

本文中提到的这些技术改进为以太坊的去中心化和轻量化验证奠定了基础,逐步实现低资源设备也能运行完全验证节点的目标,使得网络更安全、易于访问。
原文:Possible futures of the Ethereum protocol, part 4: The Verge(vitalik.eth)
作者:vitalik.eth
编译:lllu_23,LXDAO
封面:Photo by Shubham Dhage on Unsplash
译者前言
为了实现更广泛的去中心化与可验证性,以太坊在不同历史时期提出并尝试了多种技术路径,直至 2023 年, The Verge 路线图逐步明确了无状态验证(Stateless verification)、EVM 执行的有效性证明(Validity proofs of EVM execution)和共识的有效性证明(Validity proofs of consensus)等核心技术。无状态验证引入了 Verkle 树以优化数据存储效率,这使得以太坊客户端在不存储完整状态的情况下也能验证区块。EVM 执行的有效性证明则让用户只需下载区块或部分数据即可验证执行的正确性,减少了验证复杂度。共识层的有效性证明则确保在权益证明(PoS)机制下的交易、签名和验证器操作的正确性,提升共识验证的效率并减少完全验证节点的计算负担。
本文中提到的这些技术改进为以太坊的去中心化和轻量化验证奠定了基础,逐步实现低资源设备也能运行完全验证节点的目标,使得网络更安全、易于访问。
本文概述
本文共约 10,000 字,分为 3 个部分,阅读完预计需要 50 分钟。
- 无状态验证:Verkle 或 STARKs
- EVM 执行的有效性证明
- 共识的有效性证明
正文内容
《以太坊协议可能的未来(四):The Verge》
特别感谢 Justin Drake、Hsia-wei Wang、Guillaume Ballet、Ignacio、Josh Rudolf、Lev Soukhanov、Ryan Sean Adams 和 Uma Roy 的反馈和审阅。
区块链最强大的功能之一就是任何人都可以在自己的计算机上运行一个节点,并验证链的正确性。即使 95% 的运行链共识(PoW、PoS......)的节点都立即同意更改规则,并开始根据新规则生产区块,每个运行完全验证节点的人都可以拒绝接受该链。不属于这些共谋集团的质押者会自动聚集在一起,继续构建一条继续遵循旧规则的链,而完全验证的用户也会遵循这条链。
这是区块链与中心化系统的关键区别。然而,要使这一特性成立,需要有足够多的人来运行完全的验证节点。这既适用于质押者(因为如果质押者不验证链,他们实际上就没有为协议的执行规则做出贡献),这也适用于普通用户。如今,在消费级笔记本电脑(包括写这篇文章时使用的笔记本电脑)上运行节点是可能的,但要做到这一点却很困难。The Verge 的目标是改变这种现状,让完全验证链的计算成本变得更加低廉,以至于每个手机钱包、浏览器钱包甚至智能手表都可以默认进行验证。
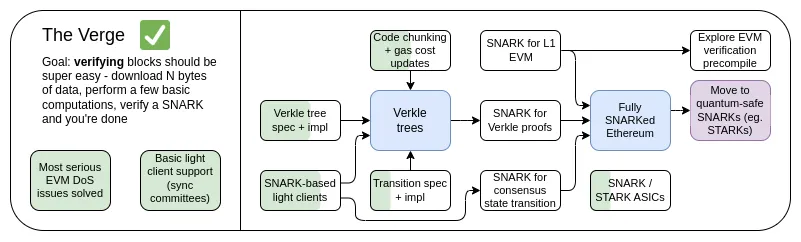
最初,"Verge" 指的是将以太坊的状态存储转移到 Verkle 树上—— Verkle 树结构允许更紧凑的证明,从而实现以太坊区块的无状态验证。节点可以验证一个以太坊的区块,而无需在其硬盘上存储任何以太坊状态(账户余额、合约代码、存储空间等......),其代价是花费几百 KB 的证明数据和几百毫秒的额外时间来验证一个证明。如今,Verge 代表了一个更大的愿景,专注于实现以太坊链的最大资源效率验证,其中不仅包括无状态验证技术,还包括使用 SNARK 来验证所有以太坊执行。
除了增加对 SNARK 验证整个链的长期关注外,另一个新问题与 Verkle 树是否是最好的技术有关。Verkle 树很容易受到量子计算机的攻击,因此如果我们用 Verkle 树取代当前的 KECCAK Merkle Patricia 树,以后就必须再次更换树。默克尔(Merkle)树的自然替代方案是直接跳过二叉树,使用默克尔分支的 STARK。从历史上看,由于开销和技术复杂性,这种方法一直被认为是不可行的。但最近,我们看到 Polygon 在一台笔记本电脑上用 circle STARKs 每秒证明了 170 万个波塞冬(Poseidon)哈希值,而且由于采用了 GKR 等技术,更多 “传统” 哈希值的证明时间也在被迅速缩短。
因此,在过去的一年里,The Verge 变得更加开放,有了更多的可能性。
The Verge :关键目标
- 无状态客户端:完全验证客户端和质押节点不需要超过几 GB 的存储空间
- (长期目标)在智能手表上完全验证链(共识和执行)。载入一些数据,验证一个 SNARK,即可完成验证。
本章内容
- 无状态验证:Verkle 或 STARKs
- EVM 执行的有效性证明
- 共识的有效性证明
无状态验证:Verkle 或 STARKs
我们要解决什么问题?
