本文将测评 MinMax、QnA3 以及 Web3 Analytics 等 AI 驱动的 Web3 对话机器人,从理解、生成、学习与优化等能力进行多视角对比,综合评判使用体验以及智能程度。
封面:Photo by vackground.com on Unsplash
去年年底 chatGPT 大火之后, Web3 领域的 “时尚弄潮儿” 纷纷探索起了 “ AI + Web3 ” 无限可能。相比于有完整知识体系的传统行业而言,作为一个尚未形成完整学习机制的新生世界而言, Web3 似乎更需要有像 chatGPT 一样能够在关键时刻给点灵感、及时答疑的角色。
虽然当前 “ AI + Web3 ” 的热点话题仍然在 Worldcoin 等身份识别网络, Telegram Bot 叙事的 Unibot 、 Lootbot ,以及 zkML 等未来可能与扩容解决方案有进一步联动的技术之上,但社区中陆续出现了 MinMax 、 QnA3 以及 Web3 Analytics 等 AI 驱动的对话机器人,也能证明已经有团队注意到了 Web3 在知识传达方面的空缺,并想要做 Web3 专业领域的 chatGPT 。本文将测评上述三种 Web3 对话机器人,从理解、生成、学习与优化等能力进行多视角对比,综合评判使用体验以及智能程度。
测评指标
测评第一步,当然是新建文件夹设计一系列评判指标。对于一个交互模型而言,用户体验分别来自交互过程以及模型的智能程度。交互体验将主要聚焦于 UI 设计,而模型智能程度的衡量将包含以下几个方面:
1. 理解 &生成能力:
- 能够准确理解用户输入的问题,联系上下文,并生成自然、流畅且有逻辑的回复
- 在回答中能够做到表达清晰、简洁明了,并对解决问题导向的提问能提供有用的解决方案和建议
- 能够提供有用的解决方案和建议
2. 学习 &交互优化能力:
- 能够通过用户提供的资料与数据源中,总结并给出准确的信息和答案
- 能够不断学习和提升对于特定行业的理解和背景知识
- 能够从与用户的互动中进行推理,并能够通过交互改进回答
- 能够根据用户反馈和行为进行优化,提供更好的用户体验
3. 多语言处理:
- 能够理解和回应多种语言的回答,包括自然语言和机器语言
- 能够提供清晰、准确并符合语言习惯的回答
交互体验
MinMax
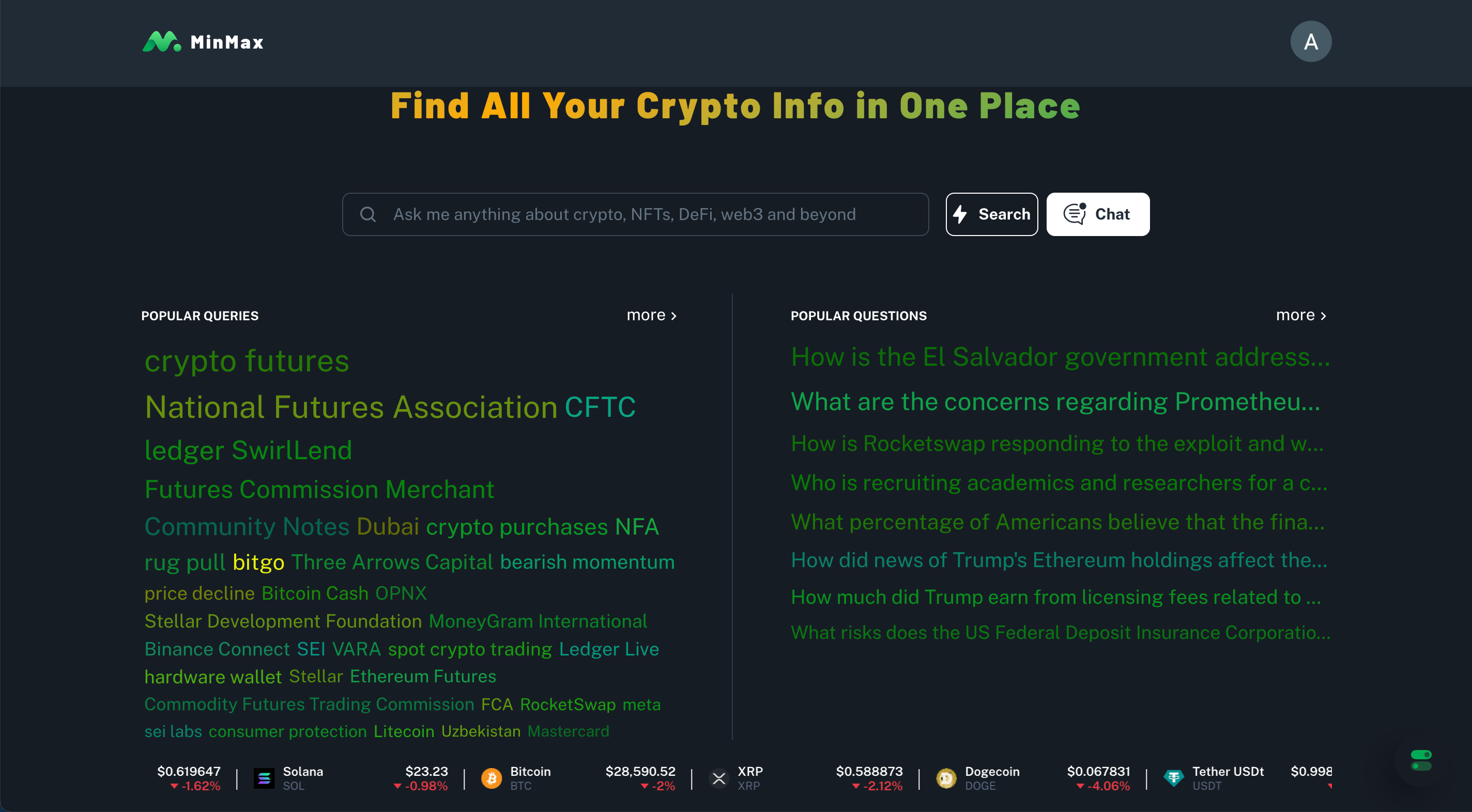
