

作为 Arweave 的重要中间件,KYVE 解决了什么问题?
基础概念
1. 什么是 Arweave?
- Arweave 是去中心化数据存储的协议/网络
- Arweave 实现了数据的永久储存
- Arweave 实现了一次付费永久储存的经济模式
- Arweave 不是传统意义的链式结构,而是使用了类似图状的 Weave 数据结构,新节点无需同步所有旧数据
- Arweave 使用 SPoRA((Succinct Proofs of Random Access,随机访问的简洁证明)) 共识,该共识鼓励存储更多的数据,储存更少节点储存的数据。通过储存内容 + 算力的方式来竞争出块,更多共识细节可以参考这里
2. 什么是中间件?
- 中间件是一类介于系统层与应用层中,掩盖系统层开发细节,直接提供应用层业务所需功能的工具
- 区块链领域的中间件可以理解为,避免了直接与底层链端交互开发,辅助上层应用进行开发的一系列工具,例如 Chainlink/The Graph/Infura 等都属于中间件
3. 什么是 KYVE?
- KYVE 是一组提供数据流标准化存储与验证的去中心化协议
- KYVE 协议构建在一条基于 CosmosSDK 的公链 Korellia 上
- KYVE 是 Arweave 生态最重要的应用之一,作为存储中间件双雄 KYVE + Bundlr 之一
4. KYVE 解决了 Arweave 什么问题?
4.1 扩容问题
- 链上储存扩容
- 传统区块链类似 Ethereum 全节点大小已经达到 700G, 日益增长的链数据会造成节点的储存压力, 也就是我们常说的状态爆炸问题,不断提高着新节点加入的门槛。KYVE 最主要的一项业务便是归档其它区块链的数据并储存至 Arweave。区块链数据在归档到 Arweave 后可以压缩裁剪掉可以通过计算还原的历史中间状态数据,仅保留较近一段时间的中间状态数据和最新状态数据用作节点验证,大幅缩小储存压力。
- KYVE 使用了一种被称为 Bundle 的批处理技术,将多个数据进行捆绑处理,大大加快存储与验证的效率, 也降低了存储开销。某种程度上 KYVE 也可以看作 Arweave 的 Rollup。
- KYVE 使用不同的 Runtime 模块来匹配不同类型的区块链数据类型,抓取区块数据存储后,也可以非常方便查找,提供了一定程度的检索功能
- 链下计算扩容
- 传统区块链例如 Ethereum 的节点需要同时负责执行/结算/共识/DA 的工作。执行的意思就是每次智能合约的调用,几乎所有节点都需要去执行一遍计算。这样做安全性非常高但是也有显而易见的问题 - 效率很低,导致的问题大家也都清楚 - 网络堵塞,费用高昂。这个时候就出现了计算扩容的需求
- 针对传统区块链的扩容有很多方向, 侧链/rollup/新共识/链下扩容等。链下扩容的基础思路是将执行部分放到用户本地或者单独的链下节点进行计算。好处是显而易见的,这里执行计算的机器只有一台或者少数的几台,节约了大量计算资源。而且链下机器可以针对特定计算类型进行优化,达到计算效率的最优化
- Arweave 的永久储存特性可以保证链上储存的数据不可更改性 (数据可用性),这个在链下扩容看来就像图灵机的纸带,所有的合约代码与合约运行状态都可以持续的记录到 Arweave 上,用户在使用时将合约代码与合约的所有运行状态同步到本地,进行一遍状态计算确保最新状态的有效性后,就可以开始执行自己的操作,最后将最新的合约状态再上传至 Arweave 完成链下计算的功能
- 上面说的 Arweave 提供的这种链下计算方法叫做 SmartWeave, 是 Arweave 团队开发的智能合约执行环境。通过上面流程的描述可以发现一个问题,为了获得最新状态数据的有效性保证,用户在本地执行链下计算需要先下载所有历史状态数据并进行一遍验证计算。显然如果历史状态过多或者计算量巨大,用户每次实际使用前都浪费大量时间和算力在同步历史数据与验证最新状态上。KYVE 通过整个网络的共识可以保证最新状态的有效性,那么借助 KYVE 的最新状态数据,用户便可以直接开始自己的链下计算工作了,计算完成后通过 KYVE 再将状态更新回 Arweave。KYVE 解决了上传下载过程中数据有效性这个对于链下计算扩容来说至关重要的问题
4.2 数据跨链问题
- 已有数据跨链方案的问题
- 如今最常用的数据跨链方案大都遵循监控 - 中继模型, 在源链上会有一组合约监控具体的数据状态并生成证明文件,证明文件通过中继网络发送到目标链上。这里可以看到两个问题,源链上的监控者需要持续的监控状态变更,还需要持续生成证明文件,开销是一个问题。更重要的问题是数据信息的中继需要完全信赖中继网络,这也是整个系统最薄弱的地方。
- 中继或者见证人的存在本质上是为了解决 DA 信息相互独立隔绝的问题。假如多条链的 DA 存放在同一个 DA 层上,那所有信息中继都只是 DA 层内的信息传递,安全性等同于 DA 层的安全性,那就只需监控者就可以完成跨链。
- KYVE + Arweave = DA Layer?