如今,以太坊客户端需要存储数百 GB 的状态数据才能验证区块,而且这一数量每年都在增加。原始状态数据每年增加约 30 GB,单个客户端必须在此基础上存储一些额外的数据,才能有效地更新 trie。
这就减少了能够运行完全验证以太坊节点的用户数量:尽管有足够大的硬盘来存储所有以太坊状态,甚至是多年的历史数据,但人们默认购买的电脑往往只有几百 GB 的存储空间。状态大小也给首次建立节点的过程带来了极大的阻力:节点需要下载整个状态,这可能需要数小时或数天的时间。这会产生各种连锁反应。例如,它大大增加了质押者升级其节点设置的难度。从技术上讲,可以在不停机的情况下做到这一点——启动一个新客户端,等待它同步,然后关闭旧客户端并转移密钥——但在实践中,技术上会很复杂。
无状态验证是什么,它是如何运作的?
无状态验证是一种允许节点在没有整个状态的情况下验证区块的技术。相反,每个区块都有一个见证者,其中包括(i)区块将访问的状态中特定位置的值(例如代码、余额、存储),以及(ii)这些值的加密证明是正确的。
实际上,要实现无状态验证,需要改变以太坊的状态树结构。这是因为当前的 Merkle Patricia 树对于任何加密证明方案的实现都是极其不友好的,特别是在最坏的情况下。这不仅适用于 “原始” 默克尔树的分支,也适用于将默克尔树的分支 “封装” 在 STARK 中的可能性。关键的困难源于 MPT 的两个弱点:
这是一个十六叉树(即每个节点有 16 个子节点)。这意味着,在平均情况下,一个大小为 N 的树的证明有 32 * (16 - 1) * log16(N) = 120 * log2(N) 字节,在 2 项的树中约为 3840 字节。对于二叉树,你只需要 32 * (2 - 1) * log2(N) = 32 * log2(N) 字节,即大约 1024 字节。
代码没有默克尔化。这意味着证明任何账户代码的访问都需要提供整个代码,最多 24000 字节。
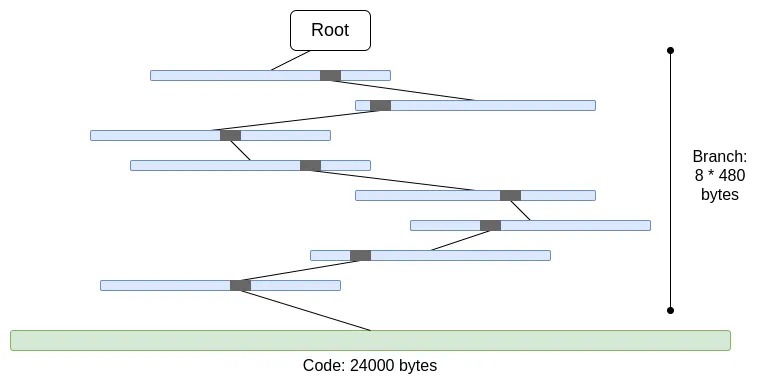
我们可以计算出最坏的情况,如下所示:
30,000,000 gas / 2,400(“冷” 账户读取成本)* (5 * 480 + 24,000) = 330,000,000 字节
分支成本略有降低(5 * 480 而不是 8 * 480),因为分支较多时,分支的顶端部分会重复出现。但即便如此,在一个时隙内下载完这些数据,也是完全不切实际的。如果我们尝试用 STARK 将其封装起来,就会遇到两个问题:(i) KECCAK 对 STARK 相对不友好;(ii) 330 MB 的数据意味着我们必须证明对 KECCAK 轮函数的 500 万次调用,即使我们能大幅提高 STARK 证明 KECCAK 的效率,但对于除最强大的消费级硬件之外的所有硬件来说都是无法证明的。
如果我们用二叉树替换十六叉树,并对代码进行额外的默克尔化处理,那么最坏的情况大约为 30,000,000 / 2,400 * 32 * (32 - 14 + 8) = 10,400,000 字节(14 是对大约 2^14 个分支的冗余位进行的减法,而 8 则是进入代码块中叶子的证明的长度)。需要注意的是,这需要改变 gas 成本,对访问每个单独的代码块收费;EIP-4762 就是这样做的。10.4 MB 要好得多,但对于许多节点来说,在一个时隙内下载的数据仍然太多。因此,我们需要引入一些更强大的技术。在这方面,有两种领先的解决方案:Verkle 树和 STARKed 二进制哈希树。
Verkle 树
Verkle 树使用基于椭圆曲线的向量承诺来进行更短的证明。关键在于,无论树的宽度如何,每个父子关系对应的证明部分都只有 32 字节。证明树的宽度的唯一限制是,如果证明树过宽,其证明的计算效率就会降低。针对以太坊提出的实现方案宽度为 256。
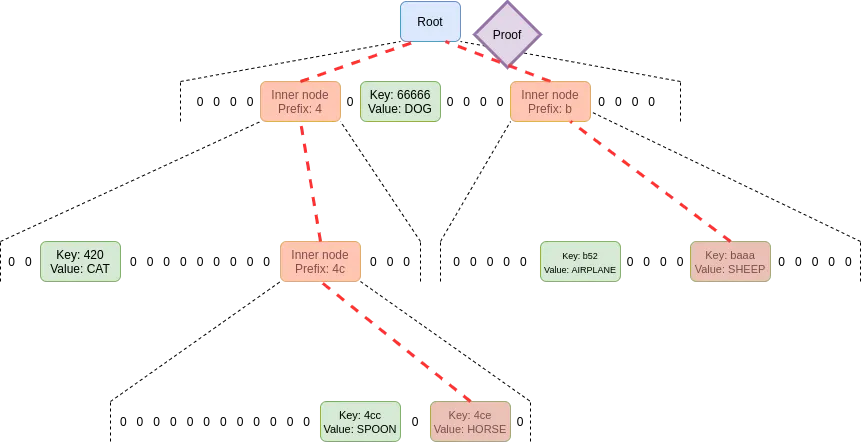
因此,证明中一个分支的大小为 32 * log256(N) = 4 * log2(N) 字节。因此,理论上的最大证明大小大约为 30,000,000 / 2,400 * 32 * (32 - 14 + 8) / 8 = 1,300,000 字节(由于状态块的分布不均匀,实际计算结果略有不同,但作为初步近似值是可以的)。
