為什麼 Web 3 驅動的分佈式存儲能保護數據隱私,是元宇宙時代的基礎設施?
作者: Rosie(TG:rororoxu)
原用標題: A&T 前瞻:為什麼 Web3 驅動的分佈式存儲是元宇宙時代的基礎設施?
封面: Photo by GuerrillaBuzz Blockchain PR Agency on Unsplash
目錄
- Introduction
- 中心化元宇宙數據存儲現狀
- Web 3 驅動的分佈式數據存儲網絡發展現狀
- 分佈式存儲網絡創業公司 Mapping
- 總結
Introduction
在上一篇 《A&T 前瞻: 為什麼 Web 3 驅動的分佈式算力網絡是元宇宙的基礎設施?》裡,我們通過收集市場數據和設立假設,論證了為什麼 Web3 驅動的分佈式計算是元宇宙時代的基建。在本篇文章裡,我們將一起探索在元宇宙時代爆發時,對現在的存儲和傳輸會有什麼樣的挑戰,以及 Web3 驅動的存儲和傳輸為什麼能支撐元宇宙時代的數據量,成為元宇宙時代的基礎設施。
中心化元宇宙數據存儲現狀
數據存儲,按照存儲時長分為兩類:
- Memory - 內存存儲內存裡存的數據在計算機關機後將消失,存儲在這裡的數據是為了加快數據讀取速度,或者是為了加快某個計算而暫時性地進行存儲。
- Storage - 硬盤存儲存在硬盤存儲裡的數據不會在計算機關機後消失,會在用戶沒有直接或間接進行刪除操作的情況下永遠存儲在硬盤裡。當用戶進行了存儲命令操作,一個文件(包括圖片、視頻等)會從內存裡複製到硬盤裡進行存儲。
不管是什麼數據類型(音頻、圖像、視頻等),存在存儲介質裡的都是一串 0 和 1 的數字。在上一篇文章裡提到,元宇宙裡的沉浸感是由每一幀高清且渲染好的圖片通過一個類人眼的顯示屏幕展示出來的。在元宇宙裡,兩個最多的數據類型是音頻流和視頻流。
現在是怎麼做的?
不管是視頻流還是音頻流,可以分為兩大類型:
- 不需要被處理的數據,這類型數據包括背景音樂、一個場景裡的背景某些背景模型等。這類型數據通常被存在本地(也就是設備裡),需要的時候就可以播出/展示。
- 需要被實時處理的數據,這類型數據包括語音、用戶與其他用戶互動產生的聲音、用戶站在不同角度看場景裡某個物品。這類型數據需要被處理,如果不是在本地進行處理,則需要在雲端或服務器邊進行處理並且壓縮,然後再傳輸到客戶端邊。

這些被實時處理後傳輸回來的音頻和視頻數據可以與本地數據進行疊加,給用戶創造最貼近 “以假亂真” 的沉浸感。
現在有什麼痛點?