- 最近很火的专注于 DA 的区块链 Celestia 最重要的一个 Feature 就是解决了数据跨链互操作的问题。因为所有其上的区块链都将 DA 数据存放其中,所以数据跨链本质上就只需要监控这一个角色了,所有中继都是链内的信息传递,这个安全性等同于区块链的安全性。之前我们讨论过 KYVE 保证了数据的有效性,Arweave 保证了数据的可用性,那本质上 KYVE+Arweave 完全可以作为 DA 层,达到和 Celestia 一样的数据跨链和互操作性效果
- KYVE 相较于 Celestia 的优势在于获取数据的主动性。KYVE 是中间件,网络内可以通过治理提案很容易的创建新的数据池来抓取特定区块链的数据。Celestia 是被动获取构建于其上的执行层的数据,选择一定程度上是受限的。
- 还有一点我们不能忘记,KYVE 的底层网络 Korellia 是基于 CosmosSDK 的独立 POS 链。所以 IBC 是完全适用于 KYVE 的,我想像不出还有哪个网络比 KYVE 更适合作为 Arweave 与 Cosmos 生态的 IBC 接口。
KYVE 架构

5.1 网络设计
- Protocol Layer
- 协议层架构于链层之上,负责现有 KYVE 业务 (Pools/Fund/Stake/Delegate)
- 创建和维护各种数据池
- 数据池内 Protocol 节点负责上传和验证数据
- 数据池内 Protocol 节点负责达成数据有效性共识
- 数据池内节点发送自身状态到 Chain 节点
- Chain Layer
- Tendermint 共识, 保存 Protocol 节点的状态
- 负责保证 Protocol 的状态有效性 (目前只有 KYVE 协议)
5.2 网络角色
- Pools
- 数据池可以被看做是完成收集及验数据工作的最小单位
- 数据池内包含 Funder/Protocol Staker/Protocol Delegator 角色
- 数据池的运行规则依赖 runtime 模块