另外需要注意的是,在上述所有示例中,这种 “最坏情况” 并不 完全 是最坏情况:更坏的情况是攻击者故意 “挖掘” 两个地址,使其在树中具有较长的共同前缀,并从其中一个地址读取数据,这会将最坏情况下的分支长度再延长约 2 倍。不过,即使考虑到这一点,Verkle 树也能让我们在最坏情况下获得 2.6 MB 的证明,这与目前最坏情况下的 calldata 大小基本相同。
我们还利用这一注意事项做了另一件事:我们让访问 “相邻” 存储空间的费用变得非常低廉:无论是相同合约的许多代码块,还是相邻的时隙。EIP-4762 提供了 “相邻” 的定义,相邻访问只收取 200 gas 的费用。通过相邻访问,最坏情况下的证明大小变为 30,000,000 / 200 * 32 = 4,800,800 字节,仍在可以接受的范围内。如果为了安全起见,我们希望减小这一数值,可以稍微提高相邻访问成本。
STARKed 二进制哈希树
这项技术的原理不言自明:你只需构建一棵二叉树,取出需要证明块中值最大为 10.4 MB 的证明,并用证明的 STARK 来替代该证明。这使得证明本身仅由被证明的数据和来自实际 STARK 的大约 100-300 kB 的固定开销组成。
这里的主要挑战是验证时间。我们可以进行与上述基本相同的计算,只不过我们计算的不是字节数,而是哈希次数。一个 10.4 MB 的区块意味着 330,000 次哈希。如果再加上攻击者 “挖掘” 地址树中具有较长公共前缀的可能性,真正的最坏情况将变成约 660,000 次哈希。因此,如果我们每秒可以证明大约 200,000 次哈希,就没有问题了。
这些数字在一台使用 Poseidon 哈希函数的消费类笔记本电脑上已经达成,而 Poseidon 哈希函数是专门为 STARK 友好性而设计的。然而,Poseidon 还相对不成熟,因此很多人尚不信任它的安全性。因此,目前有两条现实的前进道路:
- 快速对 Poseidon 进行大量安全分析,并对其安全性感到足够放心,以便在 L1 进行部署。
- 使用更 “保守” 的哈希函数,如 SHA256 或 BLAKE。
截至目前,Starkware 的 circle STARK 证明器在消费级笔记本电脑上仅能以每秒 10,000 到 30,000 次哈希的速度进行证明,前提是它们在证明保守哈希函数。然而,STARK 技术正在快速进步。即使在今天,基于 GKR 的技术显示出在潜在地将这个速度提升到大约 100,000 到 200,000 范围的潜力。
除验证区块外的见证使用案例
除了验证区块外,还有其他三个关键用例需要更高效的无状态验证:
- 内存池:当交易被广播时,P2P 网络中的节点需要在重新广播之前验证交易是否有效。如今,验证包括验证签名,还包括检查余额是否充足和 nonce 是否正确。在未来(例如,使用本机帐户抽象,如 EIP-7701),这可能涉及运行一些 EVM 代码,这些代码执行一些状态访问。如果节点是无状态的,则事务需要附带证明状态对象的证明。如果节点是无状态的,交易需要附带证明,证明状态对象的有效性。
- 包含列表:这是一项拟议功能,允许(可能规模较小且不成熟的)权益证明验证者强制下一个区块包含交易,而不管(可能规模较大且成熟的)区块构建者的意愿。这将削弱有权势者通过延迟交易来操纵区块链的能力。不过,这需要验证者有办法验证包含列表中交易的有效性。
- 轻客户端:如果我们希望用户通过钱包(如 Metamask、Rainbow、Rabby......)访问链而无需信任中心化实体,他们需要运行轻客户端(如 Helios)。Helios 的核心模块为用户提供经过验证的状态根。然而,为了获得完全无信任的体验,用户需要为他们所做的每个 RPC 调用提供证明(例如,对于 eth_call 请求,用户需要证明在调用过程中访问的所有状态)。
所有这些用例都有一个共同点,那就是它们需要相当多的证明,但每个证明都很小。因此,STARK 证明对它们并没有实际意义;相反,最现实的做法是直接使用默克尔分支。默克尔分支的另一个优点是可更新:给定一个以区块 B 为根的状态对象 X 的证明,如果收到子区块 B2 及其见证,就可以更新证明,使其以区块 B2 为根。Verkle 证明也是原生可更新的。
与现有研究有哪些联系?
