fork 上运行,可以自由地添加或修改代码,而不受主网智能合约大小限制的约束。这为开发者提供了前所未有的灵活性,使他们能够实验和部署新功能,而无需担心影响现有用户的体验或合约的执行效率。
例如,如果一个开发者想要在已部署的合约中增加一个新的观察功能或自定义事件,他可以在 shadow fork 上对该合约进行修改,创建一个 shadow contract,然后在这个新的合约版本中实现所需的功能。这个过程不仅不会消耗任何 gas 费用,而且可以随时更新和迭代,极大地增强了合约的可维护性和可扩展性。
同时,shadow event 是 shadow contract 的一个重要组成部分,它允许开发者定义特定的事件日志,这些日志仅存在于 shadow contract 中。这意味着开发者可以创建用于特定分析、索引或测试目的的定制事件,而无需担心这些操作会增加公链上的交易成本或数据存储负担。
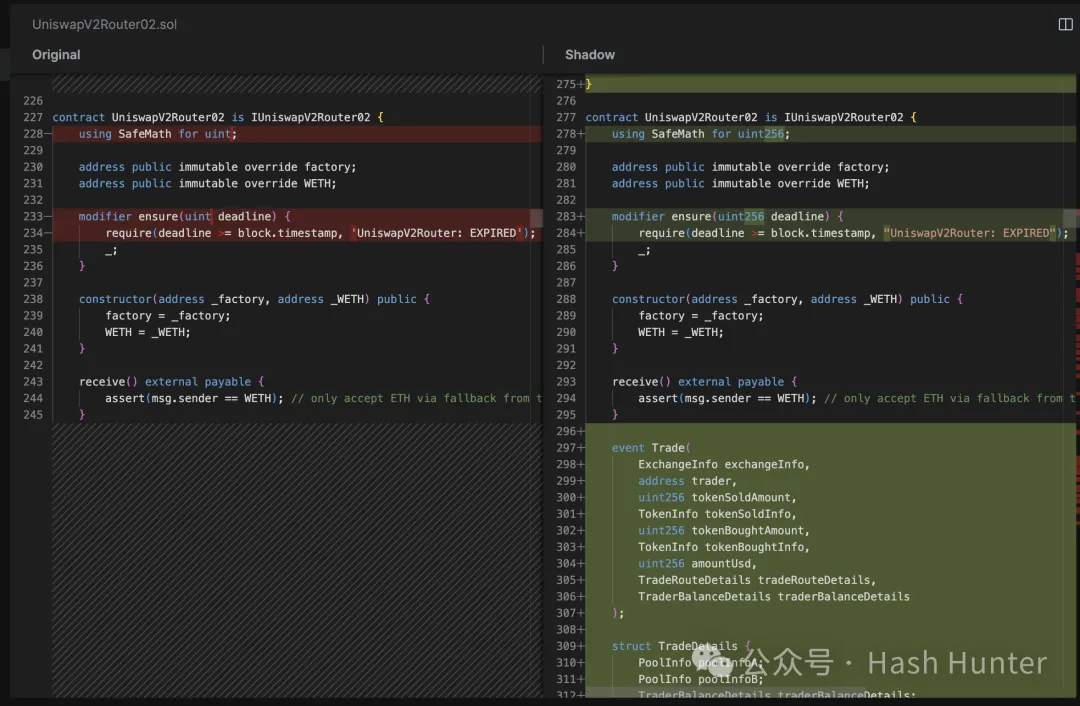
如上图所示。在左边的代码中,我们看不到任何有关 Trade 事件的定义,这表明它是原始的、在主网上的 uniswap v2 的合约代码。然而,在右边的 “Shadow” 版本中,我们可以看到一个新增的 `Trade` 事件,这个事件在合约中被定义,当交易发生时被触发。也就是说当主网上出现一笔新交易时,这笔交易就会变重放到 shadow fork 环境中,并且以定制化的版本再跑一次从而溢出你想要的信息。
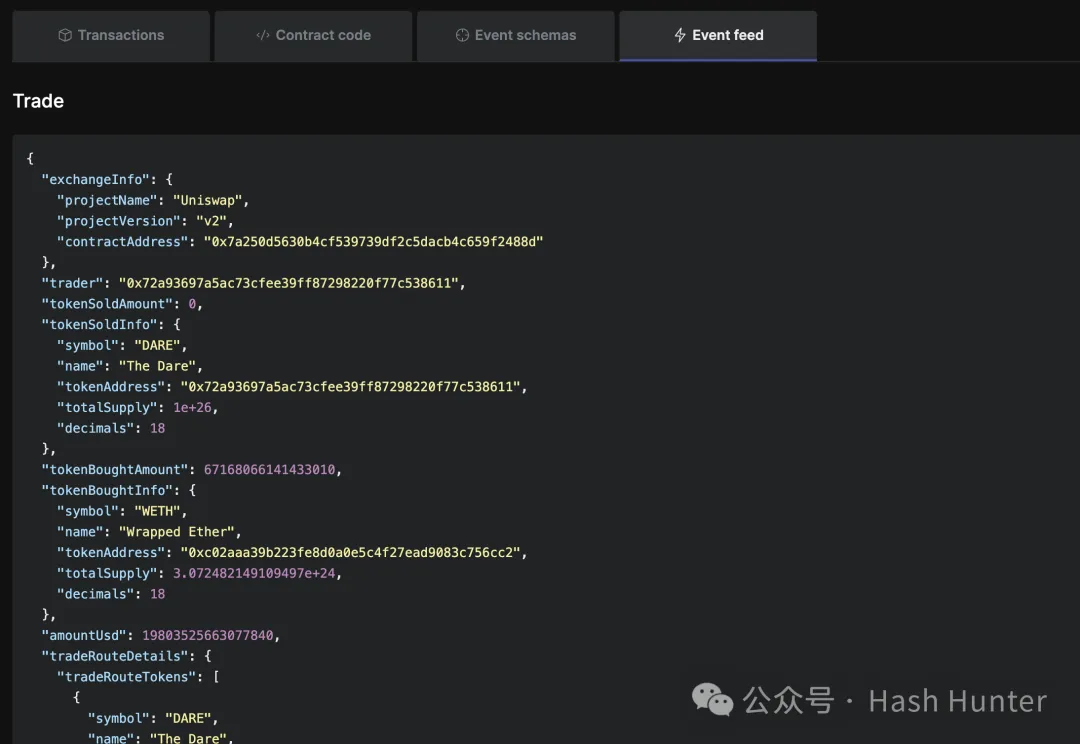
从这段数据返回中我们可以看到。`Trade` 事件记录了交易相关的一系列参数,如 `exchangeInfo`、`trader`、`tokenSoldAmount`、`tokenBoughtAmount` 等等。这些参数提供了交易的详细信息,包括交易者地址、卖出和买入的代币数量及其相应的信息。
通过这些详细数据,开发者可以监控交易活动,并进行复杂的数据分析和索引,这在传统的公链合约中可能需要昂贵的 gas 费用和复杂的数据管道来实现。
对现有基础设施的颠覆
在传统领域中,开发者主要通过两种渠道获取链上数据:一种是直接从公共或自建节点请求实时数据,如区块高度和特定地址的余额;另一种是通过第三方数据提供商获取处理过的历史数据,如地址聚合持仓或特定交易的 MEV 情况。尽管这些方法被广泛采用,但在实际操作中,开发者常常面临效率低下和使用不便的问题。
如某个加密社区分析师所说
