合併後,以太坊將為共識層實現提議者-構建者分離(PBS)
作者: Hakeen,W3.Hitchhiker
修訂: Evelyn,W3.Hitchhiker
一、以太坊的升級路線圖 M2SVPS
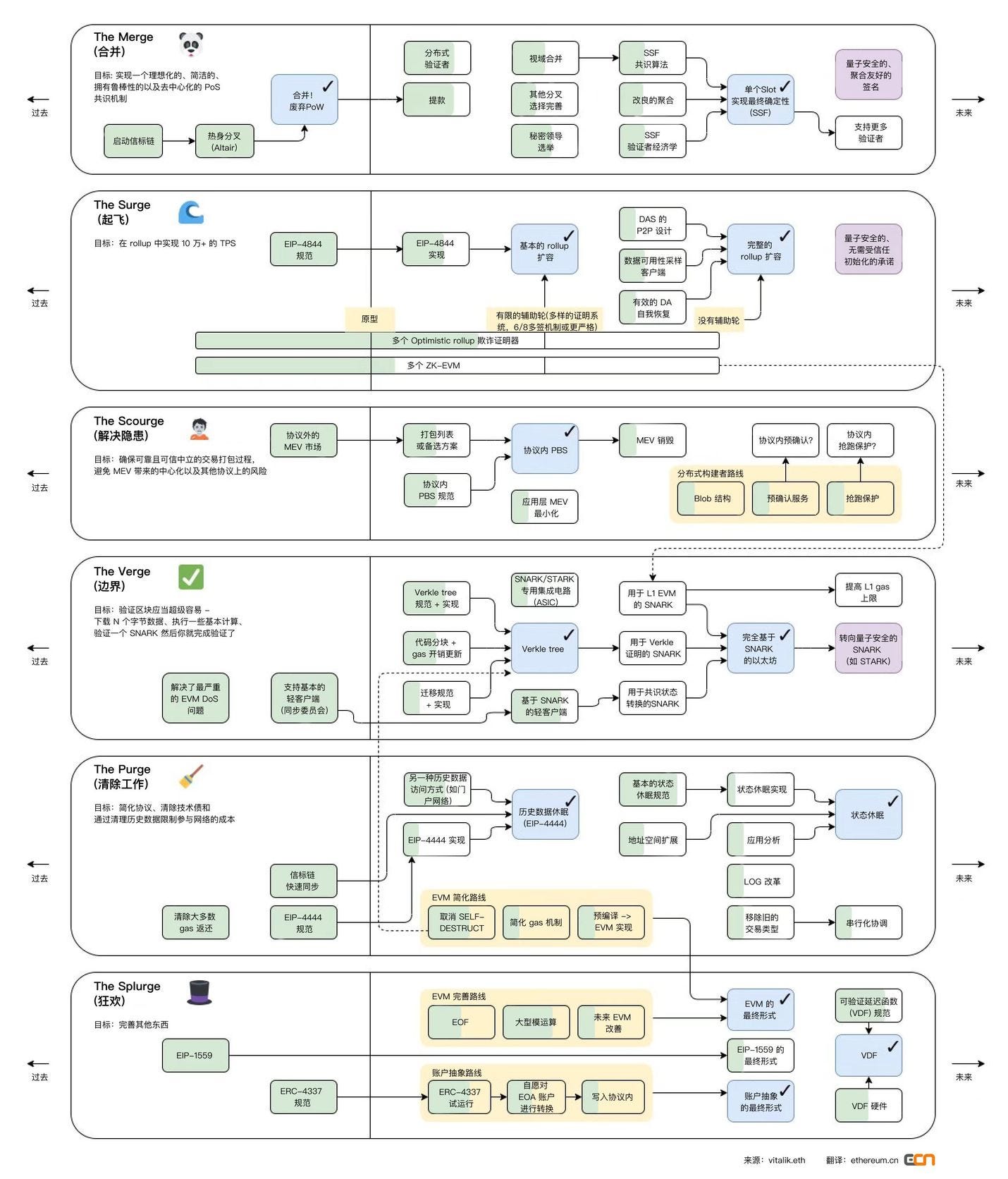
The Merge

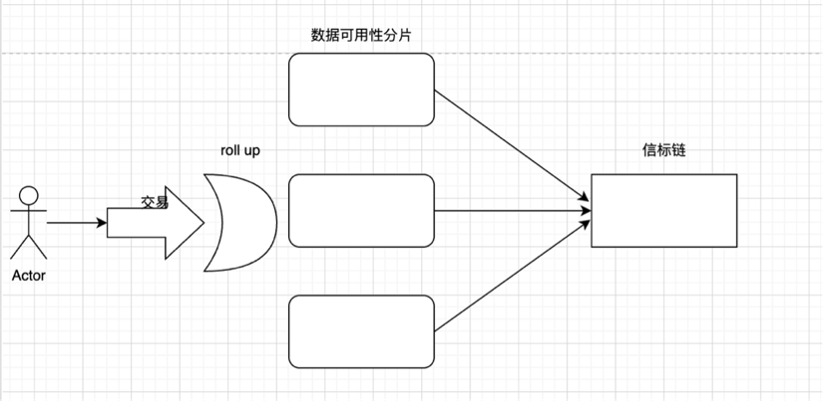
在 The Merge 階段,POW 共識機制將過度為 POS,信標鏈將合併在一起。為了便於理解,我們將以太坊結構簡化為下圖:
我們在這裡先定義什麼是分片:簡單理解就是水平分割數據庫以分散負載的過程
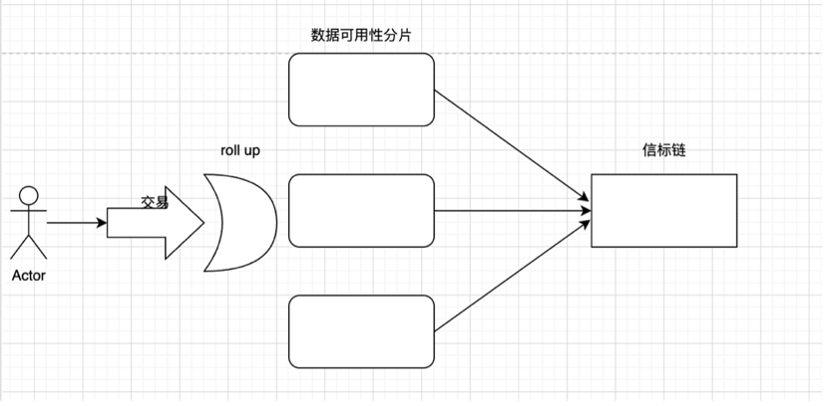
在轉為 POS 後:區塊提議者和區塊驗證者分離,POS 工作流程如下(根據上圖理解):
- 在 Rollup 上提交交易
- 驗證者將交易添加到分片區塊中
- 信標鏈選擇驗證者以提出新的塊
- 其餘的驗證者組成隨機的委員會並驗證分片上的提議
提出區塊和證明提議都需要在一個 slot 內完成,一般是 12s。每 32 個 slot 組成一個 epoch 週期,每個 epoch 將打亂驗證者排序並重新選舉委員會。
合併後,以太坊將為共識層實現提議者-構建者分離(PBS)。Vitalik 認為,所有區塊鏈的終局都將是擁有中心化的區塊生產和去中心化的區塊驗證。由於分片後的以太坊區塊數據非常密集,出於對數據可用性的高要求,區塊生產的中心化是必要的。同時,必須有一種能夠維護一個去中心化的驗證者集的方案,它可以驗證區塊並執行數據可用性採樣。
礦工和區塊驗證分離。礦工進行區塊的構建,然後將區塊提交給驗證者。向驗證者出價投標選擇自己的區塊,然後驗證者投票來決定區塊是否有效。
分片是一種分區方式,可以在 P2P 網絡中分散計算任務和存儲工作負載,經過這種處理方式,每個節點不用負責處理整個網絡的交易負載,只需要維護與其分區(或分片)相關的信息就可以了。每個分片都有自己的驗證者網絡或者節點網絡。
分片的安全性問題:例如整個網絡有 10 條分片鏈,破壞整個網絡需要 51% 的算力,那麼破壞單個分片只需要 5.1% 的算力。因此後續的改進就包含了一個 SSF 算法,這個算法能夠有效防止 51% 的算力攻擊。根據 vitalik 總結,轉向 SSF 是一個多年的路線圖,即使目前做了大量工作,它也將是以太坊較晚推行的重大變化之一,並且遠在以太坊的 PoS 證明機制、分片和 Verkle 樹完全推出之後。