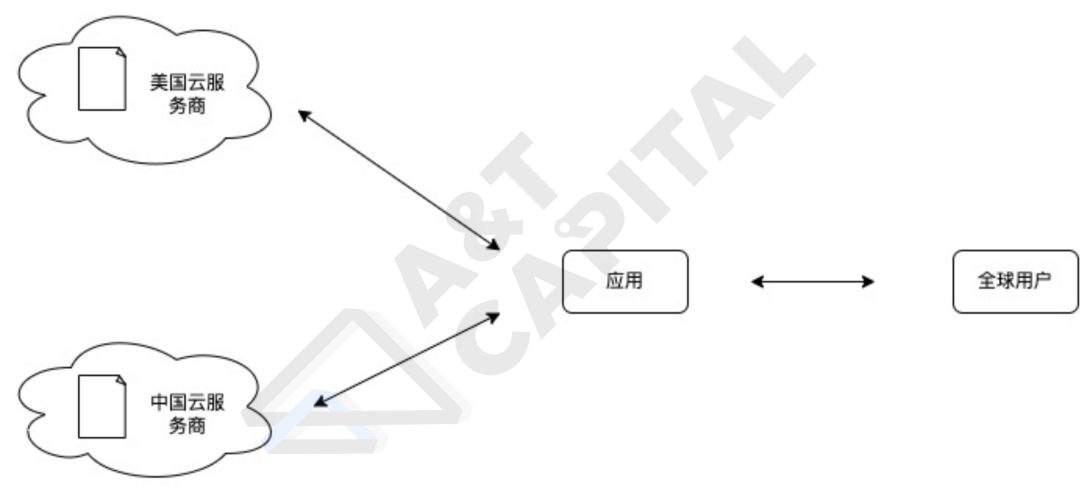
如上圖所示,在服務全球用戶的時候,同一份數據會被複製到不同的地域的雲服務器上,方便就近用戶調取文檔。雖然雲服務看似已經有了巨頭公司(eg AWS、Azure),但這些雲廠商在不同地區的滲透率其實差別很大。例如,AWS 在中國的業務滲透率就沒有阿里雲、騰訊雲高。因此,應用在開發時會有以下幾個痛點(假設架構已經是基於雲服務,如果不是,則會有更多的痛點):
- 單云開發無法滿足全球用戶需求前面提到,AWS 在中國的業務滲透率沒有阿里雲、騰訊雲高。拋開商業和政策角度,國內云廠商在國內設立的數據中心更多、容量更大,能更好的服務國內的用戶。這一現像也同樣在世界的其他地方發生,因此,在相當一部分的世界裡,當地的雲廠商在數據中心數量上比起我們知道的雲巨頭更多,能更好的滿足服務當地用戶的需求。這一現像給應用開發者帶來的難題是,為了更好的服務在不同地區的用戶,他們需要將自己的自己的應用需要存儲的數據放在當地的雲服務廠商的數據中心裡,也就是說,他們需要使用多雲的存儲架構來支持服務全球用戶調取數據的需求。
- 多雲開發複雜且運維成本高根據上述點一的原因,要滿足快速響應全球用戶的需求,應用開發者很可能需要使用多雲開發的策略。但是,使用多雲開發策略是一件複雜且運維起來十分耗時耗人力的事。每家云廠商提供的 SDK 都不一樣,導致即使使用不同雲廠商提供的相同的雲服務(例如存儲),也會需要通過理解如何使用 SDK,如何配置雲服務,如何部署等等進行單個雲的操作。這樣導致使用雲的門檻和需要維護系統的人力都需要比使用單云策略更複雜、更高。
- 數據暴露給雲廠商,數據沒有隱私當將數據存儲在雲廠商的服務器裡的時候,由於明文數據(沒有加密過的數據)是存儲在有能力看到數據的雲廠商裡,雲廠商潛在會去掃描數據,從數據中提取信息,導致數據隱私洩露。
- 數據託管給雲廠商,數據也許會丟失與點三的原因相似,由於數據是存儲在雲廠商的服務器裡,雲廠商有能力對數據進行更改或者刪除,導致數據的完整性缺失,或者是數據的正確性出現問題。
未來會有什麼痛點?
