索引協議和 Keeper 網絡是 Web3 DApp 開發架構中的重要中間件. 但現有的協議都具有安全性差、性能不足、機制複雜等特點. 而零知識證明技術的蓬勃發展能讓這些上一代的協議被賦予新技術所帶來的安全性與性能飛躍。
作者: msfew@foresightventures
原用標題: Foresight Ventures: Crypto-Native 索引協議與 Keeper 網絡
中間件安全性問題
現有的 Indexing 協議和 Keeper 網絡都不是完全 trustless 的, 而是 trusted, 或者看似 trustless 的. 開發者和用戶需要以 “Trust, Not Verify” 的方式來信任這些產品不會作惡.
它們都是上一代的基礎設施, 在當時可能確實沒有太好的解決方案, 所以用了 Fisherman 機製或者 DAO 治理 (Social Consensus…), 來保證數據的可信和協議的安全運行.
在當前, 各個 zk 方案已經進入性能優化的收尾階段, 這些前朝的劍, 就不能再來斬本朝的官了. 通過 zk, 可以實現 Web3 中間件的所有革新, 確保安全性, 去中心化, 和性能被同時滿足, 就如同 Optimistic Rollup 在未來很可能會被 zk Rollup 搶走 Layer2 的主導地位一樣.
Web3 Indexing
a) Web3 索引
我們首先需要了解為什麼需要 Web3 特製的索引協議:
