在前進的路線圖中我們最先到達的,是通過利用 Ai 助理(不一定可信)來改變你與 dapp 交互的方式(下面視頻展示)。 其次到達的將是協定/鏈層級的網路,最終將實現共用的擁有權與治理。
原文:Don't Trust, Verify: An Overview of Decentralized Inference
編譯:LlamaC
「推薦寄語:人工智慧(Ai)是大眾認知最廣泛且最深刻的稱呼,目前驅動我們進入 AGI(通用人工智慧)或在未來實現 ASI(超級智慧)的是利用神經網路訓練出來的大腦,這個大腦本質是一個大型語言模型(Large Language Model),簡稱 LLM。 目前大眾認知最廣交互最多的 LLM 是 ChatGPT。 大家對 ChatGPT 能在未來可創造巨大價值的共識上沒有任何質疑。 假設有條路徑有可能使其價值被大家共用,那麼 DeGPT(去中心化 ChatGPT)就是可被寄託的烏托邦。 在前進的路線圖中我們最先到達的,是通過利用 Ai 助理(不一定可信)來改變你與 dapp 交互的方式(下面視頻展示)。 其次到達的將是協定/鏈層級的網路,最終將實現共用的擁有權與治理。」
擴充視訊:
當前利用 Ai 助理可實現的是將我們從不同協定交互介面的低效率中解放出來,而且是通過我們最適應的文字交談方式。 至少將有以下幾種意圖交互例子:
1、我想通過 EigenLayer 重新質押我的 $ETH,並將其委託給 AVS,期望至少有 X% 的年化收益率和最多 Y% 的風險。
2、我想將 X 美金的總額在未來 20 天中平均分配資金以不超過當前價格的 20% 買入 Y 這個代幣。
3、幫我將 X 量的 USDC 質押至鏈上協定中賺取收益,年利率至少為 Y%,風險不高於 Z%。
簡而言之,擁有最佳體驗/安全的 Ai 助理將有望成為新的流量入口並在與大型協定的集成上掌控更高的議價權。
在開始正文閱讀之前,了解什麼是 Ai 訓練和 Ai 推理? 他們的區別是什麼? 將極大的提升您讀懂正文的能力。
AI 訓練(AI Training)和 AI 推理(AI Inference)是人工智慧(AI)領域的兩個主要階段,它們在 AI 系統開發和運行過程中扮演著關鍵角色。 讓我們用一個簡單的類比來理解它們:
想像一下,你正在學習做飯。 這個過程可以類比為 AI 訓練。
1. AI 訓練:
◦ 就像你在學習做飯時,需要閱讀食譜、觀看教學視頻、向廚師請教,並親自嘗試各種食材和烹飪方法。
◦ 在 AI 中,這個過程涉及到使用大量數據(食譜和教學視頻)來「教導」AI 模型(你的烹飪技巧)如何執行特定任務,比如識別圖片中的物體或理解語言。
◦ 訓練過程中,AI 模型會不斷調整自己,以更好地從數據中學習規律和模式。
◦ 訓練完成後,你會得到一個「訓練好的」模型,就像你經過練習后能夠熟練地做出一道菜。
2. AI 推理:
◦ 一旦你學會了做飯,你就可以使用你的技能來準備新的菜餚,不需要每次都查閱食譜或觀看教學視頻。
◦ 在 AI 中,推理是使用訓練好的模型來對新數據做出預測或決策的過程。 例如,一個訓練好的圖像識別模型可以用來識別新拍攝的照片中的內容。
◦ 推理通常需要較少的計算資源,因為它不涉及模型的學習過程,只是應用已有的知識來解決問題。
區別:
•目的:AI 訓練的目的是創建或改進模型,而 AI 推理的目的是使用模型來執行任務。
•過程:AI 訓練是一個涉及大量數據和計算資源的過程,需要不斷調整和優化;AI 推理則是一個應用訓練好的模型來快速做出決策的過程。
•資源需求:訓練通常需要更多的時間和計算能力,因為它涉及到模型的學習; 推理則相對快速且資源需求較低,因為它只是模型的應用。
簡而言之,AI 訓練就像是學習和練習,而 AI 推理就像是實際應用所學到的技能。
正文:
假設您想運行一個大型語言模型,如 Llama2-70B。 這樣一個龐大的模型需要超過 140GB 的記憶體,這意味著您無法在家中的機器上運行原始模型。 您的選擇是什麼?您可能會選擇雲服務提供者,但您可能不太願意信任一個單一的中央公司來處理這項工作,並吞噬掉您所有的使用數據。 那麼您需要的是去中心化推理,它允許您在不依賴任何單一提供者的情況下運行機器學習模型。
信任問題
在去中心化網路中,僅僅運行一個模型並信任其輸出是不夠的。 假設我要求網路使用 Llama2-70B 分析一個治理困境。 我怎麼知道它實際上在使用 Llama2-13B,給了我更差的分析,並私吞了我的差額?
