用 AI 分析 Crypto 代碼和區塊鏈上大規模跑 AI 模型根本不是一回事,以及在 AI 模型中加一些 Crypto 因素也很難稱得上是完美結合。 Crypto 融入 AI 的工作流以及 AI 賦能 Crypto 才是合理選擇。
作者:佐爺歪脖山
封面:Photo by Milad Fakurian on Unsplash
- 湧現(emergence):當許多小的個體相互作用後產生了大的整體,而這個整體展現了構成它的個體所不具備的新特性的現象,比如,生物學所研究的生命現象是化學的一個湧現特性。
- 幻覺(Hallucination):模型有輸出欺騙性數據的傾向,AI 模型的輸出看起來是正確的,實際上是錯誤的。
AI 和 Crypto 的連結呈現出明顯的波段起伏特徵,在 2016 年 AlphaGo 戰勝人類圍棋職業選手后,加密世界自發誕生了 Fetch.AI 等將兩者結合的嘗試,自從 2023 年 GPT-4 的橫空出世,這種 AI + Crypto 的熱潮再起,以 WorldCoin 發幣為代表,人類似乎要進入一個 AI 負責生產力,Crypto 負責分配的烏托邦時代。
這種情緒在 OpenAI 推出文生視頻應用 Sora 后達到高潮,但既然是情緒,總有不理性的成分在,至少李一舟就屬於被誤傷的那一部分,比如
- AI 的具體應用和演算法研發總被混為一談,Sora 和 GPT-4 背後的 Transformer 原理開源,但是使用二者要給 OpenAI 付費;
- AI 和 Crypto 的結合尚屬於 Crypto 的主動貼近,而 AI 巨頭們尚未有明顯意願,現階段 AI 能為 Crypto 做的大於 Crypto 能為 AI 做的;
- 在 Crypto 應用中使用 AI 技術 ≠ AI 和 Crypto 的融合,比如鏈遊/GameFi/元宇宙/ Web3 Game/AW 中的數位人;
- Crypto 能為 AI 技術發展做的,主要是在 AI 三要件算力、數據和模型上的去中心化、代幣激勵等方面的補強;
- WorldCoin 是二者結合的成功實踐,zkML 處於 AI 和 Crypto 的技術交叉點,UBI 理論(人類基本收入)進行了第一次大規模實踐。
我在本文會聚焦 Crypto 能為 AI 增益之處,當前主打 AI 應用的 Crypto 專案主要是噱頭,不便納入討論。
從線性回歸到 Transformer
長期以來,涉及 AI 話題的焦點是人工智慧的「湧現」會不會造就《駭客帝國》中的機械智慧體或者矽基文明,在人類和 AI 技術的相處上,此類擔憂一直存在,最近的是在 Sora 問世後,而稍早前也有 GPT-4(2023)、AlphaGo(2016)和 1997 年 IBM 的深藍擊敗國際象棋。
此類擔憂從未成真也是事實,不如放鬆心態,簡要梳理下 AI 的作用機制。
我們從線性回歸出發,其實就是一元一次方程,比如賈玲的減肥機制,就可以做如下歸納,x 和 y 分別代表攝入能量和體重的關係,即吃的越多自然長得越胖,如果要減肥那麼就要少吃。
但是,這樣會帶來一些問題,第一,人類的身高和體重有生理極限, 3 米巨人和千斤大小姐不太容易出現,因此考慮極限以外的情況缺乏意義; 第二,單純的少吃多練,並不符合減肥的科學原理,嚴重時會損害身體。