Verkle trees:
https://vitalik.eth.limo/general/2021/06/18/verkle.html
John Kuszmaul 的原版 Verkle 树论文:
https://math.mit.edu/research/highschool/primes/materials/2018/Kuszmaul.pdf
Starkware 证明数据:
https://x.com/StarkWareLtd/status/1807776563188162562
Poseidon2 论文:
https://eprint.iacr.org/2023/323
Ajtai(基于点阵难度的替代快速哈希函数):
https://www.wisdom.weizmann.ac.il/~oded/COL/cfh.pdf
Verkle.info:https://verkle.info/
还有什么要做,需要权衡什么
剩下的主要工作是:
- 关于 EIP-4762 后果的更多分析(无状态 gas 成本变化)
- 完成和测试过渡程序的更多工作,这在任何无状态 EIP 的复杂性中占据了很大一部分。
- 对 Poseidon、Ajtai 和其他 "STARK-friendly" 哈希函数的更多安全分析
- 为 “保守”(或 “传统”)的哈希函数开发更多超高效率的 STARK 协议,例如基于 Binius 或 GKR 的想法。
此外,我们很快就会围绕下面三种选项之进行决策:(i) Verkle 树,(ii) STARK 友好哈希函数,以及 (iii) 保守哈希函数。它们的特性可大致归纳在下表中:
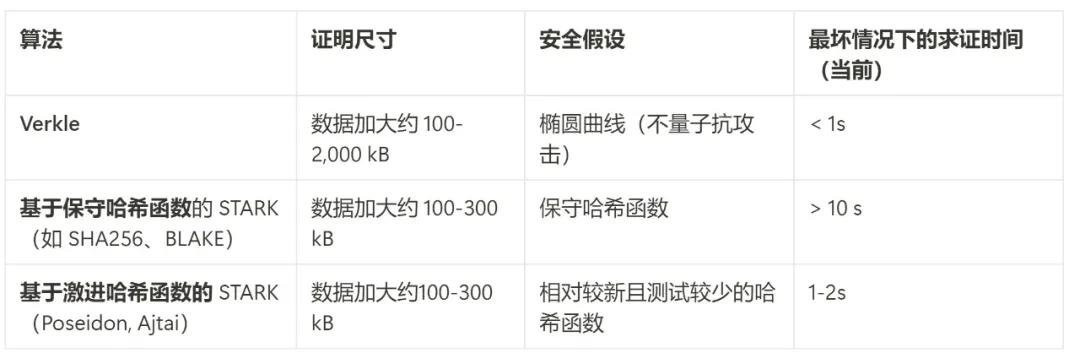
除了以上提到的几点外,还有其他一些重要的考虑因素:
- 如今,Verkle 树代码已经相当成熟。除了 Verkle 之外,使用其他任何代码都会推迟部署,很可能会推迟到一个硬分叉。这也没有关系,尤其当如果我们需要额外的时间来进行哈希函数分析或验证者的实现,并且还有其他重要的功能想要更早地纳入以太坊中时。
- 使用哈希值更新状态根比使用 Verkle 树更快。这意味着基于哈希值的方法可以降低全节点的同步时间。
- Verkle 树具有有趣的见证更新属性-Verkle 树见证是可更新的。这个属性对内存池、包含列表和其他用例都很有用,而且还有可能有助于提高实现效率:如果更新了状态对象,就可以更新倒数第二层的见证,而无需读取最后一层的内容。
- Verkle 树更难进行 SNARK 证明。如果我们想把证明大小一直减小到几千字节,Verkle 证明就会带来一些困难。这是因为 Verkle 证明的验证引入了大量 256 位操作,这就要求证明系统要么有大量开销,要么本身有一个包含 256 位的 Verkle 证明的定制化内部结构。这对无状态本身不是问题,但会在后续带来更多困难。
如果我们想要以量子安全且合理高效的方式获得 Verkle 见证的可更新性,另一种可能的途径是基于点阵的默克尔树。
如果证明系统最终在最坏情况下不够高效,我们还可以用多维 gas 来弥补这种不足:(i) calldata、(ii) 计算、(iii) 状态访问以及可能的其他不同资源设定不同的 gas 限制。多维 gas 增加了复杂性,但作为交换,它更严格地限制了平均情况与最坏情况之间的比例。有了多维 gas ,理论上需要证明的最大分支数可能会从 30,000,000 / 2400 = 12,500 减少到例如 3000。这样,即使在今天,BLAKE3 也可以(勉强)满足要求,而无需进一步改进证明器。