在中心化世界中,您可能信任像 OpenAI 這樣的公司會誠實地完成這項工作,因為他們的聲譽岌岌可危(而且在某種程度上,LLM 的品質是不言自明的)。 但在去中心化世界中,誠實不是假設的——它是經過驗證的。
這就是可驗證推理發揮作用的地方。 除了提供對查詢的回應外,您還可以證明它在您要求的模型上正確運行。 但如何做到呢?
天真的方法是将模型作为链上智能合约运行。这肯定能保证输出经过验证,但这是非常不切实际的。GPT-3 用 12,288 的嵌入维度表示单词。如果您要在链上进行这样大小的单个矩阵乘法,根据当前的汽油价格,将花费大约 100 亿美元——计算将填满每个区块约一个月。
所以,不行。我们需要一种不同的方法。
验证问题
在观察了这个领域之后,对我来说很明显,已经出现了三种主要方法来解决可验证推理问题:零知识证明、乐观欺诈证明和加密经济学。每种方法都有其自己的安全性和成本影响。
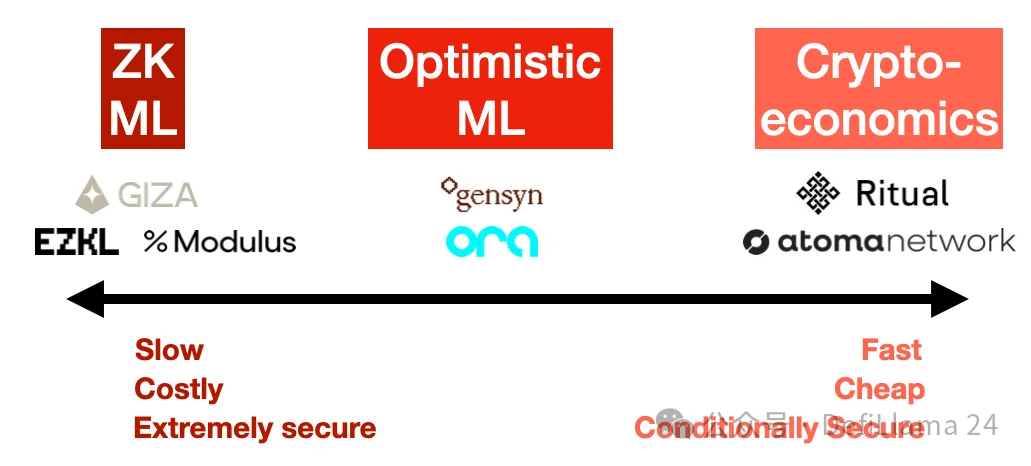
1. 零知识证明(ZK ML): 想象一下,能够证明您运行了一个庞大的模型,但证明的大小实际上是固定的,无论模型有多大。这就是 ZK ML 承诺的,通过 ZK-SNARKs 的魔力。
虽然原则上听起来很优雅,但将深度神经网络编译成零知识电路,然后可以证明是非常困难的。这也极其昂贵——至少,推理成本和延迟(生成证明的时间)可能至少是 1000 倍,更不用说在进行任何这些操作之前将模型本身编译成电路了。最终,这些成本必须转嫁给用户,因此对于最终用户来说,这将非常昂贵。
另一方面,这是唯一在密码学上保证正确性的方法。有了 ZK,无论模型提供者多么努力尝试作弊,都无法成功。但它这样做的代价是巨大的,使得这种方法在可预见的未来对于大型模型来说不切实际。
项目示例:EZKL、Modulus Labs、Giza
https://ezkl.xyz/|https://www.modulus.xyz/ | https://www.gizatech.xyz/
2. 乐观欺诈证明(Optimistic ML): 乐观的方法是信任,但验证。我们假设推理是正确的,除非有其他证据。如果一个节点试图作弊,“观察者” 在网络中可以叫出作弊者,并使用欺诈证明挑战他们。这些观察者必须一直在观察链,并在自己的模型上重新运行推理,以确保输出是正确的。
这些欺诈证明是 Truebit 风格的交互式挑战-响应游戏,您可以反复在链上将模型执行二分法,直到找到错误。

如果這種情況真的發生,成本是難以置信的,因為這些程式非常龐大,並且有巨大的內部狀態——單個 GPT-3 推理的成本約為 1 petaflop(10^15 次浮點運算)。 但博弈論表明,這種情況幾乎永遠不會發生(欺詐證明也很難正確編碼,因為代碼幾乎從未在生產中被擊中)。
樂觀的一面是,只要有一個誠實的觀察者在關注,Optimistic ML 就是安全的。 成本比 ZK ML 便宜,但請記住,網路中的每個觀察者都在自己重新運行每個查詢。 在平衡狀態下,這意味著如果有 10 個觀察者,那麼安全成本必須轉嫁給使用者,因此他們將不得不支付超過 10 倍的推理成本(無論有多少觀察者)。
缺點,就像 optimistic rollups 一樣,您必須等待挑戰期過去,才能確定響應已驗證。 不過,根據網路的參數化方式,您可能需要等待幾分鐘而不是幾天。
專案示例:Ora、Gensyn(儘管目前尚未明確指定)
https://www.ora.io/ | https://www.gensyn.ai/
3. 加密經濟學(Cryptoeconomic ML): 在這裡,我們放棄所有花哨的技術,做簡單的事情:質押加權投票。 使用者決定應該有多少節點運行他們的查詢,他們各自揭示他們的回應,如果響應之間存在差異,那麼不同的節點將被削減。 標準的預言機東西——這是一種更直接的方法,允許使用者設置他們期望的安全級別,平衡成本和信任。 如果 Chainlink 在做 ML,這就是他們會做的。
這裏的延遲很快——您只需要每個節點的提交-揭示。 如果這被寫入區塊鏈,那麼從技術上講,這可以在兩個區塊內發生。