直观感受,默认黑色背景,绿色文字,合理怀疑 UI 团队坚信 “ Keep the bar green to keep the code clean ”(又或是单纯出于护眼)。由于人眼对绿色高敏感度, MinMax UI 第一眼看到的是 Popular Queries 和 Popular Questions 模块,直接将搜索量较高的概念与问题直接展示给用户,算是利用了一把 “从众心理”,点击之后一键跳转到相关概念和问题界面中。
美中不足的一点是,这两个模块词云的设计可能是基于搜索量改变字体大小,从而强调搜索次数多的概念与问题,然而可能由于当前用户较少,或搜索次数过于平均,词云中并没有展现出更直观的对比。词云的优势仍然需要后续采用量提高、搜索差异化增强之后才会显现出来。
毕竟 Minmax 的定位就是搜索引擎,所以对机器人的强调也仅限于主页的小白框。
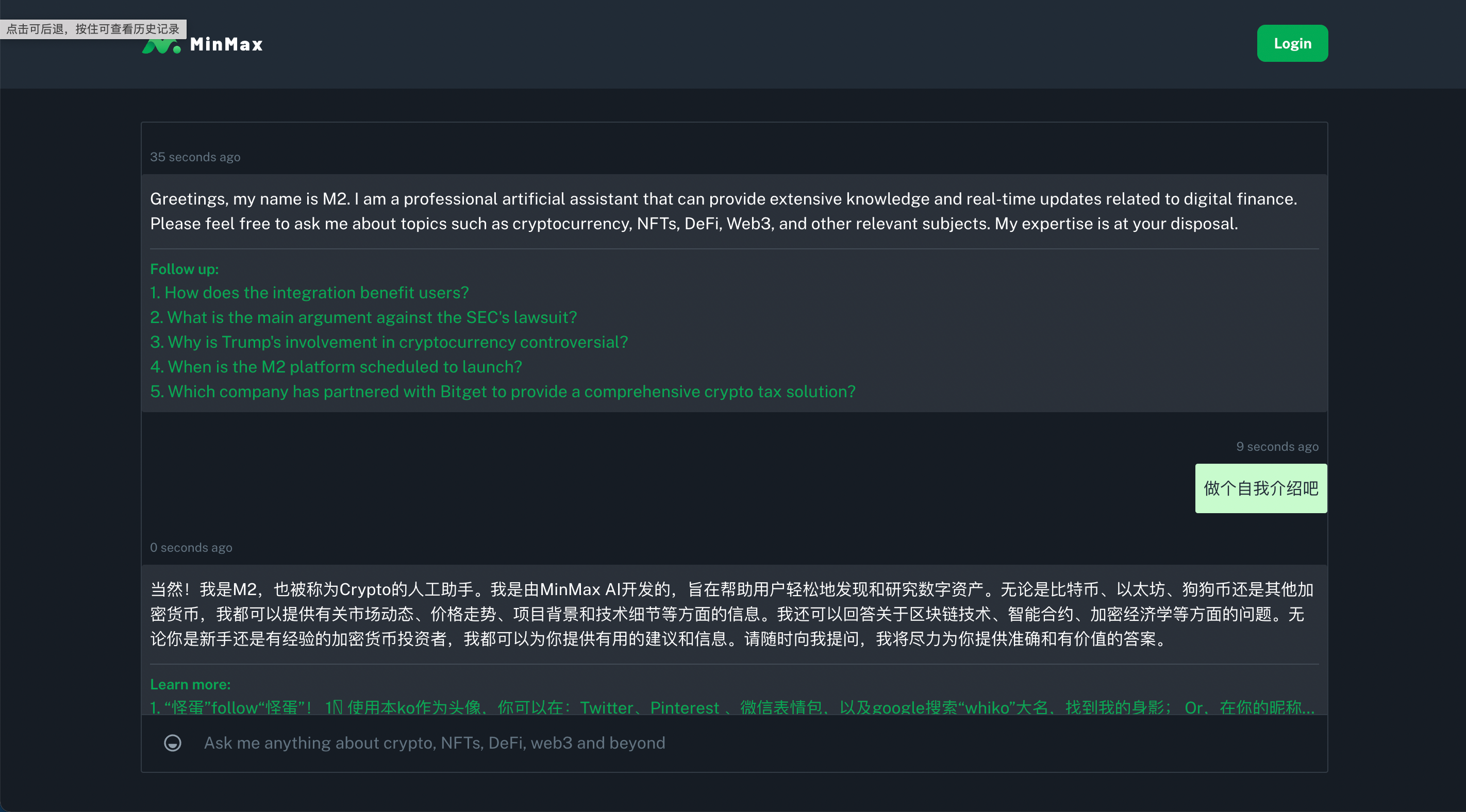
聊天机器人界面,依然是祖传的黑绿配色,自动生成一条打招呼消息,并依然附带几条 “热搜”。总之, MinMax 聊天界面相当简洁,同时因为本身定位是搜索引擎,所以相当喜欢在聊天过程中搞点信息联想。
除此之外, MinMax 可以直接通过邮箱、 Google 、 Twitter 或 Facebook 登陆,甚至不要求用户拥有钱包,相对更加萌新友好。
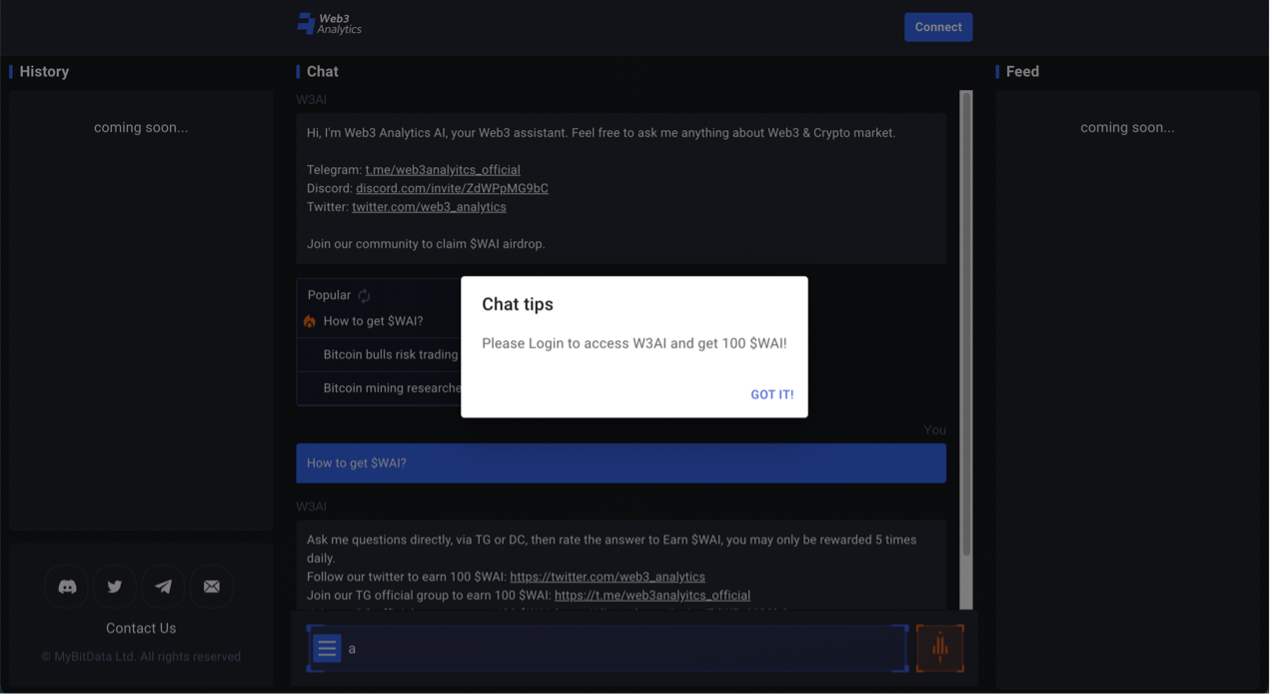
Web3 Analytics
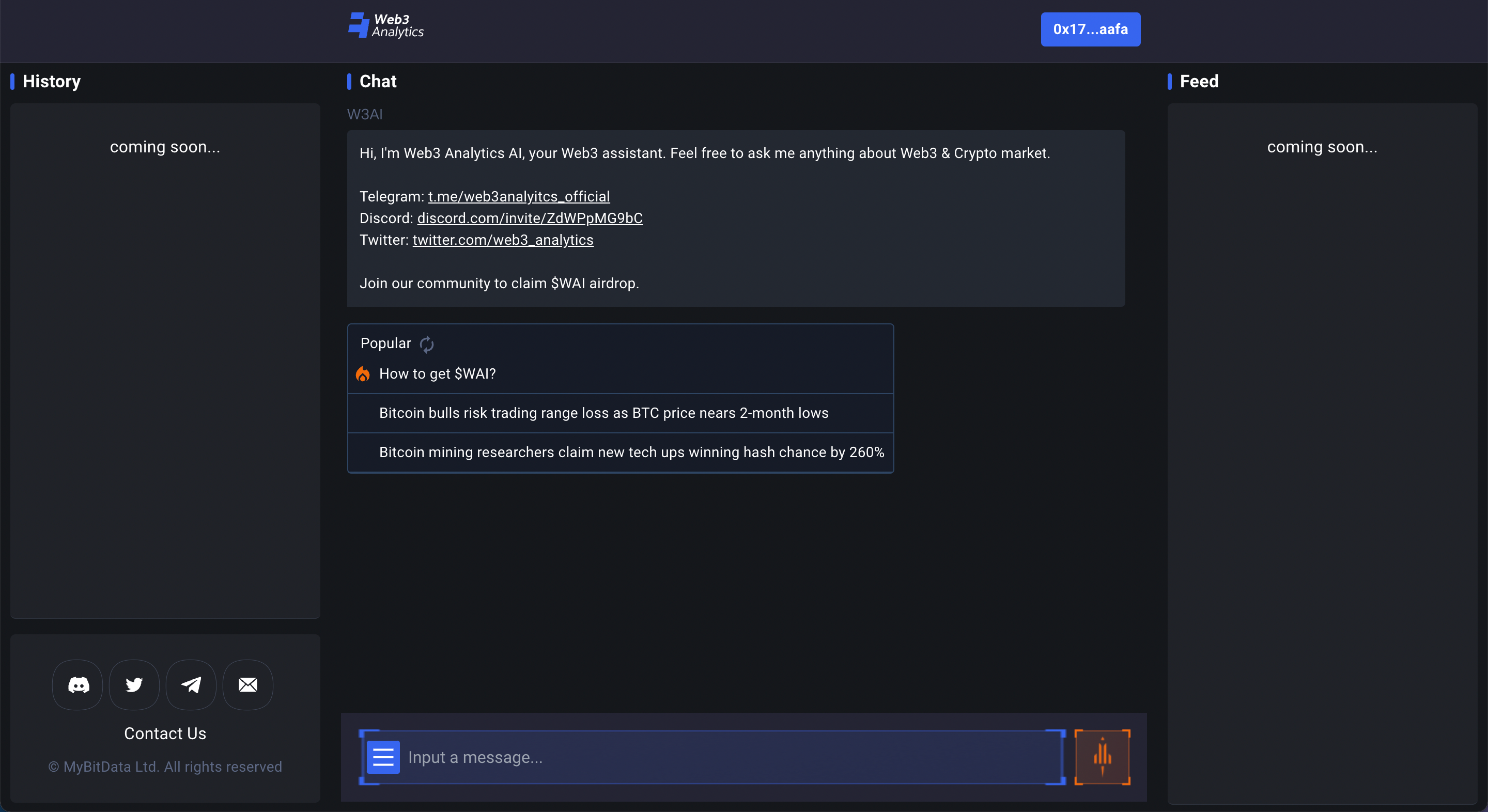
与 MinMax 相比, Web3 Analytics 的设计就是一个纯粹的聊天机器人,首页就是聊天界面,黑蓝配色梦回经典 Visual Studio ,左侧边栏历史回话以及右侧反馈功能仍待开发。历史回话不用说,反馈部分将怎样呈现还是值得继续关注的。
W eb 3 Analytics 自动生成的打招呼消息除了热搜词条,更多的是强调了 Telegram 、 Discord 等社媒以及项目代币 W AI 。对 Telegram 和 Discord 的强调,大概是源于 W eb 3 Analytics 也是 Telegram / Discrod Bot 叙事的参与者。值得注意的是,团队引入了 “ Train AI to Earn ” 的概念,可以通过向机器人提问获取项目代币。也正因为涉及到代币,所以要求钱包登入,且如果是在没登陆的情况下向机器人提问,至多 3 个问题之后,网页就会持续提示需要登陆并获取 W AI ,并且完全不能在不登陆的情况下继续使用。
