

读懂这篇文章,读懂区块链基础设施未来发展。
封面:Photo by Shubham Dhage on Unsplash
前言
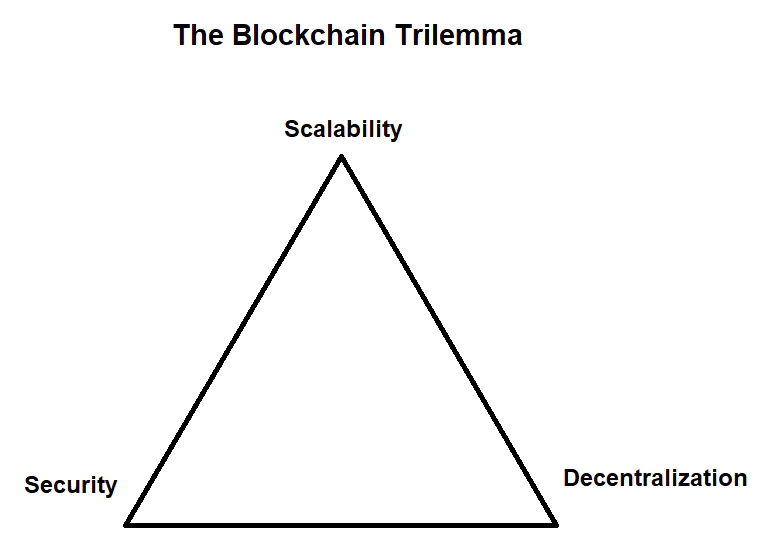
- 纵观整个区块链的技术发展,大部分技术难题以及解决方案都在围绕一个中心思想发展 - 怎么在不可能三角(性能,安全,去中心化) 中找寻平衡,这里要讨论的模块化与数据可用性问题也不出其右。
TL;DR
- 模块化的出现不是突然,而是必然。
- 数据可用性保证对轻节点与 Rollup 的安全性至关重要。
- 数据可用性扩容对于 L1 的吞吐量和费率都将产生巨大影响。
- 以太坊, Celestia 和 Polygon Avail 等项目都在持续着数据有效性项目的研发。
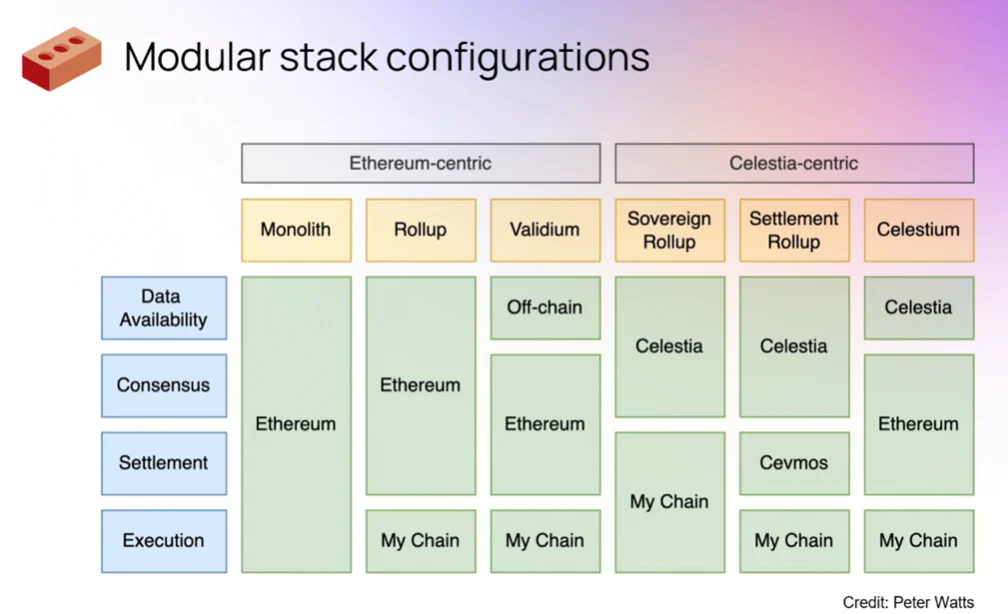
单体化 (Monolithic) 区块链
什么是单体化区块链
- 单体化架构的区块链可以理解为全节点需要同时处理网络内所有类型的工作,这里的工作类型我们抽象为三部分 - 执行 (Execution), 共识 (Consensus), 数据可用性 (Data Availability)。单体化和模块化是相对概念,也是工程学发展的一种必然趋势。
单体化区块链工作流程
- 用户发送交易至节点
- 节点验证交易的有效性,执行交易,状态转换,如果有效则并放入内存池进行广播,否则抛弃交易回滚状态- 执行 (Execution)
- 节点生成区块头,从内存池中选择一组交易,排序并放入区块,生成区块体,将区块存储到本地 - 共识 (Consensus), 数据可用性 (DA)
- 网络通过自己的共识机制挑选出块节点,出块节点广播自己的本地最新区块 - 共识 (Consensus)
- 网络内其它节点收到区块后检查本地是否已经有了,没有的话需要重新验证交易的有效性与可用性, 并将此区块存储到本地 - 执行 (Execution), 数据可用性 (DA)
- 网络内节点达成最终性 (Finality) 后此区块成为链上最新区块
模块化 (Modular) 区块链

为什么要解耦单体化区块链?
