

zkEVM 一直以来都是 layer2 和以太坊扩容的圣杯,并处于区块链 &以太坊的最前沿,这一领域汇聚了很多零知识证明和工程创新,以及以太坊生态系统中所有最有才华的人。这是一个非常有趣且非常值得研究的话题,在这篇文章中,我将带领大家深入了解 zkEVM,并解释 EF 和 @Scroll_ZKP 的原生 zkEVM 架构。
作者:Luozhu 丨经作者授权发布
编译:DYan,Web3Cafff 译者
封面:Photo by Steven Lelham on Unsplash
zkEVM 的三个层级
首先并不是所有的 zkVM 都等同于 zkEVM,即使是 zkEVM 本身也分为三个层次(感谢 @drakefjustin 的研究)

第一层是 “语言层”(兼容 EVM),即将适配 EVM 的语言(例如 Solidity 或 Yul)编译成适配零知识证明的语言(例如 @zksync' zinc,和 @StarkWareLtd 的 Cairo),然后编译 Zinc 和 Cairo 代码运行在对应的虚拟机上,这可能和以太坊的 EVM 完全不同。

这种解决方案的优点是,我们可以从头开始设计一个对零知识证明兼容的虚拟机,而不受过去 EVM 设计的限制。
@gavofyork 没想到有一天 zk-snark 会用在 EVM 中,所以如果将零知识设计结构直接应用在 EVM 的很多地方,会造成巨大的开销,尤其是运行 Keccak 哈希算法和 MPT 算法时,详情参考 @yezhang1998 的文章 https://hackmd.io/@yezhang/S1_KMMbGt。这些缺点导致开发者很难获得最佳的开发体验,这些 zkVM 在底层使用自己语言的指令集,且不能支持很多重要的 EVM 操作码。
因此,开发者要想获得最佳的开发体验,他们可能需要学习这些 zkVM 自带语言(如 Cairo),这可能会导致 zk-Rollup 无法直接继承 Layer1 生态,并且 Layer2 开发者也因为开发语言问题而无法顺利编码。
第二个层级是 “字节码级别”(等同于 EVM),既可以在 solidity 语言级别实现兼容,又可以在 EVM 操作码级别实现完全兼容,只有达到字节码级别兼容,才能称为 “zkEVM”。在 zkEVM 基础上,solidity 开发者可以获得最佳的开发体验,L1 应用和开发工具基本可以不加修改地迁移到 L2,现阶段的 @Scroll_ZKP 和 EF 原生 zkEVM 的(包括 @ConsenSys 和 @0xPolygonHermez 的努力),都是针对字节码级别的 zkEVM。
第三层是 “共识层”,也是最终的 zkEVM,它不仅将在语言和字节码层面实现兼容性,而且在共识层面也实现了兼容性。当实现共识层兼容后,每个矿工在生成区块时都会为此区块生成一个证明,当所有节点同步时,只需要验证生产的证明是否有效,无需重新计算所有交易。并且基于 Halo2 算法 的递归证明,可以用一个证明来验证整个区块的历史是有效的,那时同步节点甚至不需要验证每一个证明,只需要验证最后一个证明就可以接入网络。