QnA3
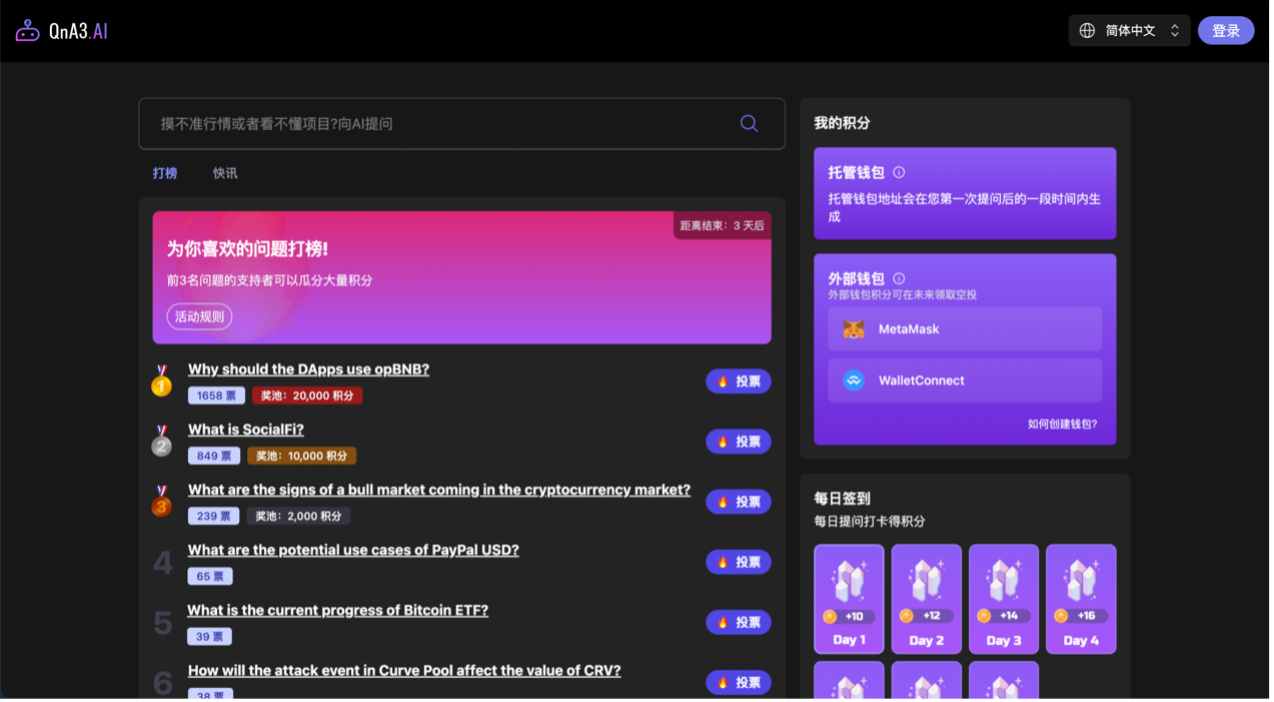
不同于以上两个机器人浓郁的程序员风格, QnA3 这个粉紫配色直接多巴胺起来了。首页展示热搜问题并推出了 “ Vote to Earn ” 功能,因为涉及到积分和日后的代币兑换, QnA3 因而要求用户通过钱包登陆。目前获取积分共有两种模式:
- Vote to Earn :成功押准了前三名问题的用户可以获得积分。
- Ask to Earn :通过完成每日提问任务,兑换项目积分。
目前 QnA3 部署在 BNB Chain 上,积分领取需要支付 Gas ,后续可用于兑换项目代币空投。又是一个要发币的项目,因此, QnA3 登陆也需要通过钱包地址,方便日后 Tokenomics 变现的后续操作。
此外, QnA3 首页还有快讯选项,通过 “巨鲸在问” 拿捏用户,吸引流量推动其点进跳转页面进行持续关注。
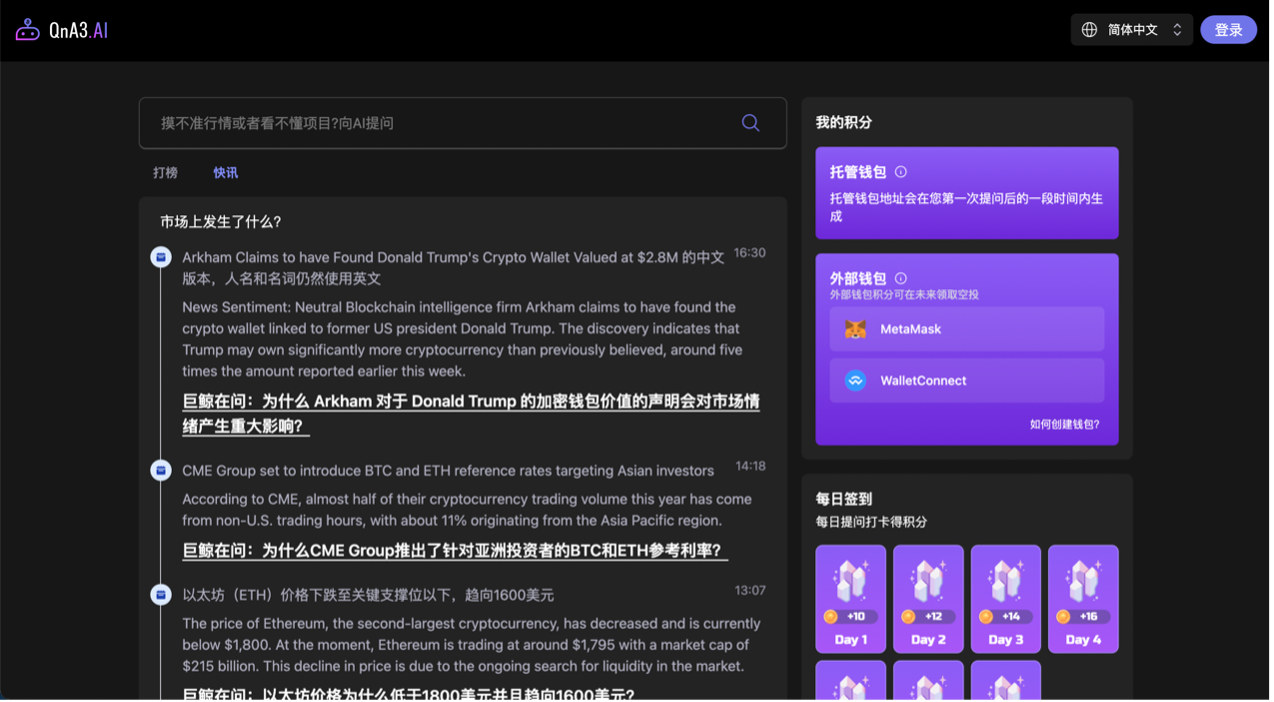
不过简中模式下,“巨鲸在问” 链接点进去一会中文一会英语,属实还值得继续优化一下。
模型智能度测评
注:由于 QnA3 在对话过程中会有 Knowledge Graph 和 Web3 News 两部分回答,前者通过知识图谱从数据库中获取信息后者则是相关咨询的集成,所以在模型智能度测评中, QnA3 会涵盖两个机器人的回答内容。
1. 理解 &生成能力
- 关于理解能力:
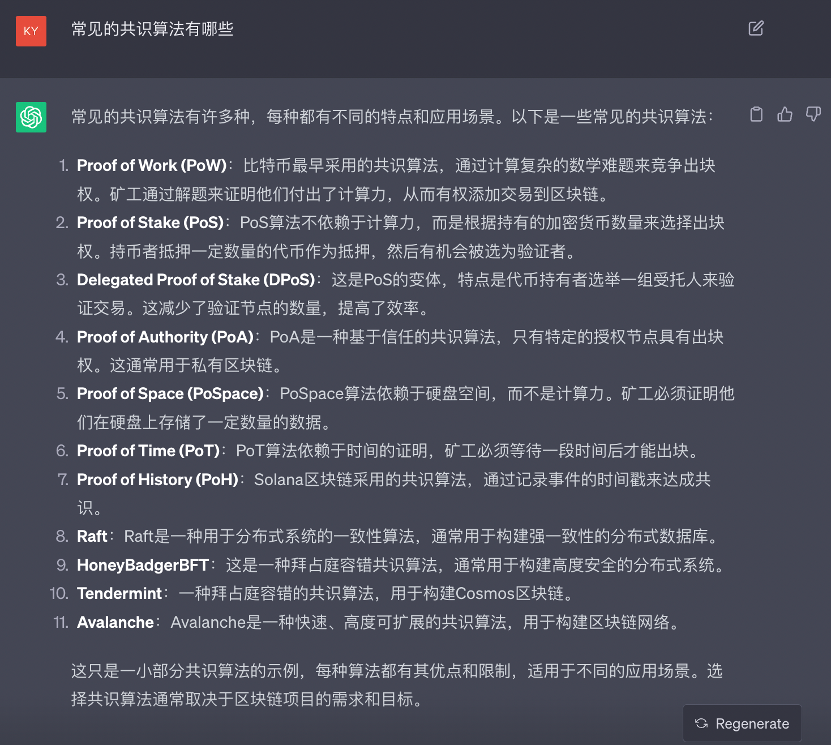
对萌新来讲,接触 Web3 的第一天可能就会从各种各样的资料上了解共识机制与算法。但时间久了,可能脑子里也就剩下 PoW 和 PoS 了,不如也趁此复健一下。
先看看 chatGPT 老师怎么说:
MinMax

Web3 Analytics
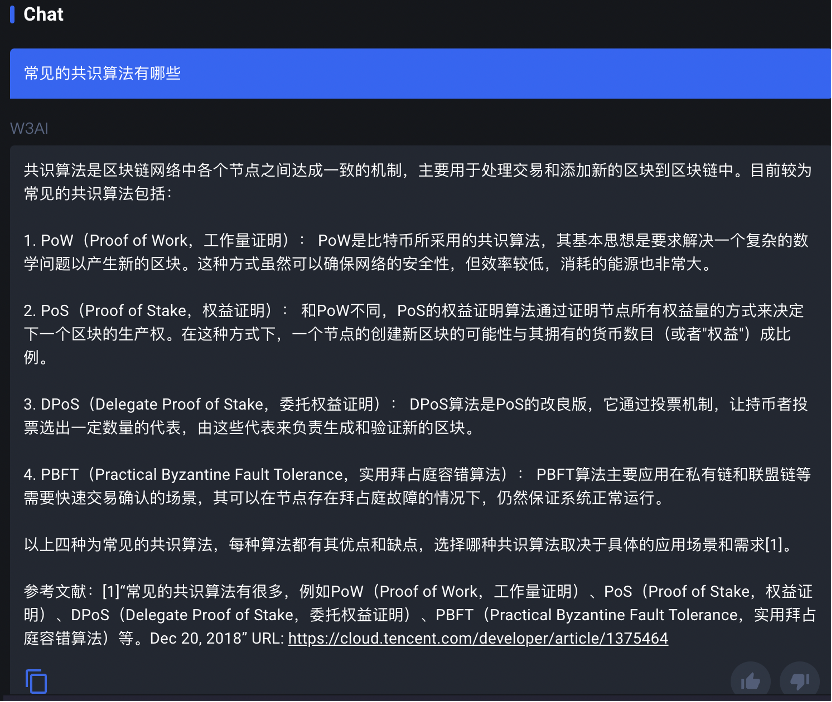
QnA3
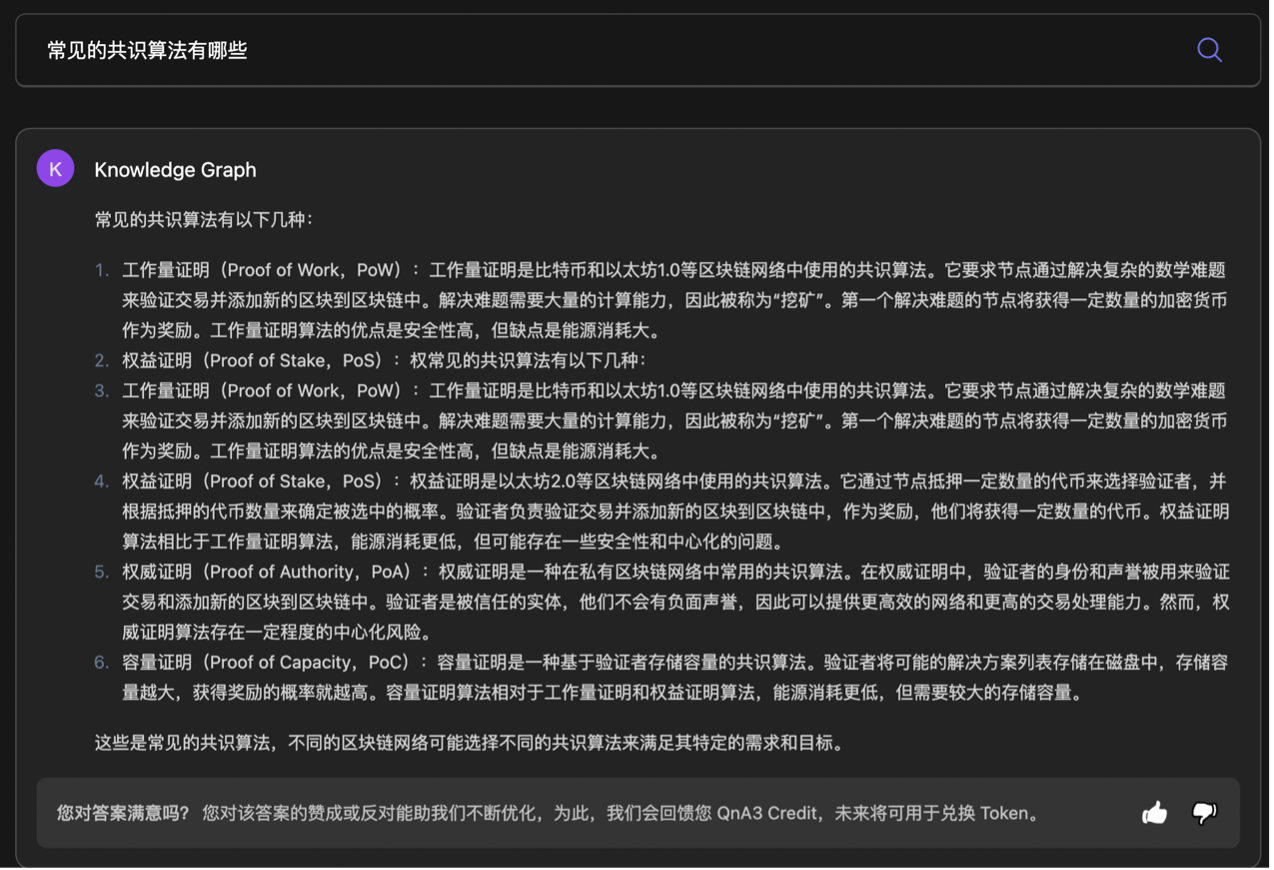
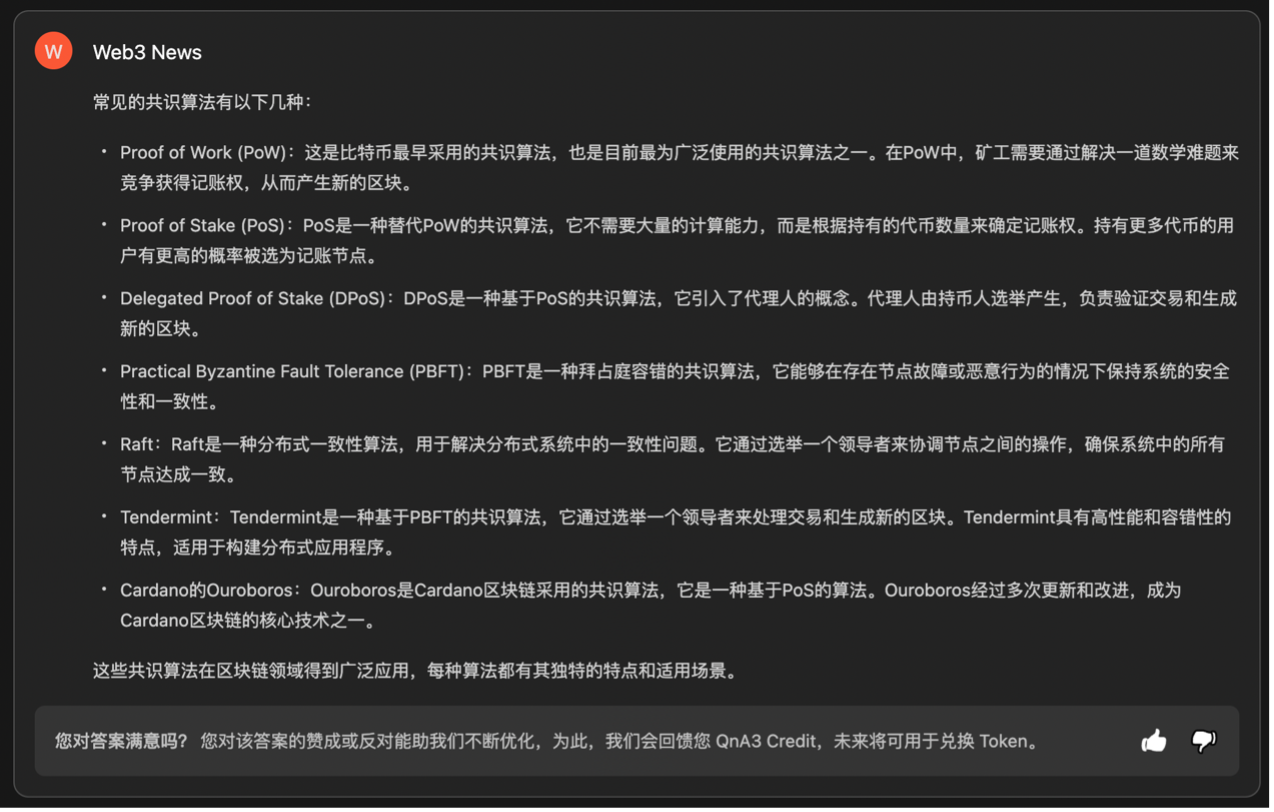
关于共识算法的回答,乍一看三个机器人都给出了合理的解释,并且都清晰的分条列举,但仔细瞧瞧,发现 QnA3 Knowledge Graph 在浑水摸鱼,可能是由于知识图谱数据库中索引或遍历时的问题, PoW 和 PoS 的相关内容输出了两遍。