- 针对不同的虚拟机环境需要不同的 runtime,但是相同的虚拟机环境可以复用 runtime
- @kyve/evm 可以用在 Ethereum 上,也可以用在 EVM 兼容链上 (Moonbeam/Aurora)
- 对于 Solana 则要使用 @kyve/solana

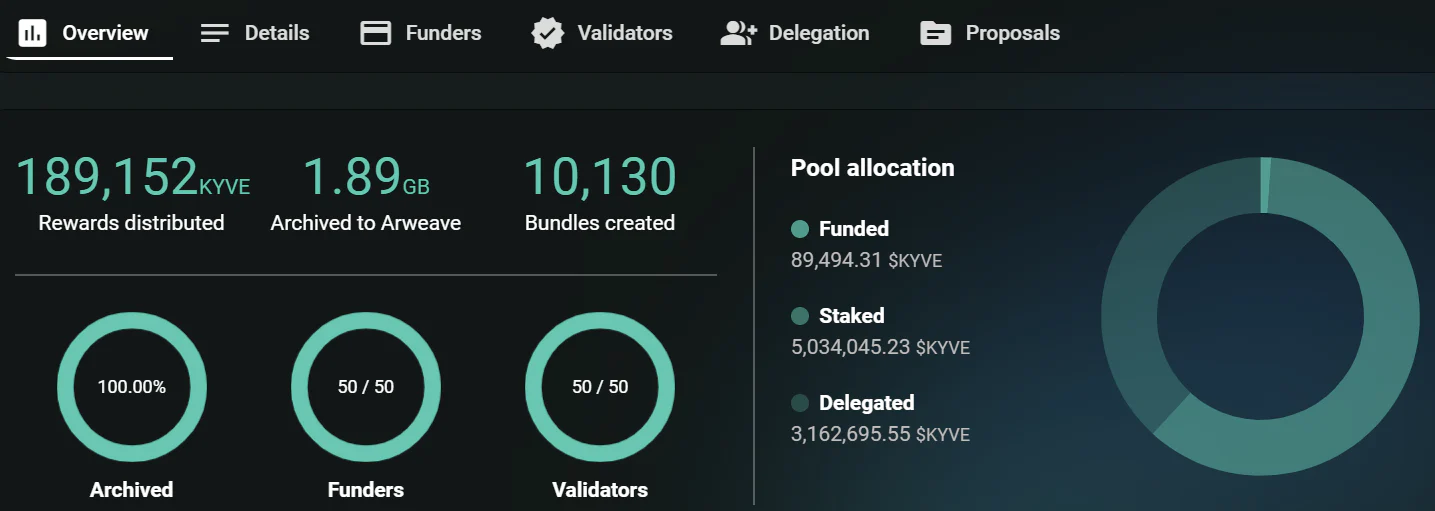
- Funder
- Funder 是每个数据池的资金来源,数据池内所有其它角色的盈利来自于 Funder
- Funder 是需要使用该数据池数据的项目方或者用户,如果数据池内的 funding 被耗尽则该数据池会停止工作
- 目前每个数据池只有 100 个 Funder 卡槽,目前 Funder 没有激励,但是不排除之后针对数据池给与 Funder 的特权与激励
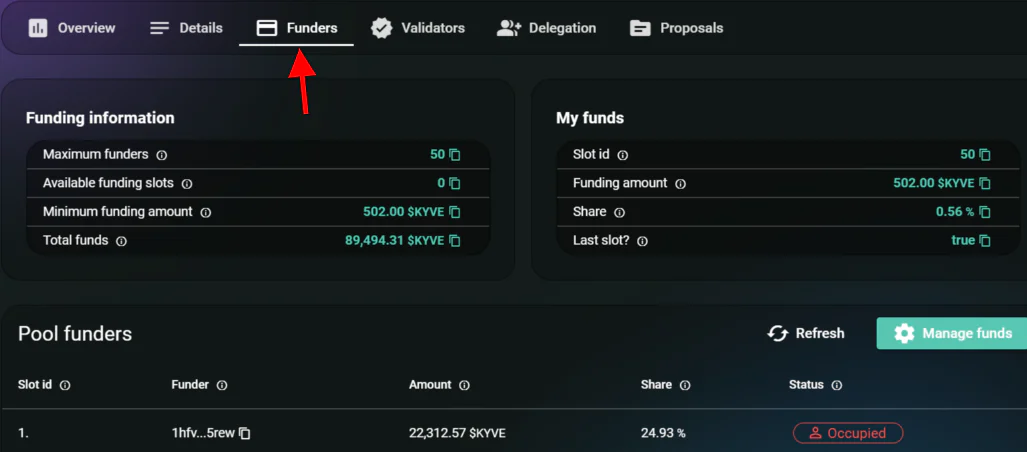
- Protocol Staker
- Protocol Staker 是数据池内运行节点的角色,真正负责数据池内的上传验证等工作
- 成为 Protocol Staker 需要质押 kyve 代币,如果出现不良行为 (离线/上传错误数据/验证数据失误等) 会造成节点内质押代币的 slash
- Protocol Staker 会按工作量获得 kyve 代币奖励,奖励和节点代币质押量相关

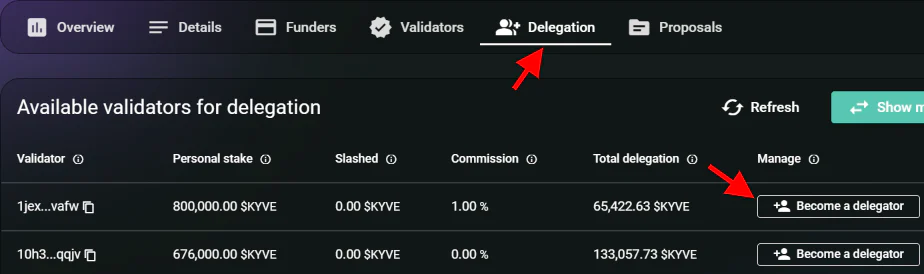
- Protocol Delegator
- 如果你不想自己运行 Protocol 节点, 可以选择作为 Delegator, 将 kyve 代币质押给自己支持的 Staker 来分享节点的工作收益
- Protocol Staker 的不良行为也会造成在其上质押的 kyve 的 Delegator 被 slash
- Protocol Delegator 可以帮助筛选出优质节点,共享网络收益
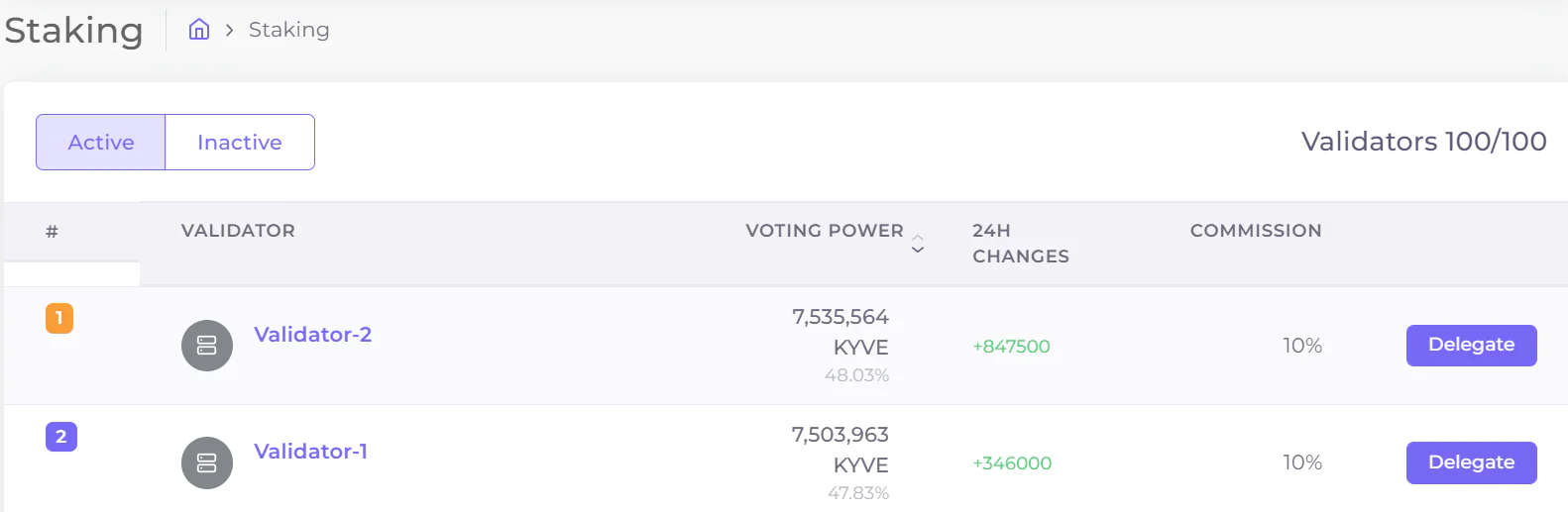