我們引入 BMI(Body Mass Index)身體質量指數,即體重除以身高的平方來衡量二者的合理關係,並且通過吃、睡、練三個因數來衡量身高和體重的關係,因此我們需要三個參數和兩個輸出,明顯線性回歸是不夠用的,神經網路就此誕生,顧名思義,神經網路模仿的是人腦結構,思考次數越多,也有可能越合理,三思而後行,加多加深思考的次數, 即深度學習(我牽強附會亂說的,大家理解意思就好)
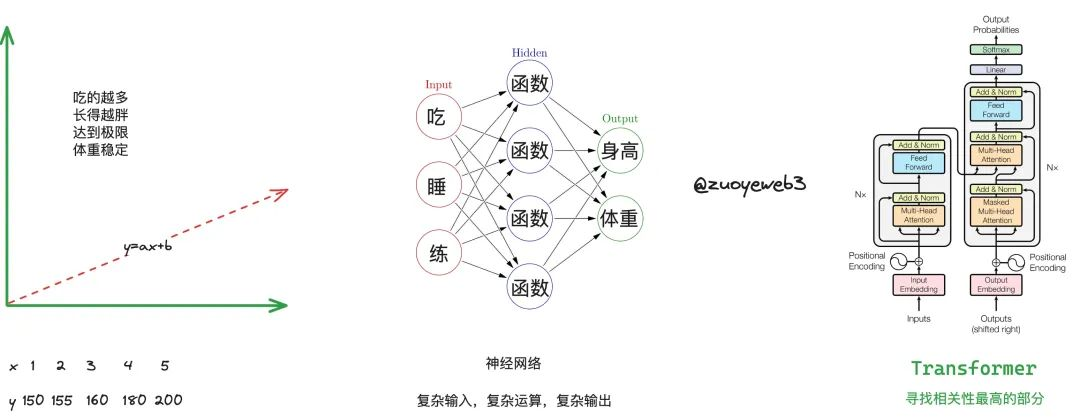
但是層數的加深也不是無止境的,天花板依然存在,達到某個臨界值可能效果就會變差,因此通過更合理的方式理解既有資訊之間的關係就變得很重要,比如深刻理解身高和體重之間更細緻的關係,找到以往沒發現的因數,再或者賈玲找到頂級教練,但是不好意思直說想減肥,那麼就需要教練揣摩下賈玲到底啥意思。

在這種場景下,賈玲和教練構成編碼和解碼的對手,來回傳遞的意思代表了雙方的真正含義,但是不同於 “我要減肥,給教練送禮” 的直白,雙方真正的意圖被 “意思” 隱藏了起來。
我們注意到一個事實,如果雙方往複的次數夠多,那麼各個 “意思” 的含義也就更容易猜出來,並且各個意思和賈玲和教練的關係也會越來越明確。
如果將這個模型擴展,那就是通俗意思上的大模型(LLM,large language model),更精確的說是大語言模型,考察的是詞句之間的上下文關係,但是目前的大模型都被擴展,可以涉足圖像、視頻之類的場景。
在 AI 的光譜中,不論是簡單的線性回歸還是極其複雜的 Transformer 都是演算法或模型的一種,除此之外,還有算力和數據兩個要素。
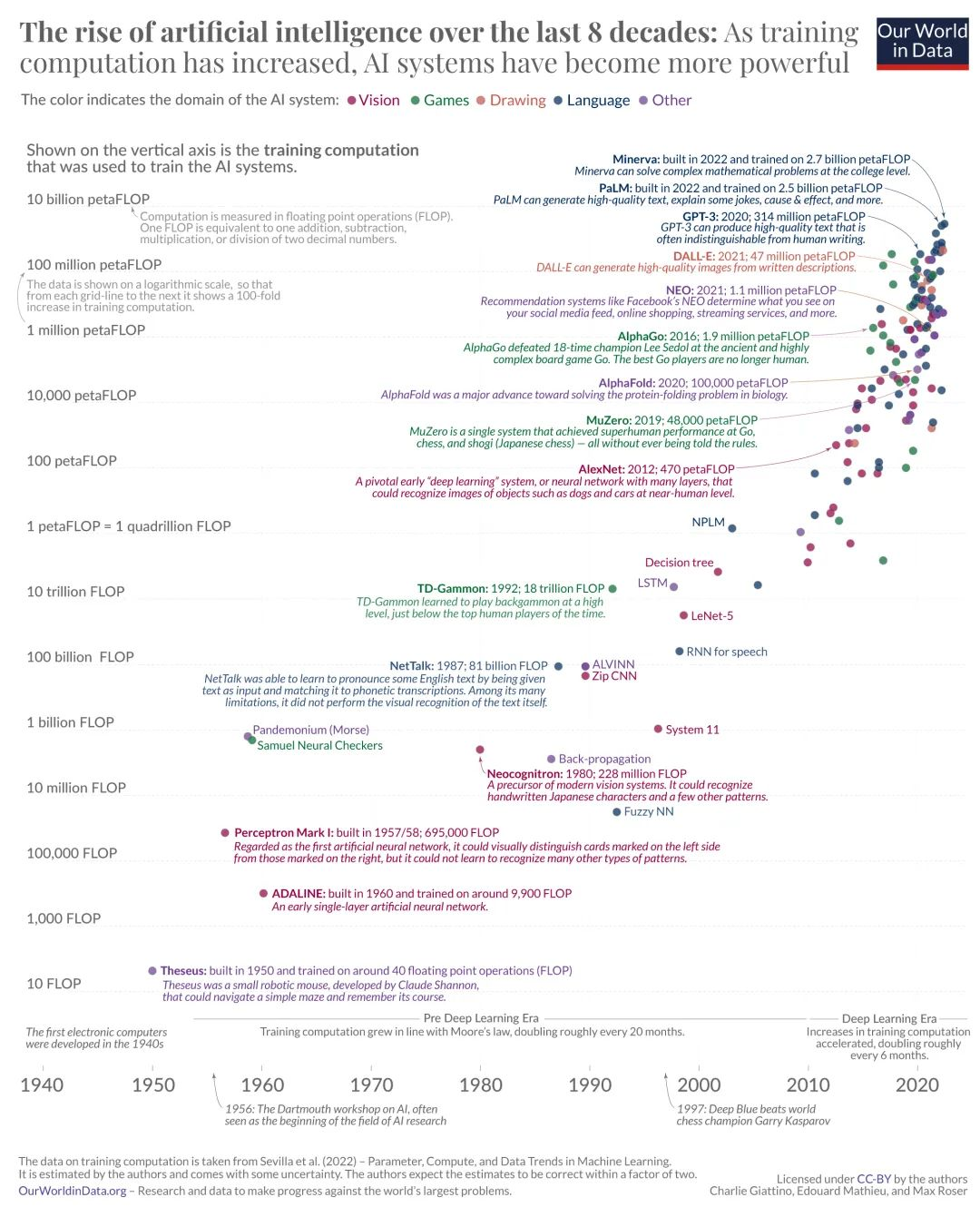
圖源:https://ourworldindata.org/brief-history-of-ai
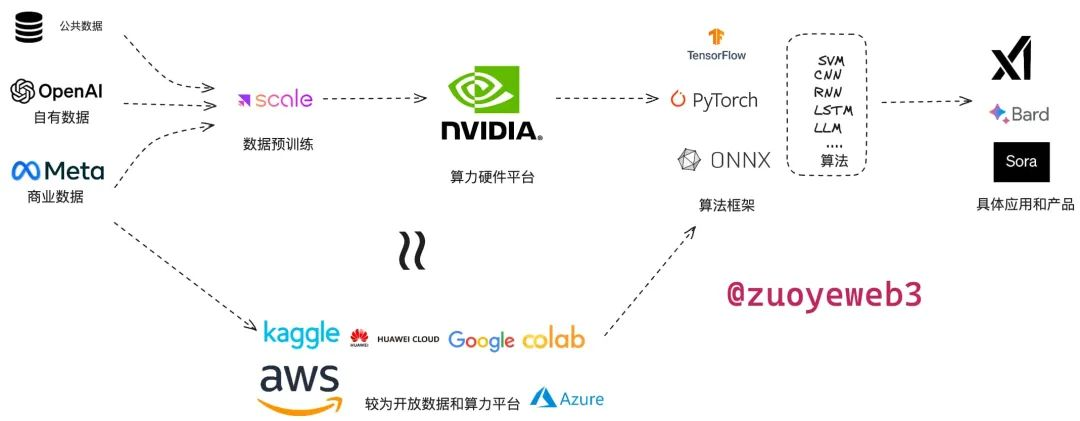
簡單來說,AI 就是吞吐數據,進行運算,導出結果的機器,只不過和機器人等實物相比,AI 更虛擬一些,在算力、數據和模型三部分上,目前 Web2 商業化運作流程如下:
- 數據分為公共數據、公司自有數據和商業數據,需要專業的標註等預處理環節才能使用,比如 Scale AI 公司就為目前主流 AI 公司提供數據預處理;
- 算力分為自建和雲算力租賃兩種模式,GPU 硬體目前英偉達一家獨大,CUDA 庫老黃也準備很多年,目前軟硬體生態一家獨大,其次是雲服務廠商的算力租賃,比如微軟的 Azure、谷歌雲和 AWS 等,很多提供一站式的算力和模型部署功能;
- 模型可以分為框架和演算法兩類,模型之戰已經終結,谷歌的 TensorFlow 先來先涼,Meta 的 PyTorch 後發先至,但是不論是提出 TransFomer 的谷歌還是坐擁 PyTorch 的 Meta 都逐漸在商業化上落伍於 OpenAI,但是實力依舊不容小覷; 演算法目前 Transformer 一家獨大,各類大模型主要在數據源和細節上開卷。