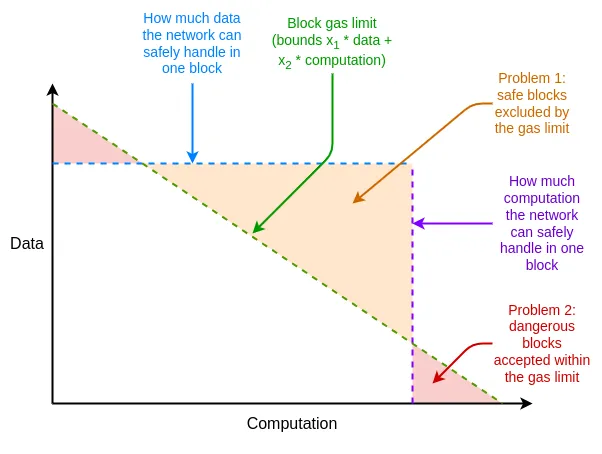
另一个 “灵机一动” 的提议是将状态根计算延迟到区块之后的时隙。这样,我们就有整整 12 秒的时间来计算状态根,这意味着即使在最极端的情况下,每秒也有约 60,000 次哈希,证明时间是足够的,这再次处于 BLAKE3 勉强够用的范围。
这种方法的缺点是会增加轻客户端的延迟一个时隙,不过也有更巧妙的技术,可以将这种延迟减少到 仅 为证明生成延迟。例如,证明可以在任何节点生成后立即在网络上广播,而不是等待下一个区块。
它与路线图的其他部分如何互动?
解决了无状态问题之后,就能大大提高单独质押(solo staking)的便捷性。如果有技术能降低单独质押的最低平衡,如 Orbit SSF 或小组质押(squad staking)等应用层策略,这将变得更有价值。
如果同时引入 EOF,多维 gas 就会变得更加便捷。这是因为多维 gas 执行的主要复杂性在于处理不传递父调用全部 gas 的子调用,而 EOF 只需将此类子调用设为非法,就能使这一问题变得微不足道(并且本机帐户抽象将为当前部分 gas 子调用的主要用例提供协议内替代方案)。
另一个重要的协同作用是无状态验证与历史过期之间的关系。如今,客户端必须存储近 1TB 的历史数据;这些数据比状态大几倍。即使客户端是无状态 的,除非我们能解除客户端存储 历史数据 的责任,否则近乎无存储的客户端的梦想将无法实现。这方面的第一步是 EIP-4444,它还意味着以 torrent 或 Portal 网络的形式存储历史数据。
EVM 执行的有效性证明
我们要解决什么问题?
以太坊区块验证的长期目标很明确:你应该能够通过以下方式验证以太坊区块:(i) 下载区块,或者甚至只下载区块中数据可用性采样的一小部分;(ii) 验证区块有效的一个小证明。这将是一个资源占用极低的操作,可以在移动客户端、浏览器钱包,甚至(没有数据可用性部分)在另一条链上完成。
实现这一目标需要对(i)共识层(即权益证明)和(ii)执行层(即 EVM)进行 SNARK 或 STARK 证明。前者本身就是一个挑战,应该在进一步不断改进共识层(如最终确定性)的过程中加以解决。后者需要 EVM 执行证明。
EVM 执行的有效性证明是什么,它是如何工作的?
从形式上看,在以太坊规范中,EVM 被定义为一个状态转换函数:你有一个前状态 S、一个区块 B,你正在计算一个后状态 S' = STF(S,B)。如果用户使用的是轻客户端,他们并不完整地拥有 S 和 S',甚至也不拥有 B;相反,他们拥有一个前状态根 R、一个后状态根 R' 和一个区块哈希值 H,需要证明的完整声明大致如下:
- 公共输入:前状态根 R、后状态根 R'、区块哈希 H
- 私人输入:区块主体 B、区块访问的状态中的对象 Q、执行区块后的相同对象 Q’、状态证明(如默克尔分支)P
- 声明 1:P 是一个有效证明,表明 Q 包含由 R 表示的状态的某些部分。
- 声明 2:如果你对 Q 执行 STF,(i)执行仅访问 Q 内部的对象,(ii)区块是有效的,且(iii)结果是 Q’。
- 声明 3:如果利用 Q'和 P 的信息重新计算新的状态根,就会得到 R'
如果存在这种情况,您就可以拥有一个完全验证以太坊 EVM 执行的轻型客户端。这使得客户端在资源使用上相对低效。要实现真正完全验证的以太坊客户端,还需要在共识方面做同样的工作。
目前,针对 EVM 计算的有效性证明的实现已经存在,并且被二层网络广泛使用。然而,要使 EVM 有效性证明在 L1 上可行,仍然需要做很多工作。
与现有研究有哪些联系?