信標鏈,負責生成隨機數,將節點分配給分片,捕捉單個分片的快照和其他各種功能,負責完成分片間的通信,協調網絡的同步。
信標鏈的執行步驟如下:
- 區塊生產者對區塊頭和出價一起進行承諾。
- 信標鏈上的區塊者(驗證者)選擇獲勝的區塊頭和投標,無論區塊打包者是否最終生成區塊體,都將無條件獲得中標費。
- Committee(驗證者中隨機選取)投票確認獲得的區塊頭。
- 區塊打包者披露區塊體。
The Surge
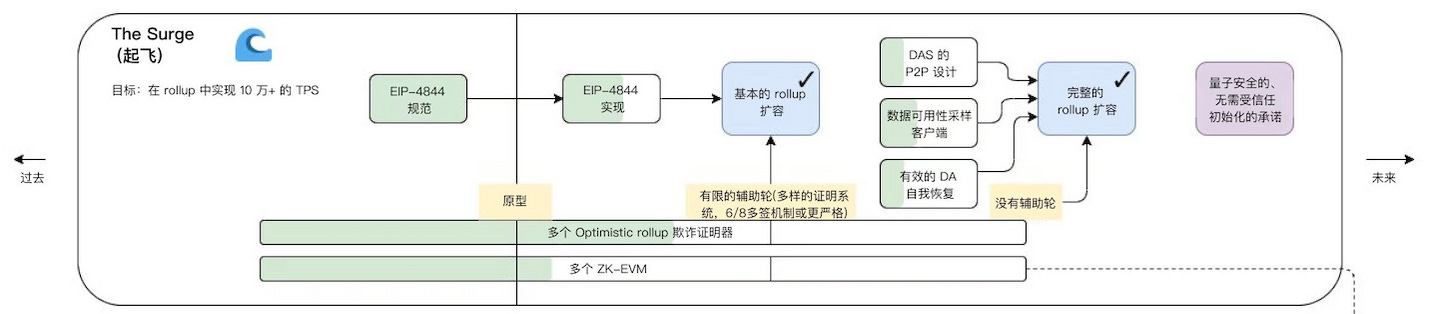
該路線的主要目標是推動以 Rollup 為中心的擴容。Surge 指的是添加了以太坊分片,這是一種擴容解決方案, 以太坊基金會聲稱:該解決方案將進一步啟用低 gas 費的二層區塊鏈,降低 rollup 或捆綁交易的成本,並使用戶更容易操作保護以太坊網絡的節點。
該圖仍然可以通過以下簡圖來理解:
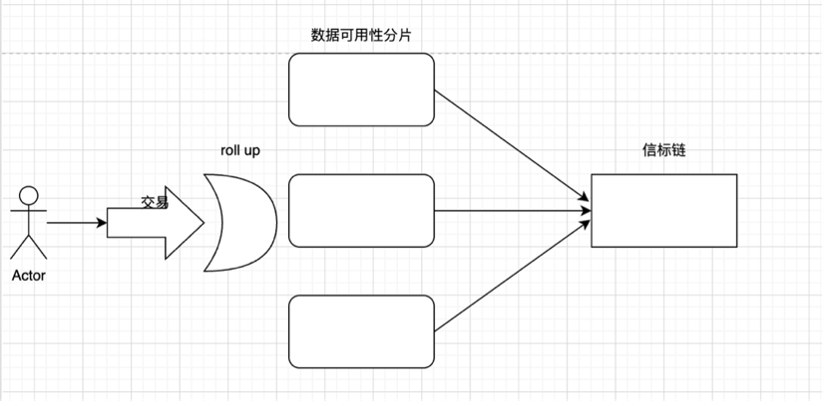
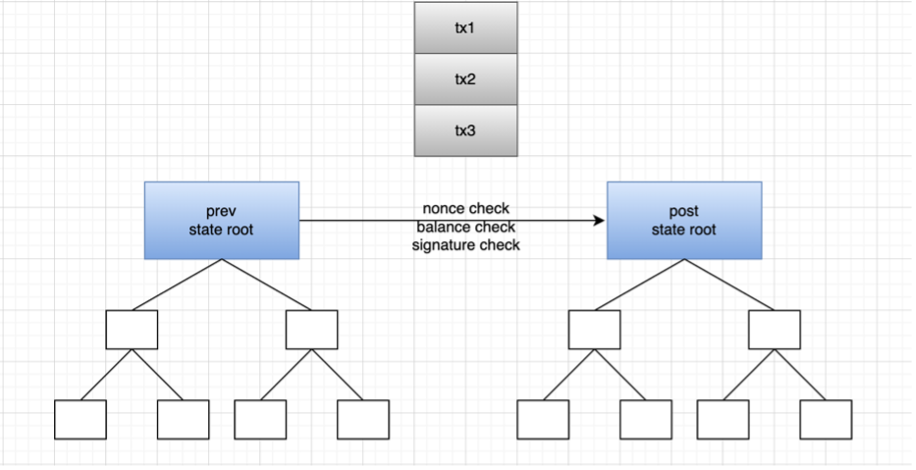
以 zkrollup 運行原理為例:在 zkrollup 中分為排序器(sequencer)和聚合器(aggregator),排序器負責將用戶交易排序,並且將其打包成批次(batch),發送給聚合器。聚合器執行交易,從前狀態根(prev state root),生成後狀態根(post state root),然後生成證明(proof),聚合器最後將前狀態根、後狀態根、交易數據,證明發送到 L1 上的合約,合約負責校驗證明是否有效,交易數據存儲在 calldata 內。Zkrollup 數據可用性可以讓任何人能夠根據鏈上存儲的交易數據,還原出賬戶的全局狀態。
但是使用 calldata 的費用非常昂貴,因此整個 EIP-4844 協議(可能隨時改變)提出了將交易區塊的大小改為 1~2MB,為未來的 rollup 與數據分片打下堅實基礎。目前以太坊的區塊大小大約是 60KB ~100KB,以 EIP-4844 為例,大概可以提升 10~34x 的區塊大小極限。該區塊格式被稱為 blob(也可以稱為數據分片 data shard)。

The Scourge

該階段 Scourge 是路線圖的補充,主要用於解決 MEV 的問題。那什麼是 MEV?