- Chain Staker
- Chain Staker 需要在 Korellia 网络上运行 Chain 节点,负责 Korellia 网络的有效与安全
- Chain Staker 在运行 Chain 节点时也需要质押 kyve 代币,类似于其它 Cosmos 生态链
- Chain Delegator
- Chain Delegator 质押代币给支持的 Chain Staker 来分享节点工作收益,和其它 cosmos 生态的链的 Stake 机制相同
5.3 经济设计
- 金库
- Protocol 节点每次完成 bundle proposal 都会从 Funder 处获取奖励,其中 1% 作为网络费用会被直接扣除到金库
- Slash 的资金也会进入金库
- 金库资金用于网络的发展与治理
- Slashing
- 无效上传行为,会造成当事节点 20% 质押代币的罚没
- 无效验证行为,会造成当事节点 10% 质押代币的罚没
- 超时离线行为,会造成当事节点 1% 质押代币的罚没
KYVE 工作原理
6.1 Data Bundle
- 为了加快 KYVE 中数据验证的效率,所有数据在被上传前都被打包成 bundle,这样在一个验证轮内可以同时处理多个数据,数据流也可以被拆分至多个验证轮中执行。
6.2 Bundle Lifecycle
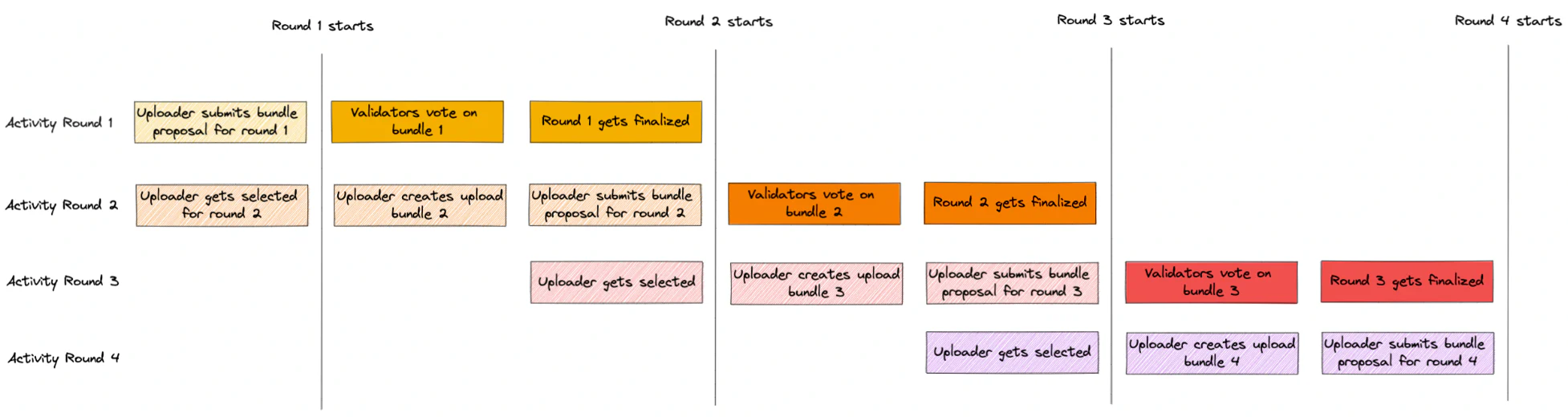
- 1. 选择一个 Uploader
- 每一个验证轮由选举此轮的 Uploader 开始
- Uploader 的选择与节点 staker 的质押量以及 Delegation 数量相关
- 2. 创建 Bundle Proposal
- 上面选择出来的 Uploader 按照设定的 upload_interval 去收集数据
- 一旦收集到足够数据,数据就被发到 buffer 进行 gzip 压缩
- 最后创建一个 bundle proposal 之后供其它 validator 进行验证
