

在前进的路线图中我们最先到达的,是通过利用 Ai 助理(不一定可信)来改变你与 dapp 交互的方式(下面视频展示)。其次到达的将是协议/链层级的网络,最终将实现共享的所有权与治理。
原文:Don’t Trust, Verify: An Overview of Decentralized Inference
编译:LlamaC
「推荐寄语:人工智能(Ai)是大众认知最广泛且最深刻的称呼,目前驱动我们进入 AGI(通用人工智能)或在未来实现 ASI(超级智能)的是利用神经网络训练出来的大脑,这个大脑本质是一个大型语言模型(Large Language Model),简称 LLM。目前大众认知最广交互最多的 LLM 是 ChatGPT。大家对 ChatGPT 能在未来可创造巨大价值的共识上没有任何质疑。假设有条路径有可能使其价值被大家共享,那么 DeGPT(去中心化 ChatGPT) 就是可被寄托的乌托邦。在前进的路线图中我们最先到达的,是通过利用 Ai 助理(不一定可信)来改变你与 dapp 交互的方式(下面视频展示)。其次到达的将是协议/链层级的网络,最终将实现共享的所有权与治理。」
扩展视频:
当前利用 Ai 助理可实现的是将我们从不同协议交互界面的低效率中解放出来,而且是通过我们最适应的文字交谈方式。至少将有以下几种意图交互例子:
1、我想通过 EigenLayer 重新质押我的 $ETH,并将其委托给 AVS,期望至少有 X% 的年化收益率和最多 Y% 的风险。
2、我想将 X 美金的总额在未来 20 天中平均分配资金以不超过当前价格的 20% 买入 Y 这个代币。
3、帮我将 X 量的 USDC 质押至链上协议中赚取收益,年利率至少为 Y%,风险不高于 Z%。
简而言之,拥有最佳体验/安全的 Ai 助理将有望成为新的流量入口并在与大型协议的集成上掌控更高的议价权。
在开始正文阅读之前,了解什么是 Ai 训练和 Ai 推理?他们的区别是什么?将极大的提升您读懂正文的能力。
AI 训练(AI Training)和 AI 推理(AI Inference)是人工智能(AI)领域的两个主要阶段,它们在 AI 系统开发和运行过程中扮演着关键角色。让我们用一个简单的类比来理解它们:
想象一下,你正在学习做饭。这个过程可以类比为 AI 训练。
1. AI 训练:
◦ 就像你在学习做饭时,需要阅读食谱、观看教学视频、向厨师请教,并亲自尝试各种食材和烹饪方法。
◦ 在 AI 中,这个过程涉及到使用大量数据(食谱和教学视频)来 “教导” AI 模型(你的烹饪技巧)如何执行特定任务,比如识别图片中的物体或理解语言。
◦ 训练过程中,AI 模型会不断调整自己,以更好地从数据中学习规律和模式。
◦ 训练完成后,你会得到一个 “训练好的” 模型,就像你经过练习后能够熟练地做出一道菜。
2. AI 推理:
◦ 一旦你学会了做饭,你就可以使用你的技能来准备新的菜肴,不需要每次都查阅食谱或观看教学视频。
◦ 在 AI 中,推理是使用训练好的模型来对新数据做出预测或决策的过程。例如,一个训练好的图像识别模型可以用来识别新拍摄的照片中的内容。
◦ 推理通常需要较少的计算资源,因为它不涉及模型的学习过程,只是应用已有的知识来解决问题。
区别:
•目的:AI 训练的目的是创建或改进模型,而 AI 推理的目的是使用模型来执行任务。
•过程:AI 训练是一个涉及大量数据和计算资源的过程,需要不断调整和优化;AI 推理则是一个应用训练好的模型来快速做出决策的过程。
•资源需求:训练通常需要更多的时间和计算能力,因为它涉及到模型的学习;推理则相对快速且资源需求较低,因为它只是模型的应用。
简而言之,AI 训练就像是学习和练习,而 AI 推理就像是实际应用所学到的技能。
正文:
假设您想运行一个大型语言模型,如 Llama2-70B。这样一个庞大的模型需要超过 140GB 的内存,这意味着您无法在家中的机器上运行原始模型。您的选择是什么?您可能会选择云服务提供商,但您可能不太愿意信任一个单一的中央公司来处理这项工作,并吞噬掉您所有的使用数据。那么您需要的是去中心化推理,它允许您在不依赖任何单一提供商的情况下运行机器学习模型。
信任问题
在去中心化网络中,仅仅运行一个模型并信任其输出是不够的。假设我要求网络使用 Llama2-70B 分析一个治理困境。我怎么知道它实际上在使用 Llama2-13B,给了我更差的分析,并私吞了我的差额?
