

如果说,Web1.0 的本质是联合,Web2.0 的本质是互动,那 Web3.0 最迷人的地方,就是公平。
封面:Photo by Nastya Dulhiier on Unsplash
文章开始之前,我们一起来做个选择题:
现在,摆在你面前有两个选择,左边是 500W 美金,右边是个巨大的硬盘,里面装了 500 万人的购物数据,你可以随意拿走一样,左边 or 右边?
虽然现实世界中,没有人会提供这两样东西让你选,但这个问题,至少可以引发一些思考,而这些思考,也是我在写这篇 Web3 文章时,想主要探讨的:
- 数据是否能成为一项资产?
- 为什么说 Web3 的核心是让数据权回归?
- 我们离 Web3 规模化还有多远?
- 当下值得深入体验的 2 个 Web3 产品。
接下来,就分别从这 4 个问题切入,来谈谈 Web3。
1、数据能否成为一项资产?
最开始的问题中,500W 美金和 500 万人的数据放在一起,可能 90% 的人都会毫不犹豫选择前者,因为对比来看,500W 美金到手就是踏踏实实属于我的资产,但这 500 万人的购物数据,虽然也是可以卖给平台方、或者利用数据去开发产品从而获利的,但致命问题是,数据是可被复制的,如果我拿到的数据只是 N 份复制品中的一份,怎么办?
再进一步:不可否认,数据是有 “价值” 的,但它能否成为一项资产?又该如何衡量它?
要回答这个问题,首先要对 “资产” 的定义,达成共识。

参考 WiKi 对资产的定义,那资产应满足以下 3 个关键点:
- 体现所有权
- 可兑换商品
- 能够为个人或企业带来收益
显然,如果从这 3 个关键点来说,现阶段的 “数据” 确实算资产,但只是少部分企业的资产,绝不是个人的。
拿最常见的场景举例,你在外卖平台点了份盒饭,付了钱,平台召唤骑手给你配送,一单结束,你不仅收到了一份外卖,还创造了一项购买数据。这项数据中有你的姓名、联系方式、配送地址以及消费金额,还有你的饮食口味等。
不过这条数据虽然是你创造的,但所有权并不归你,你也不能用这条数据置换商品,也不能为你带来任何收益。所以,对于你来说,这条被你创造的数据并不是你的资产。
那对平台来说呢?
他们可能会把你的数据和周边区域几百几千人的数据综合在一起,产生各种丰富的维度,去进行解释、判断。然后依据这些数据的积累,这个平台就知道你点外卖的这片区域,应该配备多少送餐员,在这儿开什么样的餐馆最赚钱,也会通过你的口味,给你精准的推荐更多适合你的商品广告。数据显示,2017 年今日头条就通过类似的数据运营方式,获得了 200 亿的广告收入。
在这个环节里,用户被当成了 “数据奶牛”,源源不断的喂养着平台和企业,也就是说,如果你在免费使用一项服务,你不是用户,你就是产品本身。
所以,数据和私钥一样,如果你不能真正控制它,它就不是你的。
2、为什么说 Web3 的核心是让数据权回归?
既然数据已被证明是有价值的,且价值连城,那如何让创造数据的个体,也因此获利?让数据权回归?
这个问题在 web1、web2 阶段是无解的,直到 2014 年 Web3.0 概念被提出。
那,到底什么是 Web3?用一张被社区疯传的图来表示,它是这样的:

Web 1.0 阶段,用户只能作为内容接收端,且账户需要和平台绑定,数据归平台所有。
Web 2.0 阶段,用户除了接收内容也可以输出内容,虽然账户依然要和平台绑定,但巨头的诞生,让用户可以用一套账号登陆多个平台了,但数据依然归平台所有。
到了 Web 3.0 阶段,用户可以用一个钱包登陆所有应用,用户数据回归个体,用户可以自己管理自己的链上数据,且可以因这些数据产生收益。
举个例子:
之前在体验 project galaxy 平台做任务时,coingecko 发布了一个 DeFi 101 的任务,只要满足在以下平台中任一质押平台交互过一次,就可以领取任务 NFT。