- 3. 上传 Bundle 到 Arweave, 将上传信息同步到 Kyve 网络
- Uploader 将上面打包完成的 bundle 上传至 Arweave
- 将 Arweave 返回的上传记录以及其它上传信息同步至网络中
- 4. Validator 验证 Bundle 的有效性
- 当 Uploader 将上传记录和其它 bundle 信息同步到网络后,validator 便开始对数据有效性进行验证
- validator 会从 Arweave 下载原始 bundle 数据,解压缩,然后把数据解析到原始 json 格式,然后和源数据进行一次哈希比对
- 最后 validators 通过对 proposal 的投票来达成数据有效性的共识
- 5. 达成网络状态的最终性
- 如果超过一半的 validator 确认数据的有效性,则达成网络状态的最终性,此 Bundle Id 也可以被提供给外部使用
- 网络内奖励的分配
合作生态
- Arweave
- Solana
- Near
- Avalanche
- Mina
- Cosmos
- Moonbeam
- Aurora
- Octopus
- Celo
- Zilliqa
参考
https://docs.kyve.network/basics
https://zhuanlan.zhihu.com/p/420221118
https://members.delphidigital.io/reports/arweave-the-permanent-storage-experiment
https://medium.com/everfinance/a-storage-based-computation-paradigm-enabled-by-arweave-de799ae8c424
免责声明:作为区块链信息平台,本站所发布文章仅代表作者及嘉宾个人观点,与 Web3Caff 立场无关。本文内容仅用于信息分享,均不构成任何投资建议及要约,并请您遵守所在国家或地区的相关法律法规。