然而,安全性是最弱的。 如果節點足夠狡猾,大多數節點可能會合理地選擇串謀。 作為使用者,您必須考慮這些節點有多少利益在其中,以及作弊對他們來說需要付出多少成本。 也就是說,使用像 Eigenlayer 重新質押和可歸因安全這樣的技術,網路可以在遇到攻擊造成損失的情況下有效地提供保險。
但這個系統的好部分是,使用者可以指定他們想要多少安全。 他們可以選擇在他們的法定人數中有 3 個節點或 5 個節點,或者網路中的每個節點——或者,如果他們想要 YOLO,他們甚至可以選擇 n=1。 這裡的成本函數很簡單:用戶為他們想要的法定人數中的節點付費。 如果您選擇 3,您將支付 3 倍的推理成本。
這裡的棘手問題是:您能讓 n=1 安全嗎?在簡單的實現中,如果沒人檢查,一個孤立的節點應該每次都作弊。 但我懷疑,如果您加密查詢並通過意圖進行支付,您可能能夠欺騙節點,讓他們實際上只是回應這個任務。 在這種情況下,您可能能夠向普通使用者收取低於 2 倍推理成本的費用。
最終,加密經濟學方法最簡單、最容易,可能也是最便宜的,但它最不性感,原則上也是最不安全的。 但正如往常一樣,細節決定成敗。
專案示例:Ritual(儘管目前尚未明確指定)、Atoma Network、HyperspaceAI
https://ritual.net/ | https://www.atoma.network/ | https://aios.network/
為什麼可驗證 ML 很難
您可能會想知道為什麼我們還沒有這些?畢竟本質上機器學習模型只是非常大的計算機程式。 證明程式被正確執行長期以來一直是區塊鏈的主要內容。
這就是為什麼這三種驗證方法反應了區塊鏈保護其區塊空間的方式——ZKrollups 使用 ZK 證明,Optimistic rollups 使用欺詐證明,大多數 L1 區塊鏈使用加密經濟學。 我們現在看到基本上相同的解決方案並不奇怪。 那麼當應用於 ML 時,為什麼使得這很難?
ML 是独特的,因为 ML 计算通常表示为密集的计算图,这些图被设计为在 GPU 上高效运行。它们不是被设计来证明的。所以,如果您想在 ZK 或 OP 环境中证明 ML 计算,它们必须重新编译成一种使这成为可能的格式——这是非常复杂和昂贵的。
ML 的第二个根本困难是非确定性。程序验证假设程序的输出是确定性的。但如果您在不同的 GPU 架构或 CUDA 版本上运行相同的模型,您将得到不同的输出。即使您必须强制每个节点使用相同的架构,您仍然有算法中使用的随机性问题(扩散模型中的噪声,或 LLM 中的 token 采样)。您可以通过控制 RNG 种子来修复那种随机性。但即使有了所有这些,您仍然面临着最终的威胁问题:浮点运算中固有的非确定性。
幾乎所有 GPU 中的操作都是在浮點數上完成的。 浮點數很棘手,因為它們不滿足結合律——也就是說,對於浮點數來說,(a + b)+ c 並不總是與 a +(b + c)相同。 因為 GPU 高度並行化,加法或乘法的順序在每次執行中可能會有所不同,這可能會導致輸出中的微小差異。 這不太可能影響 LLM 的輸出,考慮到單詞的離散屬性,但對於圖像模型,它可能導致圖元值的微妙差異,導致兩個圖像無法完全匹配。
這意味著您要麼需要避免使用浮點數,這將對性能造成巨大打擊,要麼您需要在比較輸出時允許一些寬鬆。 無論哪種方式,細節都很棘手,您不能確切地將它們抽象化。(這就是為什麼,事實證明,EVM 不支援浮點數,儘管像 NEAR 這樣的一些區塊鏈確實支援。)
簡而言之,去中心化推理網路之所以困難,是因為所有細節都很重要,而現實有驚人的細節數量。
總結
現在區塊鏈和 ML 顯然有很多話要說給對方聽。 一個是創造信任的技術,另一個是迫切需要信任的技術。 雖然每種去中心化推理方法都有其自己的權衡,但我非常感興趣看到企業家如何使用這些工具來構建最好的網路。
免責聲明:作為區塊鏈資訊平臺,本站所發佈文章僅代表作者及嘉賓個人觀點,與 Web3Caff 立場無關。 文章內的資訊僅供參考,均不構成任何投資建議及要約,並請您遵守所在國家或地區的相關法律法規。