在上篇 《A&T 前瞻: 為什麼 Web 3 驅動的分佈式算力網絡是元宇宙的基礎設施?》文章裡有介紹到,想要達到類人眼的的體驗,需要向用戶輸出 13k 的圖片(具體計算請見 《A&T 前瞻: 為什麼 Web 3 驅動的分佈式算力網絡是元宇宙的基礎設施?》。每個像素可以通過 RGB(Red、Green、Blue)三個顏色的 “深淺程度”(0-255 的數值)表示,而每個像素值又佔用一個字節(1 byte,8 bits)。
因此,可以得出一張 13k 清晰度的圖片需要:
13,000 * 13,000 * 3 = 507,000,000 字節(B)
換算成 MB:
507,000,000 / 1,024,000 = ~495MB
一張壓縮後的照片大概能減小~80% 的存儲需求,那麼存儲一張壓縮後的 13k 清晰度圖片需要佔用硬件存儲:
495MB * 20% = 99MB
一台自帶存儲硬件 256GB 的 AR/MR/VR/XR 設備只能在本地存儲:
256GB * 1000 / 99MB = ~2600 張 13k 高清圖片
一個應用裡,尤其是中大型應用,在本地起碼需要存儲個上萬幀圖片(也就是視頻)。在端邊設備裡可以放置用於存儲的硬件是無法隨著應用的圖像和音頻質量的提升而無限增長的,原因在於:
- 重,所有的 AR/MR/VR/XR 都在嘗試減輕重量,提升用戶體驗。因此,放太多存儲硬件是與這些設備設計方向相違背的。
- 貴,這些設備最終不會靠賣硬件賺錢,而是硬件商通過自家的應用商店向應用開發者收取費用。硬件商會有非常強的意願控製成本,為的是能大量鋪開用戶購買來吸引應用開發者,這樣應用商店就能賺更多的錢。因此,硬件商不會去加更多存儲硬件提升設備成本(不要嫁接這部分成本到潛在用戶身上)。