如前所述,AI 應用領域廣泛,比如 Vitalik 所說的代碼修正早已經投入使用,如果換個視角,Crypto 能為 AI 做的主要集中在非技術領域,比如去中心化的數據市場、去中心化的算力平臺等等,去中心化的 LLM 有一些實踐,但是要注意,用 AI 分析 Crypto 代碼和區塊鏈上大規模跑 AI 模型根本不是一回事,以及在 AI 模型中加一些 Crypto 因素也很難稱得上是完美結合。
Crypro 目前還是更擅長生產和激勵,異想天開用 Crypto 強行改變 AI 的生產範式則大可不必,這屬於為賦新詞強說愁,拿著鎚子找釘子,Crypto 融入 AI 的工作流以及 AI 賦能 Crypto 才是合理選擇,以下是我總結的比較可能的結合點:
- 去中心化的數據生產,比如 DePIN 的數據採集,以及鏈上數據的開放性,蘊藏著交易數據的富礦,可用於金融分析、安全分析和訓練數據;
- 去中心化的預處理平臺,傳統預訓練並無不可攀越的技術壁壘,而在歐美大模型的背後,是第三世界人工標註員的高強度勞動;
- 去中心化的算力平臺,個人頻寬、GPU 算力等軟硬體資源的去中心化激勵和使用;
- zkML,傳統的數據脫敏等隱私手段並不能完美解決問題,zkML 可以隱藏數據指向性,也可以有效評估開源和閉源模型的真實性和有效性;
這四個角度是我能想到的 Crypto 能為 AI 賦能的場景,AI 是通用工具,AI For Crypto 的領域和專案就不再贅述,大家可以自行研究。
可以發現,Crypto 目前主要在加密、隱私保護和經濟學設計上發揮作用,技術結合點只有 zkML 有一些嘗試,這裡可以開一下腦洞,如果未來 Solana TPS 真能跑到 10 萬+,Filecoin 和 Solana 結合又比較完美的話,能不能打造一個鏈上 LLM 環境,這樣能打造出一個真實的鏈上 AI,改變目前的 Crypto 附著於 AI, 兩者地位不對等的關係呢?
Web3 加入 AI 工作流
無需多言,英偉達 RTX 4090 顯卡是硬通貨,目前的某個東方大國很難獲得,但是更嚴重的是,個人、小公司和學術機構也遭遇了顯卡危機,畢竟大型商業公司才是氪金玩家,如果能在自購、雲廠商之外開闢第三條道路,很明顯具備實際的商業價值,也就脫離了純粹的炒作,合理的邏輯應該是 “如果不用 Web3,則無法維持專案運作”,這種才是 Web3 For AI 的正確姿勢。
數據之源:Grass 和 DePIN 汽車全家桶
Grass 由 Wynd Network 推出,Wynd Network 是一個閒置頻寬售賣市場,Grass 是一個開放式的網路數據獲取和分發管道,不同於單純的數據收集和售賣,Grass 具備將數據清洗和驗證功能,以規避越來越封閉的網路環境,不僅如此,Grass 希望能直接對接上 AI 模型,為其提供直接可用的數據集,AI 的數據集需要專業處理, 比如大量的人工微調,以滿足 AI 模型的特殊需求。
擴展一下,Grass 要解決數據售賣的問題,而 Web3 的 DePIN 領域能生產 AI 需要的數據,主要集中在汽車的自動駕駛上,傳統上的自動駕駛需要對應公司自行積累數據,而 DIMO、Hivemapper 等專案直接運行在汽車之上,採集越來越多的汽車駕駛資訊和道路數據。