EF PSE ZK-EVM(现已停用,因为有更好的选择) :
https://github.com/privacy-scaling-explorations/zkevm-circuits
Zeth,其工作原理是将 EVM 编译到 RISC-0 ZK-VM 中:https://github.com/risc0/zeth
ZK-EVM 形式化验证项目:
还有什么要做,需要权衡什么?
目前,EVM 的有效性证明在两个维度上是不足的:安全性和验证时间。
一个安全的有效性证明涉及确保 SNARK 实际上验证了 EVM 的计算,并且不存在漏洞。提高安全性的两种主要技术是多验证者和形式化验证。多验证者意味着有多个独立编写的有效性证明实现,类似于存在多个客户端,如果一个区块被这些实现的足够大的子集证明,客户端就会接受该区块。形式验证涉及使用通常用于证明数学定理的工具,如 Lean4,来证明有效性证明只接受正确执行底层 EVM 规范(如 EVM K 语义 或用 python 编写的以太坊执行层规范 (EELS))的输入。
足够快的验证时间意味着任何以太坊区块都能在大约 4 秒内得到验证。如今,我们距离这个目标仍然很远,尽管我们比两年前想象的要接近得多。为了实现这个目标,我们需要在三个方向上进行推进:
并行化 - 目前最快的 EVM 验证者可以在约 15 秒内证明一个普通 的以太坊区块。它通过在数百个 GPU 之间进行并行化,在最后将它们的工作聚合在一起实现的。从理论上讲,我们完全知道如何制造一个能在 O(log(N)) 时间内证明计算的 EVM 验证者:让一个 GPU 执行每一个不知,然后构建一个 “聚合树”:
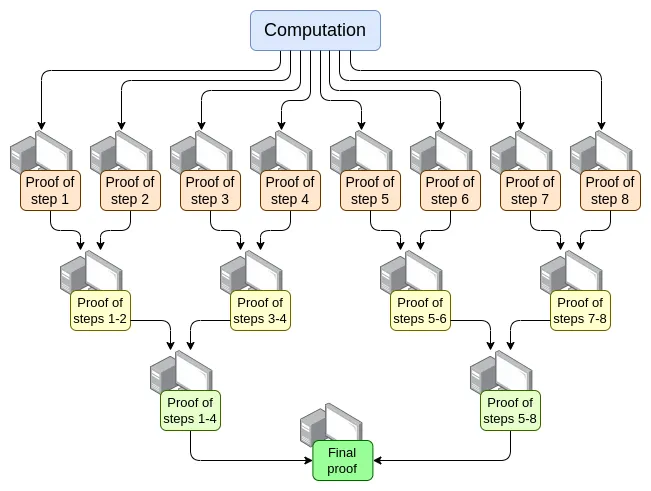
在实现这一点上存在挑战。为了在最坏情况下有效工作,即使一个非常大的交易占用整个区块,计算也不能按每个交易(per-tx)进行拆分;它必须按操作码(per-opcode)进行(无论是 EVM 的操作码还是底层虚拟机如 RISC-V 的操作码)。要确保虚拟机的 “内存” 在证明的不同部分之间保持一致,是实现过程中的一个关键挑战。不过,如果我们能 够 进行这种递归证明,那么我们就知道,即使在其他方面没有任何改进,至少证明器的延迟问题已经解决了。
- 证明系统优化——像新的证明系统,如 Orion、Binius、GKR 等,很可能再次大幅缩短通用计算的证明器时间。
- EVM gas 成本的其他变化——EVM 中的许多东西都可以优化,使其更有利于证明者,尤其是在最坏的情况下。如果攻击者可以构建一个阻塞证明者十分钟时间的区块,那么仅能在 4 秒内证明一个普通的以太坊区块是不够的。所需的 EVM 变更可大致分为两类:
- gas 成本的变化——如果一个操作需要很长时间才能证明,那么即使它的计算速度相对较快,也应该有很高的 gas 成本。EIP-7667 是为处理这方面糟糕问题而提出的一个 EIP:它大大增加了作为相对便宜的操作码和预编译的(传统)哈希函数的 gas 成本。为了弥补这些 gas 成本的增加,我们可以降低证明成本相对较低的 EVM 操作码的 gas 成本,从而保持平均吞吐量不变。
- 数据结构替换——除了用对 STARK 更友好的方法替换状态树外,我们还需要替换交易列表、收据树和其他证明成本高昂的结构。Etan Kissling 提出的将交易和收据结构移至 SSZ 的 EIP([1] [2] [3])就是朝着这个方向迈出的一步。
除此之外,上一节提到的两种更优的解决方案(多维 gas 和延迟状态根)也能在这方面提供帮助。值得注意的是,与无状态验证不同的是,在无状态验证中,无论使用哪种更优的技术,都意味着我们已经拥有足够的技术来完成我们当前 所需的工作,而即使采用这些技术,完整的 ZK-EVM 验证也需要更多的工作——只是需要的工作更少 而已。
上文没有提到的一点是证明器硬件:使用 GPU、FPGA 和 ASIC 更快地生成证明。Fabric Cryptography、Cysic 和 Accseal 这三家公司在这方面走在了前沿。这对 Layer 2 来说极具价值,但不太可能成为 Layer 1 的决定性考虑因素,因为人们强烈希望 Layer 1 保持高度去中心化,这意味着证明的生成必须在以太坊用户能力的合理范围内,而不应受到单个公司硬件的瓶颈制约。Layer 2 可以做出更积极的权衡。
在这些领域中,还有更多的工作要做:
- 并行化证明要求证明系统的不同部分可以 “共享内存”(如查找表)。我们知道这样做的技术,但需要将其付诸实施。
- 我们需要进行更多的分析,以找出理想的 gas 成本变化集,从而最大限度地减少在最坏情况下的验证时间。
- 我们需要在证明系统方面开展更多工作。
这里可能需要权衡的因素包括:
安全性与验证时间:如果选择更激进的哈希函数、更复杂的证明系统或更激进的安全假设或其他设计方案,就有可能缩短验证时间。
去中心化与证明者时间:社区需要就证明者硬件的 “规格” 达成一致。是否可以要求证明者是大规模实体?我们希望高端消费级笔记本电脑能在 4 秒内证明一个以太坊区块吗?介于两者之间的情况呢?