MEV 全名 Miner Extractable Value / Maximal Extractable Value,這一概念最先應用在工作量證明的背景下,最初被稱為 “礦工可提取價值(Miner Extractable Value)”。這是因為在工作量證明中,礦工掌握了交易的包含、排除和順序等角色能力。然而,在通過合併過渡為權益證明後,驗證者將負責這些角色,而挖礦將不再適用(此處介紹的價值提取方法在這次過渡後仍將保留,因此需要更改名稱)。為了繼續使用相同的首字母縮寫詞以便確保延續性,同時保持相同基本含義,現在使用 “最大可提取價值(Maximal Extractable Value)” 作為更具包容性的替代詞。
套利空間包括:
- 通過壓縮存儲空間,來獲得 gas 費用的價差;
- 裁判員搶跑:廣泛的搜索 mempool 上的交易,機器在本地執行計算,看看是否會有利可圖,如果有則用自己的地址發起相同交易,並且使用更高的 gas 費;
- 尋找清算目標:機器人競相以最快的速度解析區塊鏈數據,從而確定哪些借款人可以被清算,然後成為第一個提交清算交易並自行收取清算費的人。
- 夾心交易:搜索人會監視內存池內 DEX 的大額交易。例如,有人想要在 Uniswap 上使用 DAI 購買 10,000 UNI。這類大額交易會對 UNI / DAI 對產生重大的影響,可能會顯著提高 UNI 相對於 DAI 的價格。搜索人可以計算該大額交易對 UNI / DAI 對的大致價格影響,並在大額交易之前立即執行最優買單,低價買入 UNI,然後在大額交易之後立即執行賣單,以大額訂單造成的更高價格賣出。
MEV 的缺陷:
某些形式的 MEV,如夾心交易,會導致用戶的體驗明顯變差。被夾在中間的用戶面臨更高的滑點和更差的交易執行。在網絡層,一般的搶跑者和他們經常參與的礦工費拍賣(當兩個或更多的先行者通過逐步提高自己交易的礦工費,從而使他們的交易被打包到下一個區塊),導致網絡擁堵和試圖運行正常交易的其他人的高礦工費。除了區塊內發生的,MEV 也可能會在區塊間產生有害的影響。如果一個區塊中可用的 MEV 大大超過了標準區塊的獎勵,礦工可能會被激勵去重新開採區塊並為自己捕獲 MEV,進而導致區塊鏈的重新組織和共識的不穩定。
大部分 MEV 是由稱為 “搜索者” 的獨立網絡參與者提取的。搜索者在區塊鏈數據上運行複雜的算法來檢測盈利的 MEV 機會,並且有機器人自動將這些盈利交易提交到網絡。以太坊上的 MEV 問題涉及使用機器人來利用網絡交易,導致擁塞和高額費用。
The Verge
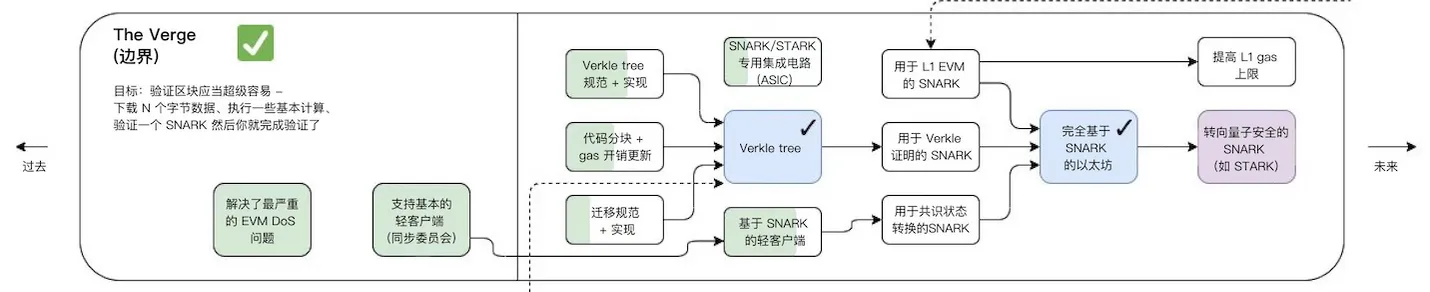
Verge 將實現 “ Verkle 樹”(一種數學證明)和 “無狀態客戶端”。這些技術升級將允許用戶成為網絡驗證者,而無需在他們的機器上存儲大量數據。這也是圍繞 rollup 擴容的步驟之一,前文提到過 zk rollup 的簡易工作原理,聚合器提交了證明,layer 1 上的驗證合約只需要驗證 blob 內的 KZG 承諾和生成的證明即可。這裡簡單介紹一下 KZG 承諾,就是確保所有的交易都被包含了進來。因為 rollup 可以提交部分交易,生成證明,如果使用 KZG,那麼所有的交易都會被確保包含進來生成證明。
The Verge 就是確保驗證非常簡單,只需要下載 N 個字節數據,執行基本的計算就可以驗證 rollup 提交的證明。
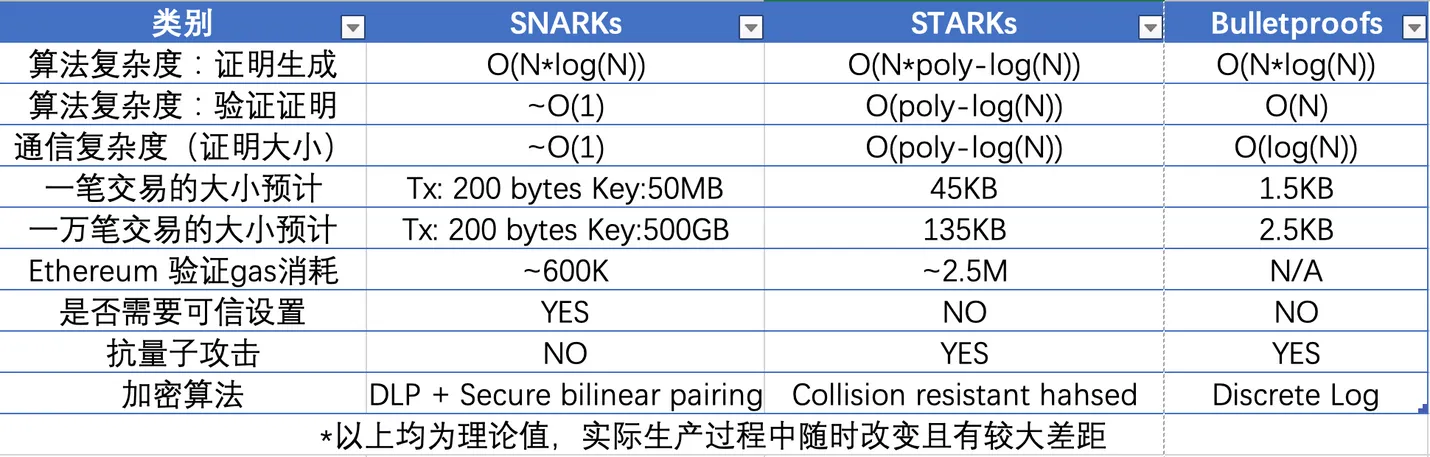
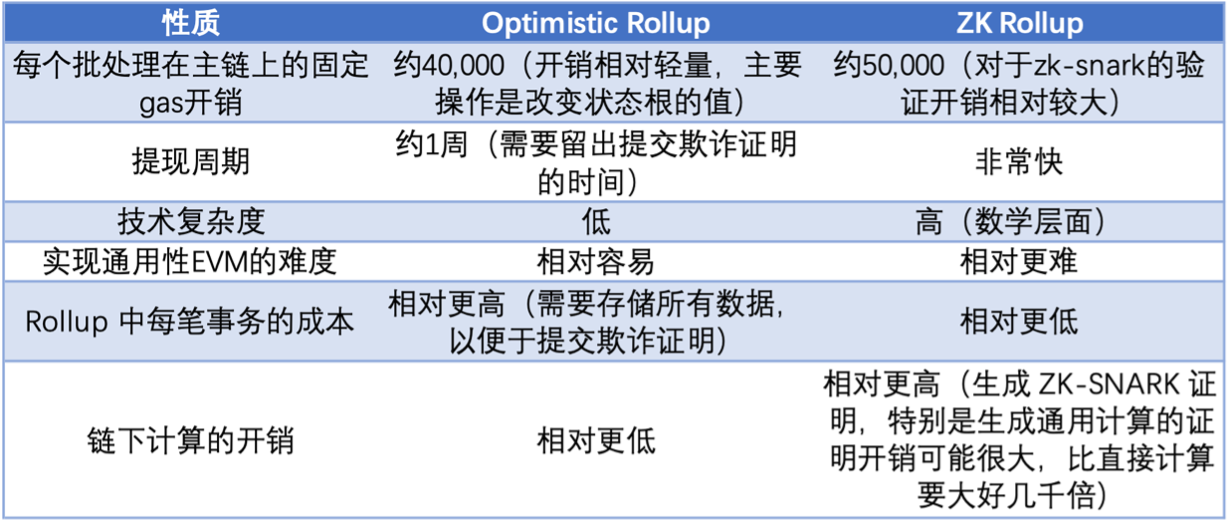
值得一提的是,ZK rollup 有許多種方案,stark、snark 或者 bulletproof 等。各個方案對於證明和驗證的方式都不盡相同,因此出現了權衡。SNARKs 目前比 STARKs 技術更易上手,技術也更完善,因此許多項目剛開始都是使用 SNARKs,但是隨著 STARKs 技術上的迭代後,最終會逐漸轉向抗量子攻擊的 STARKs。雖然以太坊為了與 rollup 適配,EIP-4844 主要改進之一是交易格式 blob,擴大了區塊容量,但目前所有的零知識證明的主要瓶頸仍然在於自身證明算法,一方面通過改進算法來解決證明問題,另一方面通過堆疊硬件來提高證明效率,也因此衍生了 ZK 挖礦賽道。有興趣的可以轉到這篇文章。
The Purge
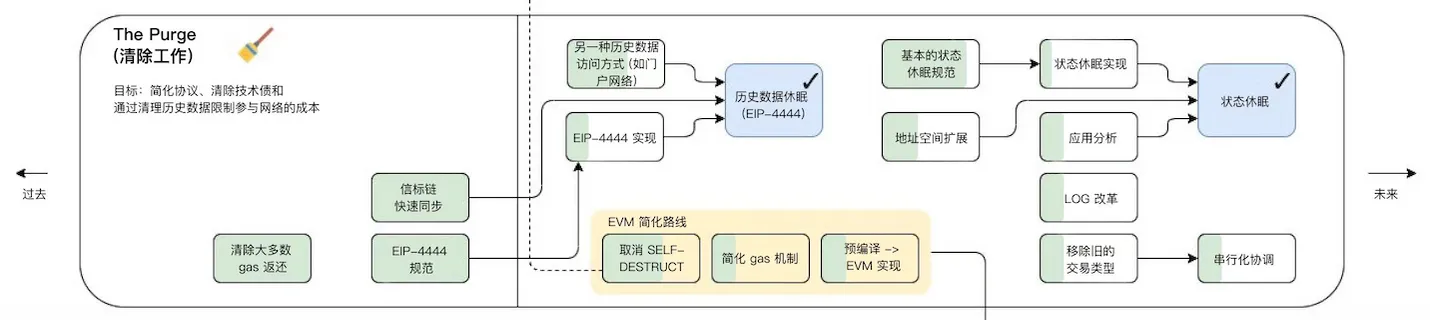
The Purge 將減少在硬盤驅動器上存儲 ETH 所需的空間量,試圖簡化以太坊協議並且不需要節點存儲歷史。這樣可以極大的提升網絡的帶寬。
EIP-4444:
客戶端必須停止在 P2P 層上提供超過一年的歷史標頭、正文和 recipient。客戶端可以在本地修剪這些歷史數據。保存以太坊的歷史是根本,相信有各種帶外方式來實現這一點。歷史數據可以通過 torrent 磁力鏈接或 IPFS 等網絡打包和共享。此外,Portal Network 或 The Graph 等系統可用於獲取歷史數據。客戶端應允許導入和導出歷史數據。客戶端可以提供獲取/ 驗證數據並自動導入它們的腳本。
The Splurge

該路線主要是一些零碎的優化修復,如賬戶抽象、EVM 優化以及隨機數方案 VDF 等。