- Web3 是地址模型, 智能合約數據以交易形式存在, 需要索引來讓數據結構更加易用; Web2 的數據結構開發者自己處理.
- Web3 的很多數據都是交易相關數據; Web2 被索引的數據很大一部分都是搜索引擎索引的網頁或者圖片等數據.
- Web3 需要通用索引協議來發揮可組合性; Web2 開發者自己根據自己的中心化應用搭建索引服務.
對於這幾點, 如果你在 DApp 的開發中, 硬是要自己來進行索引, 那麼每當去提取合約中的特定數據, 需要非常大的前端代碼量, 以下是一個例子, 真的要建立一套服務的話需要無數個不同的函數:

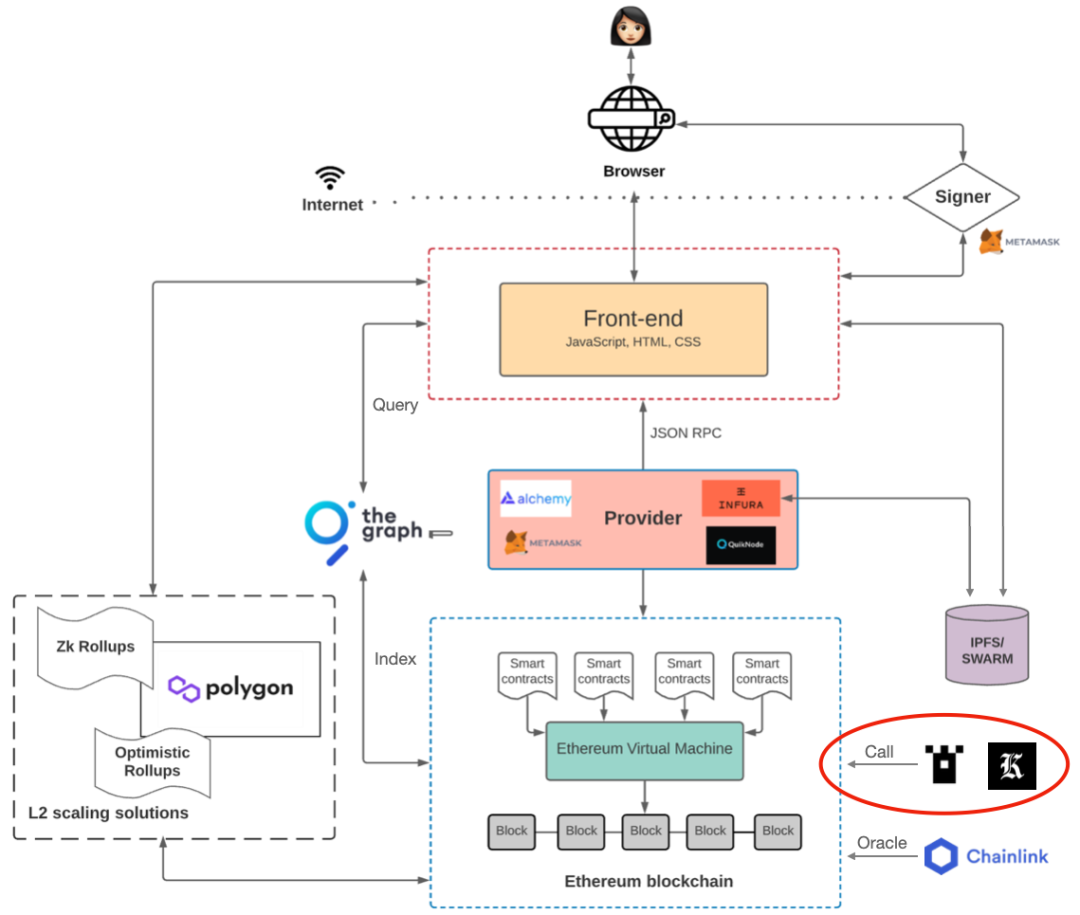
於是在我們之前的 DApp 架構圖中, 前端要使用和獲取智能合約的數據時, 就必備一個通用的 Indexing 協議作為中間層, 來讓智能合約的數據能被前端所輕鬆使用.
b) GraphQL 索引
我們需要一個 Indexing 協議作為中間層, 那麼這個協議該如何選型呢 (The Graph 19 年有講過 Web3 為什麼要用 GraphQL, 但是感覺說得不太清楚)? 我們有四個潛在選擇.
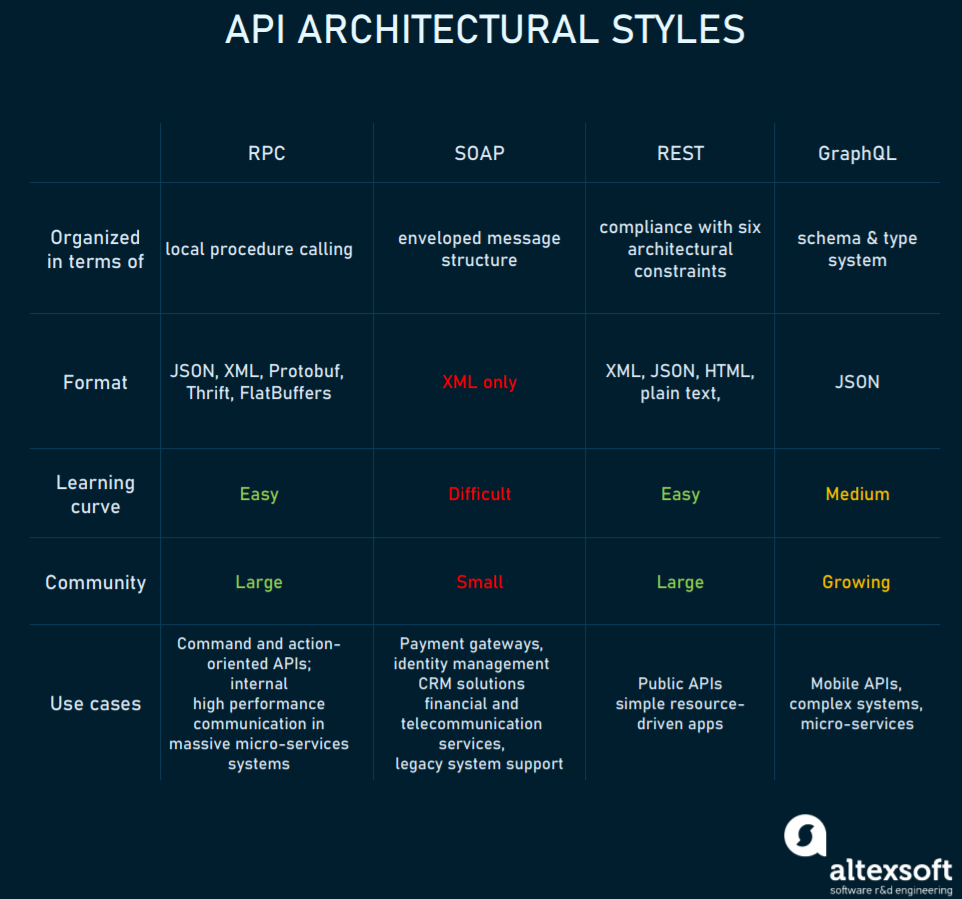
首先, 排除 SOAP. 因為它的採用率非常少, 學習曲線也非常陡峭. 甚至有人說 “REST is king, and SOAP is trash”.