- 区块链作为执行状态机复制 (SMR)的分布式网络,理论上就可以被分为数据,执行,共识等层级。单体化区块链遵循了 SMR 的设计,只是将所有层级的工作都放在了同一个节点 (全节点) 上执行。比特币,以太坊等项目都证实了其工程上的可行性。
- 回到不可能三角问题,扩容已经成了整个行业的圣杯。从比特币开始,区块链就不是科学上的创新,而是工程学上的创新。从单体化到模块化基本是工程学的发展规律,可以看一下现在的扩容技术,基本每一种都有很强的模块化趋势,或是走在模块化的道路上,看似模块化的出现是因为现前扩容的需求,实则模块化的出现是必然。
什么是模块化区块链?
- 模块化区块链是按照执行,共识/结算与数据可用性这样的模块粒度来进行解耦的区块链设计模式,每个层级由不同的网络进行维护,各层级充分发挥自身网络特性,最后通过可拔插的组合形成流水线的工作方式。
- 执行层突出强大和快速的计算处理能力,抛开共识和存储的束缚,可以通过非常少量的高性能节点来完成工作。
- 共识层需要保证交易的公正有效与安全,选出最符合网络共识要求的区块。共识层需要满足优秀的共识性与去中心化性。Polygon 做过一个比喻,当你刷信用卡的时候,你的交易记录是先存放在信用卡中心的,信用卡中心会定期将一批信用卡交易记录发给银行,银行来确认交易的可用性并对账目进行记录更改。显然你不会因为信用卡中心的确认速度更快而把钱直接存到信用卡中心,因为银行才是金融体系内负责结算的角色,它有足够的信用背书,也有足够大的体量防止被攻击。
- 数据可用性层需要保证数据在保存前没有被二次篡改或者隐藏扣留,确保所有需要记录的交易信息都被正确的记录,数据可用性层的要求比较综合,需要共识性与不错的储存能力。在单体化区块链中没有数据有效性问题,因为数据被节点记录之前都会重新执行验证一遍,并且会和本地存储的区块进行比对来确保数据的有效。还是用上面的例子,银行收到信用卡中心的账单列表后,虽然已经确定的记账的方式,但是也会让多个结算员来对账单进行二次检查和结算,确保信用卡中心没有对用户的账单做手脚。DA 的概念是伴随着模块化区块链产生的,但是在 web 领域,基于 DA 的产品几乎每个人都用过的 - BitTorrent。
数据可用性 (Data Availability)
数据可用性的出现
- 数据可用性最初不是问题,L1 中的数据是自然可用的。但是我们现在面临着扩容的剧变,数据可用性才成为一个不可避免的话题。只有保证所有交易数据的可访问和可下载,L1 或者轻节点才能对 Rollup 上的状态进行跟踪和重构。
DA 是必不可少?
轻节点验证数据可用性困境