這裡提到的賬戶抽象(Account Abstraction,AA)一直都是 ZK 系 Layer 2 想要首先實現的目標。那什麼是賬戶抽象?在實現賬戶抽象之後,一個智能合約賬戶也可以主動發起交易,而無需依賴 “元交易” 的機制(這在 EIP-4844 裡被提出)。
在以太坊內,賬戶分為合約賬戶和外部賬戶。目前的以太坊的事務類型只有一種,必須由外部地址發起,合約地址無法主動發起事務。因此,任何合約自身狀態的改變,必須依賴於一個外部地址發起的事務,無論是一個多重簽名賬戶,還是混幣器,或是任何智能合約的配置變更,都需要由至少一個外部賬戶觸發。
無論使用以太坊上的什麼應用,用戶都必須持有以太坊(並承擔以太坊價格波動的風險)。其次,用戶需要處理複雜的費用邏輯,gas price,gas limit,事務阻塞,這些概念對用戶來說過於復雜。許多區塊鏈錢包或應用試圖通過產品優化提高用戶體驗,但效果甚微。
以賬戶為中心的方案的目標是為用戶創建一個基於智能合約管理的賬戶。實現賬戶抽像後的好處是:
- 現在的合約可以持有 ETH,直接提交包含所有簽名的事務,用戶不一定需要為交易支付 gas 費用,完全取決於項目。
- 由於實現了自定義密碼學,因此未來不會強制要求使用 ESCDA 橢圓曲線來進行簽名,未來一台手機的指紋識別、面部識別、生物識別等技術均可以作為簽名方式。
從而顯著改善了用戶與以太坊的交互體驗。
二、以太坊的模塊化
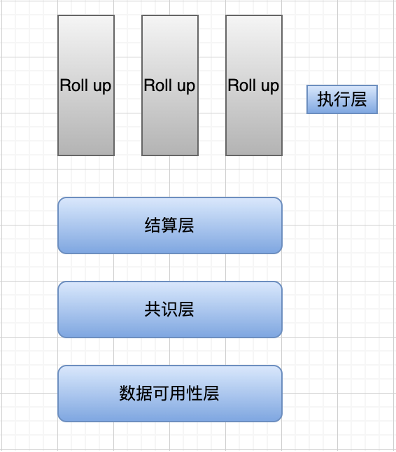
整個以太坊目前已經出現了模塊化的趨勢,執行層就是由 Layer 2 負責(如 arbitrum、zksync、starknet、polygon zkevm 等)。他們負責執行 L2 上用戶的交易,並且提交證明。Layer 2 一般使用的是 OP 技術/ ZK 技術,ZK 技術在理論上 TPS 是遠高於 OP 的,目前大量生態在 OP 系,但是未來,隨著 ZK 技術的完善,會有越來越多應用遷移到 ZK 系。該部分是對路線圖的詳細描述與補充為什麼和怎麼樣。
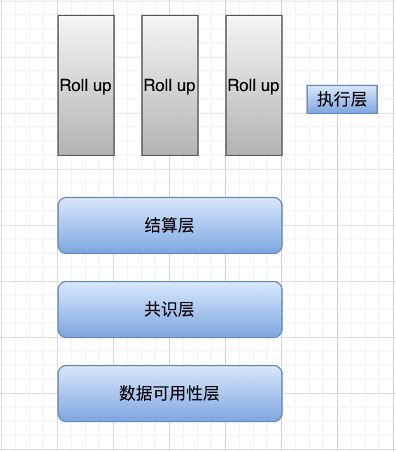
目前以太坊只是將執行層剝離開來,實際上,其它層級仍然混作一談。在 celestia 的願景中,執行層只進行兩件事:對單筆交易而言,執行交易並發生狀態更改;對同批次的交易而言,計算該批次的狀態根。當前以太坊執行層的一部分工作分給了 Rollup ,即我們熟知的 StarkNet 、zkSync 、Arbitrum 和 Optimism 。
現在無論是 optimism、polygon、starknet、zksync 等都往模塊化的道路上探索。
Optimism 提出了 bedrock / op stack,polygon 也在研發 polygon avail 作為數據可用性層,supernets 則用以簡化鏈的創建與共享驗證者集。
結算層:可以理解為主鏈上的 Rollup 合約驗證上文提到的前狀態根、後狀態根、證明的有效性(zkRollup)或欺詐證明(Optimistic Rollup)的過程。
共識層:無論採用 PoW 、PoS 或其他共識算法,總之共識層是為了在分佈式系統中對某件事達成一致,即對狀態轉換的有效性達成共識(前狀態根經過計算轉換成的後狀態根)。在模塊化的語境下,結算層和共識層的含義有些相近,故也有一些研究者把結算層和共識層統一起來。
數據可用性層:確保將交易數據完整上傳到數據可用性層,驗證節點能夠通過該層的數據復現所有狀態變更。
這裡需要辨析的是數據可用性和數據存儲的區別:
數據可用性與數據存儲是明顯不同的,前者關注的是最新區塊發布的數據是否可用,而後者則是涉及安全地存儲數據並保證在需要時可以訪問它。
1、結算層上的各種 Rollup
從結算層看,目前認為 rollup 的焦點在 ZK 系。如果通過 ZK 系的 rollup 來改進 ZK 證明系統的大小、gas 消耗、成本,再結合遞歸和並行處理的話就能夠極大的拓展其 TPS。那麼我們就先從 ZK rollup 開始。
隨著以太坊擴容之路的發展,零知識證明(Zero Knowledge Proof,ZKP)技術被 Vitalik 認為是有望成為擴容之戰的終局的方案。
ZKP 的本質是讓某人證明他們知道或所擁有某些東西。例如,我可以證明我擁有開門的鑰匙,而無須將鑰匙拿出來。證明知道某個賬戶的密碼,而無需輸入密碼並冒著被暴露的風險,這項技術對個人隱私、加密、企業甚至核裁軍都有影響。通過姚氏百萬富翁問題修改版本來加深理解:這個問題討論了兩個百萬富翁愛麗絲和鮑勃,他們想在不透露實際財富的情況下知道他們中的哪一個更富有。
假設公寓每月的租金為 1000 美元,若要符合出租人選的標準,則至少要支付一個月租金的 40 倍。那麼我們(租客)需要證明我們的年收入要有 4 萬美元以上才行。但房主不想我們找到漏洞,因此選擇不公佈具體的租金,他的目的是測試我們是否符合標準,而答案僅僅是符合或者不符合,而不對具體金額負責。
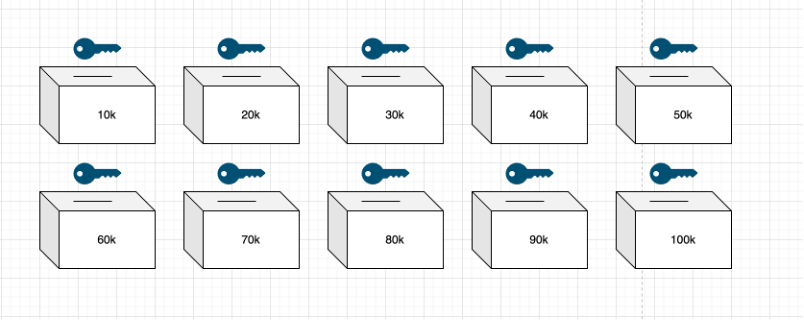
現在有十個盒子,以 1 萬美元為增量,標記為 10~100k 美元。每個都有一個鑰匙和一個插槽。房主帶著盒子走進房間毀掉 9 把鑰匙,拿走標有 40k 美元盒子的鑰匙。