其次, 排除 RPC. RPC 是客戶端對區塊鏈, 或者 Web2 服務與服務之間的常用調用規範, 以操作 (動詞) 為核心, 接口的更新更加麻煩一些, 適合客戶端與區塊鍊網絡的通信. 但對於我們的智能合約開發場景來說, 太重, 不是最適合, 性能也因為請求數量多, 和需要依賴正在運行的程序, 而導致不太好.
接著, 排除 REST. REST 風格算是以資源 (名詞) 為核心來操作的規範. 但是 Web3 應用中, 對任何資源進行更新操作的動作都需要用戶或者其他方授權觸發, 我們在索引協議中的請求全部是 GET 請求, 那就沒必要 REST 了.
最後, 選擇了 GraphQL:
- GraphQL 協議本身的構建工作量相比其他標準更小, 更不需要變化, 更容易搭建通用的協議.
- GraphQL 的交互形式給了前端更多的自由度, 由前端定義結果, 符合 DApp 結構中的無後端思想.
- GraphQL 非常適合區塊鏈中完全開放且不易變, 同時有非常多樹狀結構數據的智能合約場景, 性能上也會因此更好.
- GraphQL 在區塊鏈中已經有 The Graph 針對單個智能合約的索引制定了成熟標準, 也早就有對整條鏈的 GraphQL 接口 (ethql, Clear), 成熟度高, 開發者生態也被培養得很好.
除此之外, 我並不認為我們需要花非常多的時間去開發新的存儲網絡的 GraphQL 協議和 Query 協議 (當然這些索引的聚合是有意義的):
- 存儲網絡大多都自帶可用的索引協議, 如 Arweave 的 GraphQL 服務, 開發新的協議是在重複造輪子.
- 存儲網絡上的數據相對於合約數據或者 Web2 數據量都非常小, 同時所承載的價值也相對來說更小.
- Web2 已經有更加成熟的協議和方案來進行這些數據的索引, 開發新的協議依然類似是重複造輪子.
當我們討論索引協議的時候, 默認的都是從前端直接獲取區塊鏈智能合約的數據, 這是因為我們在前文中就闡述過, 消除後端服務器對 Web3 Crypto-native 可信 DApp 的意義.
硬要加上針對智能合約鏈的後端的話反而徒增架構複雜度和暴露更多的不可信因素 (目前有 zk-sql 等項目在專注於相關問題, 但無法完全解決; 也有 Sqlidity 這樣有趣的鏈上 SQLite 方案), 當然對於基於存儲協議的 DApp 來說, SQL 化的語句對開發熟悉度和流程來說是有必要的.
索引協議需要關注的結構應該是前端能直接使用的 GraphQL 結構.

c) 現有 Web3 GraphQL 索引協議問題
現有的 Indexing Protocol 的龍頭必然是去中心化的 The Graph 和 Pocket Network 和中心化的 Alchemy. 無論是中心化還是去中心化, 它們都各有各的問題:
- 中心化 Indexing Protocol 問題:
- 無法抗審查
- 無法保證服務高可用性
- 現有去中心化 Indexing Protocol 問題:
- 信任模型和安全性依舊差 (攻擊 Subgraph 的成本非常低, 機制和 Chainlink 2.0 一樣, 是靠 “更可信” 的 Fisherman 來舉報)
- 性能無法滿足需求
對於安全性的問題, Fisherman 機制在 Optimistic Rollup 中的體現與 Indexing Protocol 所不同, Optimistic Rollup 的數據是鏈上的, 更大的群體可以通過執行輕鬆驗證, 而 Indexing 的過程是鏈下的, 如果並非 Subgraph 的 indexer 的話, 很難去對錯誤數據進行挑戰. 這就導致信任模型更不穩固.