从长远来看,当同步一个以太坊节点只需几分钟甚至几秒钟,任何人都可以轻松加入以太坊网络时,以太坊将变得更加去中心化和可靠,我真的很期待看到它发生。
所以 zkEVM 的最终目标其实就是把它应用到 L1 上,取代我们现在的 EVM(非常有野心!)。这也是 EF (@PrivacyScaling), @Scroll_ZKP 和我们一起努力的最终目标,详情见 @VitalikButerin 发送的以太坊路线图的最后部分—“zk-snark Everything”,我相信 @VitalikButerin 和 @barrywhitehat 也会探索堆栈解决方案。
零知识证明
是什么让 zkEVM 即将发生
有很多密码学突破可以让 zkEVM 从想象变为现实,其中最重要的就是 Plonk 算法和 Halo2 算法,详情可以看 @Zac_Aztec 这个帖子,他也是 Plonk 算法 和 @aztecnetwork 的创始人。
Plonk 算法是基于 Sonic 结合数学多项式的创新
基于 Sonic 算法,Plonk 有一个 “通用且可更新” 的可信设置,即只需要一个设置,然后就可以重复使用,并且基于多项式推导(非常漂亮的数学公式),我们可以使用表现项更直观的 PLONKish 算法,这比 groth16 和其他 zk-snark 证明方案使用的 R1CS 算法更好,更多信息请见 https://www.youtube.com/watch?v=bz16BURH_u8
zkEVM 也使用了 Plonkish 的两个非常重要的特性,即 “自定义门” 和 “查找表参数”。
Plonk 的这两个特性让我们可以编写高度自定义的约束条件,这对减少算法的开销很有帮助(后面你会发现,我们经常在原生 zkEVM 架构中使用这两个特性)。https://www.youtube.com/watch?v=Vdlc1CmRYRY 感谢 @zeroknowledgefm 积累了这么多的零知识证明的资源,让大家了解零知识证明背后的神奇魔力和奇妙的数学。
原生 zkEVM 架构
正如我们之前提到的,Native zkEVM 不仅会在 zk-Rollup 中使用,而且也会取代我们现在的 L1 EVM,成为 L1 zkEVM,所以它的设计/代码和架构非常值得学习(也是最前沿的创新!)
众所周知的 EVM 本质上是一个状态机,通过交易驱动 state1 到 state2,所以可以理解为驱动最小状态变化的操作是一个事务(其实就是 trace)。
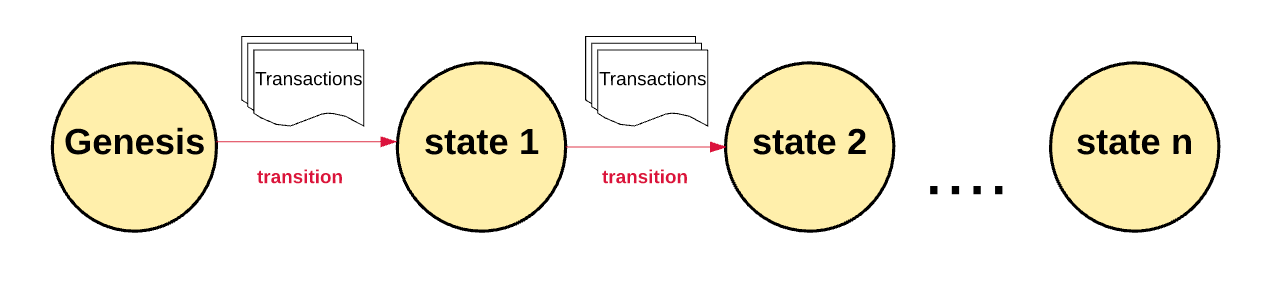
如果我们可以得到交易并约束/证明它们,那么就可以约束/证明整个状态机。
zkEVM 的基本思想是创建一个 EVM 架构来约束 EVM(状态机)并证明 EVM 的所有执行逻辑是正确的,这个 EVM 架构可以获取所有交易,以及该交易调用的每个特定操作码,然后证明每笔交易,以及每笔交易调用的所有操作码,操作码的操作逻辑,甚至操作顺序,都是完全正确的。