租客年薪達到 7.5 萬美元,銀行代理人監督開具資產證明的文件,不寫明具體資金,這個文件的本質是銀行的資產聲明可驗證索賠文件。隨後我們將該文件投入 10k~70k 的箱子中。那麼房主使用 40k 的鑰匙打開箱子,看到裡面的可驗證索賠文件時,則判定該租客符合標準。
這裡面涉及到的點包括,聲明人(銀行)出具資產達標證明,驗證者(房主)通過鑰匙驗證租客是否具有資格。再次強調,驗證結果只有兩個選擇—— 具有資格和不具有資格,並不會也不能對租客具體資產數額作出要求。
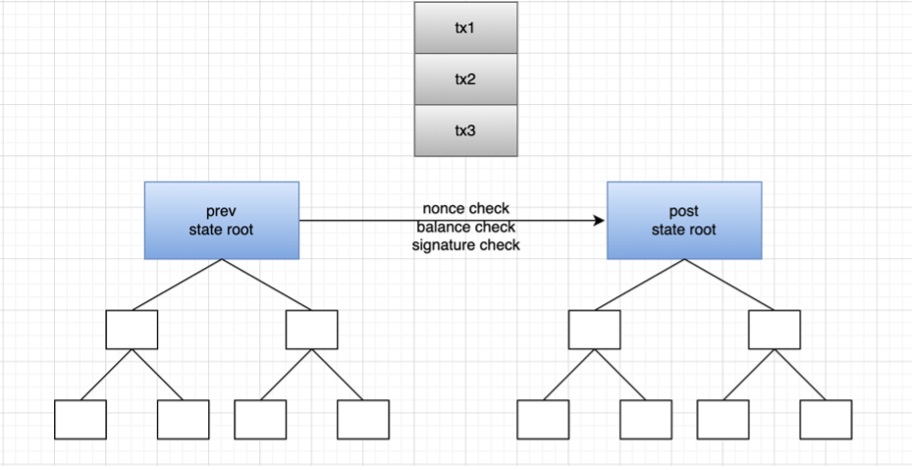
我們仍然可以用下圖作為理解,交易在 layer 2 上執行,在分片提交交易。layer 2 一般採用 rollup 的形式,也就是在 layer 2 上將多筆交易打包成一個批次來處理事務,然後再提交給 layer 1 的 rollup 智能合約。這裡包含新舊狀態根,layer 1 上的合約會驗證兩個狀態根是否匹配,如果匹配那麼主鏈上的舊狀態根就會更換為新狀態根。那如何驗證批次處理後得到的狀態根是正確的呢,這裡就衍生出了 optimistic rollup 和 zk rollup。分別使用欺詐證明和 zk 技術進行交易的確認以及狀態根的驗證。
這裡的 layer 2(rollup)就相當於上文例子中的聲明人(銀行),其打包操作就是這份聲明操作,並不會對具體數額作出聲明,而是確認是否達到標準。打包後提交給 layer 1 的就是這份可索賠的聲明文件。驗證新舊狀態根就是房主通過鑰匙驗證自己期望的租客經濟實力是否達標。狀態根驗證問題就是銀行提交的聲明,該如何進行聲明才能使問題可信。
基於 optimistic 也就是欺詐證明的 rollup 來說,主鏈的 Rollup 合約記錄了該 Rollup 內部狀態根變更的完整記錄,以及每個(觸發狀態根變更的)批次處理的哈希值。如果有人發現某個批次處理對應的新狀態根是錯誤的,他們可以在主鏈上發布一個證明,證明該批次處理生成的新狀態根是錯誤的。合約校驗該證明,如果校驗通過則對該批次處理之後的所有批次處理交易全部回滾。
這裡的驗證方式相當於聲明人(銀行)提交了可驗證資產聲明文件,然後將資產文件全部公開到鏈上,並且數據也要公開到鏈上,其他挑戰者根據原始數據進行計算看可驗證的資產文件是否存在錯誤或偽造的情況,如果有問題,則提出挑戰,挑戰成功則向銀行索賠。這裡最重要的問題就是需要預留時間給挑戰者收集數據並且驗證該份文件的真實性。
對於使用零知識證明(Zero Knowledge Proof,ZKP)技術的 Rollup 來說,其每個批次處理中包含一個稱為 ZK-SNARK 的密碼學證明。銀行通過密碼學證明技術來生成資產聲明文件。這樣就不需要預留時間給挑戰者,從而也就沒有挑戰者這一角色存在了。
2、現在 ZK 系 Rollup 不及預期的原因
目前 polygon 系的 hermez 已經發布,zksync dev 主網、starknet 主網也已經上線。但是他們的交易速度似乎與我們理論上還相差過大,特別是 starknet 的用戶能明顯感知到,其主網速度慢的令人驚訝。究其原因還是在於零知識證明技術生成證明難度仍然很大,成本開銷仍然很高,還有需要對以太坊的兼容性和 zkevm 性能上的權衡。Polygon 團隊也承認:“ Polygon zkEVM 的測試網版本也具有有限的吞吐能力,這意味著它遠不是作為優化擴展機器的最終形式。 ”
3、數據可用性層
以太坊的抽象執行步驟如下所示:
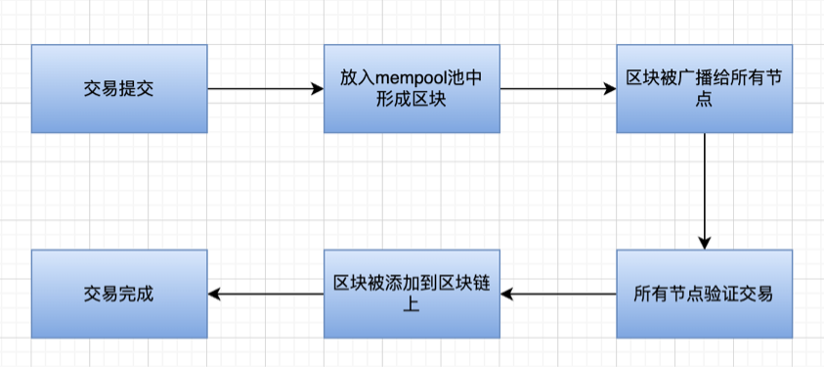
在以太坊的去中心化過程中,我們也可以在 The Merge 路線圖上看到—— 去中心化驗證者。其中最主要的就是實現客戶端的多樣性以及降低機器的入門門檻,增加驗證者的人數。因此有些機器不達標的驗證者想要參與網絡,就可以使用輕客戶端,輕節點的運行原理是通過臨近的全節點索要區塊頭,輕節點只需要下載和驗證區塊頭即可。如果輕節點不參與進來,那麼所有的交易都需要全節點去執行驗證,因此全節點需要下載和驗證區塊中的每筆交易,同時隨著交易量的增多,全節點承壓也越來越大,因此節點網絡逐漸傾向於高性能、中心化。
但是這裡的問題是,惡意的全節點可以給予缺失/ 無效的區塊頭,但是輕節點沒辦法證偽,對此問題有兩種辦法,剛開始是使用欺詐證明,需要一個可信的全節點來監控區塊的有效性,在發現無效區塊後構造一個欺詐證明,在一段時間內未收到欺詐證明則判定為有效區塊頭。但是這裡明顯需要一個可信的全節點,即需要可信設置或者誠實假設。但是區塊生產者能夠隱藏部分交易,欺詐證明就明顯失效,因為誠實的節點,也依賴於區塊生產者的數據,若數據本身就被隱藏,那麼可信節點就認為提交的數據是全部數據,那麼自然也不會生成欺詐證明。
Mustarfa AI-Bassam 和 Vitalik 在合著的論文中提出了新的解決方案—— 糾刪碼。採用糾刪碼來解決數據可用性的問題,比如 celestia,polygon avail 均採用的是 reed-solomon 糾刪碼。但是如何確保傳輸的數據是完整的數據呢,結合 KZG 承諾/ 欺詐證明即可。