這幾個缺陷結合在一起, 就導致了大的 DeFi 應用因為性能和安全性而很少使用這些索引協議, 這個市場有著巨大的空缺.
d) ZK 解決智能合約索引協議問題
ZK 其實是個非常好的解決方案, 任何的 Optimistic 機制的問題都可以通過轉為 ZK 來解決, 比如 Rollup 這個最顯著的領域.
ZK 化之後的索引協議兼具了中心化和去中心化協議的所有優點, 包括高可用性和抗審查 (多個節點保證 uptime), 性能極佳 (因為 ZK 的存在所以可以選用中心化高性能節點), 安全性 (ZK 的數學密碼學很好地保證安全性)
對於一個索引協議來說, ZK 的方案:
- 不需要 EVM 兼容性.
- 注重整體性能, 需要保證 Verifiable Query 的速率.
The Graph 自己也意識到了自己的機制安全性的不足, 正在琢磨 Shellproof.
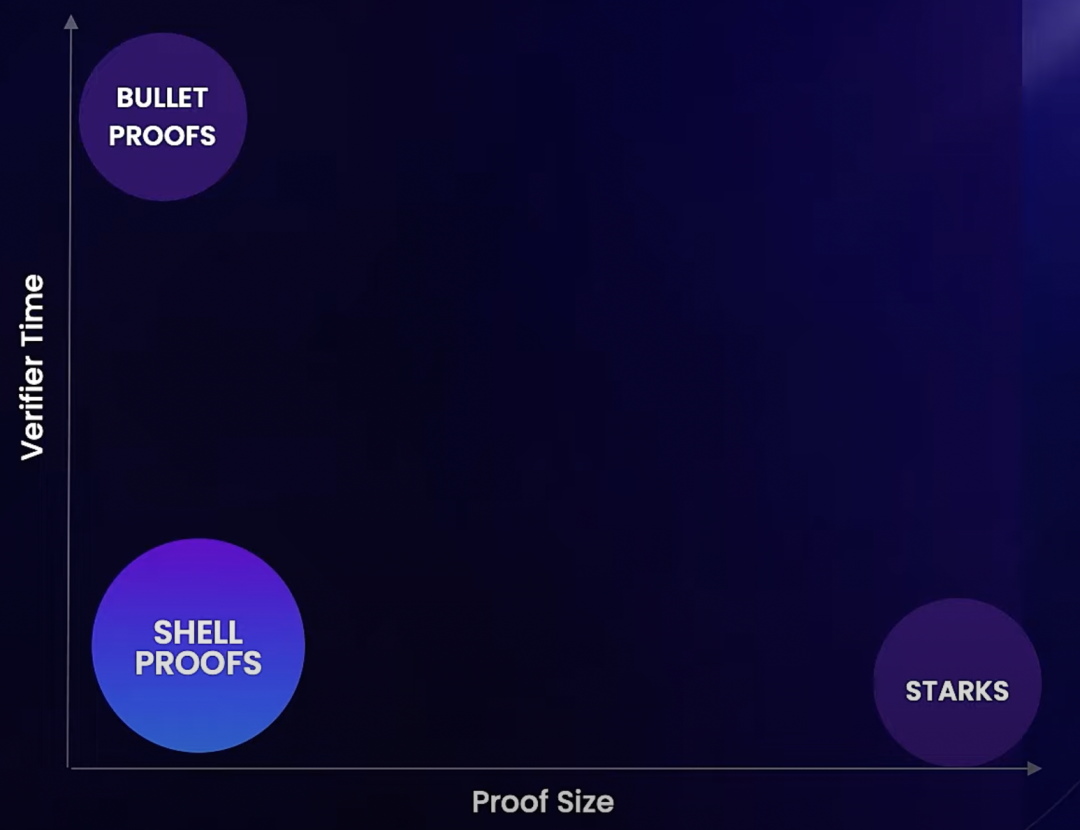
但是我認為 The Graph 目前的研究和開發進度還是慢, 不知道 Shellproofs 是否能支持全部 subgraph 的運行. 而且 The Graph 已經在現有的機制上花了這麼多功夫, 去替換這個機制的難度甚至比重新建立一套還要高.