因此,光是存一個應用所需的視頻即將用滿存儲,更不用提多個應用需要的常用音頻和視頻流所需的存儲空間。在可預見未來的元宇宙大規模使用後,現在已有的存儲架構方式將不足以支撐未來發展需要的數據存儲和使用。
Web 3 驅動的分佈式數據存儲網絡發展現狀
是什麼?
分佈式數據存儲網絡將會存儲三種不同類型的數據:
- 第一類是需要經常被調用的數據/內容,這類數據會存在一個分佈式的數據緩存內容分發網絡裡
- 第二類是非結構化數據,即沒有預定義數據模型的數據,不能使用數據庫的二維邏輯表進行存儲和調取的數據
- 第三類是結構化數據,即有數據模型定義的數據,用數據庫的二位邏輯表(行與欄)進行存儲和調取的數據
在元宇宙裡,一些經常需要被調用的視頻和音頻數據會存儲在分佈式的數據緩存內容分發網絡裡,而不常被調用的視頻和音頻數據則會存儲在非結構化數據庫裡。
每當數據調取的頻率發生變化時,分佈式的數據緩存內容分發網絡裡的內容則會隨著調用頻率而進行更新。
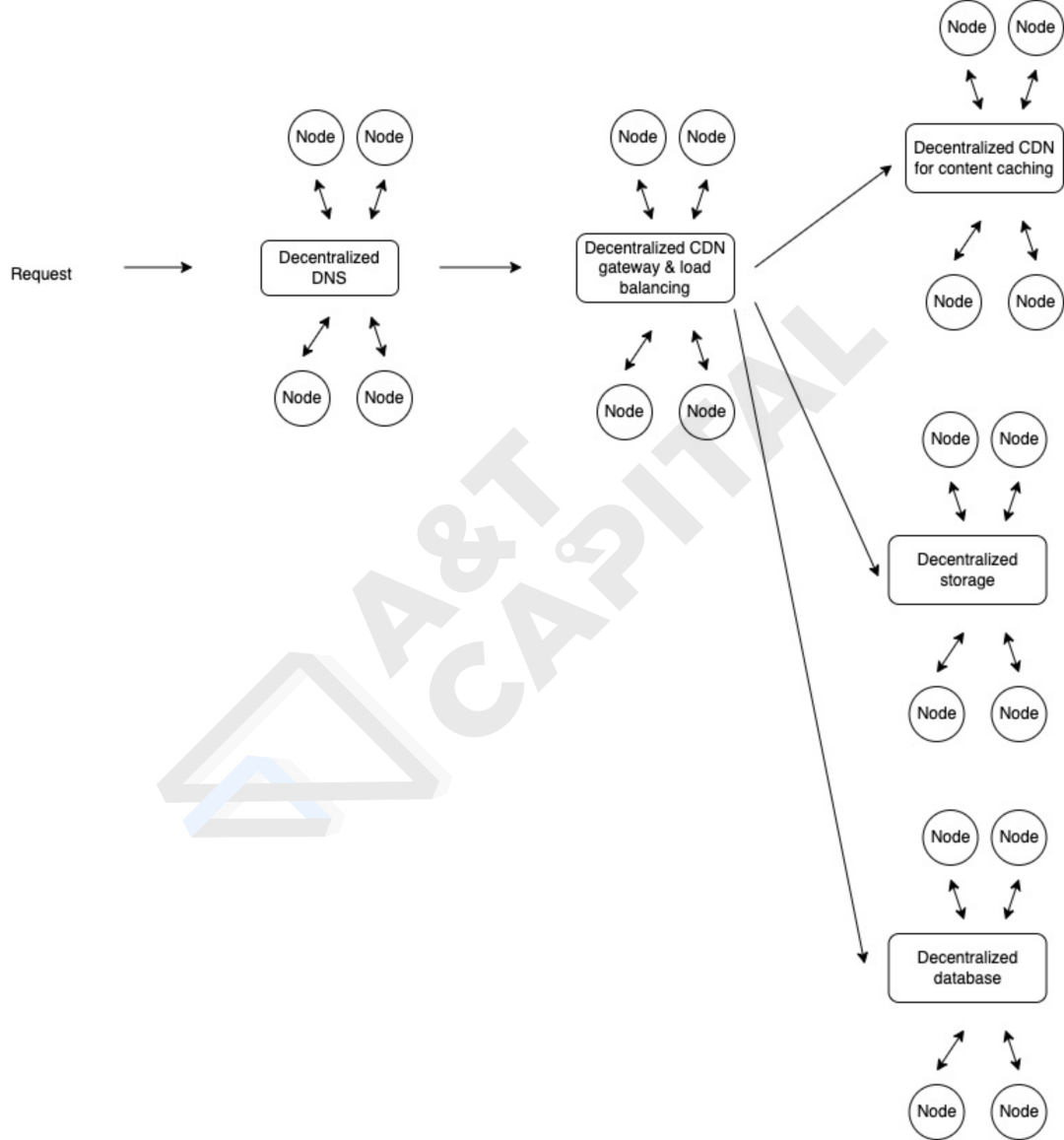
上圖展示了一個作者設想的分佈式數據存儲網絡的架構:
- 一個數據調用的 request 通過去中心化的 dns 找到相應的內容分發網絡,這一步是為了找到存儲 request 需要調用數據的網絡的大致定位;
- 找到網絡後,均衡負載和 gateway 將會把 request 推送到 request 想要調取的數據的服務器上。根據數據類型的不同,request 可能最終去到:
- 分佈式的數據緩存內容分發網絡裡
- 去中心化非結構數據存儲網絡裡
- 去中心化結構化數據庫裡
如何解決元宇宙里數據隱私、完整性、以及存儲調用效率問題?
- 主動加密/被動加密上文提到的存儲數據隱私可能被存儲服務器的擁有者侵犯。這一問題可以通過兩種方式解決,一個是在數據發送到服務器節點存儲時主動進行加密,然後再進行存儲。另外一個方式是在數據到達服務器時網絡裡的其他節點 enforce 數據必須進行加密後存儲。