在 KZG 承諾/ 欺詐證明中,能夠確保區塊生產者發布完整的數據,不會隱藏交易,然後將數據通過糾刪碼進行編碼,再通過數據可用性採樣,這樣就可以讓輕節點正確地驗證數據。
Rollup 內聚合器提交的數據都是以 calldata 形式存儲在鏈上的,這是因為 calldata 數據相對於其它存儲區域更便宜。
Calldata cost in gas = Transaction size × 16 gas per byte
每筆交易主要的開銷在 calldata 成本,因為在鏈上存儲費用極其昂貴,該部分占到 rollup 成本的 80%~95% 之多。
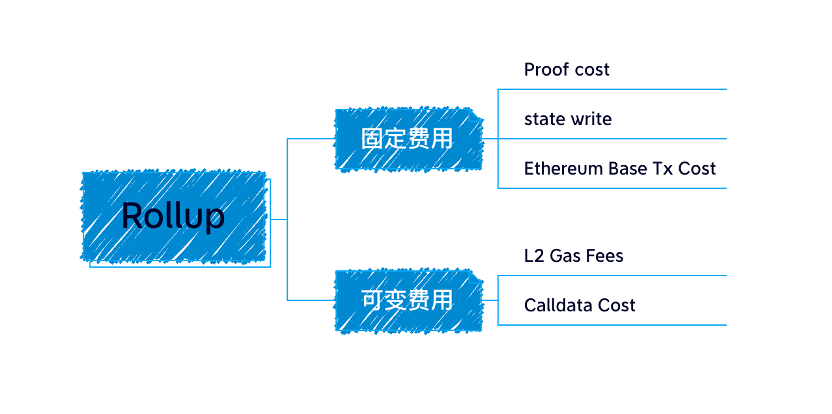
由於這個問題,我們才提出了 EIP-4844 的新交易格式 blob,擴大區塊容量,降低提交到鏈上所需的 gas 費。
4、數據可用性層的鏈上與鏈下
那麼如何解決鏈上數據昂貴的問題呢?有以下幾種方法:
- 首先是壓縮上傳到 L1 的 calldata 數據大小,這方面已經有了許多的優化。
- 其次是降低在鏈上存放數據的成本,通過以太坊的 proto-danksharding 和 danksharding 來為 rollup 提供 “大區塊”,更大的數據可用性空間,採用糾刪碼和 KZG 承諾來解決輕節點的問題。如 EIP-4844。
- 第三個是,把數據可用性放在鏈下,這部分的通用方案包括,celestia / polygon avail 等。
通過數據可用性存放的位置,我們將其分為下圖所示:
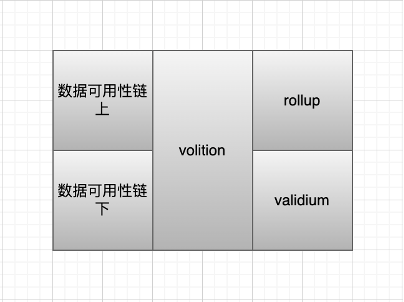
Validium 的方案:將數據可用性放在鏈下,那麼這些交易數據就由中心化的運營商來維護,用戶就需要可信設置,但成本會很低,但同時安全性幾乎沒有。之後 starkex 和 arbitrum nova 都提出成立 DAC 來負責交易數據的存儲。DAC 成員都是知名且在法律管轄區內的個人或組織,信任假設是他們不會串通和作惡。
Zkporter 提出 guardians(zksync token 持有者)來質押維護數據可用性,如果發生了數據可用性故障,那麼質押的資金將被罰沒。Volition 則是用戶自己選擇鏈上/ 鏈下數據可用性,根據需求,在安全與成本之間選擇。
這時候,celestia 和 polygon avail 就出現了。如果 validium 有鏈下數據可用性的需求,又害怕去中心化程度低,從而引發類似跨鏈橋的私鑰攻擊,那麼去中心化的通用 DA 方案則可以解決這個問題。Celestia 和 polygon avail 通過成為一條單獨的鏈,來為 validium 提供鏈下 DA 的解決方案。但是通過單獨的鏈,雖然提升的安全性,但相應會提高成本。
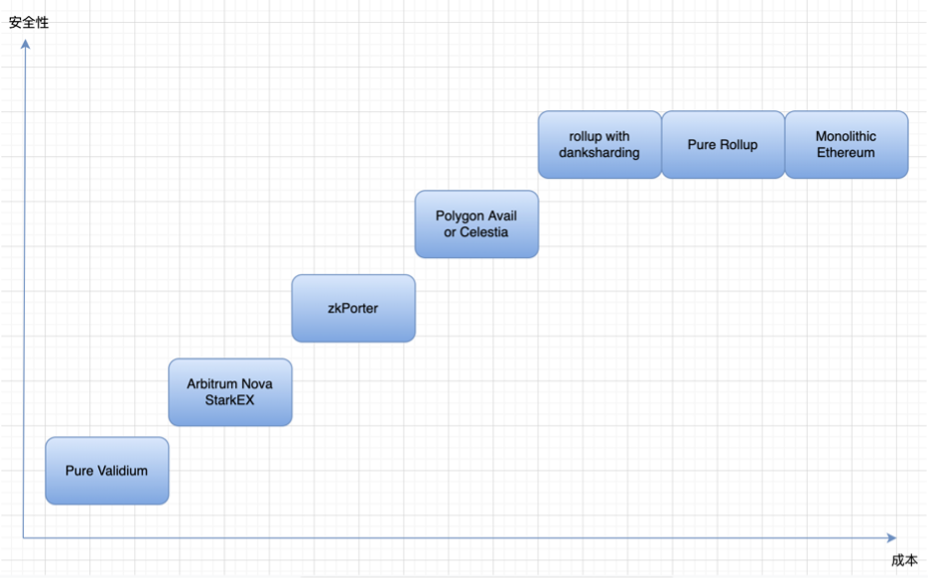
Rollup 的拓展實際上有兩部分,一部分是聚合器的執行速度,另一方面則需要數據可用層的配合,目前聚合器是中心化的服務器來運行,假設交易執行的速度能達到無限大的程度,那麼主要拓展困境在於其受到底層數據可用性解決方案的數據吞吐量的影響。如果 rollup 要最大化其交易吞吐量,則如何最大化數據可用性解決方案的數據空間吞吐量是至關重要的。
再回到開頭,使用 KZG 承諾或者欺詐證明來確保數據的完整性,通過糾刪碼來拓展交易數據幫助輕節點進行數據可用性採樣,進一步確保輕節點能夠正確驗證數據。
也許你也想問,到底 KZG 承諾是如何運行來確保其數據的完整性的呢?或許可以稍微解答一下:
- KZG 承諾:證明多項式在特定位置的值與指定的數值一致。
- KZG 承諾無非就是多項式承諾中的一種,能夠在不給定具體消息的情況下驗證消息。大概流程如下:
- 將數據通過糾刪碼化為多項式,將其拓展。使用 KZG 承諾確保我們的拓展是有效的,且原數據是有效的。然後利用拓展可以 reconstruct 數據,最後進行數據可用性採樣。
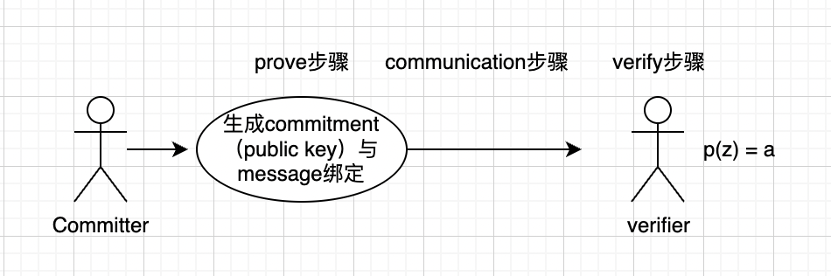
- 提交者(commiter)生成承諾(commitment),將其與消息綁定。
- 將綁定後的消息傳送給驗證者,這裡的 communication 方案就關係到證明規模(proof size)的大小。
- 驗證者(verifier),帶入有限域的多個值驗證是否仍然等於 a(這就是可用性採樣的過程),基本原理就是驗證次數越多那麼正確的概率就越高。
Celestia 要求驗證者下載整個區塊,現在的 danksharding 則利用數據可用性採樣技術。
由於區塊存在部分可用的情況,因此任何時候我們都需要在重構區塊的時候保證同步。在區塊確實部分可用時,節點之間通信,將區塊拼湊出來。
KZG 承諾和數據欺詐證明的比較:
可以看到 KZG 承諾能確保拓展和數據是正確的,而欺詐證明引入第三方進行觀察。最明顯的區別是,欺詐證明需要一個時間間隔來給觀察者進行反應,然後再報告欺詐,這時候需要滿足節點直接的同步,從而整個網絡能夠及時收到欺詐證明。KZG 則明顯的比欺詐證明更快,其使用數學方法來確保數據的正確,而不需要一個等待時間。
它能夠證明數據以及其拓展是正確的。但是由於一維 KZG 承諾需要耗費更大的資源,因此以太坊選擇二維 KZG 承諾。