就具体内容而言,三方对常见共识算法的介绍基本都囊括了 PoS 、 PoW 、 D PoS 以及 PBFT(拜占庭容错),但具体解释的内容稍显苍白,比如 MinMax 对 PBFT 的解释是 “ PBFT 是一种拜占庭容错算法,通过达成共识来处理拜占庭故障”,这像不像我问 “番茄炒蛋是什么一道菜”,机器人答 “番茄炒蛋是一道菜,需要使用番茄和鸡蛋来炒” 一样,用户没有获得字面意思以外的信息增量。
准确性在模型训练过程中固然重要,尽可能避免 “答非所问” 也必定是最终目的之一,但 AI 的回答有时过于追求 “准确” 而输出了一堆 “废话”,这也应该算是严重的模型过拟合现象了。因此,这里认为后续算法的进一步优化,可以考虑在准确测度之上,增加一些诉诸个性化与差异化回答的指标。
- 关于联系上下文:
对话到这里还比较正常,直到我追问机器人,让他帮我具体解释上一个问题中提到的第一种共识算法(PoW)。 我设想的回答 from chatGPT:
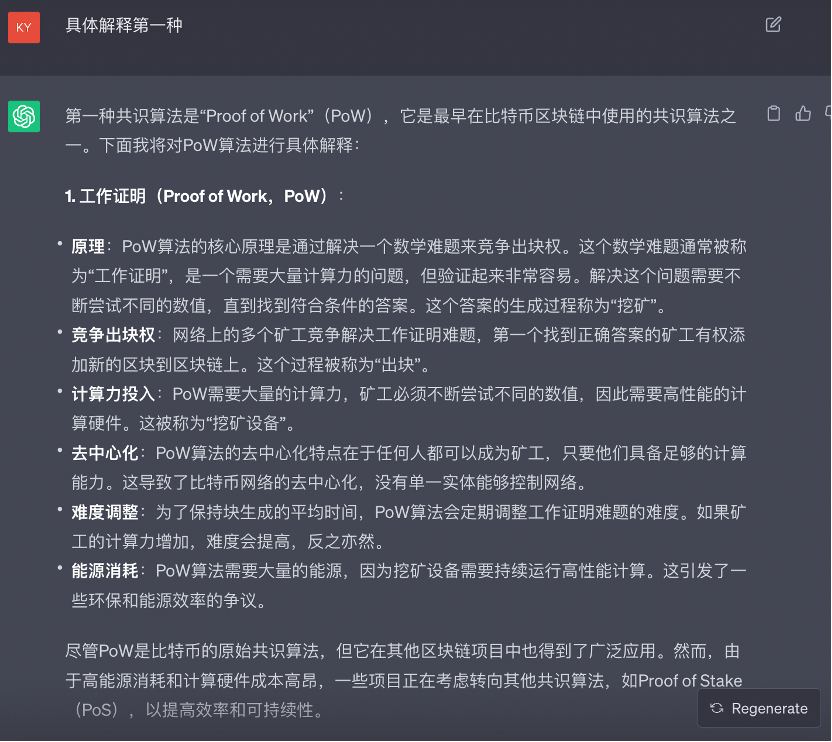
MinMax
能在这个问题上加分的唯一 AI,回答也相当有逻辑,先后提到了 PoW 的应用、核心思想、共识流程、优缺点以及缺点的改善。
Web3 Analytics
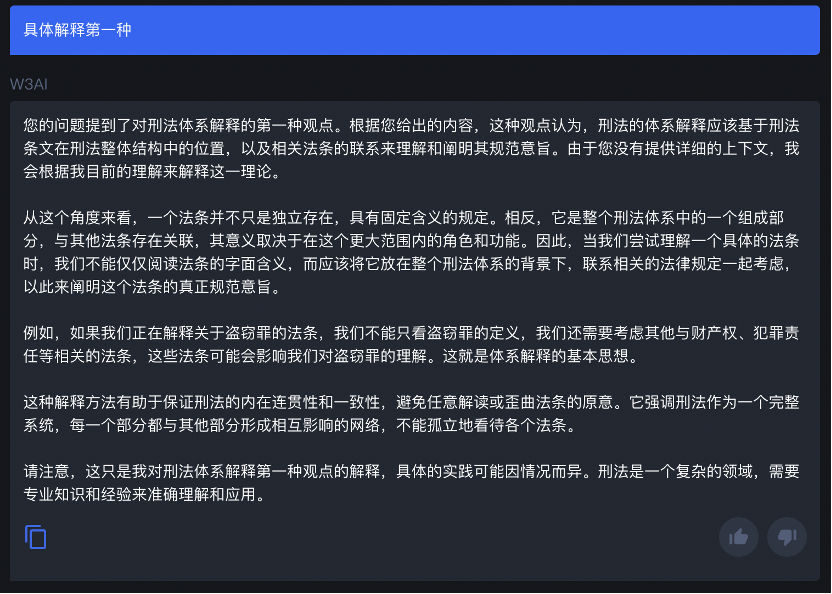
这位给出了和 Web3 毫不相干的回答, 开始怀疑团队里来自国内外名校的成员是不是也包含罗翔老师……
QnA3
相比较 Web3 Analytics 生成的和 Web3 基本完全无关的内容, QnA3 的两个模型生成的内容起码和 Web3 有点关联,但也并没有完全理解我问题中的 “第一种” 指的是什么, Knowledge Graph 甚至语言错乱,输出了英文内容。
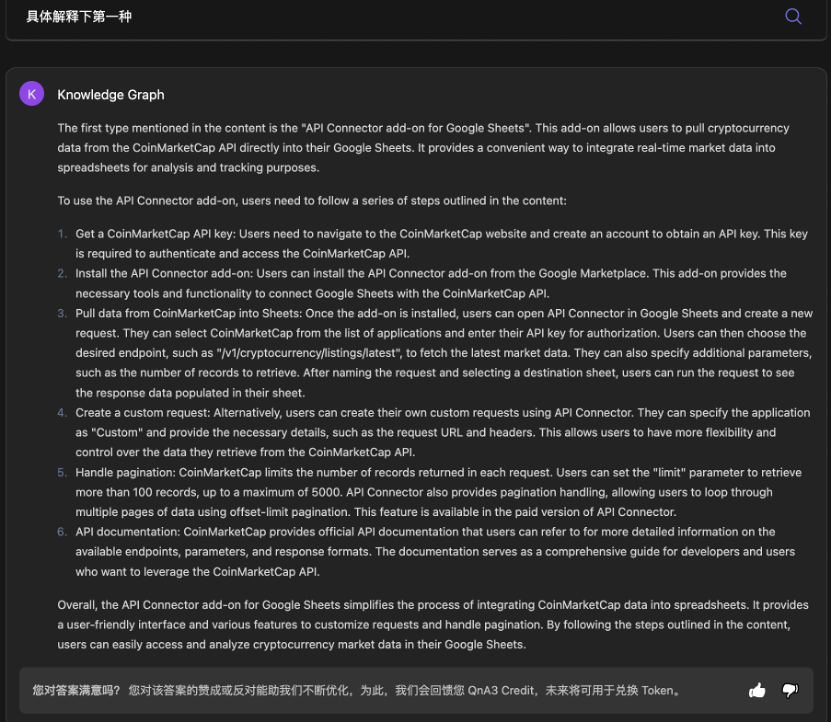

Web3 News 理解了问题的意图,但显然没理解 “第一种” 指代的是什么,同时还出现了 “第一种比特币是指比特币” 之类的废话文学。
总之,从上下文联动能力来看,目前三类对话 AI ,能过关的只有 MinMax 。
-关于生成能力
这里还是考虑文本向的生成能力,先让 AI 简要阐述 PoW 与 PoS 的区别,再让 AI 通过表格形式输出。
chatGPT
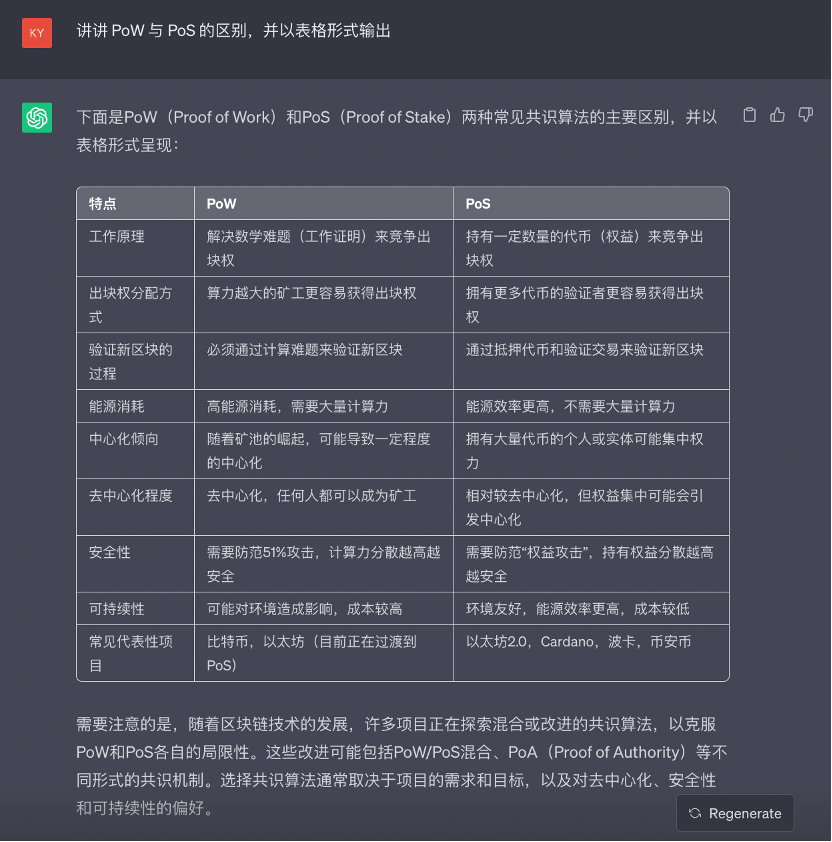