- 認證節點網絡數據的完整性和正確性可以通過一個 validator network 來確保。validator 節點可以 periodically scan 網絡節點裡的數據,確保沒有節點裡存儲的數據副本一致。
- 節點分佈全球存儲調用效率與存儲距離以及數據存儲 medium 直接相關:
- 當數據存儲在內存裡,數據在硬件上調取的數據更快;
- 當數據調取的節點離 request 距離近的話,數據發送的就更快。
- PoPW 使用 tokenomics 激勵全球的網絡用戶加入數據存儲網絡,PoPW 的共識協議確保數據的正確性和完整性。Tokenomics 用於基礎設施網絡有兩個好處:
- 能夠在全球範圍內快速擴展網絡,更好的響應全球的數據調取的需求;
- 大型物理網絡需要資金投入,不管是前期購入硬件成本還是後期的運維和維護成本。通過使用 tokenomics 構建和維護網絡並將收益全部分配給供應方是一種更具成本效益的解決方案。
分佈式存儲網絡創業公司 Mapping
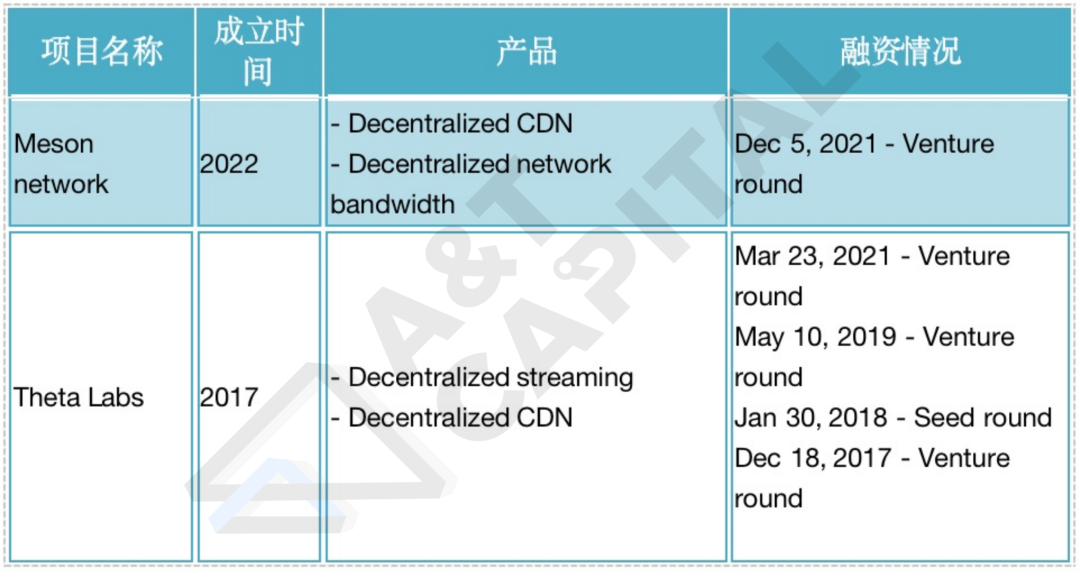
Web3 驅動的去中心化 CDN
Web3 驅動的去中心化的非結構性數據存儲

Web3 驅動的去中心化的關係型數據庫
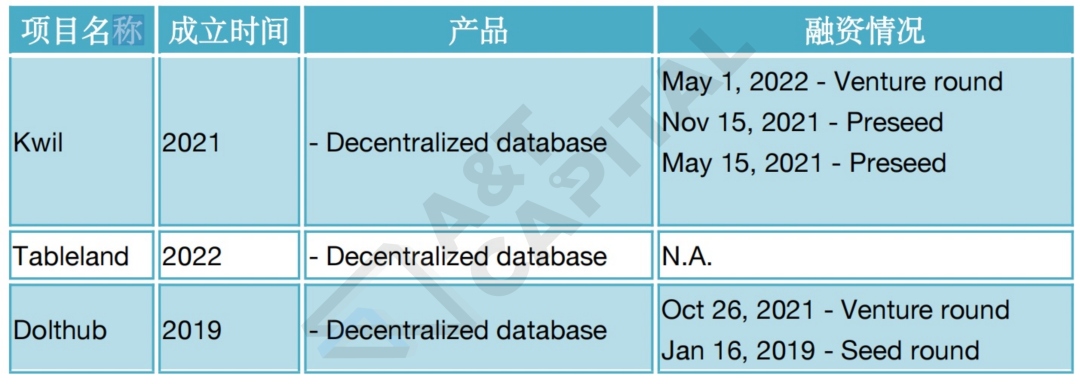
總結
筆者認為,在可預見未來內可以看到 web3 驅動的分佈式節點 CDN 更大規模的應用、分佈式數據庫的小規模應用,以及針對非結構化數據存儲的優化及潛在小規模應用。
免責聲明:作為區塊鏈信息平台,本站所發布文章僅代表作者及嘉賓個人觀點,與 Web3Caff 立場無關。文章內的信息僅供參考,均不構成任何投資建議及要約,並請您遵守所在國家或地區的相關法律法規。