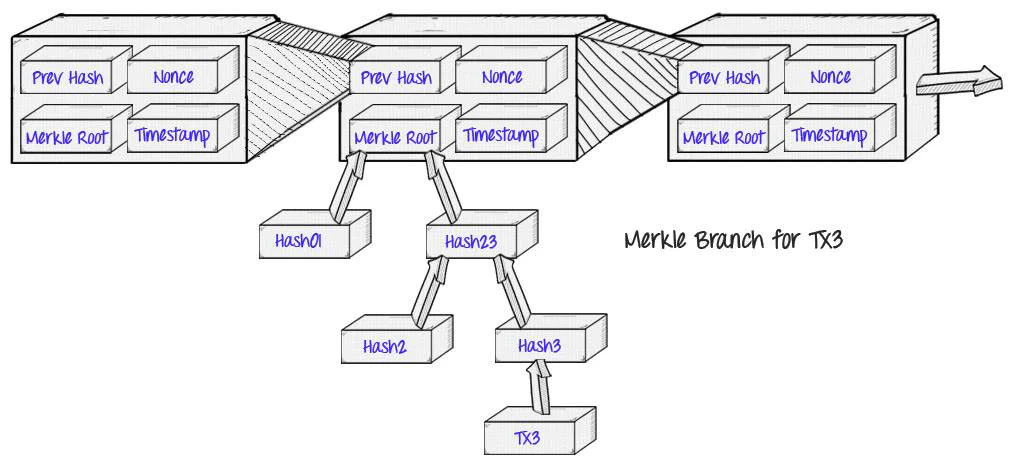
- 比特币在设计时就提出了 SPV(Simple Payment Verification) 的概念,即使不运行网络的全节点也可以使用网络的方式。这类节点称为轻节点,它们只下载区块头,不下载具体的交易数据,不会去验证交易的可用性,只保证同步的是最新的区块头,也就是只能确保区块是有效的,对于区块内交易的可用性则是完全信任全节点的。
- 因为交易数据是记录为 Merkle Tree 的结构,轻节点虽然拥有验证某条交易的可用性的能力,但是对于全节点恶意隐藏或是扣留的交易数据,轻节点由于只有区块头,是很难确认具体哪条交易信息是无效的,除非下载全部交易数据,总结就是确认交易无效容易,确认交易是否存在是困难的。
- 传统分片 (Sharding) 扩容方式中,矿工会被分配到不同的分片上处理该分片的工作。矿工需要运行该分片的全节点加上其它分片的轻节点来保证跨分片操作的能力。因为分片安全的分割性,如果某个分片的节点作恶,很容易出现上面描述的轻节点验证数据可用性困境,大大降低分片的性能与安全性。
Rollup 强依赖数据可用性保证
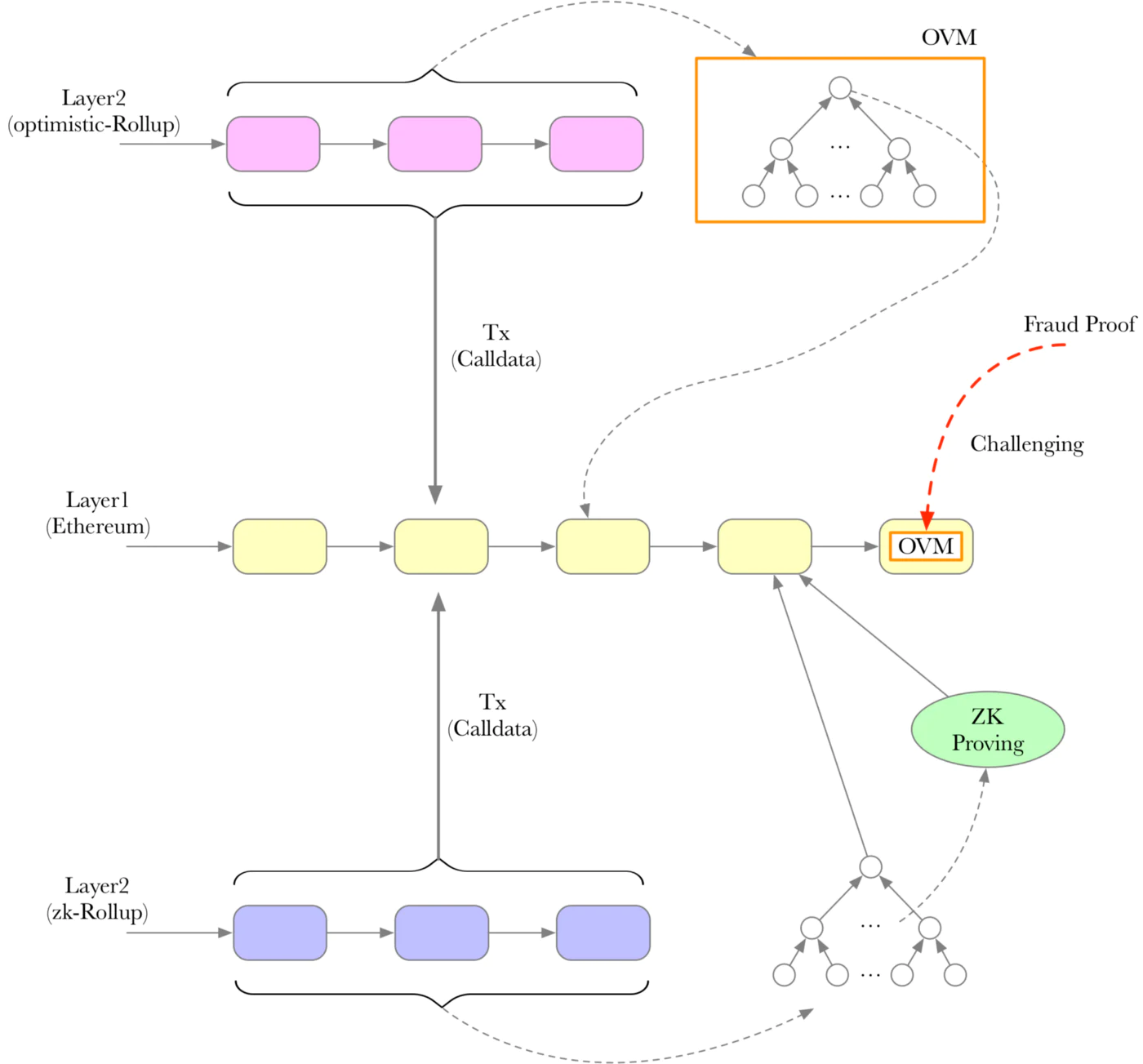
- Optimistic Rollup
- 在 Optimistic Rollup 扩容方式中,运用一种称为 Sequencer 的高性能服务器对交易进行验证与执行,最终将交易批量打包 (batch) 传回 L1 进行储存。Sequencer 是更加中心化的节点,处理速度非常快,L1 的共识层是无法跟上这样的处理速度进行共识的,所以为了防止 Sequencer 的作恶,我们先假设 Sequencer 处理的工作是有效的,然后还有一类角色负责定期从 L1 读取 Sequencer 提交的交易来区块的有效性,如果发现有无效交易则可以提交欺诈证明 (Fraud Proof) 来进行可用性挑战,如果数据最后被认定无效,则 Sequencer 上的状态也会回滚至有效前。
- 这里的问题时,如果要验证 Sequencer 提交的交易的可用性,需要先保证 Sequencer 提交了所有它验证过的交易,没有隐藏或是扣留等,也就是需要保证数据的可用性,否则是无法进行欺诈证明验证的。Optimistic 和 Arbitrum 等 Rollup 现在的解决方法是将所有交易发回以太坊,以太坊来进行数据可用性工作
- ZK Rollup