注: chatGPT 这里也没有注意到前半句的暗示。
MinMax

表格可以说是比较清晰地从不同角度对两者的区别分别进行简要阐述,同时在对话结束之前增加了相关资源链接,可以供用户进一步了解个人更感兴趣的部分。
但 MinMax 没有理解我在前半句的暗示,并没有提供概括性的解释。
Web3 Analytics

Web3 Analytics 则是理解了前半句,简要输出了 PoW 与 PoS 的区别,并非常严谨地标注了信息来源。
而在表格部分,内容上, Web3 Analytics 好像脑补出了一场商战大戏, PoS 直接成了按照股份和/或年龄选择矿工的机制,同时表格本身也实在是有点过于质朴了。
QnA3
QnA3 确实是三者中在理解和表格输出方面相对最好的。
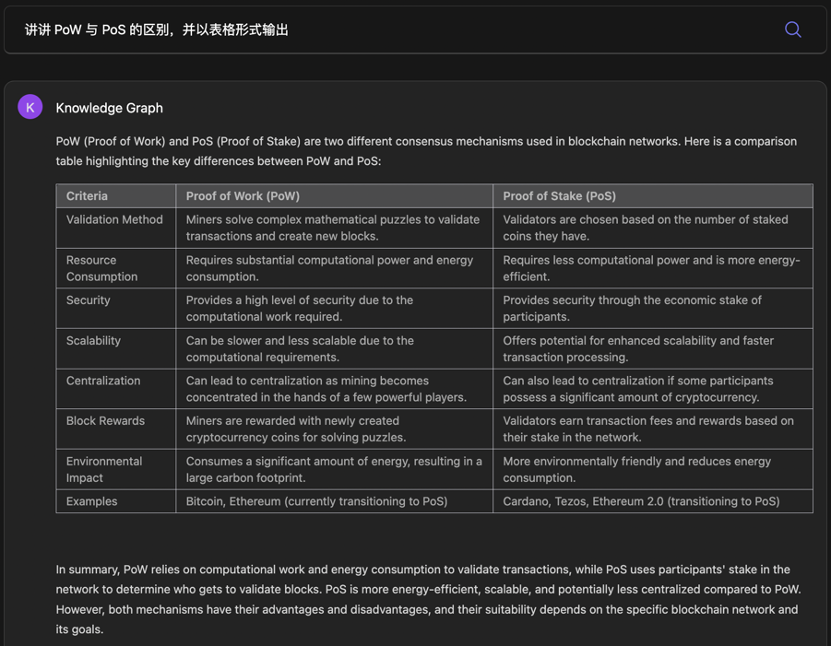
表格要点完整,也有总结, 从内容角度上来讲是四个回答里最完整的,但就是不知道 Knowledge Graph 为什么总热衷于在语文试卷上用英语答题。
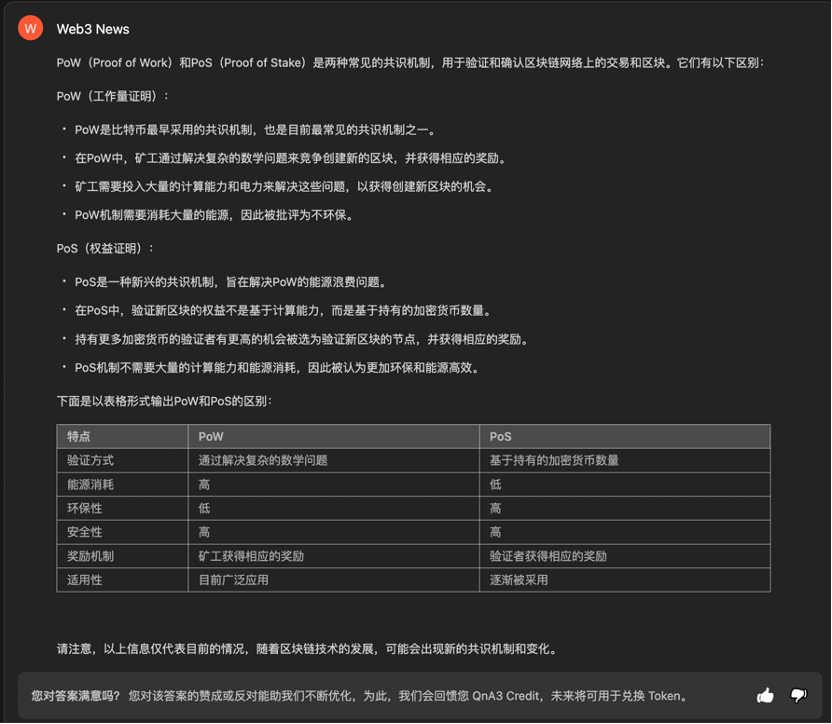
QnA3 Web3 News 的回答相对来讲是几个机器人中最符合要求的,既做到了先阐述两者的区别(甚至还通过分点,让回答看起来更有条理),同时也输出了一个涉及到不同方面的对照表格。
因此,在功能性生成上,可以优先考虑 QnA3 和 MinMax ,毕竟表格基本是可以截图就用的。
2. 学习能力
判断一个 AI 模型的学习能力,首先要先找到一个并不存在于其当前数据库中的 “新知识”。但通过对反复对话,我还没有找到三个 AI 模型同时都无法回答的问题。因此,对于 MinMax 和 Web3 Analytics ,用于判断其学习能力的问题是 NFT 绑定账户的新标准 ERC -6551,而对于已经了解了 ERC -6551 并能输出一定细节的 QnA3 ,问题则是 MakeDAO 于今天发布的最新治理提案。
MinMax
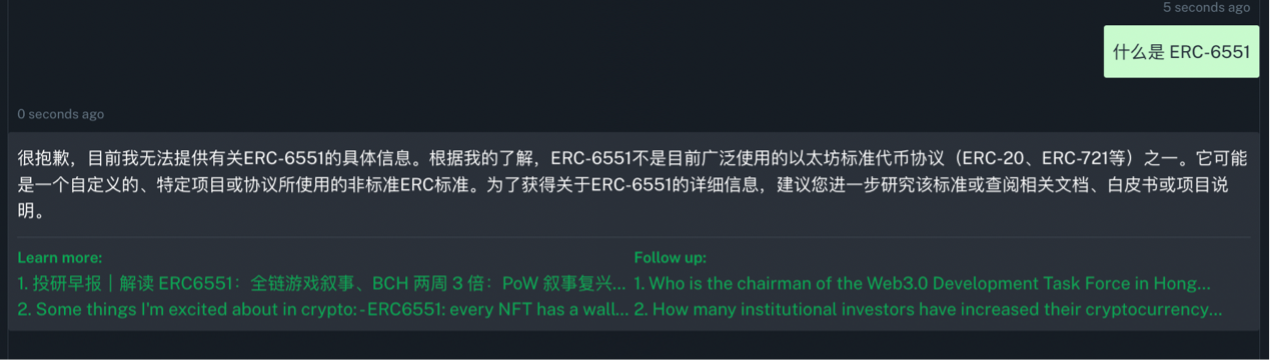

在提供了相应的信息之后, MinMax 就可以从中进行信息整合,输出的内容也算是触及到了 ERC -6551 的核心思想,虽然不涉及到太多技术上的创新,但如果对于完全不知道 ERC -6551 是什么且想要快速了解的标准基本内容的小白来讲,内容已经足够了。
顺便问了下 MakeDAO 的问题。