在中心化世界中,您可能信任像 OpenAI 这样的公司会诚实地完成这项工作,因为他们的声誉岌岌可危(而且在某种程度上,LLM 的质量是不言自明的)。但在去中心化世界中,诚实不是假设的——它是经过验证的。
这就是可验证推理发挥作用的地方。除了提供对查询的响应外,您还可以证明它在您要求的模型上正确运行。但如何做到呢?
天真的方法是将模型作为链上智能合约运行。这肯定能保证输出经过验证,但这是非常不切实际的。GPT-3 用 12,288 的嵌入维度表示单词。如果您要在链上进行这样大小的单个矩阵乘法,根据当前的汽油价格,将花费大约 100 亿美元——计算将填满每个区块约一个月。
所以,不行。我们需要一种不同的方法。
验证问题
在观察了这个领域之后,对我来说很明显,已经出现了三种主要方法来解决可验证推理问题:零知识证明、乐观欺诈证明和加密经济学。每种方法都有其自己的安全性和成本影响。
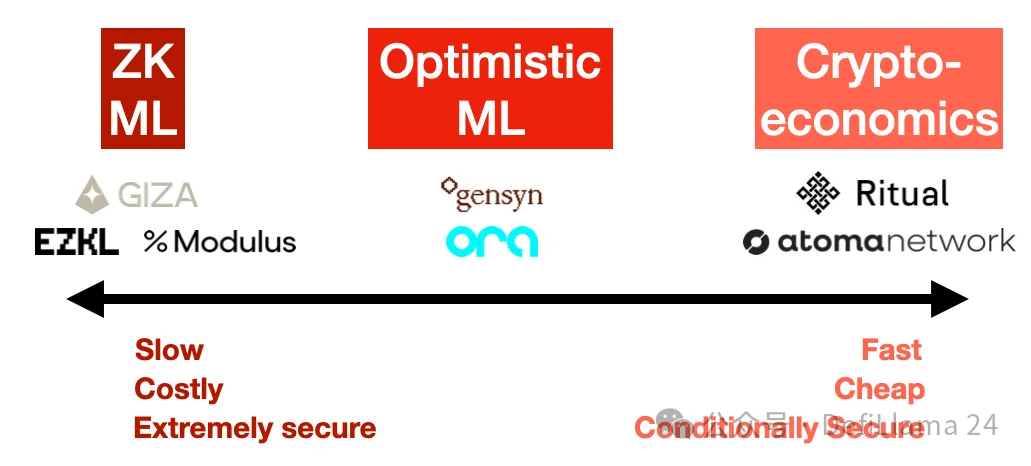
1. 零知识证明(ZK ML): 想象一下,能够证明您运行了一个庞大的模型,但证明的大小实际上是固定的,无论模型有多大。这就是 ZK ML 承诺的,通过 ZK-SNARKs 的魔力。
虽然原则上听起来很优雅,但将深度神经网络编译成零知识电路,然后可以证明是非常困难的。这也极其昂贵——至少,推理成本和延迟(生成证明的时间)可能至少是 1000 倍,更不用说在进行任何这些操作之前将模型本身编译成电路了。最终,这些成本必须转嫁给用户,因此对于最终用户来说,这将非常昂贵。
另一方面,这是唯一在密码学上保证正确性的方法。有了 ZK,无论模型提供者多么努力尝试作弊,都无法成功。但它这样做的代价是巨大的,使得这种方法在可预见的未来对于大型模型来说不切实际。
项目示例:EZKL、Modulus Labs、Giza
https://ezkl.xyz/|https://www.modulus.xyz/ | https://www.gizatech.xyz/
2. 乐观欺诈证明(Optimistic ML): 乐观的方法是信任,但验证。我们假设推理是正确的,除非有其他证据。如果一个节点试图作弊,“观察者” 在网络中可以叫出作弊者,并使用欺诈证明挑战他们。这些观察者必须一直在观察链,并在自己的模型上重新运行推理,以确保输出是正确的。
这些欺诈证明是 Truebit 风格的交互式挑战-响应游戏,您可以反复在链上将模型执行二分法,直到找到错误。

如果这种情况真的发生,成本是难以置信的,因为这些程序非常庞大,并且有巨大的内部状态——单个 GPT-3 推理的成本约为 1 petaflop(10^15 次浮点运算)。但博弈论表明,这种情况几乎永远不会发生(欺诈证明也很难正确编码,因为代码几乎从未在生产中被击中)。
乐观的一面是,只要有一个诚实的观察者在关注,Optimistic ML 就是安全的。成本比 ZK ML 便宜,但请记住,网络中的每个观察者都在自己重新运行每个查询。在平衡状态下,这意味着如果有 10 个观察者,那么安全成本必须转嫁给用户,因此他们将不得不支付超过 10 倍的推理成本(无论有多少观察者)。
缺点,就像 optimistic rollups 一样,您必须等待挑战期过去,才能确定响应已验证。不过,根据网络的参数化方式,您可能需要等待几分钟而不是几天。
项目示例:Ora、Gensyn(尽管目前尚未明确指定)
https://www.ora.io/ | https://www.gensyn.ai/
3. 加密经济学(Cryptoeconomic ML): 在这里,我们放弃所有花哨的技术,做简单的事情:质押加权投票。用户决定应该有多少节点运行他们的查询,他们各自揭示他们的响应,如果响应之间存在差异,那么不同的节点将被削减。标准的预言机东西——这是一种更直接的方法,允许用户设置他们期望的安全级别,平衡成本和信任。如果 Chainlink 在做 ML,这就是他们会做的。
这里的延迟很快——您只需要每个节点的提交-揭示。如果这被写入区块链,那么从技术上讲,这可以在两个区块内发生。