打破向后兼容性的程度:其他方面的不足可以通过更积极的 gas 成本变化来弥补,但这更有可能不成比例地增加某些应用程序的成本,迫使开发人员重写和重新部署代码,以保持经济可行性。同样,这两种更优的解决方案也有其自身的复杂性和弊端。
它与路线图的其他部分如何互动?
实现 Layer 1 网络 EVM 有效性证明所需的核心技术在很大程度上与其他两个领域共享:
- Layer 2 的有效性证明(即 "ZK Rollup")
- “STARK 二进制哈希证明” 方法以实现无状态性
成功实现 Layer 1 的有效性证明将使得简单的单点质押变得极其容易:即使是最弱的计算机(包括手机或智能手表)也能进行质押。这进一步提高了解决单点质押的其他限制(如 32 ETH 最低限额)。
此外,Layer 1 的 EVM 有效性证明可使 Layer 1 gas 限值大幅提高。
共识的有效性证明
我们要解决什么问题?
如果我们想用 SNARK 完全验证一个以太坊区块,那么 EVM 的执行并不是我们唯一需要证明的部分。我们还需要证明——共识 :系统中处理存款、取款、签名、验证者余额更新的部分,以及以太坊权益证明部分的其他元素。
共识比 EVM 简单得多,但它面临的挑战是,我们没有 Layer 2 EVM Rollup,无论如何大部分工作都必须要完成。因此,任何证明以太坊共识的实现都需要 “从头开始”,尽管证明系统本身是可以在其基础上构建的共享工作。
共识的有效性证明是什么,它是如何工作的?
信标链被 定义为一个状态转换函数,就像 EVM 一样。状态转换函数主要由三部分组成:
- ECADD(用于验证 BLS 签名)
- 配对(用于验证 BLS 签名)
- SHA256 哈希(用于读取和更新状态)
在每个区块中,我们都需要为每个验证者证明 1-16 个 BLS 12-381 ECADD(可能不止一个,因为签名可能包含在多个集合中)。这可以通过子集预计算技术来弥补,因此我们可以说每个验证者只需证明一个 BLS 12-381 ECADD。目前,每个时隙有大约 30,000 个验证者签名。未来,随着最终确定性的实现,这种情况可能会向两个方向发生变化(参见此处的阐述):如果我们采取 “暴力破解” 路线,每个时隙的验证者数量可能会增加到 100 万。与此同时,如果采用 Orbit SSF,则会保持在 32,768 个,甚至减少到 8,192 个。
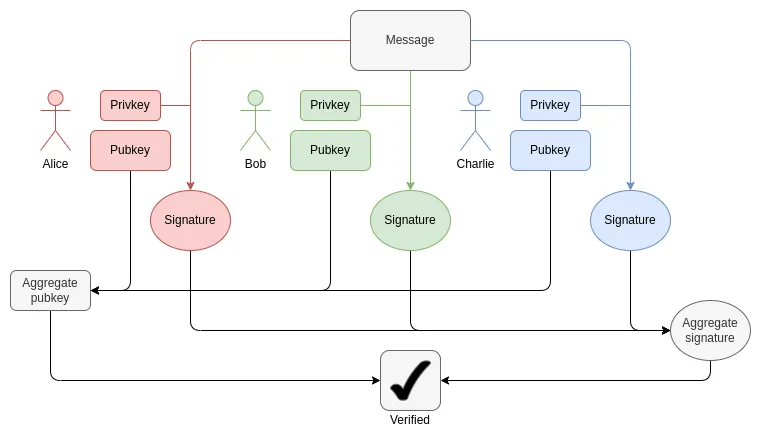
就配对而言,目前每个时隙最多有 128 个验证,这意味着需要验证 128 个配对。随着 EIP-7549 的推出和进一步修改,每个时隙的验证次数有可能减少到 16 次。配对的数量很少,但成本极高:每个配对的运行(或证明)时间比 ECADD 长数千倍。
证明 BLS12-381 操作的一个主要挑战是没有一个方便的曲线,其曲线阶等于 BLS12-381 的字段大小,这给任何证明系统都增加了大量的开销。另一方面,为以太坊提出的 Verkle 树是用 Bandersnatch 曲线 构建的,这使得 BLS12-381 本身成为 SNARK 系统中用于证明 Verkle 分支的自然曲线。一个比较简单的实现每秒可以证明大约 100 次 G1 附加值;要使证明速度足够快,肯定需要像 GKR 这样巧妙的技术。
对于 SHA256 哈希来说,目前最糟糕的情况是纪元(epoch)转换区块,整个验证者短余额树(short-balance tree)和大量验证者的余额都会被更新。每个验证者的短余额树只有 1 个字节,因此约有 1 MB 的数据会被重新哈希。这相当于 32,768 次 SHA256 调用。如果有一千个验证者的余额高于或低于一个阈值,需要更新验证者记录中的有效余额,这相当于一千个默克尔分支,因此可能需要一万次哈希。洗牌机制(shuffling mechanism)需要每个验证者 90 比特(因此需要 11 MB 的数据),但这可以在一个纪元的任何时间计算。在最终确定性的情况下,这些数字可能会根据具体情况有所增减。洗牌(Shuffling)变得不必要,尽管 Orbit 可能会重新带来某种程度的洗牌需求。