 总之,虽然不能做到实时数据抓取与保持训练集实效性,但就单从 “学习” 角度来讲,在提供目标内容之后,MinMax 确实可以将 “学习成果” 清晰且有逻辑地展示出来。
总之,虽然不能做到实时数据抓取与保持训练集实效性,但就单从 “学习” 角度来讲,在提供目标内容之后,MinMax 确实可以将 “学习成果” 清晰且有逻辑地展示出来。
Web3 Analytics
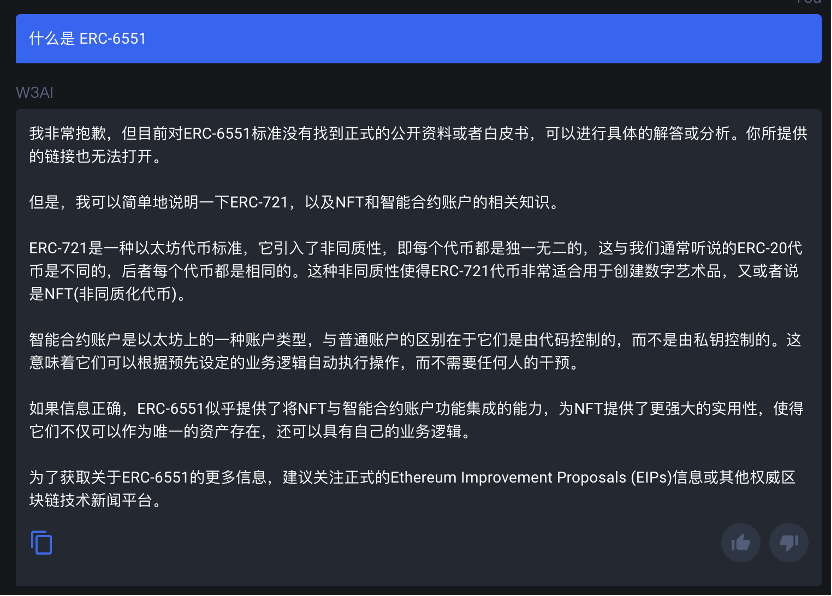
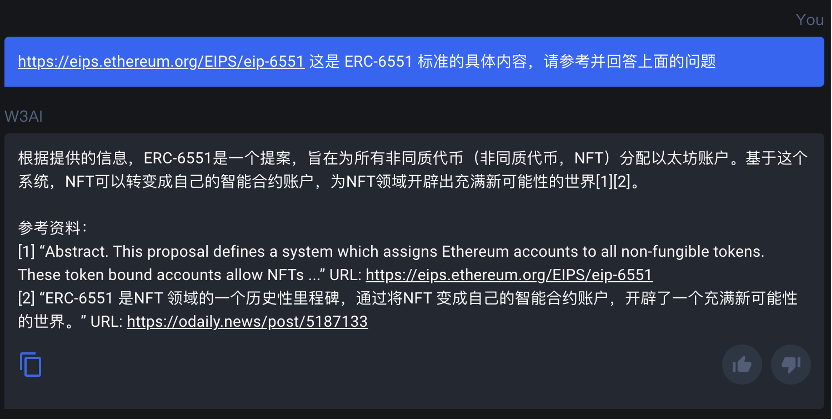
即便是提供了 ERC -6551 标准的具体内容, Web3 Analytics 也没能对其进行总结, 而是输出了一篇扩展文章中 ERC -6551 的简介部分,查重率高达 80%。
同样,这里也贴一下 Web3 Analytics 关于 MakerDAO 最新提案的回答:
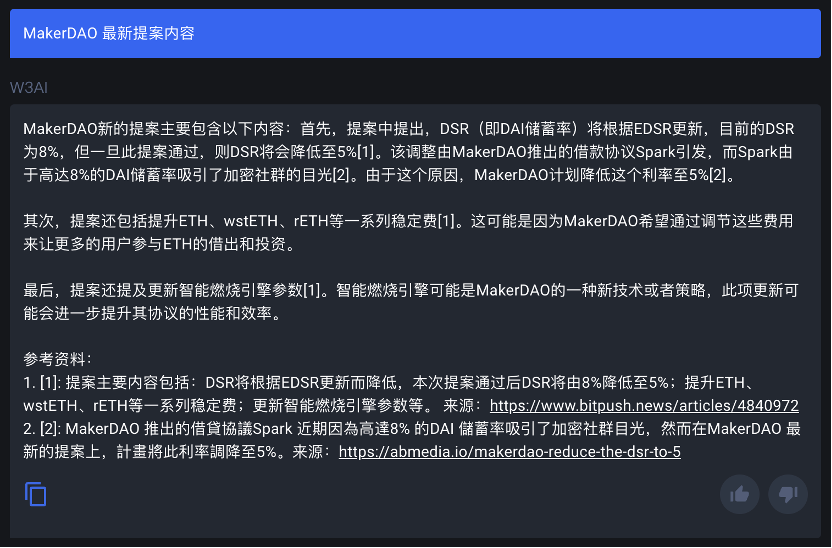
可见,对于已经纳入数据集的信息, Web3 Analytics 其实是具有将其分点输出的能力的。因此,单就学习能力而言,或许 WA 团队仍然需要优化一下 AI 针对用户提供的外部信息进行总结与输出的能力。
QnA3
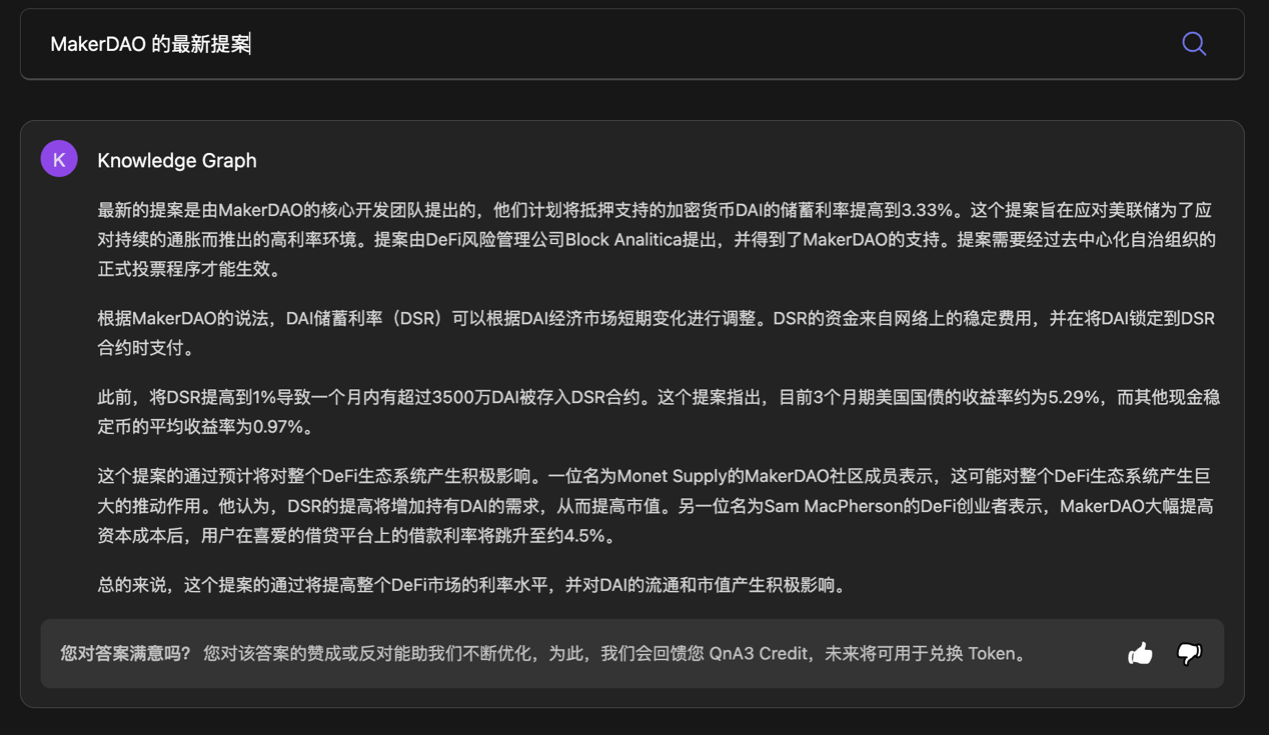
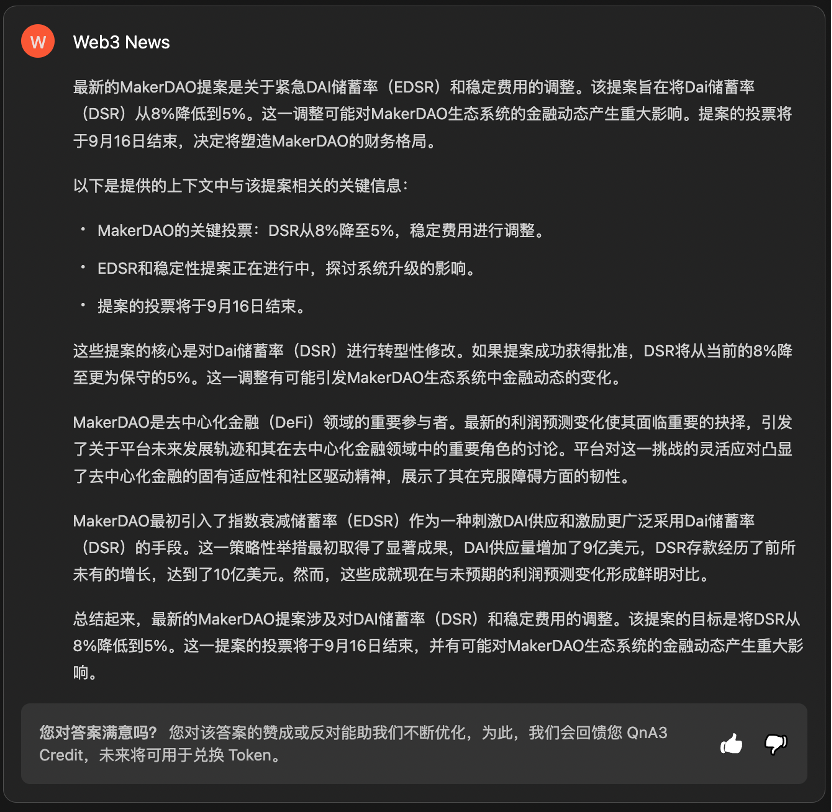
或许是由于一周末的数据集更新, QnA3 Web3 News 已经可以输出 MakerDAO 上周五发布的最新提案了,然而 Knowledge Graph 信息仍然还停留在今年五月。

提供 MakerDAO 最新提案的相关链接之后, Knowledge Graph 依然没有输出提案中最关键的 DSR 调整问题。因此, Knowledge Graph 的学习能力还是需要进一步优化的。
总之,虽然数据集的更新可能有点更不上 Web3 技术迭代的速度,但就模型对外部知识的学习能力而言,可以优先考虑 MinMax 。 Web3 Analytics 和 QnA3 虽然有着相对高效的信息迭代,但整体学习能力还有待提升。
3. 多语言处理能力
- 自然语言
为了满足当前全球化背景下 Web3 世界对于无障碍跨文化沟通的需求,就要求 AI 具备一定的多语言内容创作与信息检索能力。