然而,安全性是最弱的。如果节点足够狡猾,大多数节点可能会合理地选择串谋。作为用户,您必须考虑这些节点有多少利益在其中,以及作弊对他们来说需要付出多少成本。也就是说,使用像 Eigenlayer 重新质押和可归因安全这样的技术,网络可以在遇到攻击造成损失的情况下有效地提供保险。
但这个系统的好部分是,用户可以指定他们想要多少安全。他们可以选择在他们的法定人数中有 3 个节点或 5 个节点,或者网络中的每个节点——或者,如果他们想要 YOLO,他们甚至可以选择 n=1。这里的成本函数很简单:用户为他们想要的法定人数中的节点付费。如果您选择 3,您将支付 3 倍的推理成本。
这里的棘手问题是:您能让 n=1 安全吗?在简单的实现中,如果没人检查,一个孤立的节点应该每次都作弊。但我怀疑,如果您加密查询并通过意图进行支付,您可能能够欺骗节点,让他们实际上只是回应这个任务。在这种情况下,您可能能够向普通用户收取低于 2 倍推理成本的费用。
最终,加密经济学方法最简单、最容易,可能也是最便宜的,但它最不性感,原则上也是最不安全的。但正如往常一样,细节决定成败。
项目示例:Ritual(尽管目前尚未明确指定)、Atoma Network、HyperspaceAI
https://ritual.net/ | https://www.atoma.network/ | https://aios.network/
为什么可验证 ML 很难
您可能会想知道为什么我们还没有这些?毕竟本质上机器学习模型只是非常大的计算机程序。证明程序被正确执行长期以来一直是区块链的主要内容。
这就是为什么这三种验证方法反应了区块链保护其区块空间的方式——ZKrollups 使用 ZK 证明,Optimistic rollups 使用欺诈证明,大多数 L1 区块链使用加密经济学。我们现在看到基本上相同的解决方案并不奇怪。那么当应用于 ML 时,为什么使得这很难?
ML 是独特的,因为 ML 计算通常表示为密集的计算图,这些图被设计为在 GPU 上高效运行。它们不是被设计来证明的。所以,如果您想在 ZK 或 OP 环境中证明 ML 计算,它们必须重新编译成一种使这成为可能的格式——这是非常复杂和昂贵的。
ML 的第二个根本困难是非确定性。程序验证假设程序的输出是确定性的。但如果您在不同的 GPU 架构或 CUDA 版本上运行相同的模型,您将得到不同的输出。即使您必须强制每个节点使用相同的架构,您仍然有算法中使用的随机性问题(扩散模型中的噪声,或 LLM 中的 token 采样)。您可以通过控制 RNG 种子来修复那种随机性。但即使有了所有这些,您仍然面临着最终的威胁问题:浮点运算中固有的非确定性。
几乎所有 GPU 中的操作都是在浮点数上完成的。浮点数很棘手,因为它们不满足结合律——也就是说,对于浮点数来说,(a + b) + c 并不总是与 a + (b + c) 相同。因为 GPU 高度并行化,加法或乘法的顺序在每次执行中可能会有所不同,这可能会导致输出中的微小差异。这不太可能影响 LLM 的输出,考虑到单词的离散属性,但对于图像模型,它可能导致像素值的微妙差异,导致两个图像无法完全匹配。
这意味着您要么需要避免使用浮点数,这将对性能造成巨大打击,要么您需要在比较输出时允许一些宽松。无论哪种方式,细节都很棘手,您不能确切地将它们抽象化。(这就是为什么,事实证明,EVM 不支持浮点数,尽管像 NEAR 这样的一些区块链确实支持。)
简而言之,去中心化推理网络之所以困难,是因为所有细节都很重要,而现实有惊人的细节数量。
总结
现在区块链和 ML 显然有很多话要说给对方听。一个是创造信任的技术,另一个是迫切需要信任的技术。虽然每种去中心化推理方法都有其自己的权衡,但我非常感兴趣看到企业家如何使用这些工具来构建最好的网络。
免责声明:作为区块链信息平台,本站所发布文章仅代表作者及嘉宾个人观点,与 Web3Caff 立场无关。文章内的信息仅供参考,均不构成任何投资建议及要约,并请您遵守所在国家或地区的相关法律法规。