- 对于 ZK Rollup(Zk-SNARK/Zk-STARK) 的 Sequencer 来说,不存在欺诈性证明问题,在提交 batch 交易时还需要同时提交零知识可用性证明,只要证明是有效的,则交易一定是有效的。即便如此也还是需要将交易数据发送回 L1 进行记录,为了防止有一天此 Rollup 服务终止后,用户依然可以用 L1 上保存的数据恢复账户状态,避免资金在 Rollup 中的锁死。这个时候如果没有数据可用性保证,也就无法恢复正确的链上状态。这个也被称为 Rollup 链上状态持久性问题。
DA 扩容问题
吞吐量
- 受限于底层区块大小限制,区块大小其实是共识层和数据可用性层共同的问题。以太坊为例,区块大小的均值在 50-60kb,区块大小限制了单位区块可以包含的交易数量。Rollup 现在是将批量交易 (batch) 信息通过 calldata 字段进行压缩保存,其效率必然受限于单个区块可容纳交易限制。
- 受限于底层数据可用性验证效率限制,现在的 Rollup 例如 Optimism,数据可用性依然依赖 L1(以太坊) 来进行,和单体化时期并没有区别,全节点下载所有交易,通过 L1 上的智能合约计算 Merkle Tree 等方式来验证区块内所有交易的可用性,然后进行本地保存,网络中所有节点都需要重复这个步骤。以太坊的 TPS 在 14 左右,数据可用性验证也差不多是这个速率,可见数据可用性验证的效率对 Rollup 效率影响之大。
存储成本
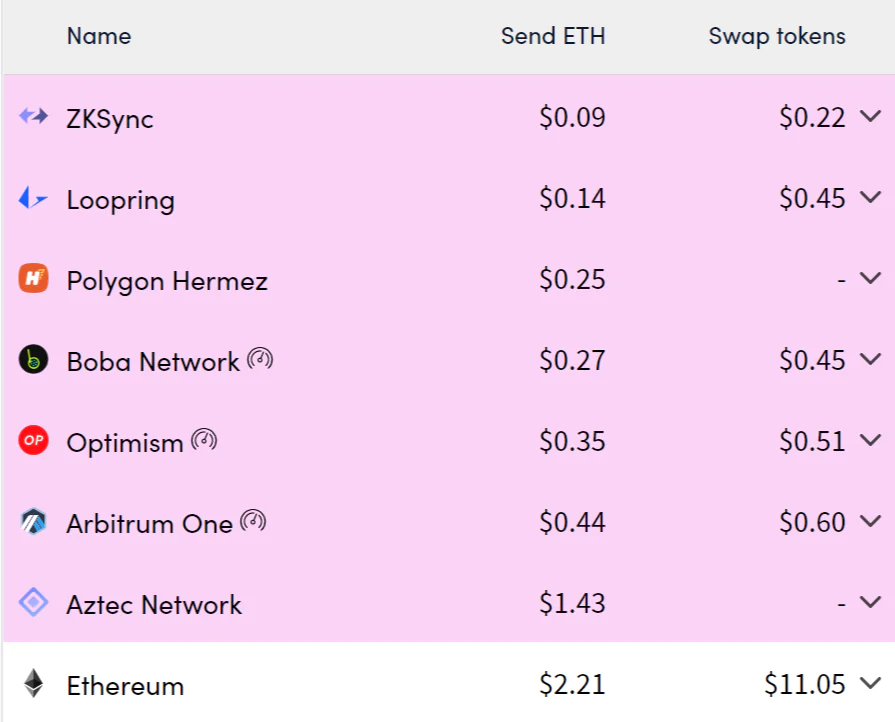
- 受限于底层存储成本限制,因为存储的高昂费用,使得用户最敏感的交易费用在 L2 上并没有得到大幅度的减少。现在 Rollup 的费率主要由固定成本与可变成本两部分组成。其中对于 Rollup 费率影响最大的便是 calldata 的存储费率 16gas / byte。
- 固定成本:L1 Base Tx Fee 21000 + 状态写入成本 20000
- 动态成本:L2 Base Fee(可忽略不计) + calldata 写入成本 (16gas / byte)
- 数据可用性的存储和通用的存储是有区别的。数据可用性存储不会对大文件存储做优化,反而需要对数据验证做更多优化。可以看这篇了解更多。
DA 扩容技术
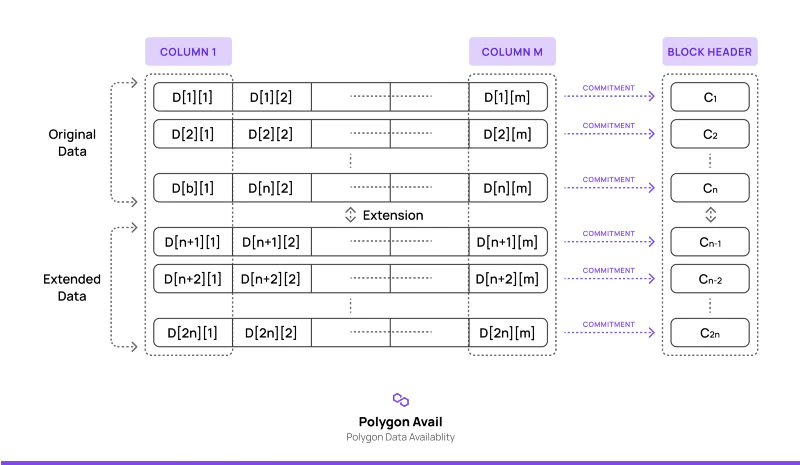
二维 R-S 纠删码 (2D Reed-Solomon Erasure Coding)
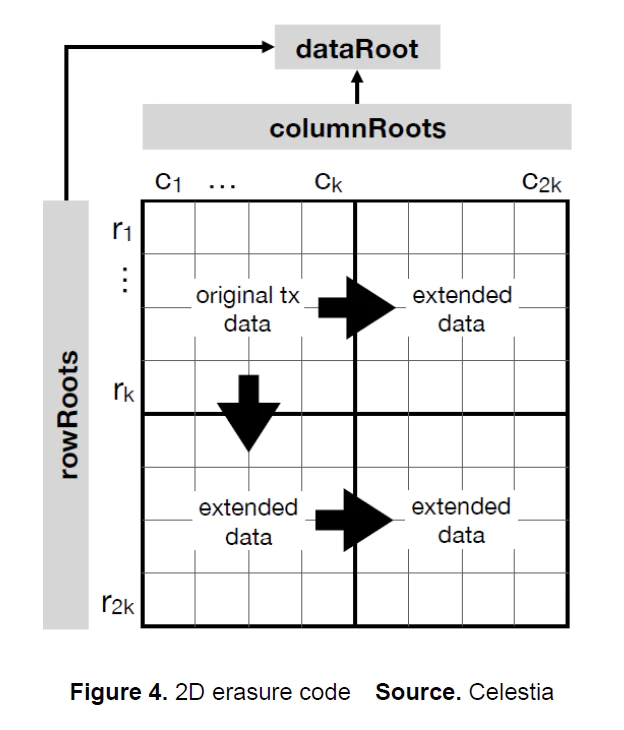
- 纠删码是在原始数据上附加一些额外的数据,保证原始数据在一定的兀余度内的丢失都是可以通过算法恢复的,几乎所有分布式数据网络中为了保证数据的冗余性都会使用纠删码进行数据可用性保护,CD-ROM 上也大量使用纠删码来保证一定程度的物理损坏不会导致数据遗失。