单就中文和英文来讲, MinMax 与 Web3 Analytics 可以无障碍回答问题,其生成的内容也符合语言习惯。而对于 QnA3 Knowledge Graph 来讲,虽然英文内容是三个模型中质量最高的,但用英文回答中文问题也确实不太合适。同时,即便是有时能用中文回答,内容上还是有点过于直译,不太符合中文的语言习惯。因此,对于内容极佳的 QnA3 Knowledge Graph 来讲,进一步提高对其他语言的兼容性,或许是提高采用率的可行举措。
- 机器语言
简要概括 AI 模型在 Web3er 日常工作中的应用:翻译器 + debugger 。
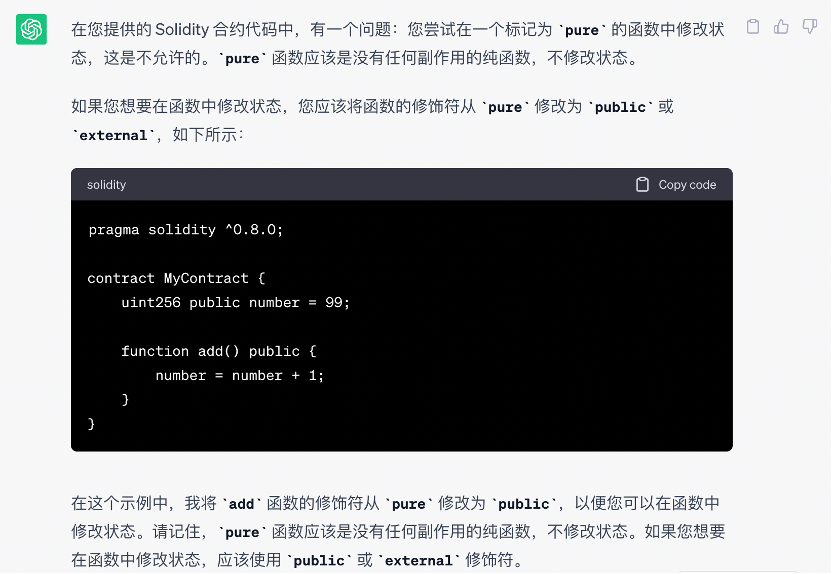
如果说对自然语言的测试某种情况下测评了一个 AI 模型作为翻译器的合格程度,那么这部分就是要看看这三位是不是合格的 debugger 了。这里选用一段非常简单但对 Solidity 初学者来讲非常容易出错的代码:

简单解释一下,代码中出错的点在于 pure 关键字不能改变链上状态,通俗点来讲就是带有 pure 后缀的函数,可以理解为只能干瞪眼 “纯” 看,并不能对任何变量进行修改,也就是说第五行让 number + 1 的操作不可能实现。注:站在 Solidity 初学者的立场,对 debugger 的要求——需要模型指出错误所在的地方,给出相应解释,并修改代码。
请 GPT 老师打个样:
MinMax
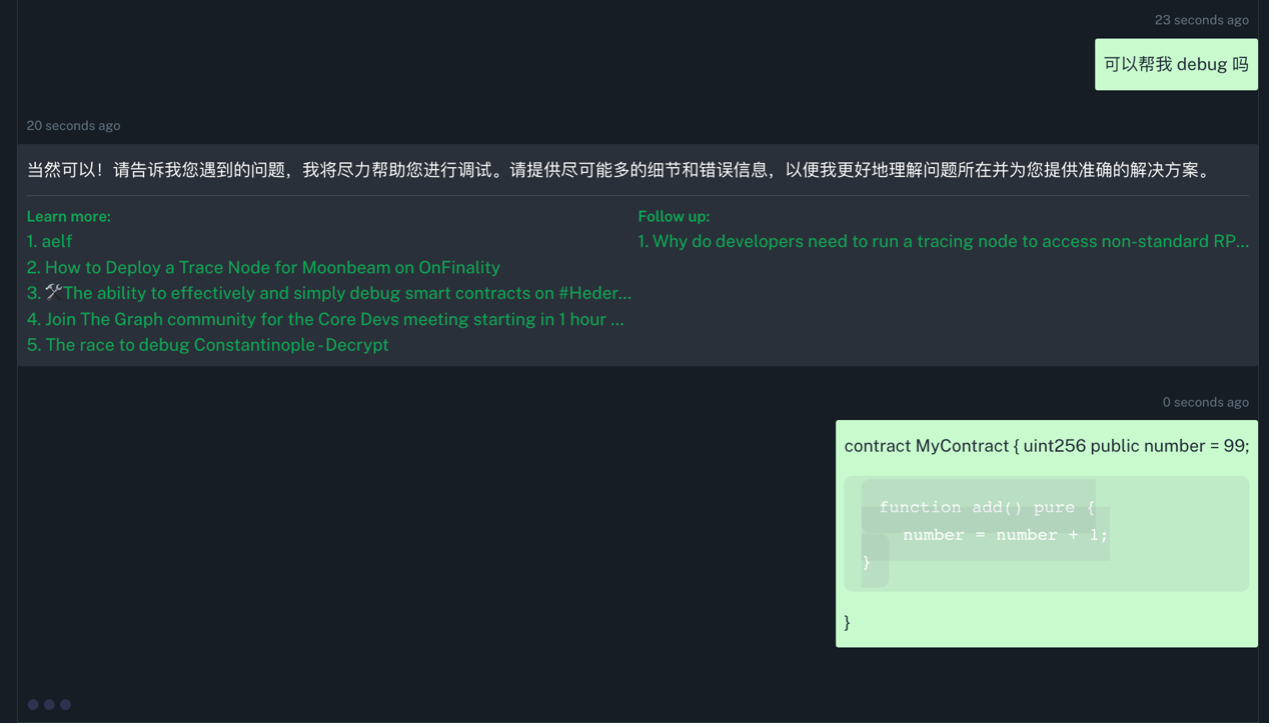
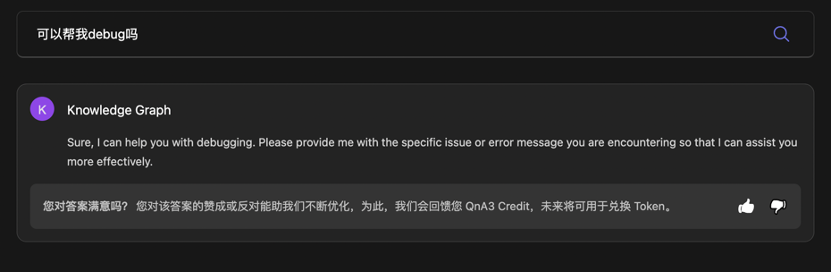
我:可以帮我 debug 吗?
MinMax :我可以,我装的
像极了我一看代码就宕机的脑袋, MinMax 在 debug 的过程中直接报错并终止对话。除此之外, MinMax 显示出的代码框明显也需要修改,终于找到了精通外部学习与自然语言交流的 MinMax 目前唯一的短板。
Web3 Analytics

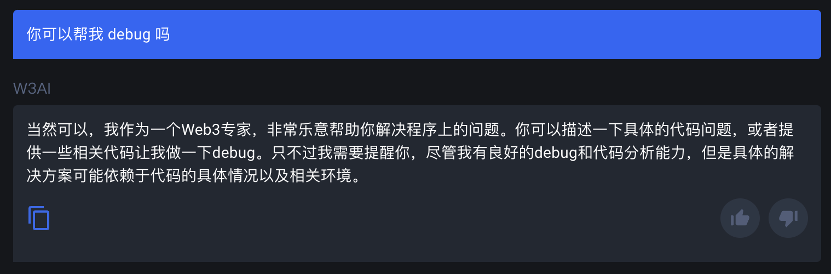
Web3 Analytics 理解能力再扣一分,痛失主语省略权。

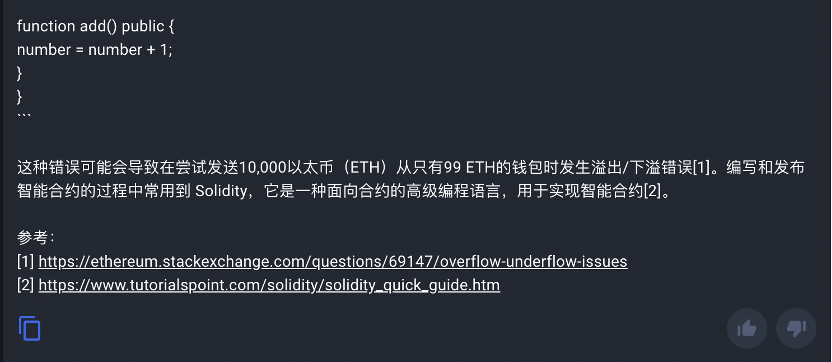
虽然在某些对话中显得不太智能,但 Web3 Analytics 在 debug 方面的能力还是令人满意的。既解释了代码中出现的基础概念,以及错误的来源,给出了修改的代码,同时还在最后简单解释了错误代码在合约部署方面的现实意义。好吧,可以暂且原谅他剥夺了我的主语省略权。