比如 100 行× 100 列,那就是 100,00 個份額(shares)。但每採樣一次,都不是萬分之一的保證。那麼擴展四倍意味著在整個份額中至少要有 1/4 的份額不可用,你才可能抽到一個不可用的份額, 才表示真正不可用,因為恢復不出來。只有在 1/4 不可用的情況下才恢復不出來,才是真正有效的發現錯誤,所以抽一次的概率大概是 1/4。抽十多次,十五次,可以達到 99% 的可靠性保證。現在在 15–20 次的範圍之內做選擇。
5、EIP-4844(Proto-Danksharding)
在 proto-danksharding 實現中,所有驗證者和用戶仍然必須直接驗證完整數據的可用性。
Proto-danksharding 引入的主要特徵是新的交易類型,我們稱之為攜帶 blob 的交易。攜帶 blob 的事務類似於常規事務,不同之處在於它還攜帶一個稱為 blob 的額外數據。Blob 非常大(~125 kB),並且比類似數量的調用數據便宜得多。但是,這些 blob 無法從 EVM 訪問(只有對 blob 的承諾)。並且 blob 由共識層(信標鏈)而不是執行層存儲。這裡其實就是數據分片概念逐漸成型的開始。
因為驗證者和客戶端仍然需要下載完整的 blob 內容,所以 proto-danksharding 中的數據帶寬目標為每個插槽 1 MB,而不是完整的 16 MB。然而,由於這些數據沒有與現有以太坊交易的 gas 使用量競爭,因此仍然有很大的可擴展性收益。
儘管實現全分片(使用數據可用性採樣等)是一項複雜的任務,並且在 proto-danksharding 之後仍然是一項複雜的任務,但這種複雜性包含在共識層中。一旦 proto-danksharding 推出,執行層客戶端團隊、rollup 開發人員和用戶不需要做進一步的工作來完成向全分片的過渡。Proto-danksharding 還將 blob 數據與 calldata 分離,使客戶端更容易在更短的時間內存儲 blob 數據。
值得注意的是,所有工作都是由共識層更改,不需要執行客戶端團隊、用戶或 Rollup 開發人員的任何額外工作。
EIP-4488 和 proto-danksharding 都導致每個插槽(12 秒)的長期最大使用量約為 1 MB。這相當於每年大約 2.5 TB,遠高於以太坊今天所需的增長率。
在 EIP-4488 的情況下,解決此問題需要歷史記錄到期提案 EIP-4444 (路線圖部分有提及),其中不再要求客戶端存儲超過某個時間段的歷史記錄。
6、數據分片
在這裡,將盡可能多的以小白的視角講清楚以太坊擴容過程中大家都在討論的問題。所以我們回到分片,再次強調一下對於分片的片面概念:簡單理解就是水平分割數據庫以分散負載的過程。
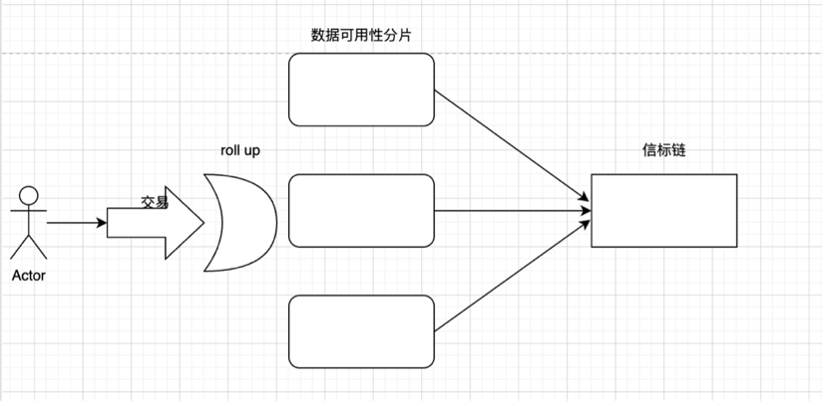
在這裡,我們的數據分片有一個很重要的問題就是,在 PBS 中(提議者與區塊構建者分離,路線圖 The Merge 處有提及),在分片中,每個節點群只處理該分片內的交易,交易在分片間會相對獨立,那麼 AB 兩用戶處於不同分片上,相互轉賬該如何處理呢?那這裡就需要很好的跨片通信的能力。
過去的方式是數據可用性層分片,每個分片都有獨立的提議者(proposers)和委員會(committee)。在驗證者集中,每個驗證者輪流驗證分片的數據,他們將數據全部下載下來進行驗證。
缺點是:
- 需要嚴密的同步技術來保證驗證者之間能夠在一個 slot 內同步。
- 驗證者需要收集所有的 committee 的投票,這裡也會出現延遲。
- 而且驗證者完全下載數據對其壓力也很大。
第二種方法是放棄完全的數據驗證,而是採用數據可用性採樣的方法(該方法在 The Surge 後期實現)。這裡又分為兩種隨機採樣方式,1)區塊隨機採樣,對部分數據分片採樣,如果驗證通過後,驗證者進行簽名。但是這裡的問題是,可能會出現遺漏交易的情況。2)通過糾刪碼將數據重新解釋為多項式,再利用特定條件下多項式能夠恢復數據的特點,來確保數據的完整可用性。
“分片" 關鍵就是驗證者不負責下載所有數據,而這就是為什麼 Proto-danksharding 不被認為是"分片的" 的原因(儘管它的名字裡有"分片 sharding")。Proto-danksharding 要求每個驗證者完整地下載所有分片 blob 來驗證它們的可用性;Danksharding 則隨後將引入採樣,單個驗證者只需下載分片 blob 的片段。
三、以太坊的未來之 Layer 3
被視為以太坊拓展未來的 ZK 系 Layer 2 如 zksync、starknet 都紛紛提出了 Layer 3 的概念。簡單理解就是 Layer 2 的 Layer 2。

以太坊上高昂的交易成本正在推動它(L3)成為 L2 的結算層。相信在不久的將來,由於交易成本顯著降低、對 DeFi 工具的支持不斷增加以及 L2 提供的流動性增加,最終用戶將在 L2 上進行大部分活動,而以太坊逐漸成為結算層。
L2 通過降低每筆交易的 gas 成本和提高交易率來提高可擴展性。同時,L2s 保留了去中心化、通用邏輯和可組合性的好處。但是,某些應用程序需要特定的定制,這可能更好地由一個新的獨立層提供服務:L3!