- 二维 R-S 纠删码是一种数据编码方式,解决的问题是通过增加数据兀余度与采用特别的数据排列方式,帮助节点无需下载所有交易的情况下就可以快速验证数据的可用性。全节点将数据附加纠删码后,再被切分为横纵轴数量一样的带有奇偶校验数据的数据分片,现在数据呈二维平面排列,然后计算出行和列的 Merkle Root,同时也需要用行和列的 Merkle Root 计算一个整体数据的 Merkle Root, 放入区块头信息中供之后快速校验。
- 可以看出一个全节点如果想隐藏一笔交易,那几乎就不可能了,因为任何的修改都会导致二维数据矩阵实质性的变化,非常容易被检测出来。网络内全节点如果检测到任何数据有效性问题,也会通过数据有效性欺诈证明来快速通知轻节点。
数据可用性采样 (Data Availability Sampling)
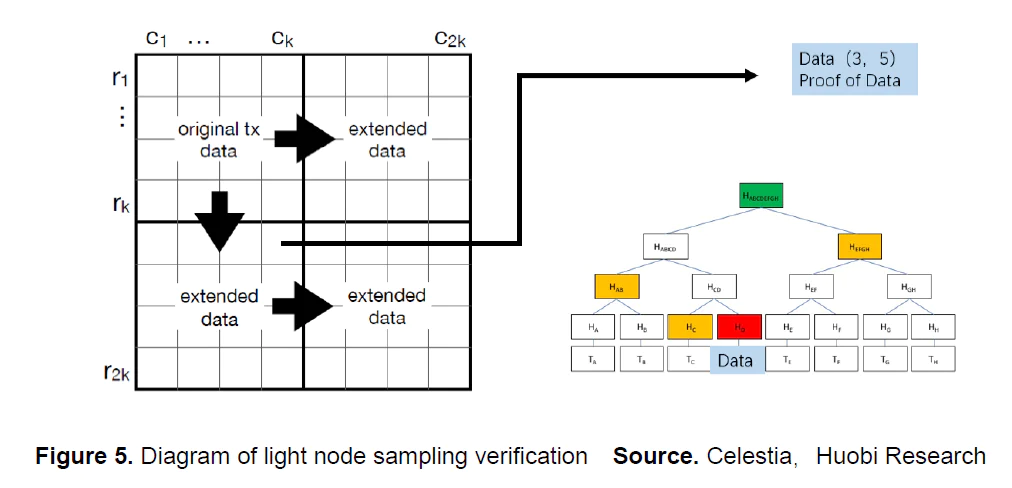
- 数据可用性采样 + 二维 R-S 纠删码几乎是数据可用性项目的通用设计了,也是几个项目技术细节上有差异化的地方。以太坊的 Dank Sharding 也不断在进行数据可用性采样方面的研究。
- 在交易数据完成二维 R-S 纠删码编码,区块头也广播之后。轻节点就可以通过区块头中的行与列的 Merkle Root 计算出整体数据的 Merkle Root 并与区块头中的数据进行对比。如果整体数据的 Merkle Root 没有问题的话,轻节点再进行一个非常小的数据采样测试。例如随机选择第 3 行与第 5 列,之后就是与 SPV 中轻节点验证交易可用性方式一样了,要求全节点返回计算需要用到的节点路径进行哈希计算。最后再与全节点给出的第 3 列与第 5 行的 Merkle State 数据做对比就完成了一次采样验证。
- 这个方案最重要也是最美妙的一点在于,验证数据量与计算量很小,支持大量轻节点的加入,并且节点数量越多,区块的可用性概率也越高整个网络也越安全,对于检测数据隐藏或者扣留的情况非常高效。
命名空间默克尔树 (Namespaced Merkle Tree)
- 这个是 Celestia 首先提出的技术,简单说就是将整个默克尔状态树划分了归属,全节点做验证时只需要下载自己归属下的那部分树结构就可以了。这样的好处是可以同时支持不同的执行层数据的可用性验证。这个设计充分体现了 Celestia 的模块化主义与多 Rollup 并存的展望。技术细节可以参考这篇文章。
KZG 承诺 (Kate-Zaverucha-Goldberg Commitment)