这里已经显示我满足条件,在 Yearn 这个平台质押过了,而什么时候质押的,我已经忘了。但这条数据属于 “我” 的行为数据,让我因此获得了 NFT 奖励。
也因为这次不经意的交互行为,让我在登陆 Rabbithole 时,也顺带完成了技能任务,增加了平台上的技能值。
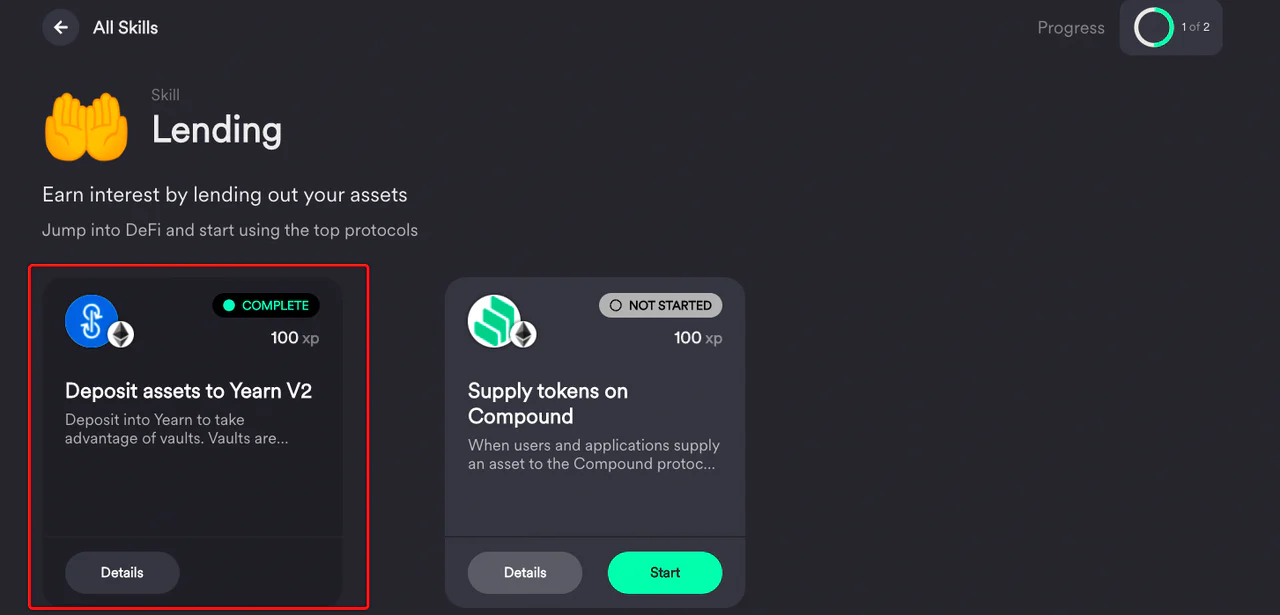
也就是说,一次不经意的链上交互行为数据,已经被 2 个不同平台奖励了,而可以确定的是,未来将有更多平台会因为我的这次行为,给我奖励。
这在 Web1 和 Web2 阶段是绝对无法想象的,你不可能因为你在抖音发了一篇爆款,而在微信平台被奖励,但 Web3 却可以。
这里,回顾下刚才提到的资产概念的 3 个关键点:
- 体现所有权
- 可兑换商品
- 能够为个人或企业带来收益
某种意义上说,Web 3 已经完全实现了数据 “资产化”,你的链上行为数据真正属于你,且可以为你带来收益,也可以兑换 NFT 等类商品的东西。
而一旦用户体验了拥有 “数据权” 的自由后,就很难再回到 Web1 和 Web2 的桎梏中了。所以,Web3 带来的 “数据权” 回归的未来,一旦流行,就很难压制。
3、我们离 Web3 规模化还有多远?
要回答这个问题,我们依然要对一个词,达成共识——规模化。
到底什么程度才是 “规模化” 了?
这里需要引用 TRIZ 之父、前苏联发明家根里奇·阿奇舒勒的 “S 型” 曲线原理:
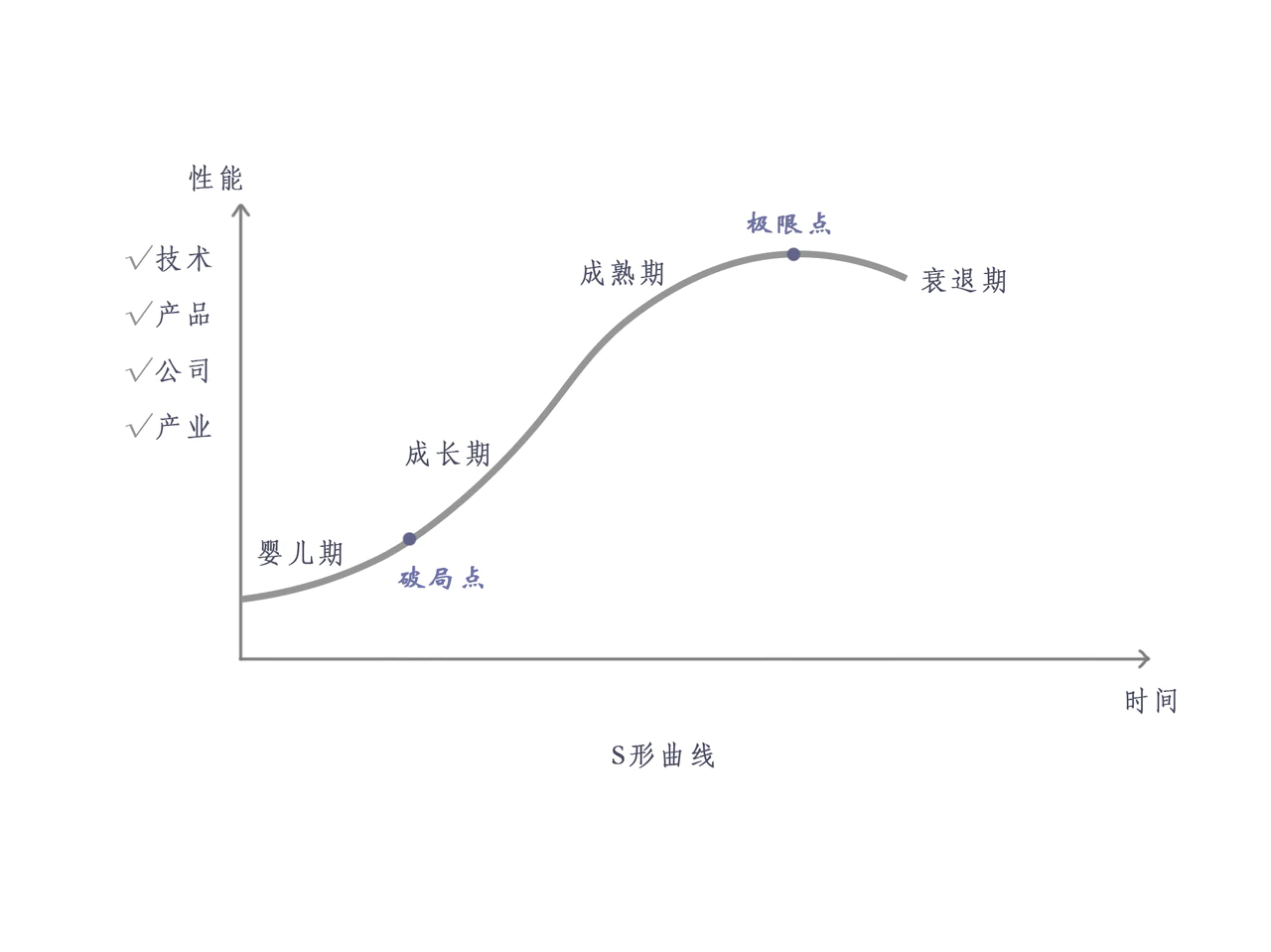
任何一个品类,不论是技术提升、产品创新,还是公司和产业的发展,随着时间推移,它们都会呈现出同一条 “生长脉络”,遵循同一个进化规律,而这个规律表现在图形上,就是一条 “S 型 “曲线。
而这个 S 型曲线的进化过程,被分成了 4 个阶段:婴儿期、成长期、成熟期和衰退期,婴儿期和成长期中间一个爆发点,被称为 “破局点”,破局点之前,进程比较缓慢,一旦突破了破局点,事物的发展就会进入指数型增长阶段,增长到 “极限点” 后,便会进入完全爆发期,之后便呈现向下趋势,进入衰退期。
也就是说,破局点是一个事物要爆发的 “蓄势点”,而真正被大规模应用让更多人知道的点是 “极限点”。
所以,当我们说,“我们离 Web3 规模化还有多远” 时,我们其实是在预估 Web3 这条进程曲线,从破局点走到极限点,到底要多长时间。