在以往的自動駕駛中,需要汽車識別技術和高精地圖兩部分,而高精地圖等資訊被四維圖新等公司長期積累,形成事實上的行業壁壘,如果後來者藉助 Web3 數據反而具備彎道超車的機會。
數據預處理:解放被 AI 奴役的人類
人工智慧可以分成人工標註和智慧演算法兩部分,第三世界,如肯亞和菲律賓等地區負責人工標註等價值曲線最低的部分,而歐美的 AI 預處理公司拿走大頭收入,進而出售給 AI 研發企業。
隨著 AI 的發展,更多的企業盯上這部分業務,在競爭下數據標註的單價越來越低,該部分業務主要就是給數據打標籤,類似識別驗證碼的工作,並無技術門檻,甚至有 0.01 元人民幣的超低價。

在這種情況下,諸如 Public AI 等 Web3 數據標註平臺也具備實際商業市場,連結 AI 企業和數據標註民工,使用激勵體系取代單純的商業低價競爭模式,但是要注意,Scale AI 等成熟企業的標註技術保證可靠的品質,而去中心化的數據標註平臺如何控制品質,禁止擼毛黨則是絕對剛需,本質上這是 C2B2B 的企業服務, 單純的數據規模和數量並不能說服企業。
硬體自由:Render Network 和 Bittensor
需要說明,跟比特幣礦機不同,目前沒有專用的 Web3 AI 硬體,現存的算力、計算平臺都是成熟硬體疊加 Crypto 激勵層改造而來,本質上可以歸納為 DePIN 領域,但是和數據來源專案有所區別,故按照 AI 工作流寫在此處。
DePIN 定義可參考我之前寫的文章:Helium 之前的 DePIN 往事,比特幣、Arweave 和 STEPN
Render Network 是「老專案」,並不完全為 AI 準備,最早致力於渲染工作,一如 Render 之名,2017 年開始運營,當時的 GPU 還沒那麼瘋狂,但是市場機遇已經逐步出現,GPU 顯卡市場,尤其是高端顯卡被英偉達壟斷,高昂的價格阻礙渲染、AI 和元宇宙消費者的進入,如果能在需求方和供給方構建起通道, 那麼類似共用單車的經濟模型就有機會成立。
並且 GPU 資源並不需要實際交接硬體,僅調配軟體資源即可,更值得一提的是,Render Network 在 2023 年便轉投 Solana 生態,捨棄 Polygon,在 Solana 並未回暖之時的投奔也被時間證明是正確之舉,對於 GPU 使用和分配而言,高速網路是一種剛需。
如果說 Render Network 是老項目,那麼 Bittensor 則風頭正盛。
BitTensor 建構在波卡之上,其目標是通過經濟激勵訓練 AI 模型,比拼各節點能否將 AI 模型訓練至誤差最小或者效率最高,也是較為符合經典的 AI 上鏈流程的 Crypto 專案,但是真正的訓練過程依然需要英偉達 GPU 和傳統平臺,整體上類似 Kaggle 等競賽平臺。
zkML 和 UBI:Worldcoin 的 AB 面
零知識機器學習(zkML)通過將 zk 技術引入 AI 模型訓練過程,以此來解決數據洩露、隱私失效和模型驗真的問題,前兩者容易理解,zk 加密後的數據仍然可以被訓練,但是不會再洩露個人或者隱私數據。
模型驗真是指某些閉源模型的評估問題,在 zk 技術加持下,可以設定某個目標值,那麼閉源模型可以通過驗證結果的方式證明自己的能力,而無需公開計算過程。