L3 與 L2 相關,就像 L2 與 L1 相關一樣。只要 L2 能夠支持驗證者(Verifier)智能合約,L3 就可以使用有效性證明來實現。當 L2 也使用提交給 L1 的有效性證明時,就像 StarkNet 所做的那樣,這將成為一個非常優雅的遞歸結構,其中 L2 證明的壓縮優勢乘以 L3 證明的壓縮優勢。理論上說,如果每一層都實現了例如 1000 倍的成本降低,那麼 L3 可以比 L1 降低 1,000,000 倍—— 同時仍然保持 L1 的安全性。這也是 starknet 引以為豪的遞歸證明的真實用例。
這裡需要用到《數據可用性層的鏈上與鏈下》部分知識。整個 Layer 3 包括了:
Rollup(鏈上數據可用性),validium(鏈下數據可用性)。兩種分別對應不同的應用需求。對價格、數據敏感的 web2 企業可以使用 validium,將數據放在鏈下,這樣極大的降低了鏈上 gas 費用,並且可以不公開用戶數據實現隱私性,讓企業完成自己對數據的掌控力,使用自定義的數據格式,以前企業的數據商業模式仍然能夠跑通。
- L2 用於擴展,L3 用於定制功能,例如隱私。在這個願景中,沒有嘗試提供 “二次方級可擴展性”;相反,這個堆棧中有一層可以幫助應用程序擴展,然後根據不同用例的定制功能需求分離各層。
- L2 用於通用擴展,L3 用於自定義擴展。自定義擴展可能有不同的形式:使用除 EVM 之外的其他東西進行計算的專用應用程序,其數據壓縮針對特定應用程序的數據格式進行優化的 rollup(包括將 “數據” 與 “證明” 分開,並用每個區塊的單個 SNARK 完全替換證明)等。
- L2 用於無信任擴展(rollup),L3 用於弱信任擴展(validium)。Validium 是使用 SNARK 來驗證計算的系統,但將數據可用性留給受信任的第三方或委員會。在我看來,Validium 被嚴重低估了:特別是,許多 “企業區塊鏈” 應用程序實際上可能最好由運行 validium 證明者並定期將哈希提交到鏈的中心化服務器來提供最佳服務。Validium 的安全等級低於 rollup,但可以便宜得多。
對於 dApp 的開發者來說,在基礎設施上可以有以下幾種選擇:
- 自己開發一個 Rollup(ZK Rollups 或者 Optimistic Rollups)優勢是你可以繼承以太坊的生態(用戶),還有它的安全性,但是對於一個 dApp 團隊來說,Rollup 的開發費用顯然過高。
- 選擇 Cosmos、Polkadot 或者是 Avalanche 開發的費用會更低(例如 dydx 就選擇了 Cosmos),但是你將失去以太坊的生態(用戶),以及安全性。
- 自己開發一個 Layer 1 區塊鏈帶來的開發費用和難度很高,但是卻能擁有最高的控制權。
我們對比一下三種情況:
難度/費用:Alt-layer 1 > Rollup > Cosmos
安全性:Rollup > Cosmos > Alt-layer 1
生態/用戶:Rollup > Cosmos > Alt-layer 1
控制權: Alt-layer 1 > Cosmos > Rollup
作為一個 dApp 的開發者,如果想繼承以太坊上的安全性和流量,那就不能重新開發一條鏈,那隻能選擇 rollup 。但是自己開發一個 layer 2 rollup 又非常貴,那麼合適的解決方案就變成了利用 layer 3 SDK 開發一個自己的應用專用的 Rollup(application-specific rollup),即 Layer 3。
四、Layer 2 的未來發展
由於以太坊是基於賬戶模型設計的,所有的用戶均處在一整個狀態樹內,因此無法進行並行,因此以太坊本身的桎梏就讓其需要剝離執行操作,將 rollup 的多筆交易合成為一筆交易,作為結算層的存在。現在所有的問題就集中在 layer 2 的吞吐量的提升上。不僅僅是用 Layer 3 可以提高交易的吞吐量,還有在 Layer 2 上實行並行處理,也可以極大提高整個網絡的吞吐量。
並行化問題 starknet 也在積極探索,雖然目前證明算法仍然是桎梏,但是預計未來將不會成為阻力。潛在的瓶頸包括:
- 排序器 tx 處理:一些排序器的工作似乎天生就是串行的。
- 帶寬:多個排序器之間的互連將受到限制。
- L2 狀態大小
在 starknet 社區中,成員也提出了 aptos 的並行處理方式非常不錯。就 Starknet 而言,目前也在推進排序器內部 tx 並行排序的能力。
五、總結
以太坊正在將執行層剝離,所有的行為都朝著其 “全球” 結算層願景的方向前進。目前整個以太坊雖然進度緩慢,也就是由於其整體過於龐大,每次更新都牽扯了許多利益與權衡。但不可否認的是,以太坊正在經歷重大變革,以太坊大量的鏈上活動、經濟機制改進以及以太坊 2.0 可擴展性,其引領的創新 ICO、Defi、NFT 等很多東西值得以太坊社區興奮與期待。相信伴隨著越來越多國家部署以太坊的節點,比如阿根廷首都政府計劃在 2023 年部署以太坊驗證節點,在不久的將來,以太坊真的能夠實現其宏偉願景。
免責聲明:作為區塊鏈信息平台,本站所發布文章僅代表作者及嘉賓個人觀點,與 Web3Caff 立場無關。文章內的信息僅供參考,均不構成任何投資建議及要約,並請您遵守所在國家或地區的相關法律法規。