而要具体推测出这个时间段,我们需要先回顾 Web1.0——Web2.0,这中间的历史进程。
回顾互联网的发展,大致可分为以下 5 个时期:
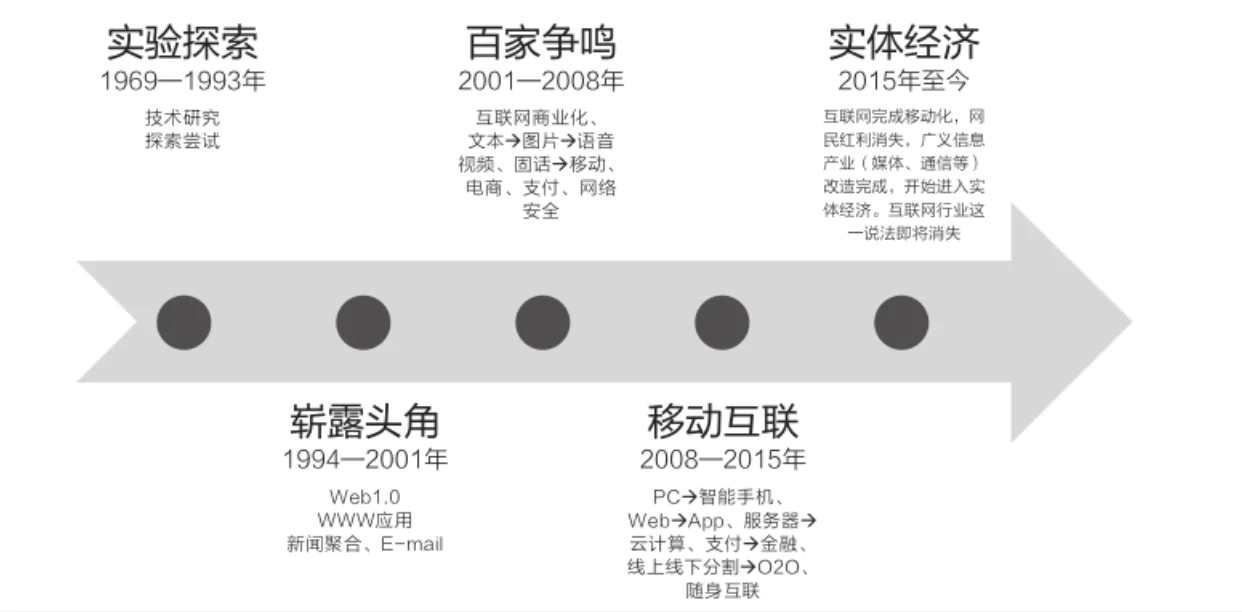
1993 年之前,互联网属于实验探索的阶段,TCP/IP 技术的发明正式开启了互联网时代。
1994 年开启 Web1.0 元年,以 WWW(WorldWide Web)应用为主的网站形式在全世界范围内迅速兴起,从雅虎、Hotmail 到我国的新浪、搜狐、网易,成为当时的代表。
这个时期的互联网主要通过对大量内容的聚合来解决在当时受众信息量不足的问题,商业化能力比较单一,平台主要靠广告来变现。
从 2001 年到 2008 年,随着固定接入带宽速度的大幅度提升及费用的大幅度降低,各种新形态的互联网业务及商业模式的兴起,从早期的文字、图片为主,到后来的语音通信、视频播放、零售类电子商务、网络应用安全等各种领域出现了不同的产品尝试。
但功能的丰富并没有带来输出模式的改变,用户仍然停留在被 “喂养” 的阶段,直到 2015 年前后,腾讯、Facebook 等平台级应用相继崛起,让用户习惯开始发生改变,此时,用户开始和平台交互,打通了双向输出渠道,Web2.0 时代就此开启。
从这个进程来看,Web1.0 过渡到 Web2.0 整整花了 21 年,而 Web2.0 开启到现在全面爆发,仅仅过去了 7 年。
如果按照这个速度推断,假设 2022 年是 Web3.0 元年,也就是 S 型曲线的破局点,根据 Web2 的极速爆发进程,Web3 从破局点到极限点,可能只需要 3-5 年,即 Web3 真正规模化的时间点是 2025 年到 2027 年之间。
而到底是 3 年走到 “极限点” 还是 5 年走到 “极限点”,不仅要看区块链技术的发展状态,还有一个非常重要的影响因素——共识的建立。
这个共识包括:现实世界与虚拟世界能源分配的共识以及对治理规则统一的共识。
Web3 爆发不仅需要个体和技术的推动,还需要能源的支持,但虚拟世界的正常运行,仍然需要实体世界稳定地供电。
也就是说,Web3 不仅要从 Web2 争夺数据权,还要争夺资源和产能,但从说服实体世界不拔插头这一点看,可能就需要费很多功夫。
再进一步,即使能源问题能解决,规则的共识也需要时间来磨合。
什么叫 “规则” 的共识?这里依然用互联网举例:

1969 年,网络刚刚诞生,第一代网络被命名为阿帕网 ARPAnet,由美国国防部高级研究计划署 ARPA 提出。
虽然当时有了网络,每台计算机也都能运行的很好,但计算机与计算机之间是不兼容的,在一台计算机上完成的工作,没办法拿到另一台计算机上去用。
当时,有科学家提出:“所有计算机生来平等,我们要让这些生来平等的计算机实现资源共享,就需要在这些系统的标准之上,建立一套大家共同遵守的标准,让所有计算机按照同一套标准开发,然后才能互相连通、信息共享。”
于是,1974 年,一位叫温顿·瑟夫的人提出了 TCP/IP 协议,让这套协议成了互通协议,这之后的所有计算机网络全部遵循这套协议,然后,才有了今天把我们所有人网在其中的如此庞大的互联网系统。
也就是说,表面上,这个叫温顿·瑟夫的人只是提出了一个名叫 TCP/IP 的协议,但本质上,他约定了一套全人类都认可的规则。如果没有这套规则,就没有现在的 Web1、Web2 甚至 Web3。
所以,Web3 再自由、再民主,也需要在代码之上,统一这个元规则的定义权。
The code is the law, but the law needs to be uniform。
代码即法律,但法律需统一。
4、当下值得深入体验的 2 个 Web3 产品。
前面讲了大趋势,现在进入小细节,说两个我个人比较喜欢的 Web3 产品:
一个是被很多人看好的去中心化内容产品 Mirror,另一个是我最近刚发现的隐私笔记类产品——Dstar Note。