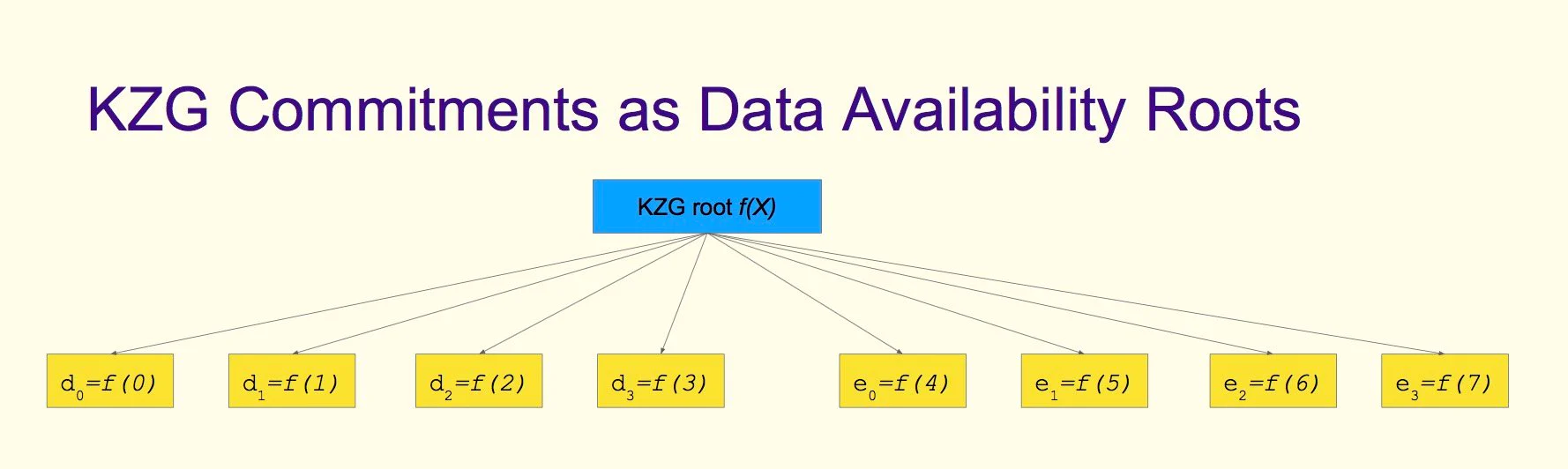
- 使用 KZG 作为数据可用性的状态根最来自于以太坊的 Danksharding 方案。KZG 承诺的作用和 Merkle Root 一样,是对于整体状态的一种证明方式 (proof of inclusion),可以看做另一种 Merkle Root,只不过它哈希的不是数据,而是多项式。数据量更小,可用性证明更加高效,而且所有叶子节点都在同一个 polynomial(多项式) 上,通过增加叶子节点就可以进行纠删码编码 (Erasure Coding 友好)。
Danksharding
Proto-Danksharding(EIP-4844)
- Proto-Danksharding 是 Danksharding 的一个早期先行版本。在交易信息中包含了一个额外的存储空间字段 - blob。每个 blob 有 128kb 空间,每个交易最多有两个 blob,每个区块最多包含 16 个 blob,blob 不可以被 EVM 执行。blob 都使用 KZG 承诺进行多项式哈希,用于之后的数据可用性验证。之前 Rollup 的批处理 batch 数据都是通过 calldate 字段传入 L1,现在可以直接放到 blob 中。
- 这里最重要的是,blob 不是永久存储的,可以理解为有时效性的缓存,每隔一段时间 (30 天) 以太坊上的 blob 数据是会被清除的,通过这种缓存的方式来减轻以太坊的存储压力以及减少存储费率。因为 30 天后 blob 数据会被清理,所以需要自行存储这些历史交易数据。以太坊共识层的目的不是保证永远保存所有历史数据。相反,其目的是提供一个高度安全的实时公告板,将历史数据存储的工作交给其它更适合的网络来进行,以太坊也在全力转向模块化趋势。
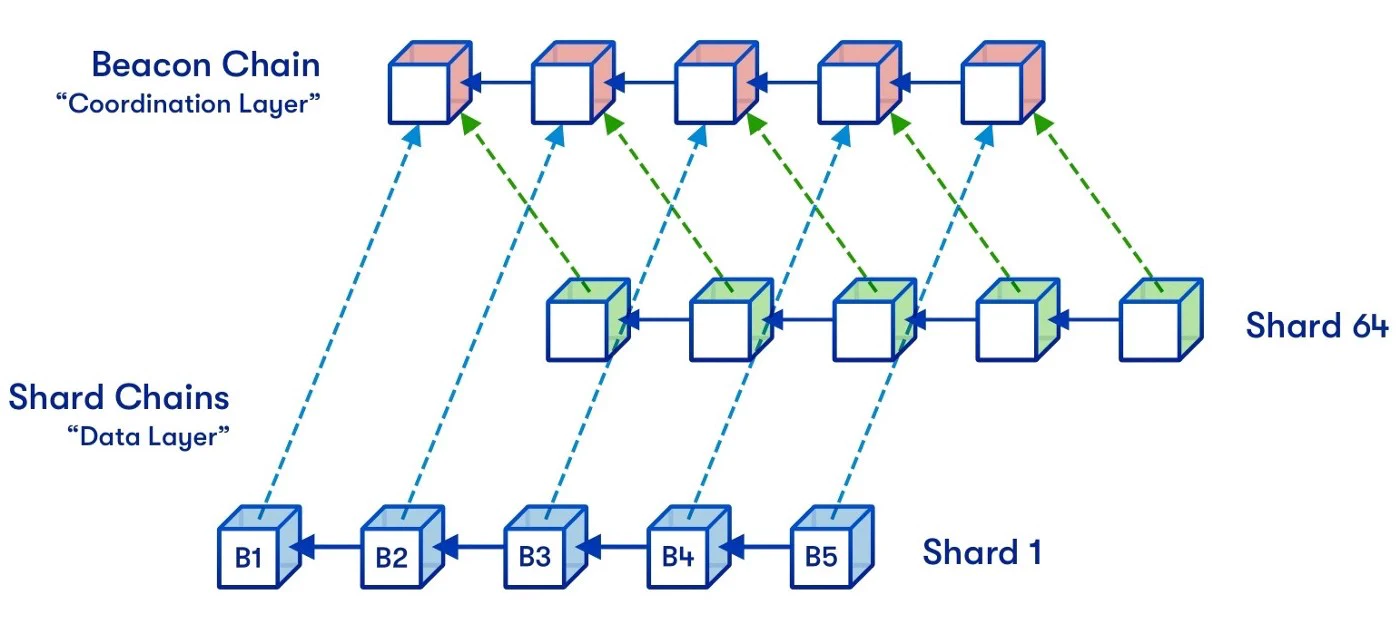
Danksharding
- Danksharding 是以太坊的新分片设计提案,围绕 Rollup-Centric 的以太坊发展路线,提出了很多数据可用性层相关的改进。此分片方案给 rollup 的批处理 batch 数据提供大量的存储空间 blob。以太坊协议本身并不试图解译这些 blob,验证一个 blob 只需要检查该 blob 是否可用——即它能否从网络上下载。这些 blob 的数据空间预期是为支持高吞吐量交易的二层 rollup 协议所用的。