另一个挑战是需要读取——所有验证者的状态,包括公钥,才能验证一个区块。针对 100 万个验证者,仅读取公钥就需要 4800 万字节,再加上 Merkle 分支。这就需要每个纪元读取数百万个哈希值。如果我们今天必须证明权益证明的有效性,现实的方法应该是某种形式的增量可验证计算:在证明系统内存储一个单独的数据结构,该结构经过优化,可以高效查找,并证明对该结构的更新。
总之,有很多挑战。
最有效地解决这些挑战可能需要对信标链进行深入的重新设计,这可以与切换到最终确定性同时进行。这种重新设计的特点可能包括
哈希函数的变化:现在使用的是 “完整” 的 SHA256 哈希函数,因此由于填充的原因,每次调用都要对应两次底层压缩函数调用。如果改用 SHA256 压缩函数,我们至少可以获得 2 倍的收益。如果改用 Poseidon,我们就有可能获得约 100 倍的收益,从而彻底解决我们的所有问题(至少在哈希方面):以每秒 170 万次哈希(54 MB)的速度,即使是一百万条验证记录也能在几秒钟内 “读取” 到证明中。
如果使用 Orbit,则直接存储洗牌后的验证记录:如果选择一定数量的验证者(如 8192 或 32768)作为给定时隙的委员会,将它们直接放入彼此旁边的状态中,以便最小化读取所有验证者公钥到证明中时所需的哈希量。这样还能高效地完成所有的余额更新。
签名聚合:任何高性能签名聚合方案都会涉及某种递归证明,网络中的不同节点会对签名子集进行中间证明。这就自然而然地将证明工作分担给了网络中的多个节点,从而大大减少了 “最终证明者” 的工作量。
其他签名方案:对于 Lamport + Merkle 签名,我们需要 256 + 32 个哈希值来验证签名;乘以 32,768 个签名者,得到 9,437,184 个哈希值。对签名方案进行优化后,可以将哈希值进一步提高一个小的常数因子。如果我们使用波塞冬(Poseidon),在单个时隙内就能证明这一点。但实际上,使用递归聚合方案会更快。
与现有研究有哪些联系?
简洁的以太坊共识证明(仅限同步委员会):
SP1 内简洁的 Helios:
https://github.com/succinctlabs/sp1-helios
简洁的 BLS12-381 预编译:
基于 Halo2 的 BLS 集合签名验证:
还有什么要做,需要权衡什么?
实际上,我们需要数年时间才能获得以太坊共识的有效性证明。这与我们实现最终确定性、Orbit、修改签名算法以及安全分析所需的时间大致相同,而安全分析需要足够的信心才能使用像波塞冬(Poseidon)这样 “激进” 的哈希函数。因此,最合理的做法是解决这些其他问题的同时,考虑到 STARK 的友好性。
主要的权衡可能在于操作顺序之间的选择,即是采取渐进式方法改革以太坊共识层,还是采用更激进的 “多项变更同时进行” 的方法。对于 EVM 来说,渐进式方法是合理的,因为它可以最大限度减少对向后兼容性的干扰。而对于共识层来说,向后兼容性的影响较少,采取更全面的重新思考,可能会有助于在构建信任证明友好的信标链时优化各种细节。
它与路线图的其他部分如何互动?
在对以太坊权益证明共识进行长期重新设计时,STARK 友好性必须成为首要考虑因素,尤其是在最终确定性、Orbit、签名方案的更改和签名聚合的设计中。
免责声明:作为区块链信息平台,本站所发布文章仅代表作者及嘉宾个人观点,与 Web3Caff 立场无关。文章内的信息仅供参考,均不构成任何投资建议及要约,并请您遵守所在国家或地区的相关法律法规。
