先说我喜欢 Mirror 的 4 个理由:
1、钱包登陆、无需注册。
「足够去中心化」

2、去中心化数据永久存储。
「所有内容数据均属于创作者」
3、众筹机制
「解决商业变现问题,为内容输出者提供资金保障」
4、克制即美德。
「只有输出一个功能,足够克制,足够聚焦」
可以说,作为内容输出者,Mirror 是为数不多让创作者专注创作的的平台。
而接下来要说的 Dstar Note,是基于互联网计算机的区块链笔记本,Mirror 更倾向于分享,属于社交类 Web3,而 DstarNote 则更注重隐私。
隐私的产品在 Web2 其实算小众,我自己一直在用的隐私密码本是 1password,但直到有一天,我看到了这个信息:

可以说,Web2 是无法做到绝对隐私的,即使是估值百亿的产品。只要服务器由集中式服务器托管,信息就会被大型公司或者云服务器提供商所控制,随时都有被盗的风险。
所以,从那个时间节点开始,我就在寻找做去中心化隐私笔记类的产品,后来就看到了 ICP 链上的 Dstar Note 。
它的原理是让每个笔记本成为一个服务器,然后通过使用 InternetComputer (ICP) 区块链,让用户可以用 ICP 身份创建一个 ICP 服务器 “罐子”,也就是笔记本。

然后再把信息用助记词转换的 AES256 加密方案在本地进行加密后上传到到你自己所创建的笔记本中。

也就是说,当云服务器 “罐子” 被创建时,你就拥有了一个自己的云服务器,所有信息不会被任何人找到,就算节点作恶,也有 AES256 的加密方案保护。
即使是我自己创建的密码本,也是需要身份识别验证的:
所以,Dstar Note 这个 Web3 产品打动我的原因,是它足够隐私、足够安全,当然,和 mirror 一样,它也足够克制,没有一些花哨的功能,聚焦做好隐私一个点,就足够了。
有时候,克制,反而激发创造力。
写在最后:
每次写文章去论述一个议题时,我总喜欢把它想的很宏大、很系统,但其实,有些微小的变化已经发生在生活中了:
当我打开浏览器时,用的更多的是 brave 而不是 Chrome;
写文章时,用的更多的是 mirror 而不是微信公众号;
保存内容时,用的更多是 Dstar Note,而不是印象笔记;
跑步时,打开的软件是 StepN,而不是悦跑圈;
理财时,用的更多的是 defi,而不是基金工具
·······
我才发现,Web3 已经默默走进了我的生活,而且我所有的行为,都正被 Web3 奖励着。
如果说,Web1.0 的本质是联合,Web2.0 的本质是互动,那 Web3.0 最迷人的地方,就是公平。
在 Web3 的系统里,用户的时间、产生的行为、贡献的数据,都能得到公平的奖励,这种激励模式将解放人类底层驱动中的恐惧,然后将其替换成个体创造力。
一旦所有个体的创造力被激发、被奖励,这样的未来,难道不值得期待吗?
免责声明:作为区块链信息平台,本站所发布文章仅代表作者及嘉宾个人观点,与 Web3Caff 立场无关。本文内容仅用于信息分享,均不构成任何投资建议及要约,并请您遵守所在国家或地区的相关法律法规。