- Danksharding 将 Proto-Danksharding 中 blob 数量提升了 16 倍,最大交易大小从 2M 上升到 32M, 目标交易大小从 1M 提升到 16M。blobs 分散存储在 Becon Chain 上,单独作为数据可用性层工作。依然是运用纠删码技术,每个节点只保存 blob 的数据片段,整个网络来保证 blob 的数据的完整性 (和 BitTorrent 一样)。blob 使用数据可用性采样 (DAS) 的方式配合 KZG 状态根来验证数据可用性,提交提交 attestation,attestation 达到阈值则认为 block 有效。再配合 EIP-4488 来减少 calldata 的存储费用,包括提供独立的数据有效性分片来存储 blob,可以说是在数据可用性扩容上全力导向 Rollup-Centric 发展路线了。
Celestia
- Celestia 是近期最重要的模块化区块链项目,也是推进数据可用性与模块化区块链落地的先驱。构建于 CosmosSDK 之上,专注于提供数据可用性服务,不执行任何交易。他们率先提出了让轻节点使用二维 R-S 纠删码进行数据可用性验证,同时开发了命名空间默克尔树来支持多种 Rollup,也提出了量子引力桥 (Quantum Gravity Bridge) 使用 Celestia 作为以太坊数据可用性层的扩容方案。
- CEO Mustafa Al-Bassam 是 Chainspace 的 Co-Funder,这个项目后来被 Facebook 收购。首席研究员 John Adler 来自 ConsenSys, 曾经帮助 Optimism 完成了第一版技术规范。
- 我觉得模块化在社区的兴起大部分是因为 Celestia 描述了一种全新的模块化区块链技术栈,其中以 Rollup + Cevmos + Celestia 的组合受到最多关注。Cevmos 是 Celestia 与 Evmos 团队合作推出的模块化结算层,使用 Optimint(Optimistic Tendermint) 共识, 基本是完全为 EVM Rollup 优化的,还结合了 Cosmos 网络的互操作性,组合性等优势,十分值得期待。
Polygon Avail
- 谈到 L2 怎么能少了号称 layer2 聚合器的 Polygon。Avail 是 Celestia 的竞品,作为 polygon 的 layer2 聚合器版图的一部份,构建于 Substrate 之上,专注于数据可用性层的服务。在我看 Avail 也是最有可能在 Polkadot 生态出现原生的数据有效层项目前的 DA 选择方案之一。Celestia 已经为 Cosmos 生态描绘出一种极高灵活度与扩展性的架构,我相信 Substrate 生态也会不甘落后的。