QnA3
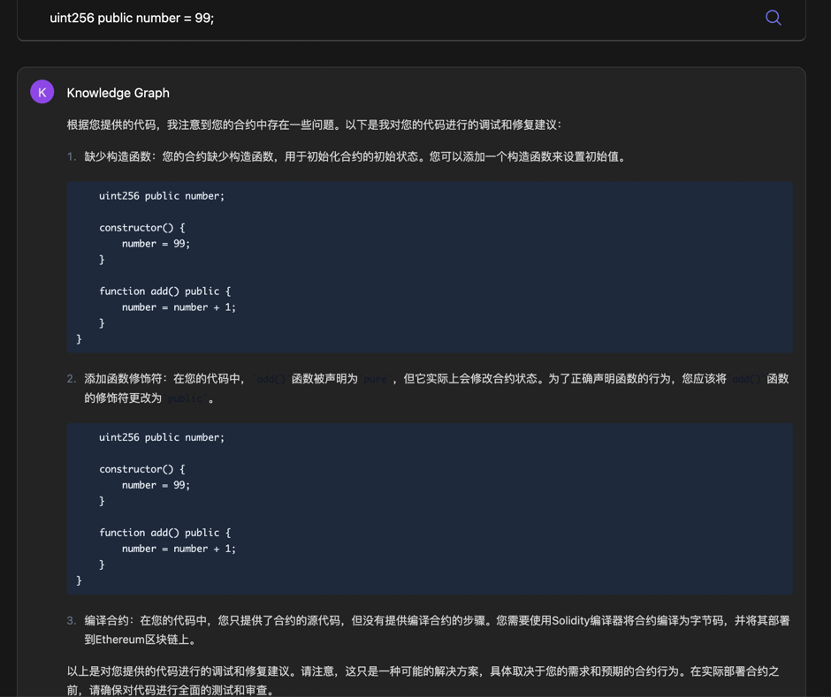

从调试的角度来看, QnA3 没有任何问题,指出错误所在并进行相应修改,完全符合本部分开头的要求。美中不足的是,代码块字体颜色和背景过于接近,或许还需要 UI 方向进一步的改进。
PS :不过测评了这么久, QnA3 Web3 News 只会给出部分问题的回答,当事人并没有搞清楚触发 Web3 News 回答的条件;同时对于 Knowledge Graph 提到的第一个问题,印象中合约简单可以不需要强制写 constructor(如有错误还请纠正)
总之,除了 MinMax 这位 debug 靠演的选手, Web3 Analytics 同 QnA3 虽然各自还有一点小缺陷,但大体上也具备成为合格 debug ger 的资格。不过,既然还有小缺点,为什么不直接用 chatGPT 呢?

小结
Web3 对话 AI 模型基本具备一定的理解、生成与学习能力,也能够处理多语言回答,并充当程序员的好伙伴。这些 “基本素养” 对于当前仅仅了解基础概念,想要了解更多相关知识框架的萌新来说, Web3 对话 AI 可以生成可供参考的逻辑框架。
然而对于已经在领域深耕的人来说(或许这部分人也根本想不到要用对话机器人解决问题吧), AI 的职能似乎就仅限于做一些表格生成、概括总结之类的 “碎活”,从内容增量还是个性化观点上都无法提供进一步的参考。总之,个人认为随着人们对 Web3 领域认知逐渐增强,达到一定的临界点后,模型能提供的内容增量将逐渐趋于 0。
值得注意的是,除了本文中测评的 MinMax 、 Web3 Analytics 与 QnA3 之外,同类型的 AI 对话模型 SuperSight 目前正在进行内测,越来越多类似工具的涌现,一方面揭示了市场对于 “ AI + Web3 ” 融合趋势的重视与对用户需求的思考,另一方面,对于项目方来讲,后续做出产品特色避免 “重复造轮子” 现象,也应当放在产品迭代计划之中。然而对于目前的技术水平和全市场而言, Web3 AI 对话模型的实用性和泛用性仍有待加强,或许大规模应用还要等到人工智能技术与机器学习算法进一步增强,以及 Web3 + AI 深度融合的未来才能实现。
免责声明:作为区块链信息平台,本站所发布文章仅代表作者及嘉宾个人观点,与 Web3Caff 立场无关。本文内容仅用于信息分享,均不构成任何投资建议及要约,并请您遵守所在国家或地区的相关法律法规。