Worldcoin 不僅是較早設想 zkML 的主流專案,還是 UBI(人類基本收入)的擁躉,在其設想中,未來 AI 的生產力將遠超人類的需求上限,因此真正的問題在於公平分配 AI 的福利,UBI 的理念將通過 $WLD 代幣像全球使用者分享,因此必須進行實人生物識別,以遵循公平原則。
當然,目前的 zkML 和 UBI 還在早期實驗階段,但是足夠有趣,我會持續關注。
結語
AI 的發展,以 Transformer 和 LLM 為代表的路線發展也會逐漸陷入瓶頸,一如線性回歸和神經網路,畢竟不可能無限制增加模型參數或者數據量,繼續增加的邊際收益會遞減。
AI 也許是湧現出智慧的種子選手,但現在幻覺問題十分嚴重,其實可以看出,目前認為 Crypto 能改變 AI 的幻覺是一種自信,同時也是一種標準的幻覺,Crypto 的加入很難從技術上解決幻覺問題,但至少可以從公平、透明角度入手改變一些現狀。
參考文獻:
- OpenAI: “GPT-4 Technical Report”, 2023; arXiv:2303.08774.
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin: “Attention Is All You Need”, 2017; arXiv:1706.03762.
- Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, Dario Amodei: “Scaling Laws for Neural Language Models”, 2020; arXiv:2001.08361.
- Hao Liu, Wilson Yan, Matei Zaharia, Pieter Abbeel: “World Model on Million-Length Video And Language With RingAttention”, 2024; arXiv:2402.08268.
- Max Roser (2022) – “The brief history of artificial intelligence: The world has changed fast – what might be next?” Published online at OurWorldInData.org. Retrieved from: ‘https://ourworldindata.org/brief-history-of-ai’ [Online Resource]
- An introduction to zero-knowledge machine learning (ZKML)
- Understanding the Intersection of Crypto and AI
- Grass is the Data Layer of AI
- Bittensor: A Peer-to-Peer Intelligence Market
免責聲明:作為區塊鏈資訊平臺,本站所發佈文章僅代表作者及嘉賓個人觀點,與 Web3Caff 立場無關。 文章內的資訊僅供參考,均不構成任何投資建議及要約,並請您遵守所在國家或地區的相關法律法規。