但在我们的实际操作时,我们发现如果只用一个架构(EVM 架构)去约束 EVM,这个架构会变得非常庞大,最后会增加不必要的复杂度和开销,所以我们根据 EVM 的不同模块设计了不同的子架构/表格查询,当需要证明时,我们只需要查询对应的表(一个表大概是这个样子,根据需求填写不同的变量)。
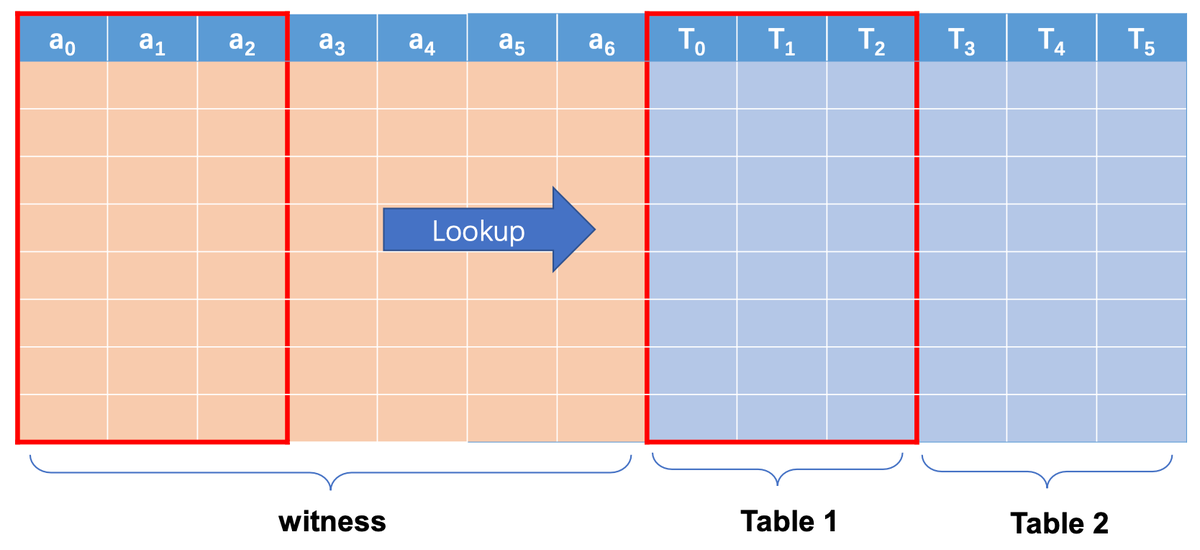
比如是内存/堆栈/存储 读&写的逻辑,EVM 架构会查询状态表,如果是涉及操作码的操作,EVM 架构会查询字节码表,同理,事务和区块会分别查询事务和区块表。
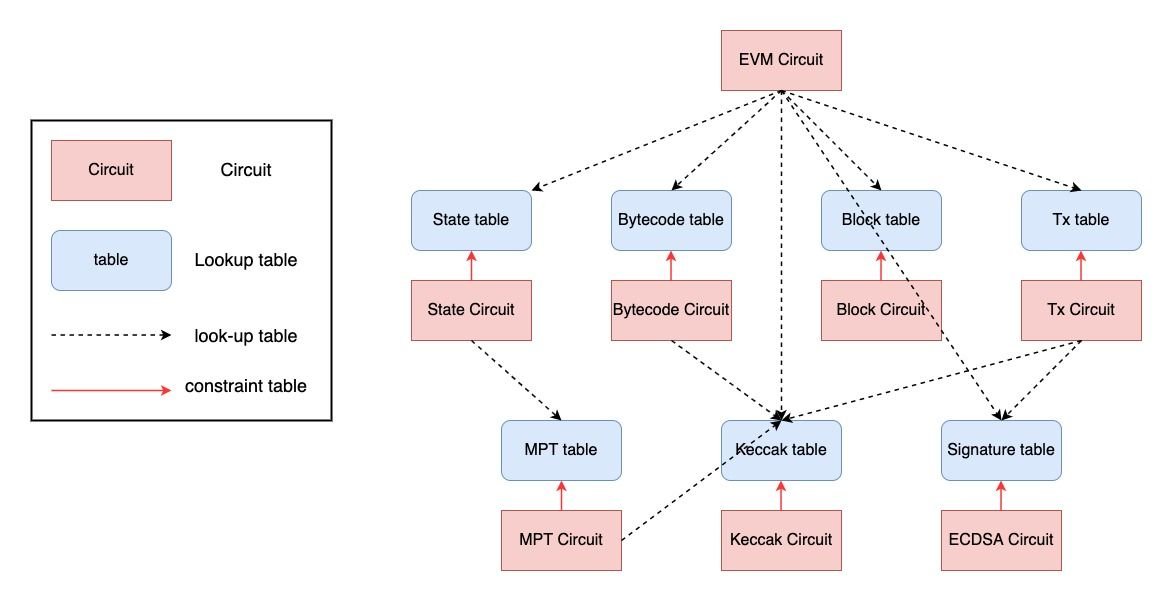
这里状态架构在约束存储相关操作(状态表)时需要操作 MPT,所以查询对应的 MPT 表,交易架构在计算哈希和交易签名验证时,也需要查询对应的 Keccak 表和 Sig 表。
这个表不是固定的,而是根据不同的操作填入不同的值(这也是 zkEVM 能变得通用的原因之一),所以证明者有能力填写虚假值来伪造一个无效的表。因此,为了保证查询表格的正确性,我们为每个表格设计了一个架构,每个架构与对应表格都有一些特定的多项式约束,以保证表格完全正确。