- 数据团队已经厌倦了处理数十个 rollup RPC。没人想再处理更多的 RPC。
- 我们大部分时间都在跨协议连接数据。仅仅关联 Compound 和 Aave 的标准版本就已经够难的,我不想不得不在 “supply()” 事件的数十个变体之间切换。
这些问题突显了现有基础设施在处理链上数据时的局限性。用户实际需要的是易于理解的交易和活动数据,而不仅仅是一连串的原始数据。
但是对于 shadow 使用者来说,只需要在 shadow fork 里面修改合约代码并且将交易重放即可。而这样的数据甚至可能会比原有数据管道的方式更加的精准和方便。同理,当用户需要全量的历史数据查询时,例如我需要这一个交易对从近两年的所有交易时,也可以通过这种重放的方式来完成。并且由于这是一种私人的节点网络,他也不会受到公共存档节点的限速限制。
未来的展望
那么,我们是否可以将 Shadow 视为对现有加密数据基础设施的挑战者乃至颠覆者呢?在我看来,这并不仅仅是因为其技术的先进性或宏大的叙述,而是这个产品是否真正满足了开发者和数据分析者的需求,并且利用新的技术和方式使得原有的摩擦成本降到最低。defi 就是一个成功的创新他极大程度的降低了传统金融的交易摩擦。使得其成为帕累托最优解。
当前,大量的尾端数据仍然未被有效利用,而大部分数据基建正是围绕这些显而易见的数据展开。这种情况不仅给开发者带来了不必要的数据适配负担,还增加了冗余的 API 调用。这种现状与过去互联网的发展历程颇有相似之处:就如同搜索引擎系统取代黄页一样,人们厌倦了在庞大的数据页中寻找所需信息,而更倾向于使用定制的算法来解决问题。
如果从今天的角度来看,我们现有的数据基础设施是否也正变成了一个庞大的 “数字黄页” 呢?
在加密数据领域,data warehouse 这种模式本质上并非 crypto-native 的创新,归根结底,它是过去大数据团队对现有加密数据业务的拙劣模仿和迁移。与其说是面向开发者,不如说是向风险投资者的一种叙事框架转移。而从 shadow 这一种专而从节点网络进行优化和改造的路径,看上去却更像是加密原生的做法。
随着未来 shadow fork 的开源和更多这一类项目的出现,加密领域开发一定会出现一种更加便捷和原生的链上数据处理体系,或许 shadow 能够给我们带来对未来数据基建的惊鸿一瞥。
免责声明:作为区块链信息平台,本站所发布文章仅代表作者及嘉宾个人观点,与 Web3Caff 立场无关。文章内的信息仅供参考,均不构成任何投资建议及要约,并请您遵守所在国家或地区的相关法律法规。

