一個真正實現了 zk 化的 The Graph 的應用可以構建出新的應用與開發範式:
- 任何 DeFi 應用都可以信任這個索引協議的數據, 大大簡化了開發流程.
- 多鏈應用可以同時可信使用多鍊和多協議的數據, 用戶體驗上會得到巨大提升 (+ Standardized Subgraph).
通過這樣的思路, 我們可以理解 zk 化的 The Graph 實際上是一個去中心化 RPC, 這遠比 The Graph 的敘事宏大, 而是真正能實現 Infura 所在追求的去中心化.
Web3 Keeper Network
在之前 Crypto-Native 應用架構的文章中, 我們提到過 Keeper.
它本質上就是, 一個鏈下定時器到了特定時間就觸發智能合約的某個功能, 類似:
- Linux 裡的 CronJob
- Web API (不是 JS) 裡的 setTimeout 和 setInterval
它的用處具體包括:
- 鏈上預言機價格更新 (之前提到的 Uniswap V2 TWAP)
- 交易, 投票, 清算機器人
- 自動化挖提賣
然而, 和我們之前提到的 The Graph 類似, 它的安全性機制是很落後的, 甚至還不是 The Graph 這樣的鏈上治理, 而是鏈下通過 DAO 和 Social Consensus 的舉報機制人工檢舉揭發非法節點. 比如下圖中, Gelato 的架構圖, 整體功能很清晰, 但每個組件都沒有體現出有任何安全性的保證.

以兩個典型的 Keeper Network 為例, 它們的安全性機制是:
- Gelato: 目前的 Keeper 服務執行節點不是 Permissionless 的, 而是在白名單上的節點才可以參與. Gelato 預計在未來去中心化之後, 通過 Stake and Slash 機制和 DAO 來保證網絡安全性. 但是去通過 DAO 來懲罰一個非法節點需要一周, 這樣緩慢的決策對一個需要高頻運轉的服務來說, 我認為是完全沒法接受的.
- Keep3r Network: 和 Gelato 類似, 也是 Watcher 監督, 發現非法行為則舉報給 DAO. 但機制闡述得更加詳細, 雖然依舊是很差的機制, 需要大量的人工交流和漫長的步驟.
就像我們剛才提到的 Indexing 協議一樣, Keeper 也完全可以通過 zk 化來解決安全性的問題, 同時甚至可以 Gelato 的 off-chain resolver 也是用 GraphQL 定義的一個 subgraph, 但和 The Graph 沒有安全性保證. 這兩個問題就可以被一起解決了.
這樣一個帶可信 off-chain resolver 的 zk 化 Keeper 可以解鎖無數新的應用場景:
- 複雜策略的交易機器人
- 跨 Cluster/跨鏈/跨區塊/跨 DEX 的套利/做市機器人
- Programmable Liquidity (調整區間, JIT, 复投, Rebalance)
Crypto-Native ZK Infra
在 zkEVM 和通用 zkVM 的最底層 infra 成熟的過程中, 我們已經可以嘗試去基於和使用它們來建立開發者可以直接使用的 infra, 包括我們構想中的這些 zk 化中間件.
ZK 作為一個典型方案, 是像 AMM 一樣的創新驅動重要因素. ZK 和 AMM 分別解鎖了比 Optimistic 和 Order Book 機制更自動化和更可信的應用運轉, 讓安全性在鏈上完全透明公開可驗證, 同時也分別解鎖了證明外包和 Swap 聚合器的額外賽道, 解鎖了無數新的應用.
除了擴容/跨鏈輕節點/隱私/機器學習以外, ZK 作為完全適合區塊鏈場景 (網絡全體做驗證, 極其自動化, 甚至比網絡共識更強的安全性) 的密碼學方案, 在 Indexing 協議與 Keeper 網絡這些中間件賽道中也大有可為. 我們也將持續關注 ZK 在更多領域中的應用.
免責聲明:作為區塊鏈信息平台,本站所發布文章僅代表作者及嘉賓個人觀點,與 Web3Caff 立場無關。文章內的信息僅供參考,均不構成任何投資建議及要約,並請您遵守所在國家或地區的相關法律法規。