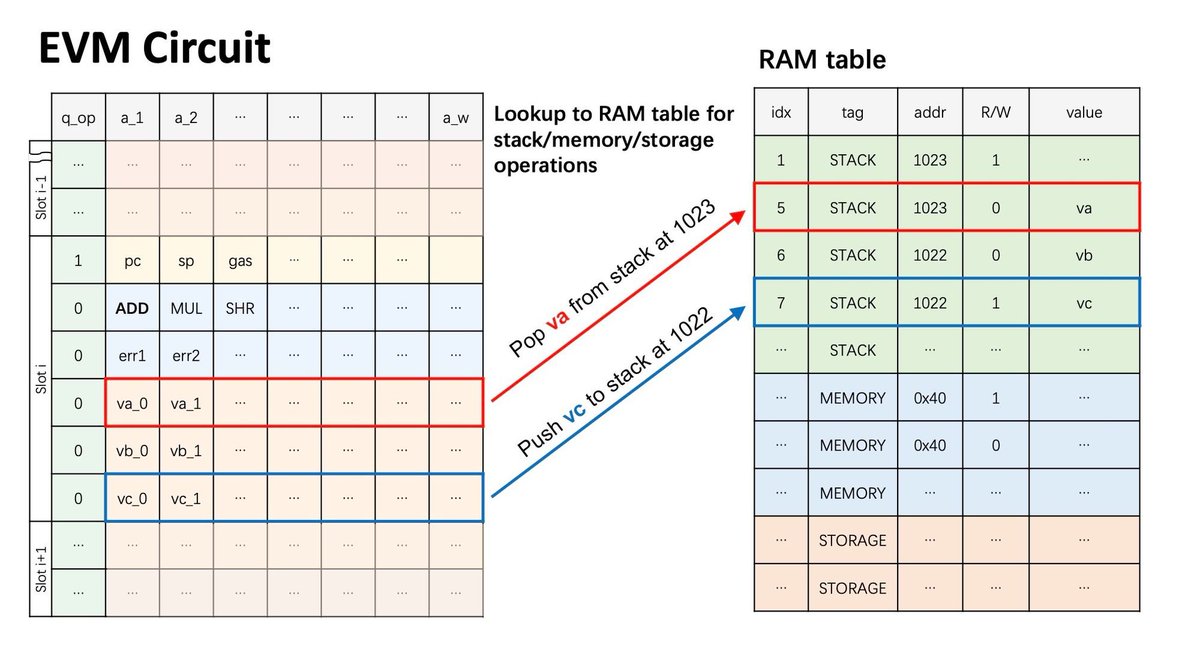
当一个事务进入 EVM 架构时,它所涉及的所有操作(操作码、堆栈/存储等)都会被重新排序,然后分配给不同的子架构,这些子架构将证明这些操作的正确性并生成证明。最后,这些子架构生成的证明将输入到聚合架构中,聚合架构将这些单个证明转变为聚合证明。

之后就可以将聚合证明发送到 L1 合约来验证证明的有效性,这也是 Scroll 在高级别架构的工作流程。

结束和开始
zkEVM 是 “zk Everything” 的里程碑,只有在实用的 zk-proving 系统成熟之后才能出现的创新,在研究 zkEVM 的过程中,我对它背后的数学机制印象深刻,我相信零知识证明是一个巨大的创新,我们正处于这个创新的最前沿。
免责声明:作为区块链信息平台,本站所发布文章仅代表作者及嘉宾个人观点,与 Web3Caff 立场无关。文章内的信息仅供参考,均不构成任何投资建议及要约,并请您遵守所在国家或地区的相关法律法规。