- Avail 的思路与 Celestia 基本相同,区别主要在于纠删码的生成以及采样验证环节。Avail 在二维 R-S 纠删码编码阶段大量使用 KZG 承诺。Avail 将数据展开为 n * m 的矩阵,对每一行都构造一个多项式,然后为每一个多项式都生成一个 KZG 承诺放入区块头。之后轻节点便只需要原始数据和 KZG 承诺便可完成可用性验证。
Startwar Validium & ZkSync ZkPorter
- Validium 和 ZkPorter 是 Zk-Rollup 两大巨头 Startware 与 ZkSync 推出的自家链下存储服务。本质是是为了解决上述 L1 的瓶颈舒服 Rollup 快速大规模应用的问题,通过将交易数据存储在为 Zk 交易数据优化过的相对中心化的网络中而不是以太坊来大幅降低交易费用。我觉得这是对于以太坊过于缓慢开发进度的一种折衷方案。毕竟安全性是有代价的,不过这样服务的出现肯定也能打中一批目标用户。
参考
https://mirror.xyz/yicheng.eth/7q29a3lMXkG2f51-BrTLxovS3tqnwf4qi7_VWFhnqKc
https://mp.weixin.qq.com/s/Y4avtYdyES45EBkhHp07XA
https://medium.com/coinmonks/why-we-need-modular-blockchains-for-scalability-276f4d724b0e
https://medium.com/blockchain-capital-blog/wtf-is-data-availability-80c2c95ded0f
https://www.mechanism.capital/rollups-introduction
https://coinmarketcap.com/alexandria/article/what-is-data-availability
https://w3hitchhiker.mirror.xyz/T9MoM-3p_xNIx7I5k-UzmfKqGBQaDQmdvGw4K8bFMTA
https://learnblockchain.cn/article/3769
https://learnblockchain.cn/books/geth/part1.html
免责声明:作为区块链信息平台,本站所发布文章仅代表作者及嘉宾个人观点,与 Web3Caff 立场无关。本文内容仅用于信息分享,均不构成任何投资建议及要约,并请您遵守所在国家或地区的相关法律法规。














